
- 1Ubuntu系统d435i相机驱动与realsense-ros安装_相机驱动之前需要安装ros,安装过程见我之前
- 2【TCP】四次挥手(终止连接)
- 3Ubuntu18.04及以上开机自启动脚本设置方法_ubuntu 1804 kaijiziqid daisudo
- 4YOLOv8实战——安装篇_yolov8安装
- 5Chapter 8 - 2. Congestion Management in TCP Storage Networks
- 6为什么不建议对Intel Realsense的D400 Series和T265进行标定(Calibration)_t265 dynamic calibration
- 7前端学习之——react篇(渲染列表)
- 8学IT毕业后该去哪个城市?哪个岗位薪资高?哪些公司待遇好?_上海 武汉哪个地方更适合计算机行业
- 9iOS 如何将证书和描述文件给其他人进行真机调试(Provisioning profile "描述文件的名字" doesn't include the currently selected devic...
- 10第十届蓝桥杯C++B组题解_第十届蓝桥杯国赛真题c++ b组
腾讯技术分享:微服务接口设计原则
赞
踩
来源|腾讯技术工程(ID:Tencent_TEG)

本文结合自身后台开发经验,从高可用、高性能、易维护和低风险(安全)角度出发,尝试总结业界常见微服务接口设计原则,帮助大家设计出优秀的微服务。
1.前言
微服务是一种系统架构风格,是 SOA(面向服务架构)的一种实践。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署,使得整个系统变得清晰灵活:
原子服务
独立进程
隔离部署
去中心化服务治理
一个大型复杂的软件应用,都可以拆分成多个微服务。各个微服务可被独立部署,各个微服务之间是松耦合的。现如今后台服务大部分以微服务的形式存在,每个微服务负责实现应用的一个功能模块。而微服务由一个个接口组成,每个接口实现某个功能模块下的子功能。
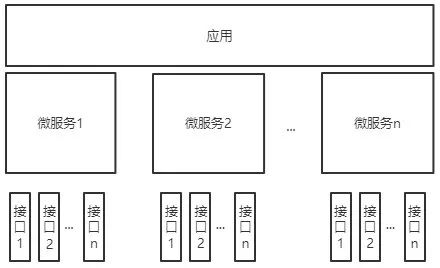
以一个 IM 应用为例,它的功能架构可能是下面这样的:
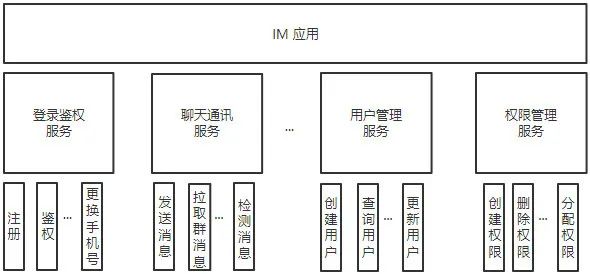
所以如果是后台开发的同学,经常需要实现一个后台微服务来提供相应的能力,完成业务功能。
服务以接口形式提供服务。在实现服务时,我们要将一个大的功能拆分成一个个独立的子功能来实现,每一个子功能就是我们要在服务中实现的一个接口。
有时一个服务会有很多接口,每个接口所要实现的功能可能会有关联,那么这就非常考验设计服务接口的功底,让服务变得简单可靠。
业界已经有很多比较成熟的实践原则,可以帮助我们设计实现出一个可靠易维护的服务。
微服务设计原则并没有严格的规范,下面结合业界成熟的方法和个人多年后台开发经验,介绍高可用,高性能,易维护,低风险服务常用的设计原则。
2.高可用
2.1 降级兜底
大部分服务是如下的结构,既要给使用方使用,又依赖于他人提供的第三方服务,中间又穿插了各种业务逻辑,这里每一块都可能是故障的来源。

如果第三方服务挂掉怎么办?我们业务也跟着挂掉?显然这不是我们希望看到的结果,如果能制定好降级兜底的方案,那将大大提高服务的可靠性。
比如我们做个性化推荐服务时,需要从用户中心获取用户的个性化数据,以便代入到模型里进行打分排序,但如果用户中心服务挂掉,我们获取不到数据了,那么就不推荐了?显然不行,我们可以在本地 cache 里放置一份热门商品以便兜底。
又比如做一个数据同步的服务,这个服务需要从第三方获取最新的数据并更新到 MySQL 中,恰好第三方提供了两种方式:
一种是消息通知服务,只发送变更后的数据;
一种是 HTTP 服务,需要我们自己主动调用获取数据。
我们一开始选择消息同步的方式,因为实时性更高,但是之后就遭遇到消息迟迟发送不过来的问题,而且也没什么异常,等我们发现一天时间已过去,问题已然升级为故障。合理的方式应该两个同步方案都使用,消息方式用于实时更新,HTTP 主动同步方式定时触发(比如 1 小时)用于兜底,即使消息出了问题,通过主动同步也能保证一小时一更新。
2.2 过载保护(保护自己)
如果是高并发场景使用的接口,那么需要做过载保护,防止服务过载引发雪崩。
相信很多做过高并发服务的同学都碰到类似事件:某天 A 君突然发现自己的接口请求量突然涨到之前的 10 倍,没多久该接口几乎不可使用,并引发连锁反应导致整个系统崩溃。
如何应对这种情况?生活给了我们答案:比如老式电闸都安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏。同理我们的接口也需要安装上“保险丝”,以防止非预期的请求对系统压力过大而引起的系统瘫痪,当流量过大时,可以采取拒绝或者引流等机制。
过载保护的做法:
请求等待时间超时
比如把接收到的请求放在指定的队列中排队处理,如果请求等待时间超时了(假设是 100ms),这个时候直接拒绝超时请求;再比如队列满了之后,就清除队列中一定数量的排队请求,保护服务不过载,保障服务高可用。
服务过载及早拒绝
根据服务当前指标(如 CPU、内存使用率、平均耗时等)判断服务是否处于过载,过载则及早拒绝请求并带上特殊错误码,告知上游下游已经过载,应做限流处理。
2.3 流量控制(保护下游)
流量控制,或者叫限流,一般用户保护下游不被大流量压垮。
常见的场景有:
(1)下游有严格的请求限制;比如银行转账接口,微信支付接口等都有严格的接口限频;
(2)调用的下游不是为高并发场景设计;比如提供异步计算结果拉取的服务,并不需要考虑各种复杂的高并发业务场景,提供高并发流量场景的支持。每个业务场景应该在拉取数据时缓存下来,而不是每次业务请求都过来拉取,将业务流量压垮下游。
(3)失败重试。调用下游失败了,一定要重试吗?如果不管三七二十一直接重试,这样是不对的,比如有些业务返回的异常表示业务逻辑出错,那么你怎么重试结果都是异常;又如有些异常是接口处理超时异常,这个时候就需要结合业务来判断了,有些时候重试往往会给后方服务造成更大压力,造成雪上加霜的效果。所有失败重试要有收敛策略,必要时才重试,做好限流处理。
控制流量,常用的限流算法有漏桶算法和令牌桶算法。必要的情况下,需要实现分布式限流。
2.4 快速失败
遵循快速失败原则,一定要设置超时时间。
某服务调用的一个第三方接口正常响应时间是 50ms,某天该第三方接口出现问题,大约有 15%的请求响应时间超过 2s,没过多久服务 load 飙高到 10 倍以上,响应时间也非常缓慢,即第三方服务将我们服务拖垮了。
为什么会被拖垮?没设置超时!我们采用的是同步调用方式,使用了一个线程池,该线程池里最大线程数设置了 50,如果所有线程都在忙,多余的请求就放置在队列里中。如果第三方接口响应时间都是 50ms 左右,那么线程都能很快处理完自己手中的活,并接着处理下一个请求,但是不幸的是如果有一定比例的第三方接口响应时间为 2s,那么最后这 50 个线程都将被拖住,队列将会堆积大量的请求,从而导致整体服务能力极大下降。
正确的做法是和第三方商量确定个较短的超时时间比如 200ms,这样即使他们服务出现问题也不会对我们服务产生很大影响。
2.5 无状态服务
尽可能地使微服务无状态。
无状态服务,可以横向扩展,从而不会成为性能瓶颈。
状态即数据。如果某一调用方的请求一定要落到某一后台节点,使用服务在本地缓存的数据(状态),那么这个服务就是有状态的服务。
我们以前在本地内存中建立的数据缓存、Session 缓存,到现在的微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。迁移后,就可以做到按需动态伸缩,微服务应用在运行时动态增删节点,就不再需要考虑缓存数据如何同步的问题。
2.6 最少依赖
能不依赖的,尽可能不依赖,越少越好。
减少依赖,便可以减少故障发生的可能性,提高服务可靠性。
任何依赖都有可能发生故障,即使其如何保证,我们在设计上应尽可能地减少对第三方的依赖。如果无法避免,则需要对第三方依赖在发生故障时做好相应处理,避免因第三方依赖的抖动或不可用导致我们自身服务不可用,比如降级兜底。
2.7 简单可靠
可靠性只有靠不断追求最大程度的简化而得到。
乏味是一种美德。与生活中的其他东西不同,对于软件而言,“乏味”实际上是非常正面的态度。我们不想要自发性的和有趣的程序;我们希望这些程序按设计执行,可以预见性地完成目标。与侦探小说不同,缺少刺激、悬念和困惑是源代码的理想特征。
因为工程师也是人,他们经常对于自己编写的代码形成一种情感依附,这些冲突在大规模清理源代码的时候并不少见。一些人可能会提出抗议,“如果我们以后需要这个代码怎么办?”,“我们为什么不只是把这些代码注释掉,这样稍后再使用它的时候会更容易。”,“为什么不增加一个功能开关?”,这些都是糟糕的建议。源代码控制系统中的更改反转很容易,数百行的注释代码则会造成干扰和混乱;那些由于功能开关没有启用而没有被执行的代码,就像一个定时炸弹等待爆炸。极端地说,当你指望一个 Web 服务 7*24 可以用时,某种程度上,每一行新代码都是负担。
法国诗人 Antoine de Saint-Exupéry 曾写道:“不是在不能添加更多的时候,而是没有什么可以去掉的时候,才能达到完美”。这个原则同样适用于软件设计。API 设计是这个规则应该被遵循的一个清晰的例子。书写一个明确的、简单的 API 是接口可靠的保证。我们向 API 消费者提供的方法和参数越少,这些 API 就越容易理解。在软件工程上,少就是多!一个很小的,很简单的 API 通常也是一个对问题深刻理解的标志。
软件的简单性是可靠性的前提条件。当我们考虑如何简化一个给定的任务的每一步时,我们并不是在偷懒。相反,我们是在明确实际上要完成的任务是什么,以及如何容易地做到。我们对新功能说“不”的时候,不是在限制创新,而是在保持环境整洁,以免分心。这样我们可以持续关注创新,并且可以进行真正的工程工作。
2.8 分散原则
鸡蛋不要放一个篮子,分散风险。
比如一个模块的所有接口不应该放到同一个服务中,如果服务不可用,那么该模块的所有接口都不可用了。我们可以基于主次进行服务拆分,将重要接口放到一个服务中,次要接口放到另外一个服务中,避免相互影响。
再如所有交易数据都放在同一个库同一张表里面,万一这个库挂了,此时影响所有交易。我们可以对数据库水平切分,分库分表。
2.9 隔离原则
控制风险不扩散,不放大。
不同模块之间要相互隔离,避免单个模块有问题影响其他模块,传播扩散了影响范围。
比如部署隔离:每个模块的服务部署在不同物理机上;
再如 DB 隔离:每个模块单独使用自身的存储实例。
古代赤壁之战就是一个典型的反面例子,铁锁连船导致隔离性被破坏,一把大火烧了 80W 大军。
隔离是有级别的,隔离级别越高,风险传播扩散的难度就越大,容灾能力越强。
例如:一个应用集群由 N 台服务器组成,部署在同一台物理机上,或同一个机房的不同物理机上,或同一个城市的不同机房里,或不同城市里,不同的部署代表不同的容灾能力。
例如:人类由无数人组成,生活在同一个地球的不同洲上,这意味着人类不具备星球级别的隔离能力,当地球出现毁灭性影响时,人类是不具备容灾的。
2.10 幂等设计(可重入)
所谓幂等,简单地说,就是对接口的多次调用所产生的结果和调用一次是一致的。数据发生改变才需要做幂等,有些接口是天然保证幂等性的。
比如查询接口,有些对数据的修改是一个常量,并且无其他记录和操作,那也可以说是具有幂等性的。其他情况下,所有涉及对数据的修改、状态的变更就都有必要防止重复性操作的发生。实现接口的幂等性可防止重复操作所带来的影响。
重复请求很容易发生,比如用户误触,超时重试等。举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果时网络异常(超时成功),此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额返发现多扣钱了,流水记录也变成了两条,就没有保证接口的幂等性。
2.11 故障自愈
没有 100% 可靠的系统,故障不可避免,但要有自愈能力。
人体拥有强大的自愈能力,比如手指划破流血,会自动止血,结痂,再到皮肤再生。微服务应该像人体一样,当面对非毁灭性伤害(故障)时,在不借助外力的情况下,自行修复故障。比如消息处理或异步逻辑等非关键操作失败引发的数据不一致,需要有最终一致的修复操作,如兜底的定时任务,失败重试队列,或由用户在下次请求时触发修复逻辑。
2.12 CAP 定理
