
- 1数据结构——哈希表、哈希桶
- 2在linux下安装mysql5.7_mysql5.7 aarch64 下载
- 3文心智能体:基于零代码平台的智能体开发与应用_文心智能体平台插件库
- 4git pull报错_git pull 报 git did not exist cleanly
- 5Android Service_c# android 后台运行
- 6安装Casaos系统后Nas脚本基础设置_casaos 安装完成后还需要安装那些文件
- 7springboot listener_Springboot 监听redis key的过期事件
- 8旅行商问题_旅行商问题,问题重述
- 9使用局部索引优化 PostgreSQL 和 MySQL 的性能
- 10redis队列list时效性过期解决方案_redis list 过期
深入理解数据结构原理(3)—数组和链表
赞
踩
目录
一、数组
1、数组的定义
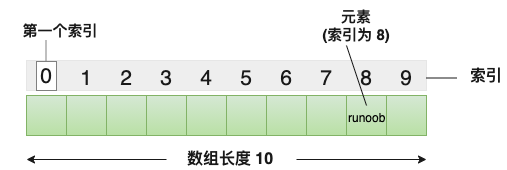
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。其特点为:提供随机访问 并且容量有限。
数组索引(index)从零开始:
在C语言中定义为:
int n [10];在java中定义为:
int[] n = new int[10];还有一种数组是在内部进行了内部封装,像 ArrayList:
ArrayList<E> objectName =new ArrayList<>();ArrayList:这个 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素
数组可以根据下标(索引)进行操作,插入的时候可以根据下标直接插入到具体的位置,但与此同时,后面的元素就需要全部向后移动。
简单总结一下 ArrayList 的时间复杂度,方便大家在学习的时候作为参考。
1、通过下标(也就是 get(int index))访问一个元素的时间复杂度为 O(1),因为是直达的,无论数据增大多少倍,耗时都不变。
2、添加一个元素(也就是 add())的时间复杂度为 O(1),因为直接添加到末尾。
3、删除一个元素的时间复杂度为 O(n),因为要遍历列表,数据量增大几倍,耗时也增大几倍。
4、查找一个未排序的列表时间复杂度为 O(n),因为要遍历列表;查找排序过的列表时间复杂度为 O(log n),因为可以使用二分查找法,当数据增大 n 倍时,耗时增大 logn 倍(这里的 log 是以 2 为底的,每找一次排除一半的可能)。
二、链表
1、链表的简单介绍
链表(LinkedList) 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。
但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点
2、链表的分类
一般的链表有单链表、双向链表、循环链表、双向循环链表
2.1、单链表
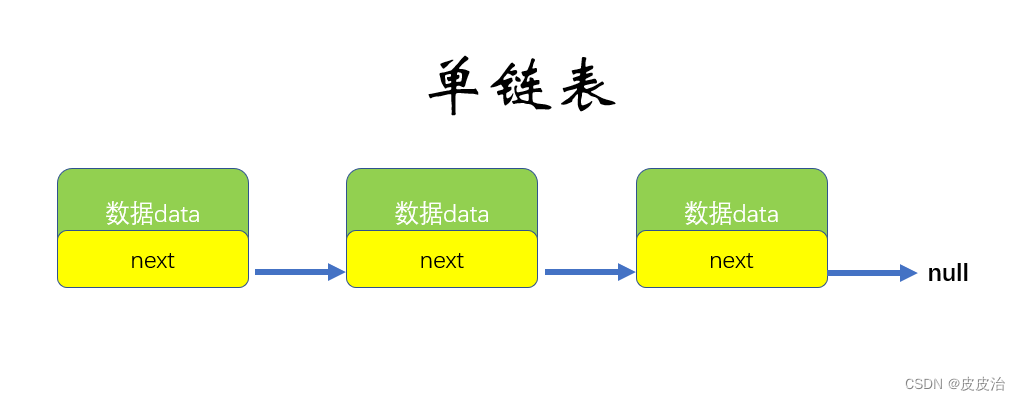
