
热门标签
热门文章
- 1都说B站难爬?这也不难!_为什么爬虫爬不到哔哩哔哩的
- 2ios浏览器 图片size过大(长度6000px) 设置translateZ(0)/translate3d(0,0,0),会模糊
- 3编写一个脚本,可以定时5分钟关闭Windows系统
- 4蓝桥杯51单片机LED控制_按键按下速度控制led的亮
- 5T265学习之路(1)---环境搭配及Realsense_viewer安装_realsense-viewer
- 6Codeforces 296D. Greg and Graph (Floyd)_n distinct integers 1 , 2 , … , x 1 ,x 2 ,
- 7python雷达成像(SAR)仿真:(三)徙动校正+方位压缩(完结)_sar方位向压缩
- 8数据优先于模型:默默无闻的英雄们,他们解锁了真正的AI成果
- 9Docker:(七)dockerfile优化小技巧_dockerfile 构建镜像优化
- 10【软考系统规划与管理师笔记】第7篇 IT服务运营管理_系统规划与管理师 运营管理
当前位置: article > 正文
[Pandas] 数据追加 df.append
作者:知新_RL | 2024-02-08 15:28:39
赞
踩
df.append
df.append()可以将其他DataFrame附加到调用方的末尾,并返回一个新对象
它是最简单、最常用的数据合并方式
语法
df.append(other, ignore_index=False, verify_integrity=False, sort=False)参数
other:调用方要追加的其他DataFrame或者类似序列内容。可以放入一个由DataFrame组成的列表,将所有DataFrame追加起来
ignore_index:如果为True,则重新进行自然索引
verify_integrity:如果为True,则遇到重复索引内容时报错
sort:进行排序
1.相同结构
如果数据的字段相同,直接使用第一个DataFrame的append()方法,传入第二个DataFrame。如果需要追加多个DataFrame,可以将它们组成一个列表再传入
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
- res1 = df1.append(df2)
- # 追加多个数据
- res2 = df1.append([df2,df2,df2])
结果展示
df1
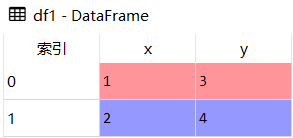
df2
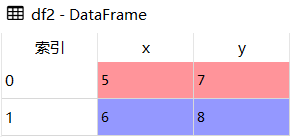
res1
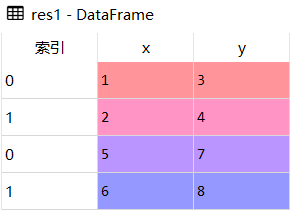
res2
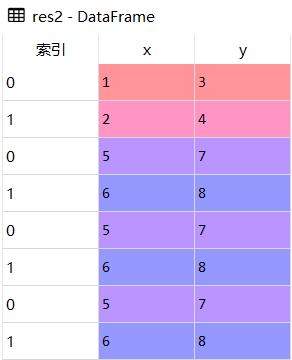
2.不同结构
对于不同结构的追加,一方有而另一方没有的列会增加,没有内容的位置用NaN填充
- import pandas as pd
-
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df3 = pd.DataFrame({'y':[5,6],'z':[7,8]})
- # 追加合并
- res = df1.append(df3)
结果展示
df1
df3

res

3.忽略索引
追加操作索引默认为原数据的,不会改变,如果需要忽略,可以传入ignore_index = True
- import pandas as pd
-
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
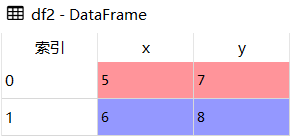
- df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
- # 忽略索引
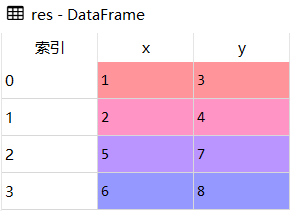
- res = df1.append(df2, ignore_index=True)
结果展示
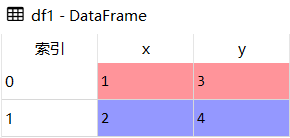
df1
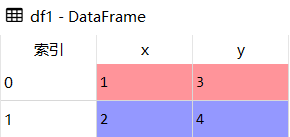
df2
res
4.重复内容
重复内容默认是可以追加的,如果传入verify_integrity = True参数和值,则会检测追加内容是否重复,如有重复会报错
- import pandas as pd
- df1 = pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2 = pd.DataFrame({'x':[5,6],'y':[7,8]})
- # 合并两个相同的内容(报错)
- df1.append([df2,df2], verify_integrity=True)
结果展示
df1
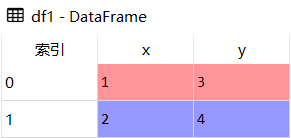
df2

5.追加序列
append()除了追加DataFrame外,还可以追加一个Series,经常用于数据添加更新场景
- import pandas as pd
-
- df = pd.DataFrame([['liver','E',89,21,24,64],
- ['Arry','C',36,37,37,57],
- ['Ack','A',57,60,18,84],
- ['Eorge','C',93,96,71,78],
- ['Oah','D',65,49,61,86]
- ],
- columns = ['name','team','Q1','Q2','Q3','Q4'])
- # 定义新同学的信息
- lily = pd.Series(['lily','C',55,56,57,58],
- index=['name','team','Q1','Q2','Q3','Q4'])
- # 追加
- df = df.append(lily, ignore_index=True)
结果展示
原df

lily
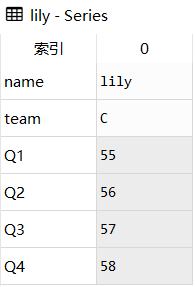
新df

6.追加字典
append()还可以追加字典
- import pandas as pd
-
- df = pd.DataFrame([['liver','E',89,21,24,64],
- ['Arry','C',36,37,37,57],
- ['Ack','A',57,60,18,84],
- ['Eorge','C',93,96,71,78],
- ['Oah','D',65,49,61,86]
- ],
- columns = ['name','team','Q1','Q2','Q3','Q4'])
-
- # 将学生信息定义为一个字典
- lily = {'name':'lily','team':'C','Q1':55,'Q2':56,'Q3':57,'Q4':58}
- df = df.append(lily, ignore_index=True)
结果展示
原df

lily

新df

扩展练习案例
- import pandas as pd
- df_list = []
-
- df1 = pd.DataFrame([['A',1]],columns = ['Site','number'])
- df_list.append(df1)
-
- df2 = pd.DataFrame([['B',2]],columns = ['Site','number'])
- df_list.append(df2)
-
- df_all = pd.concat([df1,df2])
-
- df3 = pd.DataFrame([['C',3]],columns = ['Site','number'])
- df_list.append(df3)
-
- df_all = pd.concat(df_list)
- df_all = df_all.reset_index(drop=True)
df1
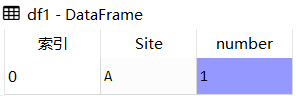
df2
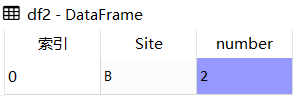
df3
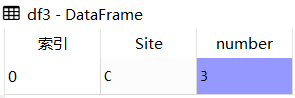
df_all
df_list
![]()
推荐阅读
相关标签