2000 年,加州大学伯克利分校的计算机科学家 Eric Brewer 在分布式计算原理研讨会(PODC)上提出了一个猜想,分布式系统有三个指标:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
它们的第一个字母分别是 C、A、P。
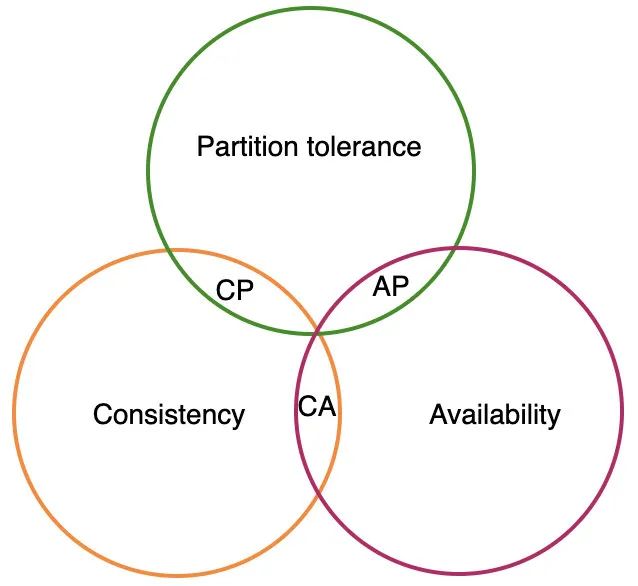
Eric Brewer 说,这三个指标最多只能同时实现两点,不可能三者兼顾,这便是著名的布鲁尔猜想。
在随后的 2002 年,麻省理工学院(MIT)的 Seth Gilbert 和 Nancy Lynch 发表了布鲁尔猜想的证明,使之成为一个定理,即 CAP 定理。
CAP 定理告诉我们,如果服务是分布式服务,那么不同节点间通信必然存在失败可能性,即我们必须接受分区容错性(P),那么我们必须在一致性(C)和可用性(A)之间做出取舍,即要么 CP,要么 AP。
如果你的服务偏业务逻辑,对接用户,那么可用性显得更加重要,应该选择 AP,遵守 BASE 理论,这是大部分业务服务的选择。
如果你的服务偏系统控制,对接服务,那么一致性显得更加重要,应该选择 CP,遵守 ACID 理论,经典的比如 Zookeeper。
总体来说 BASE 理论面向的是大型高可用、可扩展的分布式系统。与传统 ACID 特性相反,不同于 ACID 的强一致性模型,BASE 提出通过牺牲强一致性来获得可用性,并允许数据段时间内的不一致,但是最终达到一致状态。同时,在实际分布式场景中,不同业务对数据的一致性要求不一样,因此在设计中,ACID 和 BASE 应做好权衡和选择。
2.13 BASE 理论
在 CAP 定理的背景下,大部分分布式系统都偏向业务逻辑,面向用户,那么可用性相对一致性显得更加重要。如何构建一个高可用的分布式系统,BASE 理论给出了答案。
2008 年,eBay 公司选则把资料库事务的 ACID 原则放宽,于计算机协会(Association for Computing Machinery,ACM)上发表了一篇文章Base: An Acid Alternative,正式提出了一套 BASE 原则。
BASE 基于 CAP 定理逐步演化而来,其来源于对大型分布式系统实践的总结,是对 CAP 中一致性和可用性权衡的结果,其核心思想是即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。BASE 可以看作是 CAP 定理的延伸。
BASE 理论指:
Basically Available(基本可用)
基本可用就是假设系统出现故障,要保证系统基本可用,而不是完全不能使用。比如采用降级兜底的策略,假设我们在做个性化推荐服务时,需要从用户中心获取用户的个性化数据,以便代入到模型里进行打分排序。但如果用户中心服务挂掉,我们获取不到数据了,那么就不推荐了?显然不行,我们可以在本地 cache 里放置一份热门商品以便兜底。
Soft state( 软状态)
软状态指的是允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
Eventual consistency(最终一致性)
上面讲到的软状态不可能一直是软状态,必须有时间期限。在期限过后,应当保证所有副本保持数据一致性,从而达到数据的最终一致性,因此所有客户端对系统的数据访问最终都能够获取到最新的值,而这个时间期限取决于网络延时,系统负载,数据复制方案等因素。
3.高性能
3.1 无锁
3.1.1 锁的问题
高性能系统中使用锁,往往带来的坏处要大于好处。
并发编程中,锁带解决了安全问题,同时也带来了性能问题,因为锁让并发处理变成了串行操作,所以如无必要,尽量不要显式使用锁。
锁和并发,貌似有一种相克相生的关系。
为了避免严重的锁竞争导致性能的下降,有些场景采用了无锁化设计,特别是在底层框架上。无锁化主要有两种实现,无锁队列和无锁数据结构。
3.1.2 串行无锁
串行无锁最简单的实现方式可能就是单线程模型了,如 Redis/Nginx 都采用了这种方式。在网络编程模型中,常规的方式是主线程负责处理 I/O 事件,并将读到的数据压入队列,工作线程则从队列中取出数据进行处理,这种单 Reactor 多线程模型需要对队列进行加锁,这种模型叫单 Reactor 多线程模型。如下图所示:
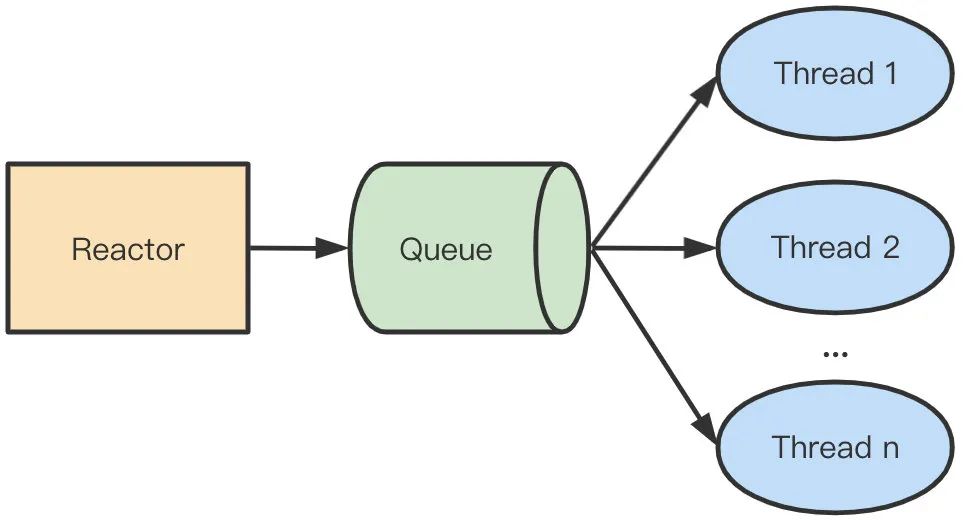
上图的模式可以改成串行无锁的形式,当 MainReactor accept 一个新连接之后从众多的 SubReactor 选取一个进行注册,通过创建一个 Queue 与 I/O 线程进行绑定,此后该连接的读写都在同一个队列和线程中执行,无需进行队列的加锁。这种模型叫主从 Reactor 多线程模型。
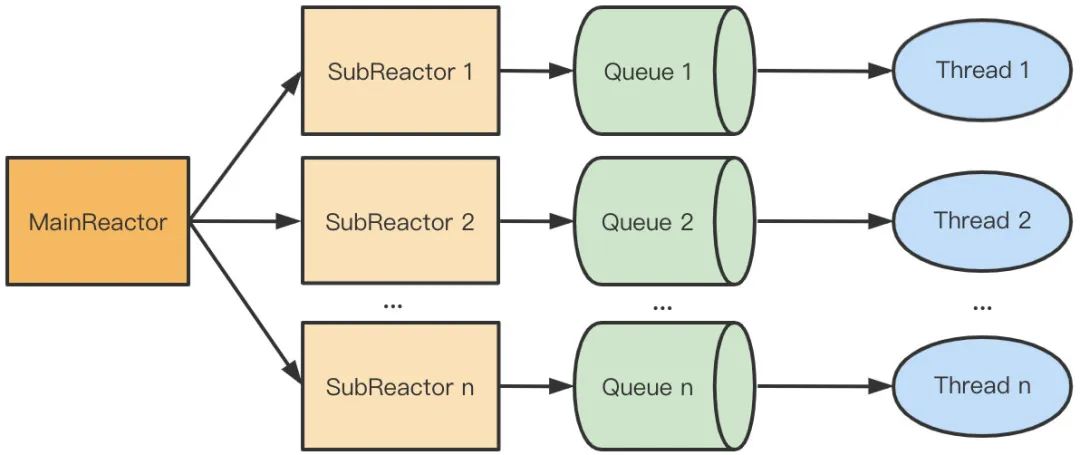
3.1.3 无锁数据结构
利用硬件支持的原子操作可以实现无锁的数据结构,很多语言都提供 CAS 原子操作(如 Go 中的 atomic 包和 C++11 中的 atomic 库),可以用于实现无锁数据结构,如无锁链表。
我们以一个简单的线程安全单链表的插入操作来看下无锁编程和普通加锁的区别。
- template<typename T>
- struct Node {
- Node(const T &value) : data(value) {}
- T data;
- Node *next = nullptr;
- };
有锁链表 WithLockList:
- template<typename T>
- class WithLockList {
- mutex mtx;
- Node<T> *head;
- public:
- void pushFront(const T &value) {
- auto *node = new Node<T>(value);
- lock_guard<mutex> lock(mtx); // (1)
- node->next = head;
- head = node;
- }
- };
无锁链表 LockFreeList:
- template<typename T>
- class LockFreeList {
- atomic<Node<T> *> head;
- public:
- void pushFront(const T &value) {
- auto *node = new Node<T>(value);
- node->next = head.load();
- while(!head.compare_exchange_weak(node->next, node)); // (2)
- }
- };
从代码可以看出,在有锁版本中 (1) 进行了加锁。在无锁版本中,(2) 使用了原子 CAS 操作 compare_exchange_weak,该函数如果存储成功则返回 true,同时为了防止伪失败(即原始值等于期望值时也不一定存储成功,主要发生在缺少单条比较交换指令的硬件机器上),通常将 CAS 放在循环中。
下面对有锁和无锁版本进行简单的性能比较,分别执行 1000,000 次 push 操作。测试代码如下:
- int main() {
- const int SIZE = 1000000;
- //有锁测试
- auto start = chrono::steady_clock::now();
- WithLockList<int> wlList;
- for(int i = 0; i < SIZE; ++i)
- {
- wlList.pushFront(i);
- }
- auto end = chrono::steady_clock::now();
- chrono::duration<double, std::micro> micro = end - start;
- cout << "with lock list costs micro:" << micro.count() << endl;
-
- //无锁测试
- start = chrono::steady_clock::now();
- LockFreeList<int> lfList;
- for(int i = 0; i < SIZE; ++i)
- {
- lfList.pushFront(i);
- }
- end = chrono::steady_clock::now();
- micro = end - start;
- cout << "free lock list costs micro:" << micro.count() << endl;
-
- return 0;
- }

三次输出如下,可以看出无锁版本有锁版本性能高一些。
- with lock list costs micro:548118
- free lock list costs micro:491570
- with lock list costs micro:556037
- free lock list costs micro:476045
- with lock list costs micro:557451
- free lock list costs micro:481470
3.1.4 减少锁竞争
如果加锁无法避免,则可以采用分片的形式,减少对资源加锁的次数,这样也可以提高整体的性能。
比如 Golang 优秀的本地缓存组件 bigcache 、go-cache、freecache 都实现了分片功能,每个分片一把锁,采用分片存储的方式减少加锁的次数从而提高整体性能。
以一个简单的示例,通过对map[uint64]struct{}分片前后并发写入的对比,来看下减少锁竞争带来的性能提升。
- var (
- num = 1000000
- m0 = make(map[int]struct{}, num)
- mu0 = sync.RWMutex{}
- m1 = make(map[int]struct{}, num)
- mu1 = sync.RWMutex{}
- )
-
- // ConWriteMapNoShard 不分片写入一个 map。
- func ConWriteMapNoShard() {
- g := errgroup.Group{}
- for i := 0; i < num; i++ {
- g.Go(func() error {
- mu0.Lock()
- defer mu0.Unlock()
- m0[i] = struct{}{}
- return nil
- })
- }
- _ = g.Wait()
- }
-
- // ConWriteMapTwoShard 分片写入两个 map。
- func ConWriteMapTwoShard() {
- g := errgroup.Group{}
- for i := 0; i < num; i++ {
- g.Go(func() error {
- if i&1 == 0 {
- mu0.Lock()
- defer mu0.Unlock()
- m0[i] = struct{}{}
- return nil
- }
- mu1.Lock()
- defer mu1.Unlock()
- m1[i] = struct{}{}
- return nil
- })
- }
- _ = g.Wait()
- }
看下二者的性能差异:
- func BenchmarkConWriteMapNoShard(b *testing.B) {
- for i := 0; i < b.N; i++ {
- ConWriteMapNoShard()
- }
- }
- BenchmarkConWriteMapNoShard-12 3 472063245 ns/op
-
- func BenchmarkConWriteMapTwoShard(b *testing.B) {
- for i := 0; i < b.N; i++ {
- ConWriteMapTwoShard()
- }
- }
- BenchmarkConWriteMapTwoShard-12 4 310588155 ns/op
可以看到,通过对分共享资源的分片处理,减少了锁竞争,能明显地提高程序的并发性能。可以预见的是,随着分片粒度地变小,性能差距会越来越大。当然,分片粒度不是越小越好。因为每一个分片都要配一把锁,那么会带来很多额外的不必要的开销。可以选择一个不太大的值,在性能和花销上寻找一个平衡。
3.2 缓存
3.2.1 为什么要有缓存?