单链表 :是指通过一组任意的储存单元来储存线性表中数据元数,单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。
因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。data表示的是对象的(值),next是存储下一个结点的位置,根据next可以找到下一节点
在C语言中定义一个单链表为:
- typedef struct ListNode{ // 定义单链表节点类型
- ElemType data; // 数据域
- struct listNode *next;// 指针域
- }ListNode,*LinkList;
在java中定义一个单量表:
- public class ListNode <A>{ // 定义链表类
- Node head; //头结点
- int size; //记录结点个数
- ListNode (){
- head = new Node<A>(null,null);// 此处为初始化头结点。
- }
-
- class MyNode<A>{ // 定义结点类
- A data; // 数值域
- Node next; // 指向下一个结点地址
- Node(A data,Node next){ //每个结点都有一个数据域和地址域
- this.data = data;
- this.next = next;
-
- }
-
- }
- }

2.2、 循环链表
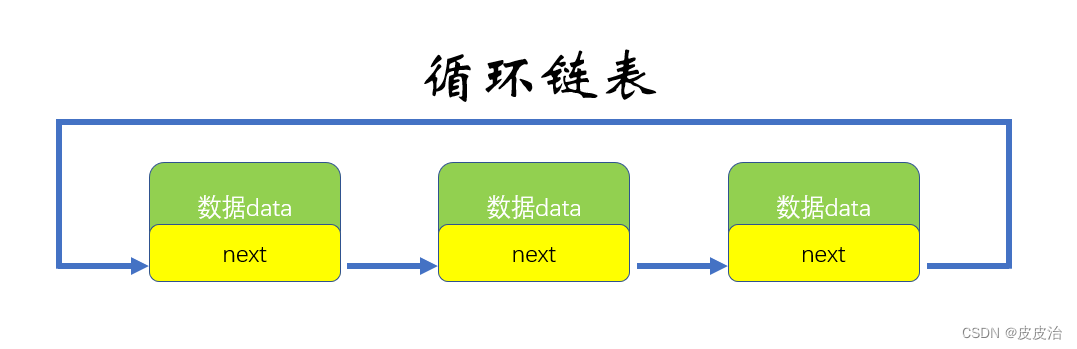
循环链表 :是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
2.3、双向链表
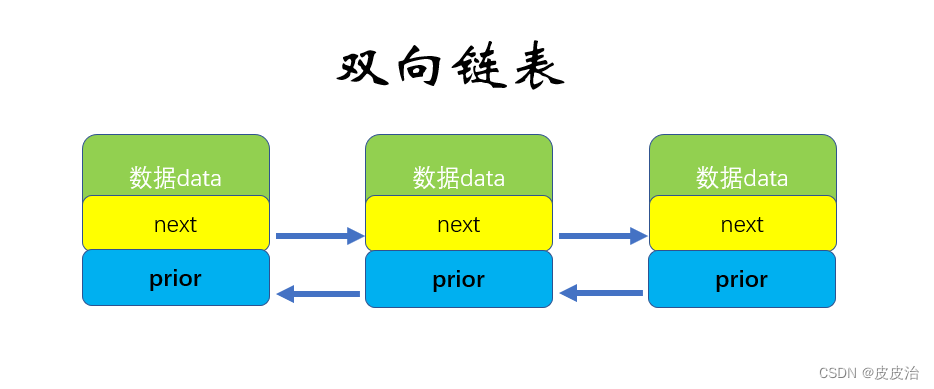
双向链表 :包含两个指针,一个 prior 指向前一个节点,一个 next 指向后一个节点。
2.4、双向循环链表
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prior 指向最后一个节点,构成一个环。
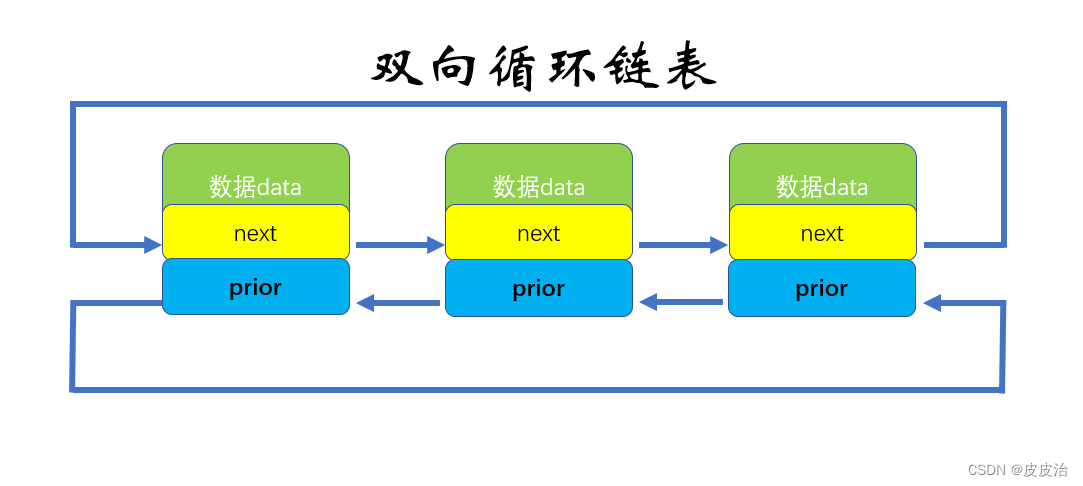
C语言中定义循环链表:
- typedef struct DoubleListNode{ // 定义单链表节点类型
- ElemType data; // 数据域
- struct DoubleListNode *prior,*next;// 前驱指针和后继指针
- }DoubleListNode,*DoubleLinkList;
2.5、数组对比链表
- 数组支持随机访问,而链表不支持。
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
2.6、应用场景
- 如果需要支持随机访问的话,链表没办法做到。
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。

