- 1uniapp支付宝支付_uni . tradepay
- 2Edge WebDriver环境的搭建_edge浏览器驱动如何安装
- 3前端项目常用函数封装(二)_前端封装
- 4深度学习与生成式预训练Transformer:未来的发展趋势_pre-trained transformer
- 5【测试】无测试组织:测试团队的敏捷转型_无测试组织:测试团队的敏捷转型
- 6自然语言处理NLP之文本摘要、机器翻译、OCR、信息检索、信息抽取、校对纠错_nlp校对
- 7关于实现uni-app项目在APP端使用微信支付功能_uniapp app微信支付
- 8最新AI创作系统ChatGPT网站源码Midjourney-AI绘画系统,GPT4-All联网搜索提问模型,Suno-v3-AI音乐生成大模型_最新ai智能问答网站源码
- 9Swin Transformer各层特征可视化_transformer 可视化
- 10Vivado使用技巧(14):IO规划方法详解_vivado io planning
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练_bart模型做中文文本生成
赞
踩
论文地址:https://arxiv.org/pdf/1910.13461.pdf
相关博客
【自然语言处理】【文本生成】CRINEG Loss:学习什么语言不建模
【自然语言处理】【文本生成】使用Transformers中的BART进行文本摘要
【自然语言处理】【文本生成】Transformers中使用约束Beam Search指导文本生成
【自然语言处理】【文本生成】Transformers中用于语言生成的不同解码方法
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练
【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
自监督方法在广泛的自然语言处理任务中取得了巨大的成功。大多数成功的方法都是masked language model的变体,其是一种降噪自编码器,通过重构随机遮蔽的单词进行训练。最近的研究展示了改变遮蔽tokens分布、被预测遮蔽token的顺序、以及替换遮蔽token的可用上下文的有效性。然而,这些方法都专注在特定类型的任务,限制了它们的适用性。
在本文中提出了
BART
\text{BART}
BART,其合并了双向和自回归
Transformers
\text{Transformers}
Transformers。
BART
\text{BART}
BART是一个使用sequence-to-sequence模型构建的降噪自编码器,其能够应用在广泛的下游任务。预训练有两个阶段:(1) 使用任意噪音函数破坏文本;(2) 通过重构原始文本学习的sequence-to-sequence模型。
BART
\text{BART}
BART使用标注基于
Transformer
\text{Transformer}
Transformer的神经机器翻译架构,尽管监督,其可以看做是
BERT(双向编码器)
\text{BERT(双向编码器)}
BERT(双向编码器)和