数据的访问具有局部性,符合二八定律:80% 的数据访问是集中在 20% 的数据上,这部分数据也被称作热点数据。
不同层级的存储访问速率不同,内存读写速度快于磁盘,磁盘快于远端存储。基于内存的存储系统(如 Redis)高于基于磁盘的存储系统(如 MySQL)。
因为存在热点数据和存储访问速率的不同,我们可以考虑采用缓存。
缓存缓存一般使用内存作为本地缓存。
必要情况下,可以考虑多级缓存,如一级缓存采用本地缓存,二级缓存采用基于内存的存储系统(如 Redis、Memcache 等)。
缓存是原始数据的一个复制集,其本质就是空间换时间,主要是为了解决高并发读。
3.2.2 缓存的使用场景
缓存是空间换时间的艺术,使用缓存能提高系统的性能。“劲酒虽好,可不要贪杯”,使用缓存的目的是为了提高性价比,而不是一上来就为了所谓的提高性能不计成本的使用缓存,而是要看场景。
适合使用缓存的场景,以之前参与过的项目企鹅电竞为例:(1)一旦生成后基本不会变化的数据:如企鹅电竞的游戏列表,在后台创建一个游戏之后基本很少变化,可直接缓存整个游戏列表;
(2)读密集型或存在热点的数据:典型的就是各种 App 的首页,如企鹅电竞首页直播列表;
(3)计算代价大的数据:如企鹅电竞的 Top 热榜视频,如 7 天榜在每天凌晨根据各种指标计算好之后缓存排序列表;
(4)千人一面的数据:同样是企鹅电竞的 Top 热榜视频,除了缓存的整个排序列表,同时直接在进程内按页缓存了前 N 页数据组装后的最终回包结果;
不适合使用缓存的场景:
(1)写多读少,更新频繁;
(2)对数据一致性要求严格。
3.2.3 缓存的分类?
(1)进程级缓存
缓存的数据直接在进程地址空间内,这可能是访问速度最快使用最简单的缓存方式了。主要缺点是受制于进程空间大小,能缓存的数据量有限,进程重启缓存数据会丢失。一般通常用于缓存数据量不大的场景。
(2)集中式缓存
缓存的数据集中在一台机器上,如共享内存。这类缓存容量主要受制于机器内存大小,而且进程重启后数据不丢失。常用的集中式缓存中间件有单机版 redis、memcache 等。
(3)分布式缓存
缓存的数据分布在多台机器上,通常需要采用特定算法(如 Hash)进行数据分片,将海量的缓存数据均匀的分布在每个机器节点上。常用的组件有:Memcache(客户端分片)、Codis(代理分片)、Redis Cluster(集群分片)。
(4)多级缓存
指在系统中的不同层级进行数据缓存,以提高访问效率和减少对后端存储系统的冲击。
3.2.4 缓存的使用模式
关于缓存的使用,已经有人总结出了一些模式,主要分为 Cache-Aside 和 Cache-As-SoR 两类。其中 SoR(System-of-Record)表示记录系统,即数据源,而 Cache 正是 SoR 的拷贝。
Cache-Aside:旁路缓存
这应该是最常见的缓存模式了。对于读,首先从缓存读取数据,如果没有命中则回源 SoR 读取并更新缓存。对于写操作,先写 SoR,再写缓存。这种模式架构图如下:
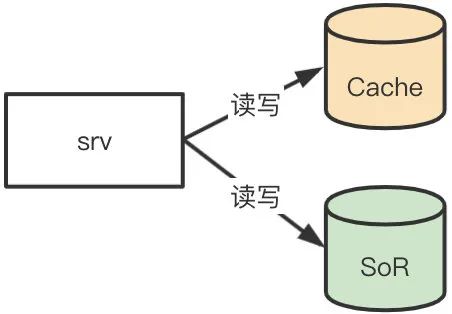
这种模式用起来简单,但对应用层不透明,需要业务代码完成读写逻辑。同时对于写来说,写数据源和写缓存不是一个原子操作,可能出现以下情况导致两者数据不一致。
(1)在并发写时,可能出现数据不一致。
如下图所示,user1 和 user2 几乎同时进行读写。在 t1 时刻 user1 写 db,t2 时刻 user2 写 db,紧接着在 t3 时刻 user2 写缓存,t4 时刻 user1 写缓存。这种情况导致 db 是 user2 的数据,缓存是 user1 的数据,两者不一致。
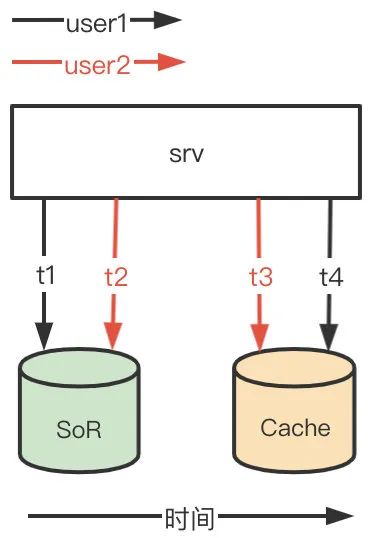
(2)先写数据源成功,但是接着写缓存失败,两者数据不一致。
对于这两种情况如果业务不能忍受,可简单的通过先 delete 缓存然后再写 db 解决,其代价就是下一次读请求的 cache miss。
Cache-as-SoR:缓存即数据源
该模式把 Cache 当作 SoR,所以读写操作都是针对 Cache,然后 Cache 再将读写操作委托给 SoR,即 Cache 是一个代理。如下图所示:

有三种实现方式:
(1)Read-Through:称为穿透读模式,首先查询 Cache,如果不命中则再由 Cache 回源到 SoR 即存储端实现 Cache-Aside 而不是业务)。
(2)Write-Through:称为穿透写模式,由业务先调用写操作,然后由 Cache 负责写缓存和 SoR。
(3)Write-Behind:称为回写模式,发生写操作时业务只更新缓存并立即返回,然后异步写 SoR,这样可以利用合并写/批量写提高性能。
3.2.5 缓存淘汰策略
在空间有限、低频热点访问或者无主动更新通知的情况下,需要对缓存数据进行回收,常用的回收策略有以下几种:
(1)基于时间:基于时间的策略主要可以分两种。
TTL(Time To Live):即存活期,从缓存数据创建开始到指定的过期时间段,不管有没有访问缓存都会过期。如 Redis 的 EXPIRE。
TTI(Time To Idle):即空闲期,缓存在指定的时间没有被访问将会被回收。
(2)基于空间:缓存设置了存储空间上限,当达到上限时按照一定的策略移除数据。
(3)基于容量:缓存设置了存储条目上限,当达到上限时按照一定的策略移除数据。
(4)基于引用:基于引用计数或者强弱引用的一些策略进行回收。
缓存常见淘汰算法如下:
FIFO(First In First Out):先进选出原则,先进入缓存的数据先被移除。
LRU(Least Recently Used):最基于局部性原理,即如果数据最近被使用,那么它在未来也极有可能被使用,反之,如果数据很久未使用,那么未来被使用的概率也较。
LFU:(Least Frequently Used):最近最少被使用的数据最先被淘汰,即统计每个对象的使用次数,当需要淘汰时,选择被使用次数最少的淘汰。
3.2.6 缓存的崩溃与修复
由于在设计不足、请求攻击(并不一定是恶意攻击)等会造成一些缓存问题,下面列出了常见的缓存问题和解决方案。
缓存穿透
大量使用不存在的 Key 进行查询时,缓存没有命中,这些请求都穿透到后端的存储,最终导致后端存储压力过大甚至被压垮。这种情况原因一般是存储中数据不存在,主要有三个解决办法。
(1)设置空置或默认值:如果存储中没有数据,则设置一个空置或者默认值缓存起来,这样下次请求时就不会穿透到后端存储。但这种情况如果遇到恶意攻击,不断的伪造不同的 Key 来查询时并不能很好的应对,这时候需要引入一些安全策略对请求进行过滤。
(2)布隆过滤器:采用布隆过滤器将,将所有可能存在的数据哈希到一个足够大的 Bitmap 中,一个一定不存在的数据会被这个 Bitmap 拦截掉,从而避免了对底层数据库的查询压力。
(3)singleflight 多个并发请求对一个失效的 Key 进行源数据获取时,只让其中一个得到执行,其余阻塞等待到执行的那个请求完成后,将结果传递给阻塞的其他请求达到防止击穿的效果。
缓存雪崩
指大量的缓存在某一段时间内集体失效,导致后端存储负载瞬间升高甚至被压垮。通常是以下原因造成:
(1)缓存失效时间集中在某段时间,对于这种情况可以采取对不同的 Key 使用不同的过期时间,在原来基础失效时间的基础上再加上不同的随机时间;
(2)采用取模机制的某缓存实例宕机,这种情况移除故障实例后会导致大量的缓存不命中。有两种解决方案:(a)采取主从备份,主节点故障时直接将从实例替换主;(b)使用一致性哈希替代取模,这样即使有实例崩溃也只是少部分缓存不命中。
缓存热点
虽然缓存系统本身性能很高,但也架不住某些热点数据的高并发访问从而造成缓存服务本身过载。假设一下微博以用户 ID 作为哈希 Key,突然有一天亦菲姐姐宣布婚了,如果她的微博内容按照用户 ID 缓存在某个节点上,当她的万千粉丝查看她的微博时必然会压垮这个缓存节点,因为这个 Key 太热了。这种情况可以通过生成多份缓存到不同节点上,每份缓存的内容一样,减轻单个节点访问的压力。
3.2.6 缓存的一些好实践
动静分离
对于一个缓存对象,可能分为很多种属性,这些属性中有的是静态的,有的是动态的。在缓存的时候最好采用动静分离的方式。以免因经常变动的数据发生更新而要把经常不变的数据也更新至缓存,成本很高。
慎用大对象
如果缓存对象过大,每次读写开销非常大并且可能会卡住其他请求,特别是在 redis 这种单线程的架构中。典型的情况是将一堆列表挂在某个 value 的字段上或者存储一个没有边界的列表,这种情况下需要重新设计数据结构或者分割 value 再由客户端聚合。
过期设置
尽量设置过期时间减少脏数据和存储占用,但要注意过期时间不能集中在某个时间段。
超时设置
缓存作为加速数据访问的手段,通常需要设置超时时间而且超时时间不能过长(如 100ms 左右),否则会导致整个请求超时连回源访问的机会都没有。
缓存隔离
首先,不同的业务使用不同的 Key,防止出现冲突或者互相覆盖。其次,核心和非核心业务进行通过不同的缓存实例进行物理上的隔离。
失败降级
使用缓存需要有一定的降级预案,缓存通常不是关键逻辑,特别是对于核心服务,如果缓存部分失效或者失败,应该继续回源处理,不应该直接中断返回。
容量控制
使用缓存要进行容量控制,特别是本地缓存,缓存数量太多内存紧张时会频繁的 swap 存储空间或 GC 操作,从而降低响应速度。
业务导向
以业务为导向,不要为了缓存而缓存。对性能要求不高或请求量不大,分布式缓存甚至数据库都足以应对时,就不需要增加本地缓存,否则可能因为引入数据节点复制和幂等处理逻辑反而得不偿失。
监控告警
对大对象、慢查询、内存占用等进行监控,做到缓存可观测,用得放心。
3.3 异步
3.3.1 调用异步
调用异步发生在使用异步编程模型来提高代码效率的时候,实现方式主要有:
Callback
异步回调通过注册一个回调函数,然后发起异步任务,当任务执行完毕时会回调用户注册的回调函数,从而减少调用端等待时间。这种方式会造成代码分散难以维护,定位问题也相对困难;
Future
当用户提交一个任务时会立刻先返回一个 Future,然后任务异步执行,后续可以通过 Future 获取执行结果;
CPS(Continuation-passing style)
可以对多个异步编程进行编排,组成更复杂的异步处理,并以同步的代码调用形式实现异步效果。CPS 将后续的处理逻辑当作参数传递给 Then 并可以最终捕获异常,解决了异步回调代码散乱和异常跟踪难的问题。Java 中的 CompletableFuture 和 C++ PPL 基本支持这一特性。典型的调用形式如下:
- void handleRequest(const Request &req) {
- return req.Read().Then([](Buffer &inbuf){
- return handleData(inbuf);
- }).Then([](Buffer &outbuf){
- return handleWrite(outbuf);
- }).Finally(){
- return cleanUp();
- });
- }
关于 CPS 更多信息推荐阅读:2018 中国 C++ 大会的吴锐_C++服务器开发实践部分。
3.3.2 流程异步
同步改异步,可以降低主链路的处理耗时。
举个例子,比如我们去 KFC 点餐,遇到排队的人很多,当点完餐后,大多情况下我们会隔几分钟就去问好了没,反复去问了好几次才拿到,在这期间我们也没法干活了。
这个就叫同步轮训,这样效率显然太低了。
服务员被问烦了,就在点完餐后给我们一个号码牌,每次准备好了就会在服务台叫号,这样我们就可以在被叫到的时候再去取餐,中途可以继续干自己的事。这就叫异步。
3.4 池化
3.4.1 为什么要池化
池化的目的是完成资源复用,避免资源重复创建、删除来提高性能。
常见的池子有内存池、连接池、线程池、对象池...
