
- 1Chainlit系列02- 开发入门聊天应用_chainlit部署
- 2EndNote 、GB/T 7714格式参考文献、文献标题有%J(附安装包)_gbt7714.ens
- 3VSCode 开发C/C++实用插件分享——codegeex_vscode c+调用图插件
- 4python+基于Python的资产管理系统 毕业设计-附源码201117_基于python的资产管理系统源码
- 5ChatGPT 提问攻略:从基础到精通,掌握AI对话的艺术_你用过chartgpt之类的ai工具吗,一般用于提问什么类型的问题呢
- 6ROS基础系列总结_ros机器人开发基础报告
- 7小程序的登录+发布流程_微信小程序开发流程csdn
- 8Vulkan填坑学习Day27-2—多采样抗锯齿(多重采样_Multisampling)_vulkan抗锯齿失效
- 9Mybatis Plus 数据分片-水平分库分表策略_mybatisplus分库分表
- 10Mac 安装Nodejs及NPM常见问题_mac 安装npm
机器学习——决策树算法_机器学习根据以下数据,产生决策树并用代码进行验证,贷款申请样本数据表
赞
踩
一、实验目的
掌握如何实现决策树算法,用并决策树算法完成预测。
二、实验内容
本次实验任务我们使用贷款申请样本数据表,该数据表中每列数据分别代表ID、年龄、高薪、有房、信贷情况、类别,我们根据如下数据生成决策树,使用代码来实现该决策树算法。
三、实验原理或流程
实验原理:
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy =系统的凌乱程度,使用算法ID3,C4.5和C5.0生成树算法使用嫡。这一度量是基于信息学理论中嫡的概念。
决策树的算法原理
(1)找到划分数据的特征,作为决策点
(2)利用找到的特征对数据进行划分成n个数据子集。
(3)如果同一个子集中的数据属于同一类型就不再划分,如果不属于同一类型,继续利用特征进行划分。
(4))指导每一个子集的数据属于同一类型停止划分。
2、决策树的优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关的特征数据
缺点:可能产生过度匹配的问题
四、实验过程及源代码
1.构建决策树如下:

该决策树的结构,可以用字典表示为:
{'有自己的房子':{0:{'有工作':{O: 'no',1: 'yes'}},1 : 'yes'}}
接下来我们编写python代码来递归构建决策树。
2.打开Pycharm,新建项目,项目位置名称:/data/Test
 编译器选择python3.5,如下图所示,然后点击OK:
编译器选择python3.5,如下图所示,然后点击OK:

 3.在项目名Test下,创建Python File文件。
3.在项目名Test下,创建Python File文件。
4.创建以dectree命名的文件。
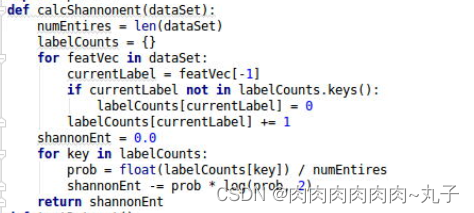
 5.打开dectree.py文件,编写代码构建决策树。
5.打开dectree.py文件,编写代码构建决策树。
(1)计算数据集的香农嫡。
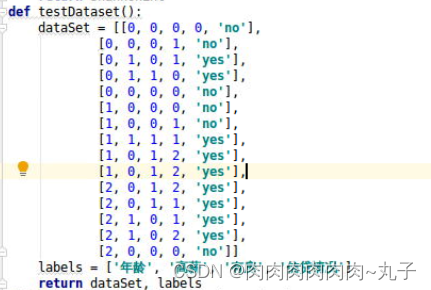
(2)创建测试数据集。
(3)创建函数splitDataset,按照特征划分数据集。
(dataSet:待划分的数据集,axis:划分数据集的特征,value:需要返回的特征值)

(4)选择最优特征。

(5)统计classList中出现次数最多的元素(类标签)。

(6)创建决策树。

6.右键,选择Run 'dectree',运行程序。
运行结果如下:

7.接下来我们用上述已经训练好的决策树做分类,只需要提供这个人是否有房,是否是高薪工作这两个信息即可。我们在dectree.py文件中添加一个classify函数,代码如下:

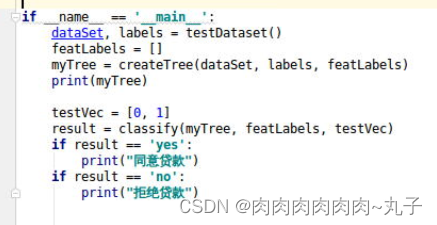
8.最后我们在dectree.py文件中的main函数中,输入测试数据[0,1],它代表没房,但是有高薪工作,该函数完整代码如下:
9.然后在dectree.py文件中右键,选择Run 'dectree',运行程序。
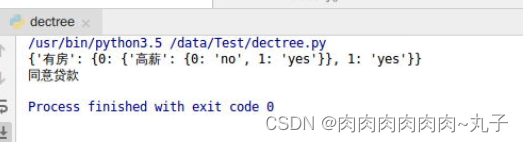
根据运行结果,我们得知会同意贷款给这个人。
五、实验结论及心得
实验结论:
本次实验中,我们使用决策树对贷款申请样本数据进行了分类和预测。通过建立决策树模型,我们可以根据不同的特征属性对个体进行分类,判断其是否符合贷款资格的要求。通过对实验结果的观察,可以得出以下结论:高薪、有房和信贷情况是影响贷款申请通过与否的重要因素;在这些因素相同的情况下,年龄越大的人更容易获得贷款资格。同时,我们也需要注意在训练决策树模型时避免过拟合现象的发生,需要对数据集进行合理分割和调整参数。总之,决策树是一种简单而有效的机器学习方法,可以应用于多个领域。
心得体会:
学习决策树的过程中,我深刻认识到了这种机器学习算法的优点和不足。决策树具有模型简单、易于理解、可解释性强等特点,在数据挖掘、分类预测等领域有着广泛的应用。但同时也存在一些缺点,如容易出现过拟合、对异常值敏感等问题。因此,在使用决策树时需要对数据进行充分的处理和清洗,采用剪枝和交叉验证等方法来避免过拟合现象的发生。此外,还需要注意选择合适的评估指标和调整参数来优化模型性能。总之,学习决策树不仅可以帮助我们更好地理解机器学习的基本原理,也有助于我们在实际应用中轻松构建高效的分类模型。