GPT(left-to-right decoder)
\text{GPT(left-to-right decoder)}
GPT(left-to-right decoder)的推广。
这种设置的关键优势是噪音的灵活性,可以对原始文本做任意的变换,包括改变长度。作者评估了一些噪音方法,发现最好的表现是通过随机打乱原始句子的顺序和使用新颖的填充方案,任意跨度的文本被单个mask token替换。该方法通过强制模型对整个句子长度进行更多的推理,并对输入进行更大范围的转换,从而推广了
BERT
\text{BERT}
BERT中的
MLM
\text{MLM}
MLM和
NSP
\text{NSP}
NSP。
BART
\text{BART}
BART用于文本生成微调时非常有效,并且对于理解任务也是有效的。其能在
GLUE
\text{GLUE}
GLUE和
SQuAD
\text{SQuAD}
SQuAD上媲美
RoBERTa
\text{RoBERTa}
RoBERTa,并且能够在问题、摘要等任务上实现state-of-the-art。
BART
\text{BART}
BART也为微调打开了新思路。提出了一个机器翻译的新思路,
BART
\text{BART}
BART模型被堆叠在几个额外的
transformer
\text{transformer}
transformer层。通过
BART
\text{BART}
BART传播,这些层被用于将外语翻译为噪音英文,从而使
BART
\text{BART}
BART作为目标端语言模型。
为了更好的理解这些影响,作者报告了消融分析,该分析复现了近期提出的其他训练目标函数。这些研究允许仔细控制一些因素,包括数据和优化参数,其以及被证明对整体的表现同训练目标函数的选择同样重要。
二、模型
1. 架构
BART
\text{BART}
BART使用标准的sequence-to-sequence
Transformer
\text{Transformer}
Transformer架构的形式,除了遵循
GPT
\text{GPT}
GPT,将
ReLU
\text{ReLU}
ReLU激活函数修改为
GeLUs
\text{GeLUs}
GeLUs和从
N
(
0
,
0
,
02
)
\mathcal{N}(0,0,02)
N(0,0,02)中初始化的参数。对于
base
\text{base}
base模型,使用6层的encoder和decoder,对于
large
\text{large}
large模型则使用12层。该架构与
BERT
\text{BERT}
BERT使用的比较接近,但具有如下的不同:(1) 解码器的每一层在编码器最后的hidden层执行交叉注意力;(2)
BERT
\text{BERT}
BERT在单词预测前添加一个额外的feed-forward network。总的来说,
BART
\text{BART}
BART比同等大小的
BERT
\text{BERT}
BERT多包含10%的参数。
2. 预训练 BART \text{BART} BART
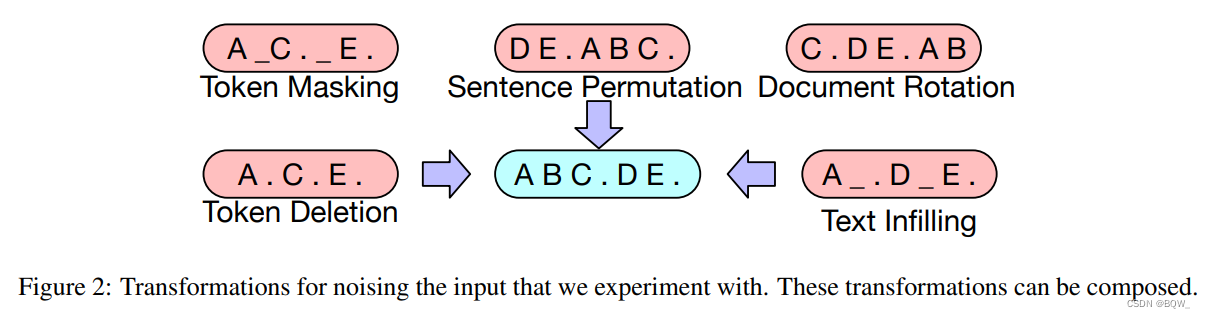
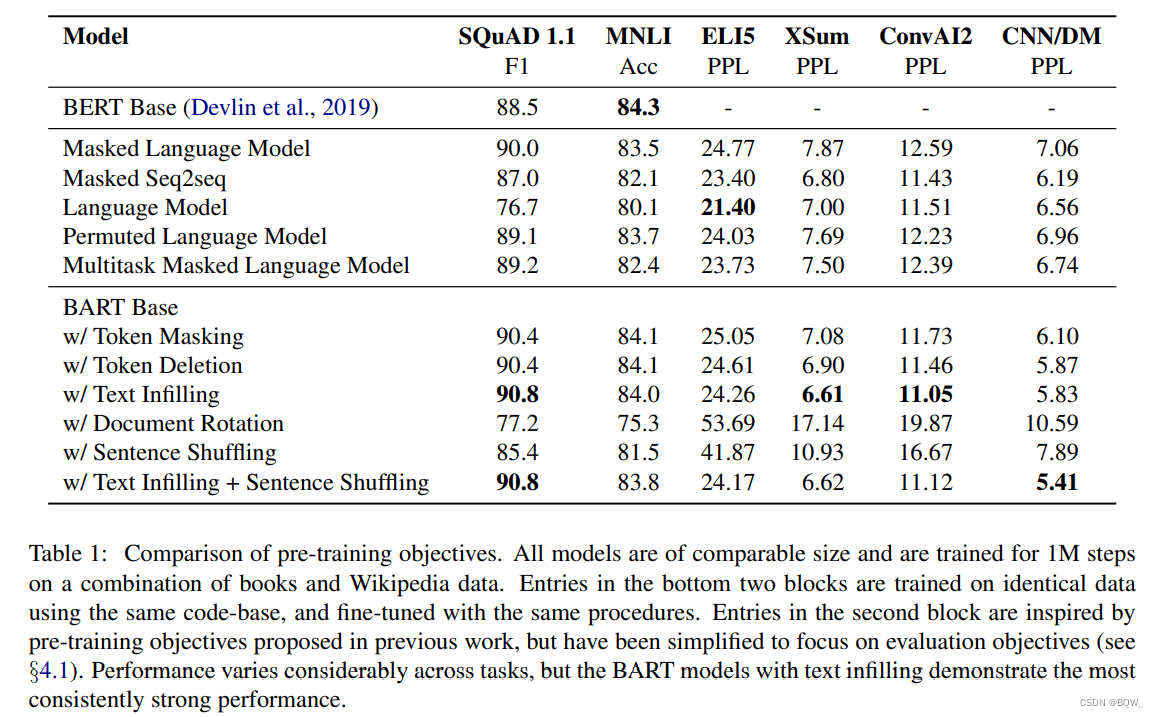