内存、连接、线程、对象等都是资源,创建和销毁这些资源都有一个特征, 那就是会涉及到很多系统调用或者网络 IO。每次都在请求中去创建这些资源,会增加处理耗时,但是如果我们用一个 容器(池) 把它们保存起来,下次需要的时候,直接拿出来使用,避免重复创建和销毁浪费的时间。
3.4.1 内存池
我们都知道,在 C/C++ 中分别使用 malloc/free 和 new/delete 进行内存的分配,其底层调用系统调用 sbrk/brk。频繁的调用系统调用分配释放内存不但影响性能还容易造成内存碎片,内存池技术旨在解决这些问题。正是这些原因,C/C++ 中的内存操作并不是直接调用系统调用,而是已经实现了自己的一套内存管理,malloc 的实现主要有三大实现。
ptmalloc:glibc 的实现。
tcmalloc:Google 的实现。
jemalloc:Facebook 的实现。
虽然标准库的实现在操作系统内存管理的基础上再加了一层内存管理,但应用程序通常也会实现自己特定的内存池,如为了引用计数或者专门用于小对象分配。所以看起来内存管理一般分为三个层次。

3.4.2 线程池
线程创建是需要分配资源的,这存在一定的开销,如果我们一个任务就创建一个线程去处理,这必然会影响系统的性能。线程池的可以限制线程的创建数量并重复使用,从而提高系统的性能。
线程池可以分类或者分组,不同的任务可以使用不同的线程组,可以进行隔离以免互相影响。对于分类,可以分为核心和非核心,核心线程池一直存在不会被回收,非核心可能对空闲一段时间后的线程进行回收,从而节省系统资源,等到需要时在按需创建放入池子中。
3.4.3 连接池
常用的连接池有数据库连接池、redis 连接池、TCP 连接池等等,其主要目的是通过复用来减少创建和释放连接的开销。连接池实现通常需要考虑以下几个问题:
初始化:启动即初始化和惰性初始化。启动初始化可以减少一些加锁操作和需要时可直接使用,缺点是可能造成服务启动缓慢或者启动后没有任务处理,造成资源浪费。惰性初始化是真正有需要的时候再去创建,这种方式可能有助于减少资源占用,但是如果面对突发的任务请求,然后瞬间去创建一堆连接,可能会造成系统响应慢或者响应失败,通常我们会采用启动即初始化的方式。
连接数目:权衡所需的连接数,连接数太少则可能造成任务处理缓慢,太多不但使任务处理慢还会过度消耗系统资源。
连接取出:当连接池已经无可用连接时,是一直等待直到有可用连接还是分配一个新的临时连接。
连接放入:当连接使用完毕且连接池未满时,将连接放入连接池(包括连接池已经无可用连接时创建的临时连接),否则关闭。
连接检测:长时间空闲连接和失效连接需要关闭并从连接池移除。常用的检测方法有:使用时检测和定期检测。
3.4.4 对象池
严格来说,各种池都是对象池的的具体应用,包括前面介绍的三种池。
对象池跟各种池一样,也是缓存一些对象从而避免大量创建同一个类型的对象,同时限制了实例的个数。如 Redis 中 0-9999 整数对象就通过对象池进行共享。在游戏开发中对象池经常使用,如进入地图时怪物和 NPC 的出现并不是每次都是重新创建,而是从对象池中取出。
3.5 批量
能批量就不要并发。
如果调用方需要调用我们接口多次才能进行一个完整的操作,那么这个接口设计就可能有问题。
比如获取数据的接口,如果仅仅提供getData(int id)接口,那么使用方如果要一次性获取 20 个数据,它就需要循环遍历调用我们接口 20 次,不仅使用方性能很差,也无端增加了我们服务的压力,这时提供一个批量拉取的接口getDataBatch(List<Integer> idList)显然是必要的。
对于批量接口,我们也要注意接口的吞吐能力,避免长时间执行。
还是以获取数据的接口为例:getDataList(List<Integer> idList),假设一个用户一次传 1w 个 id 进来,那么接口可能需要很长的时间才能处理完,这往往会导致超时,用户怎么调用结果都是超时异常,那怎么办?限制长度,比如限制长度为 100,即每次最多只能传 100 个 id,这样就能避免长时间执行,如果用户传的 id 列表长度超过 100 就报异常。
加了这样限制后,必须要让使用方清晰地知道这个方法有此限制,尽可能地避免用户误用。
有三种方法:
改变方法名,比如
getDataListWithLimitLength(List<Integer> idList);在接口说明文档中增加必要的注释说明;
接口明确抛出超长异常,直白告知主调。
3.6 并发
3.6.1 请求并发
如果一个任务需要处理多个子任务,可以将没有依赖关系的子任务并发化,这种场景在后台开发很常见。如一个请求需要查询 3 个数据,分别耗时 T1、T2、T3,如果串行调用总耗时 T=T1+T2+T3。对三个任务执行并发,总耗时 T=max(T1,T 2,T3)。同理,写操作也如此。对于同种请求,还可以同时进行批量合并,减少 RPC 调用次数。
3.6.2 冗余请求
冗余请求指的是同时向后端服务发送多个同样的请求,谁响应快就是使用谁,其他的则丢弃。这种策略缩短了主调方的等待时间,但也使整个系统调用量猛增,一般适用于初始化或者请求少的场景。比如腾讯公司 WNS 的跑马模块其实就是这种机制,跑马模块为了快速建立长连接同时向后台多个 IP/Port 发起请求,谁快就用谁,这在弱网的移动设备上特别有用,如果使用等待超时再重试的机制,无疑将大大增加用户的等待时间。
这种方式较少使用,知道即可。
3.7 存储设计
任何一个系统,从单机到分布式,从前端到后台,功能和逻辑各不相同,但干的只有两件事:读和写。而每个系统的业务特性可能都不一样,有的侧重读、有的侧重写,有的两者兼备,本节主要探讨在不同业务场景下存储读写的一些方法论。
3.7.1 读写分离
大多数业务都是读多写少,为了提高系统处理能力,可以采用读写分离的方式将主节点用于写,从节点用于读,如下图所示。
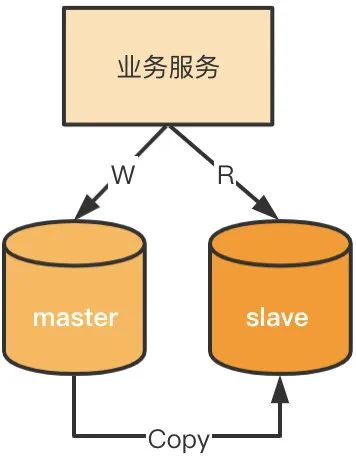
读写分离架构有以下几个特点:(1)数据库服务为主从架构;(2)主节点负责写操作,从节点负责读操作;(3)主节点将数据复制到从节点;
基于读写分离思想,可以设计出多种主从架构,如主-主-从、主-从-从等。主从节点也可以是不同的存储,如 MySQL+Redis。
读写分离的主从架构一般采用异步复制,会存在数据复制延迟的问题,适用于对数据一致性要求不高的业务。可采用以下几个方式尽量避免复制滞后带来的问题。
写后读一致
即读自己的写,适用于用户写操作后要求实时看到更新。典型的场景是,用户注册账号或者修改账户密码后,紧接着登录,此时如果读请求发送到从节点,由于数据可能还没同步完成,用户登录失败,这是不可接受的。针对这种情况,可以将自己的读请求发送到主节点上,查看其他用户信息的请求依然发送到从节点。
二次读取
优先读取从节点,如果读取失败或者跟踪的更新时间小于某个阀值,则再从主节点读取。
区分场景
关键业务读写主节点,非关键业务读写分离。
单调读
保证用户的读请求都发到同一个从节点,避免出现回滚的现象。如用户在 M 主节点更新信息后,数据很快同步到了从节点 S1,用户查询时请求发往 S1,看到了更新的信息。接着用户再一次查询,此时请求发到数据同步没有完成的从节点 S2,用户看到的现象是刚才的更新的信息又消失了,即以为数据回滚了。
3.7.2 分库分表
读写分离虽然可以明显的提示查询的效率,但是无法解决更高的并发写入请求的场景,这时候就需要进行分库分表,提高并发写入的能力。
通常,在以下情况下需要进行分库分表:
(1)单表的数据量达到了一定的量级(如 mysql 一般为千万级),读写的性能会下降。这时索引也会很大,性能不佳,需要分解单表。
(2)数据库吞吐量达到瓶颈,需要增加更多数据库实例来分担数据读写压力。
分库分表按照特定的条件将数据分散到多个数据库和表中,分为垂直切分和水平切分两种模式。
垂直切分
按照一定规则,如业务或模块类型,将一个数据库中的多个表分布到不同的数据库上。以电商平台为例,将商品数据、订单数据、用户数据分别存储在不同的数据库上,如下图所示:
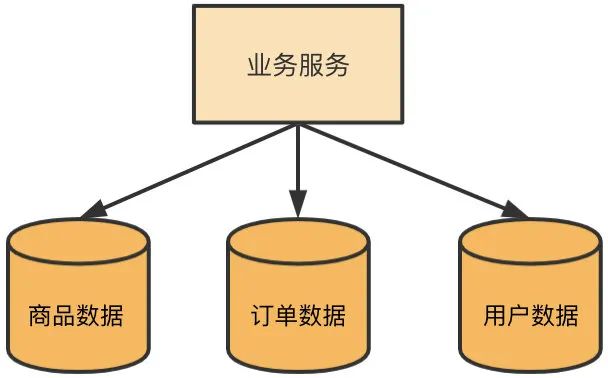
优点:(1)切分规则清晰,业务划分明确;(2)可以按照业务的类型、重要程度进行成本管理,扩展也方便;(3)数据维护简单。
缺点:(1)不同表分到了不同的库中,无法使用表连接 Join。不过在实际的业务设计中,也基本不会用到 Join 操作,一般都会建立映射表通过两次查询或者写时构造好数据存到性能更高的存储系统中。(2)事务处理复杂,原本在事务中操作同一个库的不同表不再支持。这时可以采用柔性事务或者其他分布式事物方案。
水平切分
按照一定规则,如哈希或取模,将同一个表中的数据拆分到多个数据库上。可以简单理解为按行拆分,拆分后的表结构是一样的。如用户信息记录,日积月累,表会越来越大,可以按照用户 ID 或者用户注册日期进行水平切分,存储到不同的数据库实例中。
优点:(1)切分后表结构一样,业务代码不需要改动;(2)能控制单表数据量,有利于性能提升。
缺点:(1)Join、count、记录合并、排序、分页等问题需要跨节点处理;(2)相对复杂,需要实现路由策略;
综上所述,垂直切分和水平切分各有优缺点,通常情况下这两种模式会一起使用。
3.7.3 动静分离
动静分离将经常更新的数据和更新频率低的数据进行分离。最常见于 CDN,一个网页通常分为静态资源(图片/JS/CSS 等)和动态资源(JSP、PHP 等),采取动静分离的方式将静态资源缓存在 CDN 边缘节点上,只需请求动态资源即可,减少网络传输和服务负载。
在数据库和 KV 存储上也可以采取动态分离的方式。动静分离更像是一种垂直切分,将动态和静态的字段分别存储在不同的库表中,减小数据库锁的粒度,同时可以分配不同的数据库资源来合理提升利用率。
3.7.4 冷热分离
冷热分离可以说是每个存储产品和海量业务的必备功能,MySQL、ElasticSearch 等都直接或间接支持冷热分离。将热数据放到性能更好的存储设备上,冷数据下沉到廉价的磁盘,从而节约成本。
3.7.5 重写轻读
基本思路就是写入数据时多写点(冗余写),降低读的压力。
社交平台中用户可以互相关注,查看关注用户的最新消息,形成 Feed 流。
用户查看 Feed 流时,系统需要查出此用户关注了哪些用户,再查询这些用户所发的消息,按时间排序。
为了满足高并发的查询请求,可以采用重写轻读,提前为每个用户准备一个收件箱。
每个用户都有一个收件箱和一个发件箱。比如一个用户有 1000 个粉丝,他发布一条消息时,写入自己的发件箱即可,后台异步的把这条消息放到那 1000 个粉丝的收件箱中。
这样,用户读取 Feed 流时就不需要实时查询聚合了,直接读自己的收件箱就行了。把计算逻辑从”读”移到了”写”一端,因为读的压力要远远大于写的压力,所以可以让”写”帮忙干点活儿,提升整体效率。
上图展示了一个重写轻度的一个例子,在实际应用中可能会遇到一些问题。如:
(1)写扩散:这是个写扩散的行为,如果一个大 V 的粉丝很多,这写扩散的代价也是很大的,而且可能有些人万年不看朋友圈甚至屏蔽了朋友。需要采取一些其他的策略,如粉丝数在某个范围内是才采取这种方式,数量太多采取推拉结合和分析一些活跃指标等。
(2)信箱容量:一般来说查看 Feed 流(如微信朋友圈)不会不断的往下翻页查看,这时候应该限制信箱存储条目数,超出的条目从其他存储查询。
3.7.6 数据异构
数据异构顾名思义就是存储不同结构的数据,有很多种含义:
数据格式的异构
数据的存储格式不同,可以是关系型(如 MySQL、SQL Server、DB2 等),也可以是 KV 格式(如 Redis、Memcache 等),还可以是文件行二维数据(如 txt、CSV、XLS 等)。
数据存储地点的异构
据存储在分散的物理位置上,此类情况大多出现在大型机构中,如销售数据分别存储在北京、上海、日本、韩国等多个分支机构的本地销售系统中。
数据存储逻辑的异构
相同的数据按照不同的逻辑来存储,比如按照不同索引维度来存储同一份数据。
这里主要说的是按照不同的维度建立索引关系以加速查询。如京东、天猫等网上商城,一般按照订单号进行了分库分表。由于订单号不在同一个表中,要查询一个买家或者商家的订单列表,就需要查询所有分库然后进行数据聚合。可以采取构建异构索引,在生成订单的时同时创建买家和商家到订单的索引表,这个表可以按照用户 ID 进行分库分表。
3.8 零拷贝
3.8.1 为什么要实现零拷贝?
这里的拷贝指的是数据在内核缓冲区和应用程序缓冲区直接的传输,并非指进程空间中的内存拷贝(当然这方面也可以实现零拷贝,如传引用和 C++ 中 move 操作)。现在假设我们有个服务,提供用户下载某个文件,当请求到来时,我们把服务器磁盘上的数据发送到网络中,这个流程伪代码如下:
- filefd = open(...); //打开文件
- sockfd = socket(...); //打开socket
- buffer = new buffer(...); //创建buffer
- read(filefd, buffer); //从文件内容读到buffer中
- write(sockfd, buffer); //将buffer中的内容发送到网络
数据拷贝流程如下图:
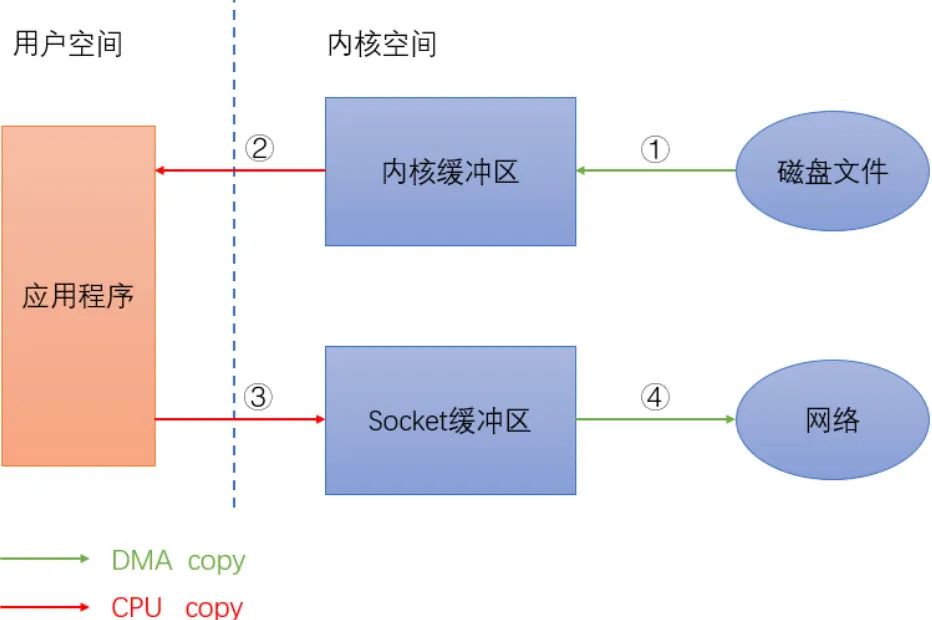
上图中绿色箭头表示 DMA copy,DMA(Direct Memory Access)即直接存储器存取,是一种快速传送数据的机制,指外部设备不通过 CPU 而直接与系统内存交换数据的接口技术。红色箭头表示 CPU copy。即使在有 DMA 技术的情况下还是存在 4 次拷贝,DMA copy 和 CPU copy 各 2 次。
3.8.2 内存映射
内存映射将用户空间的一段内存区域映射到内核空间,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间,简单来说就是用户空间共享这个内核缓冲区。
使用内存映射来改写后的伪代码如下:
- filefd = open(...); //打开文件
- sockfd = socket(...); //打开socket
- buffer = mmap(filefd); //将文件映射到进程空间
- write(sockfd, buffer); //将buffer中的内容发送到网络
使用内存映射后数据拷贝流如下图所示:
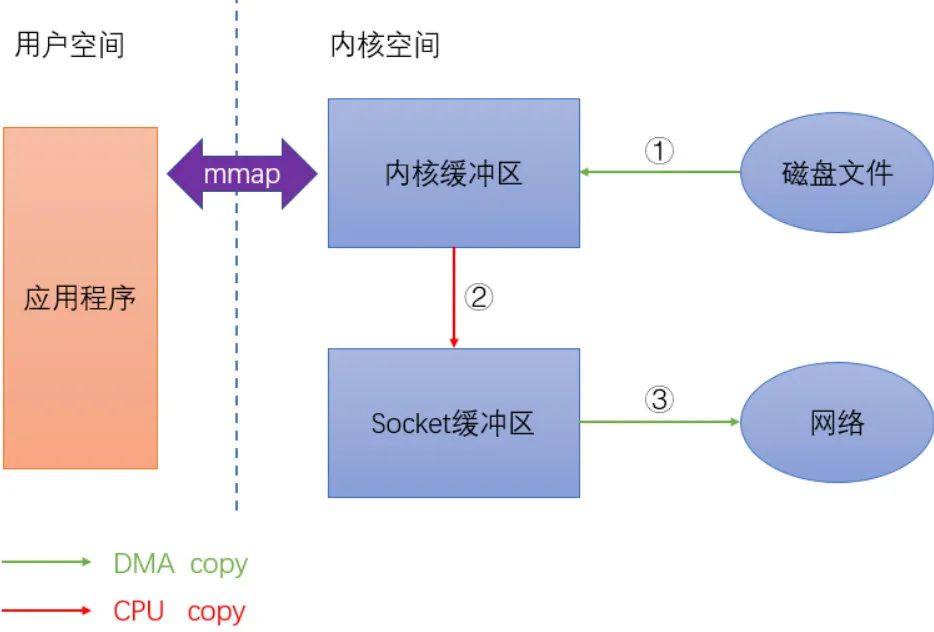
从图中可以看出,采用内存映射后数据拷贝减少为 3 次,不再经过应用程序直接将内核缓冲区中的数据拷贝到 Socket 缓冲区中。RocketMQ 为了消息存储高性能,就使用了内存映射机制,将存储文件分割成多个大小固定的文件,基于内存映射执行顺序写。
3.8.3 零拷贝
零拷贝就是一种避免 CPU 将数据从一块存储拷贝到另外一块存储,从而有效地提高数据传输效率的技术。Linux 内核 2.4 以后,支持带有 DMA 收集拷贝功能的传输,将内核页缓存中的数据直接打包发到网络上,伪代码如下:
- filefd = open(...); //打开文件
- sockfd = socket(...); //打开socket
- sendfile(sockfd, filefd); //将文件内容发送到网络
使用零拷贝后流程如下图:
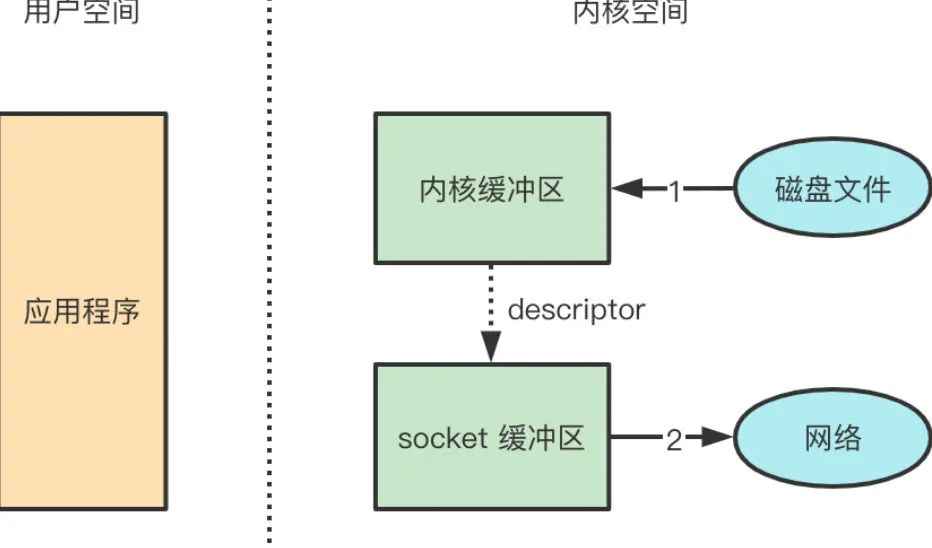
零拷贝的步骤为:
(1)DMA 将数据拷贝到 DMA 引擎的内核缓冲区中。(2)将数据的位置和长度的信息的描述符加到套接字缓冲区。(3)DMA 引擎直接将数据从内核缓冲区传递到协议引擎。
可以看出,零拷贝并非真正的没有拷贝,还是有 2 次内核缓冲区的 DMA 拷贝,只是消除了内核缓冲区和用户缓冲区之间的 CPU 拷贝。Linux 中主要的零拷贝系统函数有 sendfile、splice、tee 等。零拷贝比普通传输会快很多,如 Kafka 也使用零拷贝技术。
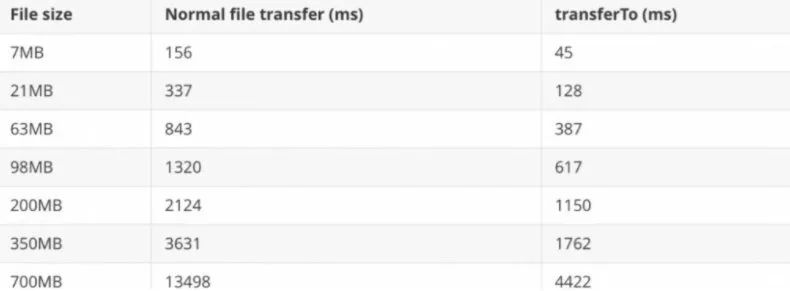
下图是来住 IBM 官网上普通传输和零拷贝传输的性能对比,可以看出零拷贝比普通传输快了 3 倍左右。
4.易维护
4.1 充分必要
不是随便一个功能就要有个接口。
虽然一个接口应该只专注一件事,但并不是每一个功能都要新建一个接口。要有充分的理由和考虑,即这个接口的存在是十分有意义和价值的。无意义的接口不仅浪费开发人力,更增加了服务的维护难度,服务将会十分臃肿。
相关功能我们应该考虑合为一个接口来实现。
4.2 单一职责
每个 API 应该只专注做一件事情。
就像我们开发人员一样,要么从事后台开发,要么从事前端开发,要么从事服务器运维开发。公司一般不会让一个人包揽所有的开发工作,因为这让员工的职责不够单一,不利于员工在专业领域的深耕,很容易成为万金油。对公司的影响是因员工对专业知识掌握的不够深,导致开发出的软件质量得不到保证。
让接口的功能保持单一,实现起来不仅简单,维护起来也会容易很多,不会因为大而全的冗杂功能导致接口经常出错。
比如读写分离和动静分离的做法都是单一职责原则的具体体现。如果一个接口干了两件事情,就应该把它分开,因为修改一个功能可能会影响到另一个功能。
4.3 内聚解耦
一个接口要包含完整的业务功能,而不同接口之间的关联要尽可能的小。
这样便降低了对其他接口的依赖程度,如此其他接口的变动对当前接口的影响也会降低。一般都是通过消息中间件 MQ 来完成接口之间的耦合。
4.4 开闭原则
对扩展开放,对修改关闭。
这句话怎么理解呢,也就是说,我们在设计一个接口的时候,应当使这个接口可以在不被修改的前提下被扩展其功能。换句话说,应当可以在不修改源代码的情况下改变接口的行为。
比如 IM 应用中,当用户输入简介时有个长度限制,我们不应该将长度限制写死在代码,可以通过配置文件的方式来动态扩展,这就做到了对扩展开放(用户简介长度可以变更),对修改关闭(不需要修改代码)。
此外,在设计模式中模板方法模式和观察者模式都是开闭原则的极好体现。
4.5 统一原则
接口要具备统一的命名规范、统一的出入参风格、统一的异常处理流程、统一的错误码定义、统一的版本规范等。
统一规范的接口有很多优点,自解释、易学习,难误用,易维护等。
4.6 用户重试
接口失败时,应该尽可能地由用户重试。
失败不可避免,因为接口无法保证 100%成功。一个简单可靠的异常处理策略便是由用户重试,而不是由后台服务进行处理。
还是 IM 应用为例,有这样的需求场景。群管理员需要拉黑用户,被拉黑的用户要先剔出群,且后续不允许加入群。那么拉黑由一个独立的接口来完成,需要两个操作。一是将用户剔出群,二是将用户写入群的黑名单存储。此时两个操作无法做到事务,也就是我们无法保证两个操作要么同时成功,要么同时失败。这种情况下我们该怎么做,既让接口实现起来简单,要能满足需求呢?