BART \text{BART} BART通过损坏文档,然后优化重构损失函数来进行训练,这个重构损失函数就是解码器输出和原始文本的交叉熵。不同于现有的降噪自编码器,这些编码器是针对特定噪音方案定制的, BART \text{BART} BART允许应用任何类型的文档噪音。在极端场景中,所有关于源的信息都丢失, BART \text{BART} BART等价于一个语言模型。
作者对先前提出的和新的变换方式进行实验,但是作者认为开发新的替代方案具有更大的潜力。
-
Token Masking
遵循 BERT \text{BERT} BERT,采样随机的
tokens并使用[MASK]进行替换。 -
Token Deletion
随机删除输入中的
tokens。相比于token masking,模型必须决定哪些位置缺失输入。 -
Text Infilling
从输入中采样文本片段,片段的长度来自 Poisson \text{Poisson} Poisson分布。每个文本片段被替换为一个单独的
[MASK]。长度为0的片段对应于插入[MASK]操作。 Text Infilling \text{Text Infilling} Text Infilling是受 SpanBERT \text{SpanBERT} SpanBERT启发,但是 SpanBERT \text{SpanBERT} SpanBERT是从不同的分布采样的片段长度,并且以等长的[MASK]序列来替换片段。 Text infilling \text{Text infilling} Text infilling教模型来预测一个片段缺失的tokens数量。 -
Sentence Permutation
一个文档按照句号划分为句子,这些句子按随机的顺序进行排列。
-
Document Rotation
等概率随机选择一个
token,然后文本被选择以该token为开头。
三、微调 BART \text{BART} BART
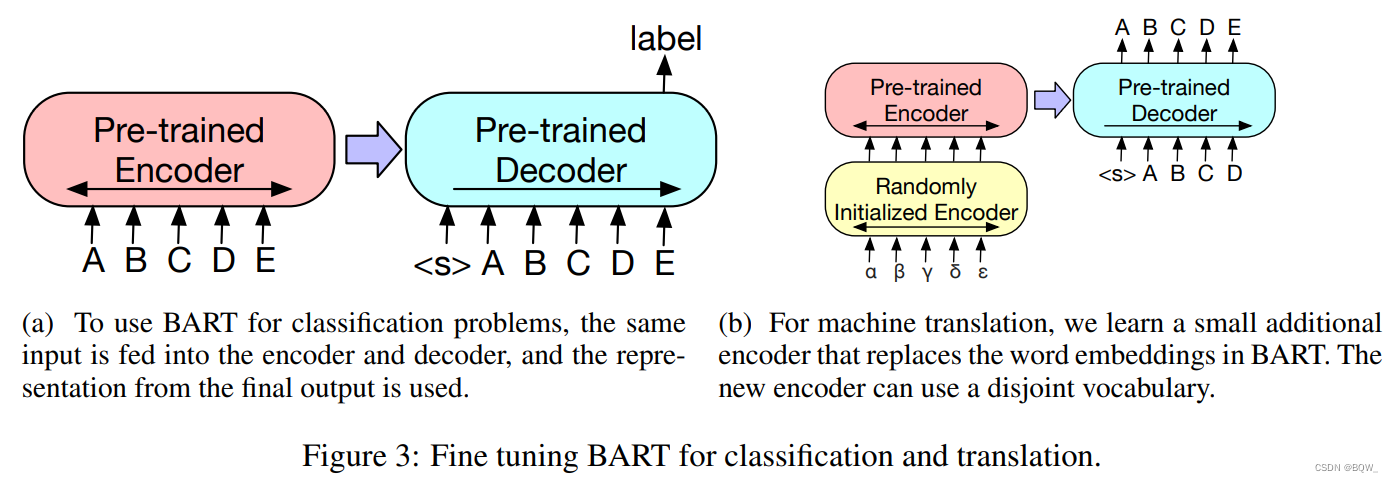
1. 序列分类任务
对于序列分类任务,相同的输入被送入至编码器和解码器,最终的解码器token的hidden state被送入至新的多类别线性层。这种方法与
BERT
\text{BERT}
BERT的CLS类似。如上图所示。
2. Token分类任务
对于token分类任务,将完整的文档送入至编码器和解码器,使用解码器顶端的hidden state来作为每个单词的表示。这个表示被用于分类token。
3. 序列生成任务
由于 BART \text{BART} BART是自回归解码器,其能够直接微调来进行序列生成任务,例如:问答和摘要。在这两个任务中,从输入中复制信息并进行操作,其与降噪预训练目标比较接近。这里,编码器的输入就是输入序列,并且解码器自回归地生成输出。
4. 机器翻译
作者也探索了使用 BART \text{BART} BART来改善机器翻译的解码器。先前的工作展示,模型能够通过合并预训练编码器来进行改善,但是解码器中使用预训练语言模型的收益有限。作者展示了使用整个 BART \text{BART} BART模型作为单个预训练解码器用于机器翻译的可能,通过添加一个新的编码器参数。如上图所示。
四、实验