我们如果将用户剔出群放到第一步,那么可能会存在踢出群成功,但是写入群的黑名单存储失败,这种情况下提示用户拉黑失败,但却把用户给踢出了群,对用户来说,体验上是个功能 bug。
秉着用户尽可能地由用户重试的原则,我们应该将写入群的黑名单存储放到第一步,踢出群放到第二步。并且踢出群作为非关键逻辑,允许失败,因为者可以让用户手动将该用户踢出群,这就给了用户重试的机会,并且我们的接口在实现上也变得简单。
如果要引入消息队列存储踢出群的失败日志,让后由后台服务消费重试来保证一定成功,那么实现上将变得复杂且难以维护。不是非常重要的操作,一定不要这么做。
4.7 最小惊讶
代码应该尽可能避免让读者蒙圈。
只需根据需求来设计实现即可,切勿刻意去设计一个复杂无用、华而不实的 API,以免弄巧成拙。一个通俗易懂易维护的 API 比一个炫技复杂难理解的 API 更容易让人接受。
4.8 避免无效请求
不要传递无效请求至下游。
无效请求下游应及早检测发现并拒绝,可能会引发相关入参无效的告警,混淆视听且骚扰。我们应避免传递无效请求至下游,避免浪费带宽和计算资源。
换位思考,谁都不想浪费力气做无用功。
4.9 入参校验
自己收到的请求要做好入参校验,及早发现无效请求并拒绝,然后告警。发现垃圾请求后推动上游不要传递无效请求至下游。
此时,我们是上游的下游,做好入参校验,避免做无用功。
4.10 设计模式
适当的使用设计模式,让我们的代码更加简洁、易读、可扩展。
设计模式(Design Pattern)是一套被反复使用、多人知晓、分类编目、代码设计经验的总结。使用设计模式可以带来如下益处。
简洁。比如单例模式,减少多实例创建维护的成本,获取实例只需要一个 Get 函数。
易读。业界经验,多人知晓。如果告知他人自己使用了相应的设计模式实现某个功能,那么他人便大概知晓了你的实现细节,更加容易读懂你的代码。
可扩展。设计模式不仅能简洁我们的代码,还可以增加代码的可扩展性。比如 Go 推崇的 Option 模式,既避免了书写不同参数版本的函数,又达到了无限扩增函数参数的效果,增加了函数扩展性。
4.11 禁用 flag 标识
为什么接口不要使用 flag 标识,因为这会使接口变得臃肿,违背单一职责,最终难以维护。
这里说下,我们为什么会使用 flag 标识。
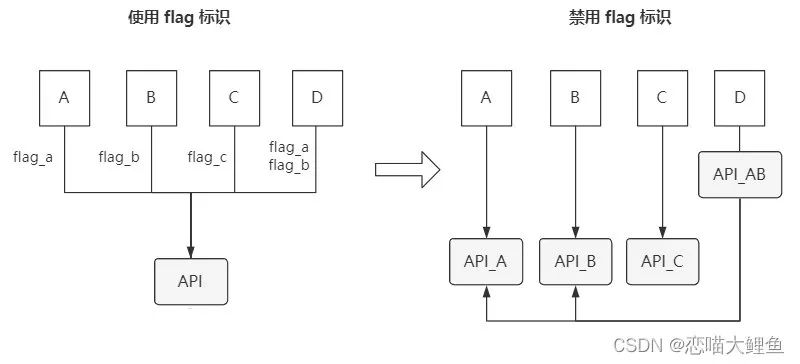
有时,我们需要提供一个读接口供上游调用查询相关信息。如主调 A 需要信息 a,主调 B 需要信息 b,主调 C 需要信息 c,主调 D 需要信息 a 和 b。如果为每个主调获取信息都提供单独的接口,那么接口会变得很多。为了减少接口的数量,我们很容易想到给接口增加多个 flag 参数,每个主调在调用接口时携带不同的 flag,表明需要获取哪些信息,然后接口根据入参 flag 获取对应的信息。比如主调 A 调用时将 flag_a 置为 true,主调 B 将 flag_b 置为 true,主调 C 将 flag_c 置为 true,主调 D 将 flag_a 和 flag_c 置为 true。
在项目前期或者 flag 数量较少的情况下,接口功能不是很多时,一般不会暴露出问题。一但开了这个口子,随着需要不同信息主调的增多,接口会不停的增加 flag,最终导致接口变得庞大臃肿,不仅难以阅读维护,还会使接口性能低下。
所以,我们应该禁用 flag 标识,尽可能地保证接口功能单一。
回到上面提到的场景,不适用 flag 标识,我们改如何是好呢?
我们应该坚持单一职责的原则,将信息进行原子分割,每个原子信息作为一个独立的接口对外提供服务。如果需要多个原子信息,我们可以增加一个 proxy 层,以独立接口将需要的相关原子信息汇聚组合。这么做你可能会问,接口变多了,会导致服务难以维护。不用担心,如果服务接口数量过多,我们应该对服务进行拆分。
还是以上面提及的例子为例,接口禁用 flag 前后组织形式对比如下:
4.12 页宜小不宜大
对于设计和实现 API 来说,当结果集包含成千上万条记录时,返回一个查询的所有结果可能是一个挑战,它给服务器、客户端和网络带来了不必要的压力,于是就有了分页的功能。
通常我们通过一个 offset 偏移量或者页码来进行分页,然后通过 API 一页一页的查询。
那么页大小设为多少合适呢?
常见的页大小有 50,100,200 和 500。如何选择页大小,我们应该在满足特定业务场景需求下,宜少不宜多。
太大的页,主要有以下几个问题:
影响用户体验。页太大,加载会比较慢,用户等待时间会比较长;
影响接口性能。页太大,会增加数据的拉取编解码耗时,降低接口性能;
浪费带宽。很多场景下,用户在浏览的过程中,不会看完一页中的所有数据,返回太大的页是一种浪费;
扩展性差。随着业务的发展,接口在页大小不变的情况下,返回的页数据可能会越来越大,导致接口性能越来越差,最终拖垮接口。
页大小多少合适,没有标准答案,需要根据具体的业务场景来定。但是要坚持一点,页宜小不宜大。如果接口的页大小,能用 50 便可满足业务需求,就不要用 100 和 200,更不要用 500。
5.低风险
道路千万条,安全第一条。虽然很多时候感觉网络攻击和安全事故离我们很远,但一旦发生,后面不堪设想,所以服务接口的安全问题是设计实现过程中不得不考虑的一环。
下面将列举常见的服务接口面临的安全问题与应对策略,来加固我们的服务,降低安全风险。
5.1 防 XSS
5.1.1 简介
XSS(Cross Site Scripting)名为跨站脚本攻击,因其缩写会与层叠样式表(Cascading Style Sheets,CSS)混淆,故将其缩写为 XSS。
XSS 漏洞是 Web 安全中最为常见的漏洞,通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页中,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是 JavaScript,但实际上也可以包括 Java、 VBScript、ActiveX、 Flash,甚至是普通的 HTML。攻击成功后,攻击者可能得到包括但不限于更高的权限(如执行一些操作)、私密网页内容、会话和 Cookie 等各种内容。
XSS 本质是 HTML 注入。
5.1.2 分类
XSS 攻击通常可以分为 3 类:存储型(持久型)、反射型(非持久型)、DOM 型。
存储型 XSS 危害直接。跨站代码存储在服务器,如在个人信息或发表文章的地方加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,每当有用户访问该页面的时候都会触发代码执行。
反射型 XSS 最为普遍。反射型跨站脚本漏洞,需要欺骗用户去点击链接才能触发 XSS 代码,一般容易出现在搜索页面。用户打开带有恶意代码的 URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
反射型和存储型 XSS 的区别是:存储型 XSS 的恶意代码存在数据库里,反射型 XSS 的恶意代码存在 URL 里。
基于 DOM 的 XSS 通过修改原始的客户端代码,受害者浏览器的 DOM 环境改变,导致恶意脚本的执行。也就是说,页面本身并没有变化,但由于 DOM 环境被恶意修改,有客户端代码被包含进了页面,并且意外执行。DOM 型 XSS 攻击,实际上就是网站前端 JavaScript 代码本身不够严谨,把不可信的数据当作代码执行了。
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞,而其他两种 XSS 都属于服务端的安全漏洞。
5.1.3 防御措施
通过前面的介绍可以得知,XSS 攻击有两大要素:
攻击者提交恶意代码。
浏览器执行恶意代码。
XSS 攻击主要是由程序漏洞造成的,要完全防止 XSS 安全漏洞主要依靠程序员较高的编程能力和安全意识,当然安全的软件开发流程及其他一些编程安全原则也可以大大减少 XSS 安全漏洞的发生。这些防范 XSS 漏洞原则包括:
预防存储型和反射型 XSS 攻击
存储型和反射型 XSS 都是在服务端取出恶意代码后,插入到响应 HTML 里的,攻击者刻意编写的“数据”被内嵌到“代码”中,被浏览器所执行。
预防这两种漏洞,常见做法:
输入校验。
不信任 UGC(用户提交的任何内容),对所有用户提交内容进行验证,包括对 URL、查询关键字、HTTP 头、REFER、POST 数据等,仅接受指定长度范围内、采用适当格式、采用所预期的字符的内容提交,对其他的一律过滤。
改成纯前端渲染,把代码和数据分隔开。
纯前端渲染的过程:
(1)浏览器先加载一个静态 HTML,此 HTML 中不包含任何跟业务相关的数据。
(2)然后浏览器执行 HTML 中的 JavaScript。
(3)JavaScript 通过 Ajax 加载业务数据,调用 DOM API 更新到页面上。
在纯前端渲染中,我们会明确的告诉浏览器:下面要设置的内容是文本(.innerText),还是属性(.setAttribute),还是样式(.style)等等。浏览器不会被轻易的被欺骗,执行预期外的代码了。
在很多内部、管理系统中,采用纯前端渲染是非常合适的。但对于性能要求高,或有 SEO 需求的页面,我们仍然要面对拼接 HTML 的问题。
拼接 HTML 时转义
如果拼接 HTML 是必要的,就需要采用合适的转义库,对 HTML 模板各处插入点进行充分的转义。常用的模板引擎,如 doT.js、ejs、FreeMarker 等,对于 HTML 转义通常只有一个规则,就是把& < > " ' /这几个字符转义掉,确实能起到一定的 XSS 防护作用,但并不完善。
| XSS 安全漏洞 | 简单转义是否有防护作用 |
|---|---|
| HTML 标签文字内容 | 有 |
| HTML 属性值 | 有 |
| CSS 内联样式 | 无 |
| 内联 JavaScript | 无 |
| 内联 JSON | 无 |
| 跳转链接 | 无 |
所以要完善 XSS 防护措施,我们要使用更完善更细致的转义策略。
预防 DOM 型 XSS 攻击
DOM 型 XSS 攻击,实际上就是网站前端 JavaScript 代码本身不够严谨,把不可信的数据当作代码执行了。
在使用 .innerHTML、.outerHTML、document.write() 时要特别小心,不要把不可信的数据作为 HTML 插到页面上,而应尽量使用 .textContent、.setAttribute() 等。
如果用 Vue/React 技术栈,并且不使用 v-html/dangerouslySetInnerHTML 功能,就在前端 render 阶段避免 innerHTML、outerHTML 的 XSS 隐患。
DOM 中的内联事件监听器,如 location、onclick、onerror、onload、onmouseover 等,<a>标签的 href 属性,JavaScript 的 eval()、setTimeout()、setInterval() 等,都能把字符串作为代码运行。如果不可信的数据拼接到字符串中传递给这些 API,很容易产生安全隐患,请务必避免。
- <!-- 内联事件监听器中包含恶意代码 -->
- <img onclick="UNTRUSTED" onerror="UNTRUSTED" src="data:image/png,">
-
- <!-- 链接内包含恶意代码 -->
- <a href="UNTRUSTED">1</a>
-
- <script>
- // setTimeout()/setInterval() 中调用恶意代码
- setTimeout("UNTRUSTED")
- setInterval("UNTRUSTED")
-
- // location 调用恶意代码
- location.href = 'UNTRUSTED'
-
- // eval() 中调用恶意代码
- eval("UNTRUSTED")
- </script>
如果项目中有用到这些的话,一定要避免在字符串中拼接不可信数据。
其他手段
Content Security Policy
严格的 CSP 在 XSS 的防范中可以起到以下的作用:(1)禁止加载外域代码,防止复杂的攻击逻辑。(2)禁止外域提交,网站被攻击后,用户的数据不会泄露到外域。(3)禁止内联脚本执行(规则较严格,目前发现 GitHub 使用)。(4)禁止未授权的脚本执行(新特性,Google Map 移动版在使用)。(5)合理使用上报可以及时发现 XSS,利于尽快修复问题。
HTTP-only Cookie
禁止 JavaScript 读取某些敏感 Cookie,攻击者完成 XSS 注入后也无法窃取此 Cookie。
验证码
防止脚本冒充用户提交危险操作
主动检测和发现
(1)使用通用 XSS 攻击字符串手动检测 XSS 漏洞。(2)使用扫描工具自动检测 XSS 漏洞。例如 Arachni、Mozilla HTTP Observatory、w3af 等。
5.1.4 小结
防范 XSS 是不只是服务端的任务,需要后端和前端共同参与的系统工程。虽然很难通过技术手段完全避免 XSS,但通过上面的做法可以有效减少漏洞的产生和 XSS 攻击带来的影响。
5.2 防 CSRF
5.2.1 简介
CSRF(Cross Site Request Forgery)名为跨站请求伪造,是一种挟制用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。
攻击者盗用了你的身份,以你的名义发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。
一个典型的 CSRF 攻击有着如下的流程:
受害者登录 a.com,并保留了登录凭证(Cookie)。
攻击者引诱受害者访问了 b.com。
b.com 向 a.com 发送了一个请求:a.com/act。浏览器会默认携带 a.com 的 Cookie。
a.com 接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求。
a.com 以受害者的名义执行了 act。
攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让 a.com 执行了自己定义的操作。
5.2.2 示例
假如一家银行用以运行转账操作的 URL 地址如下:
https://www.examplebank.com/withdraw?account=AccoutName&amount=1000&for=PayeeName那么,一个恶意攻击者可以在另一个网站上放置如下代码:
<img src="https://www.examplebank.com/withdraw?account=Alice&amount=1000&for=Badman">如果有账户名为 Alice 的用户访问了恶意站点,当图片被加载时,图片链接将被触发,而她之前刚访问过银行不久,登录信息尚未过期,那么她就会损失 1000 资金。
这种恶意的网址可以有很多种形式,藏身于网页中的许多地方。此外,攻击者也不需要控制放置恶意网址的网站。例如他可以将这种地址藏在论坛,博客等任何用户生成内容的网站中。这意味着如果服务端没有合适的防御措施的话,用户即使访问熟悉的可信网站也有受攻击的危险。
透过例子能够看出,攻击者并不能通过 CSRF 攻击来直接获取用户的账户控制权,也不能直接窃取用户的任何信息。他们能做到的,是欺骗用户浏览器,让其以用户的名义运行操作。
5.2.3 防御措施
CSRF 通常从第三方网站发起,被攻击的网站无法防止攻击发生,只能通过增强自己网站针对 CSRF 的防护能力来提升安全性。
上文中讲了 CSRF 的两个特点:
CSRF(通常)发生在第三方域名。
CSRF 攻击者不能获取到 Cookie 等信息,只是使用。
针对这两点,我们可以专门制定防护策略,如下:
阻止不明外域的访问 (1)同源检测 (2)Samesite Cookie
提交时要求附加本域才能获取的信息 (1)CSRF Token (2)双重 Cookie 验证
以下我们对各种防护方法做详细说明。
(1)同源检测:验证 HTTP Referer 字段。
根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。
以上文银行操作为例,Referer 字段地址通常应该是转账按钮所在的网页地址,应该也位于 www.examplebank.com 之下。而如果是 CSRF 攻击传来的请求,Referer 字段会包含恶意网址的地址,不会位于 www.examplebank.com 之下,这时候服务器就能识别出恶意的访问。
这种办法简单易行,工作量低,仅需要在关键访问处增加一步校验。但这种办法也有其局限性,因其完全依赖浏览器发送正确的 Referer 字段。虽然 HTTP 协议对此字段的内容有明确的规定,但并无法保证来访的浏览器的具体实现,亦无法保证浏览器没有安全漏洞影响到此字段。并且也存在攻击者攻击某些浏览器,篡改其 Referer 字段的可能。
(2)Samesite Cookie。为了从源头上解决这个问题,Google 起草了一份草案来改进 HTTP 协议,那就是为 Set-Cookie 响应头新增 Samesite 属性,它用来标明这个 Cookie 是个“同站 Cookie”,同站 Cookie 只能作为第一方 Cookie,不能作为第三方 Cookie,Samesite 有两个属性值,分别是 Strict 和 Lax。
Samesite=Strict 这种称为严格模式,表明这个 Cookie 在任何情况下都不可能作为第三方 Cookie。比如说 a.com 设置了如下 Cookie:
- Set-Cookie: foo=1; Samesite=Strict
- Set-Cookie: bar=2; Samesite=Lax
- Set-Cookie: baz=3
我们在 b.com 下发起对 a.com 的任意请求,foo 这个 Cookie 都不会被包含在 Cookie 请求头中,但 bar 会。
Samesite=Lax 这种称为宽松模式,比 Strict 放宽了点限制:假如这个请求是这种请求(改变了当前页面或者打开了新页面)且同时是个 GET 请求,则这个 Cookie 可以作为第三方 Cookie。比如说 a.com 设置了如下 Cookie:
- Set-Cookie: foo=1; Samesite=Strict
- Set-Cookie: bar=2; Samesite=Lax
- Set-Cookie: baz=3
当用户从 b.com 点击链接进入 a.com 时,foo 这个 Cookie 不会被包含在 Cookie 请求头中,但 bar 和 baz 会,也就是说用户在不同网站之间通过链接跳转是不受影响了。但假如这个请求是从 b.com 发起的对 a.com 的异步请求,或者页面跳转是通过表单的 post 提交触发的,则 bar 也不会发送。
(3)CSRF Token。CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 Cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 Cookie 来通过安全验证。
要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 Cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 Token,并在服务器端建立一个拦截器来验证这个 Token,如果请求中没有 Token 或者 Token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
Token 一般由服务端生成(也可以由前端生成)。一般 Token 由随机字符串和时间戳组合后通过哈希运算获得,用户首次加载页面时由服务端返回给前端。显然在提交时 Token 不能再放在 Cookie 中了,否则又会被攻击者冒用。因此,为了安全起见 ,前端在访问后台接口时,可以把 Token 放到如下三个地方:
query
header
request body
(4)双重 Cookie 验证。在会话中存储 CSRF Token 比较繁琐,而且不能在通用的拦截上统一处理所有的接口。
那么另一种防御措施是使用双重提交 Cookie。利用 CSRF 攻击不能获取到用户 Cookie 的特点,我们可以要求 Ajax 和表单请求携带一个 Cookie 中的值。
双重 Cookie 采用以下流程:
在用户访问网站页面时,向请求域名注入一个 Cookie,内容为随机字符串(例如 csrfcookie=v8g9e4ksfhw)。
在前端向后端发起请求时,取出 Cookie,并添加到 URL 的参数中(接上例 POST https://www.a.com/comment?csrfcookie=v8g9e4ksfhw)。
后端接口验证 Cookie 中的字段与 URL 参数中的字段是否一致,不一致则拒绝。
此方法相对于 CSRF Token 就简单了许多。可以直接通过前后端拦截的的方法自动化实现。后端校验也更加方便,只需进行请求中字段的对比,而不需要再进行查询和存储 Token。
5.2.4 小结
CSRF 和 XSS 完全是两种不同的 Web 攻击手段,所以有着不同的应对方法。二者的主要区别有:(1)XSS 本质是 HTML 注入,和 SQL 注入差不多,而 CSRF 则是冒充用户发起非法请求;(2)CSRF 需要用户登录后完成攻击,XSS 不需要。
5.3 防 SQL 注入
什么是 SQL 注入?SQL 注入攻击是通过将恶意的 SQL 语句插入到应用的输入参数中,再在后台 SQL 服务器上解析执行进行的攻击,它目前黑客对数据库进行攻击的最常用手段之一。
为什么要防 SQL 注入?如果用户输入的数据被构造成恶意 SQL 代码,程序又未对动态构造的 SQL 语句使用的参数进行审查,则会带来意想不到的危险。
篡改后台数据
盗取敏感信息
如何防 SQL 注入?这是开发人员应该思考的问题,作为测试人员,了解如何预防 SQL 注入,可以在发现注入攻击 Bug 时,对 Bug 产生原因进行定位。
严格检查输入变量的类型和格式。对于整数参数,加判断条件:不能为空、参数类型必须为数字。对于字符串参数,可以使用正则表达式进行过滤:如 [0-9a-zA-Z] 范围内的字符串。
过滤和转义特殊字符。对用户输入的 SQL 参数进行转义,如
' " / * #等特殊字符。使用参数化查询(Parameterized Query)而非手动拼接 SQL。不仅可以防止 SQL 注入,还可以避免重复编译 SQL 带来性能提升。具体是怎样防止 SQL 注入的呢?实际上当将绑定的参数传到 MySQL 服务器,MySQL 服务器对参数进行编译,即填充到相应的占位符的过程中,做了转义操作。
5.4 防刷
为什么要防刷?
后台服务接口都应该有一个合理的请求速度,尤其对于来自真人请求的接口,如果单个用户短时间内对某个接口的请求量很大,很有可能接口被恶意强刷或客户端请求逻辑有问题。
比如 IM 应用中的加好友请求,正常用户请求频次不会超过 1/s。如果每秒钟有 10+ 次加好友的请求,那么说明接口很有可能被刷了。
接口被刷,不管是读还是写接口,都会对后台服务造成巨大压力,严重的可能会导致服务不可用。
所以,我们应该对接口做适当的限频,提早拒绝非法请求。
如何防刷?
可以通过接口限频来应对被刷。接口请求频次的统计一般有如下维度:
基于用户 ID
基于 IP
基于设备 ID
每个接口应该有不同的合理阈值,这个需要结合具体的业务场景来定。
这个功能为服务接口的公共功能,建议做在网关层或单独的安全层。
5.5 防篡改
什么是篡改?在一次客户端与服务端的请求过程中,从请求方到接收方中间要经过很多路由器和交换机,黑客可以在中途截获请求的数据,篡改请求内容后再发往服务端,比如中间人攻击。假设在一个网上存款系统中,一条消息表示用户的一笔转账,攻击者完全可以多次将收款账号改为自己的账号后再将请求发到服务端。
为什么要防篡改?假如客户端与服务端采用的是 HTTPS 协议,虽然 HTTPS 协议可以将传输的明文进行加密,但是黑客仍然可以截获传输的数据包,进一步伪造请求进行重放攻击。如果黑客使用特殊手段让请求方设备使用了伪造的证书进行通信,那么 HTTPS 加密的内容也会被解密。
在 API 接口中我们除了使用 HTTPS 协议进行通信外,还需要有自己的一套加解密机制,对请求的参数进行保护,防止被篡改。
如何防篡改?对请求包进行签名可以有效的防篡改。
具体过程如下:
客户端使用约定好的秘钥对传输的参数进行加密,得到签名值 signature1,一般使用 HMAC
客户端将签名值也放入请求的参数中,发送请求给服务端。
服务端接收到客户端的请求,然后使用约定好的秘钥对请求的参数再次进行签名,得到签名值 signature2。
服务端比对 signature1 和 signature2 的值,如果对比一致,认定为合法请求。如果对比不一致,说明参数被篡改,为非法请求。
因为黑客不知道签名的密钥,所以即使截取到请求数据,对请求参数进行篡改,但是却无法对参数进行签名,无法得到修改后参数的签名值 signature。
5.6 防重放
什么是重放?如果恶意用户抓取真实的接口请求包,不停地发起重复请求,这就是对接口的重放。
为什么要重放?接口重放一般是针对写接口的恶意请求,读接口不会有什么影响。比如发帖,发消息这种写接口,如果不防重放,会出现很多垃圾内容和骚扰消息。
如何防重放?防重放的目的是不允许让相同内容的请求重复发起。对于一个具体的请求,我们可以限制某个请求的生命周期,如果超过其生命周期,认定为非法请求,这样便起到了防重放的效果。
具体做法是:
客户端基于"请求内容+时间戳+密钥"计算一个签名 signature1,一般使用 HMAC。
客户端请求后台接口时带上签名 signature1。
后台拿到签名后,会使用相同的算法计算出一个签名与前端带来的签名做比较,如果不一致,说明请求非法,直接拒绝。
因为黑客不知道签名秘钥,没有办法生成新的签名。
以上做法需要注意几个问题:
签名计算使用的算法可能会被坏人破解。因为对于 APP 或桌面应用,坏人可以反汇编获取。
签名计算时使用密钥需要保存在客户端本地,可能会有泄露的风险。因为对于 APP 或桌面应用,坏人可以反汇编获取。
终端使用的时间戳是由后台返回的,这样防止前后端的本地时间不一致导致生成的签名。
不适用于 Web 应用,坏人是可以直接查看网页源码获取签名计算使用的算法和密钥。
如果要严格做到一段时间内某个请求只能被请求一次,需要对请求进行次数的统计,会用到后台存储,实现起来会复杂一点。不过一般不需要这么做。
这个功能为服务接口的公共功能,建议做在网关层或单独的安全层。
5.7 防 DDoS
什么是 DDoS 攻击?DDoS(Distributed Denial of Service)是分布式拒绝服务攻击,攻击者利用分散在各地的设备发出海量实际上并不需要的互联网流量,耗尽目标的资源,造成正常流量无法到达其预定目的地或目标服务被压垮无法提供正常服务。
可能我举个例子会更加形象点。
我开了一家有五十个座位的重庆火锅店,由于用料上等,童叟无欺。平时门庭若市,生意特别红火,而对面二狗家的火锅店却无人问津。二狗为了对付我,想了一个办法,叫了五十个人来我的火锅店坐着却不点菜,让别的客人无法吃饭。上面这个例子讲的就是典型的 DDoS 攻击。一般来说是指攻击者利用“肉鸡”对目标网站在较短的时间内发起大量请求,大规模消耗目标网站的主机资源,让它无法正常服务。因为“肉鸡”分散在各地,有分布式的特性,所以叫分布式拒绝服务攻击。
在线游戏、互联网金融等领域是 DDoS 攻击的高发行业。
为什么要防 DDoS?DDoS 攻击带来的危害轻微的会降低目标服务的质量,增加响应延迟,严重的直接导致目标服务崩溃,无法提供服务。所以必须要防 DDoS 攻击。
常见的 DDoS 攻击有哪些?
网络层攻击
(1)ICMP Flood 攻击。ICMP Flood 攻击属于流量型的攻击方式,是利用大的流量给服务器带来较大的负载,影响服务器的正常服务。由于目前很多防火墙直接过滤 ICMP 报文。因此 ICMP Flood 出现的频度较低。
(2)UDP 反射攻击 DNS 反射攻击是一种常见的攻击媒介,网络犯罪分子通过伪装其目标的 IP 地址,向开放的 DNS 服务器发送大量请求。作为回应,这些 DNS 服务器通过伪造的 IP 地址响应恶意请求,大量的 DNS 答复形成洪流,从而构成预定目标的攻击。很快,通过 DNS 答复产生的大量流量就会造成受害企业的服务不堪重负、无法使用,并造成合法流量无法到达其预定目的地。
如 NTP Flood 攻击,这类攻击主要利用大流量拥塞被攻击者的网络带宽,导致被攻击者的业务无法正常响应客户访问。
传输层攻击
(1)SYN Flood 攻击。SYN Flood 攻击是当前网络上最为常见的 DDoS 攻击,它利用了 TCP 协议实现上的一个缺陷。通过向网络服务所在端口发送大量的伪造源地址的攻击报文,就可能造成目标服务器中的半连接队列被占满,从而阻止其他合法用户进行访问。
(2)Connection Flood 攻击。Connection Flood 是典型的利用小流量冲击大带宽网络服务的攻击方式,这种攻击的原理是利用真实的 IP 地址向服务器发起大量的连接。并且建立连接之后很长时间不释放,占用服务器的资源,造成服务器上残余连接(WAIT 状态)过多,效率降低,甚至资源耗尽,无法响应其他客户所发起的链接。
(3)UDP Flood 攻击。UDP Flood 是日渐猖厥的流量型 DDoS 攻击,原理也很简单。常见的情况是利用大量 UDP 小包冲击 DNS 服务器或 Radius 认证服务器、流媒体视频服务器。由于 UDP 协议是一种无连接的服务,在 UDP Flood 攻击中,攻击者可发送大量伪造源 IP 地址的小 UDP 包。
会话层攻击
(1)SSL 连接攻击。比较典型的攻击类型是 SSL 连接攻击,这类攻击占用服务器的 SSL 会话资源从而达到拒绝服务的目的。
应用层攻击
(1)HTTP Get 攻击。和服务器建立正常的 TCP 连接之后,不断地向后端服务接口发起 Get 请求,压垮后台服务。这种攻击的特点是可以绕过普通的防火墙防护,可通过 Proxy 代理实施攻击。
(2)UDP DNS Query Flood 攻击 UDP DNS Query Flood 攻击采用的方法是向被攻击的服务器发送大量的域名解析请求,通常请求解析的域名是随机生成或者是网络世界上根本不存在的域名。域名解析的过程给服务器带来了很大的负载,每秒钟域名解析请求超过一定的数量就会造成 DNS 服务器解析域名超时。
如何防 DDoS?DDoS 防御是保障系统安全运行的必要举措,虽然不属于服务接口层面需要考虑的事情,但是知道相关的防御措施还是很有必要的。
防御 DDoS 攻击的策略方法,包括但不限于:
(1)定期检查服务器漏洞。定期检查服务器软件安全漏洞,是确保服务器安全的最基本措施。无论是操作系统(Windows 或 linux),还是网站常用应用软件(mysql、Apache、nginx、FTP 等),服务器运维人员要特别关注这些软件的最新漏洞动态,出现高危漏洞要及时打补丁修补。
(2)隐藏服务器真实 IP。通过 CDN 节点中转加速服务,可以有效的隐藏网站服务器的真实 IP 地址。CDN 服务根据网站具体情况进行选择,对于普通的中小企业站点或个人站点可以先使用免费的 CDN 服务,比如百度云加速、七牛 CDN 等,待网站流量提升了,需求高了之后,再考虑付费的 CDN 服务。
其次,防止服务器对外传送信息泄漏 IP 地址,最常见的情况是,服务器不要使用发送邮件功能,因为邮件头会泄漏服务器的 IP 地址。如果非要发送邮件,可以通过第三方代理(例如 sendcloud)发送,这样对外显示的 IP 是代理的 IP 地址。
(3)关闭不必要的服务或端口。这也是服务器运维人员最常用的做法。在服务器防火墙中,只开启使用的端口,比如网站 Web 服务的 80 端口、数据库的 3306 端口、SSH 服务的 22 端口等。关闭不必要的服务或端口,在路由器上过滤假 IP。
(4)购买高防服务器提高承受能力。该措施是通过购买高防的盾机,提高服务器的带宽等资源,来提升自身的承受攻击能力。一些知名 IDC 服务商都有相应的服务提供,比如阿里云、腾讯云等。但该方案成本预算较高,对于普通中小企业甚至个人站长并不合适,且不被攻击时造成服务器资源闲置,所以这里不过多阐述。
(5)限制 SYN/ICMP 流量。用户应在路由器上配置 SYN/ICMP 的最大流量来限制 SYN/ICMP 封包所能占有的最高频宽。这样,当出现大量的超过所限定的 SYN/ICMP 流量时,说明不是正常的网络访问,而是有黑客入侵。早期通过限制 SYN/ICMP 流量是最好的防范 DOS 的方法,虽然目前该方法对于 DDoS 效果不太明显了,不过仍然能够起到一定的作用。
(6)黑名单。对于恶意流量,将 IP 或 IP 段拉黑。
(7)DDoS 清洗。DDoS 清洗会对用户请求数据进行实时监控,及时发现 DOS 攻击等异常流量,在不影响正常业务开展的情况下清洗掉这些异常流量。
(8)CDN 加速。CDN 指的是网站的静态内容分发到多个服务器,用户就近访问,提高速度。因此,CDN 也是带宽扩容的一种方法,可以用来防御 DDoS 攻击。
5.8 小结
道高一尺,魔高一丈,没有绝对的安全,我们能做的就是尽可能地提高坏人作恶的门槛,让我们的系统变得更加安全可靠。
6.小结
好的服务是设计出来的,而不是维护出来的。
优秀的设计原则告诉我们如何写出好的服务来应对千变万化的业务场景。
所有事物都不是 100% 可靠的,服务亦是如此,但遵守优秀的设计原则让我们的服务距离 100% 可靠更近一步。
参考文献
Google Cloud API Desgin Guide
知乎.怎么理解软件设计中的开闭原则?
微服务的 4 个设计原则和 19 个解决方案
博客园.如何健壮你的后端服务?
高可用的本质
一文搞懂后台高性能服务器设计的常见套路, BAT 高频面试系列
【架构】高可用高并发系统设计原则
CAP 定理的含义 - 阮一峰的网络日志
CAP 理论该怎么理解?为什么是三选二?为什么是 CP 或者 AP?面试题有哪些?
mmap 详解
Base: An Acid Alternative
Cache Usage Patterns - Ehcache
Securing APIs: 10 Ways to Keep Your Data and Infrastructure Safe
前端安全系列(一):如何防止 XSS 攻击?
前端安全系列(二):如何防止 CSRF 攻击?
SQL 注入攻击常见方式及测试方法 | CSDN 博客
API 接口设计:防参数篡改+防二次请求 | 腾讯云
什么是 DDoS 攻击?| 知乎
DDoS 攻击是什么? 如何防止 DDos 攻击?| SegmentFault

0基础,学IT,月薪过万
就来黑马程序员
8大学科火热开班中
现在报名基础班,仅需 28 元
扫码咨询,抢优惠名额

咨询线上课程
可以直接添加播妞解答哦


丨热门教程资源丨
回复【领取资源】领《黑马8学科汇总教程》
回复【spring1】领《Spring系列课》
回复【瑞吉外卖】领《瑞吉外卖项目》
回复【SSM】领《SSM框架教程》
回复【mysql1】领《Mysql入门到精通》
更多教程加播妞领取:heiniu526
(在下方公众号回复对应关键词,即可领取哦)
↓↓↓

- 原本是这样写的,控制台就会报标题的错误
[详细] -->赞
踩

