
- 1Centos7.4下gitlab迁移及通过docker启动gitlab服务_gitlab docker 迁移后重启
- 2计算机运维方向要考什么证,IT运维项目经理考的证
- 3mongodb创建用户
- 4大模型日报|今日必读的 13 篇大模型论文_hipporag
- 5【Python】Linux下载并安装Python 3.10版本_linux安装python3.10
- 6TCP协议和UDP协议的首部格式与连接过程
- 7给定两个数组,编写一个函数来计算它们的交集。_函数中两个数组能计算吗
- 8单臂路由和三层交换的基础理论+实验配置全解(详细)_dotlq
- 9Mysql索引底层数据结构——Java全栈知识(28)
- 10Spring Security PBKDF2_spring.security.crypto:6.2.4中,请给出使用pbkdf2passworde
零拷贝原理+kafka中的零拷贝_kafka零拷贝
赞
踩
kafka性能之零拷贝
kafka中的零拷贝并不是说完全避免了上下文切换与cpu拷贝的次数, 而是减少这种拷贝次数
传统IO
传统的一次IO流程
read: 数据从磁盘读取到内核缓冲区, 然后从内核缓冲区拷贝到用户缓冲区
write: 数据从用户缓冲区写入socket缓冲区, 然后写入网卡设备
- read之后, 也即向操作系统发出IO调用, 用户态切换到内核态
- DMA拷贝数据从硬盘到内核缓冲区
- CPU拷贝内核缓冲区数据到用户缓冲区, 内核态切换到用户态
- write之后, 也即发起IO调用, 用户态切换到内核态
- CPU拷贝用户缓冲区数据到socket缓冲区
- DMA拷贝socket缓冲区到网卡设备, 内核态切换到用户态
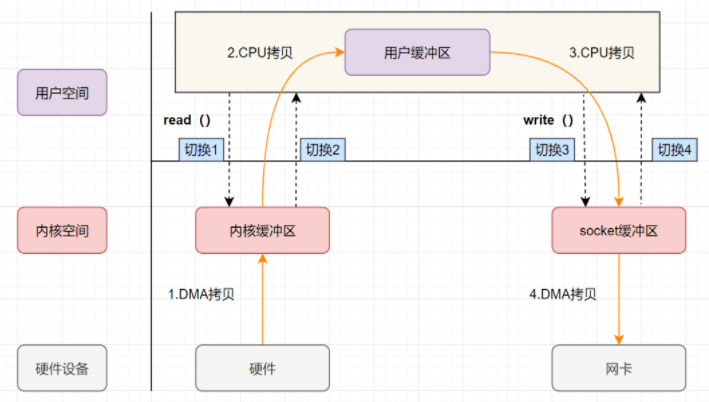
- 上述过程可以看出有4次上下文切换, 4次拷贝. 其实这个地方可以优化, 我们把数据拷贝到用户缓冲区再从用户缓冲区拿出数据到socket纯属多此一举, 如果有一种操作直接可以把数据从内核缓冲区到socket缓冲区的话, 就能减少拷贝操作了
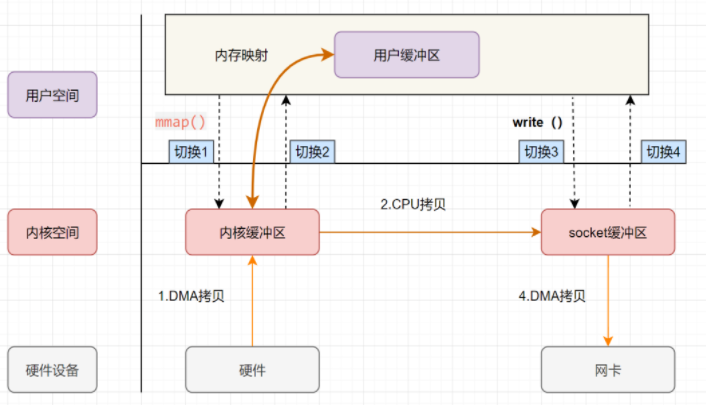
零拷贝mmp优化
mmp优化是基于虚拟内存实现的
虚拟内存是什么东西?简单来讲, 虚拟内存是由于主存不够大而出现的辅存(理论上来说, 主存想多大就多大, 实际上来说怎么可能, 主存越大价格越高, 追求性价比的情况下才出现的虚拟内存)
虚拟内存主要是干啥呢? 虚拟内存可以把内核空间和用户空间的虚拟地址映射到同一个地方, 这样用户对这个映射地址的操作, 内核空间也可以感知到, 那么内核和用户之间就可以减少拷贝了
当引入mmp机制后的IO操作
- mmp调用向操作系统发起IO, 用户态切换到内核态
- DMA拷贝数据从硬盘到内核缓冲区
- 内核态切换到用户态
- write之后, 也即发起IO调用, 用户态切换到内核态
- CPU拷贝内核缓冲区数据到socket缓冲区
- DMA拷贝socket缓冲区到网卡设备, 内核态切换到用户态
-
上述操作可以看出, 我们进行了4次上下文切换, 3次拷贝, 好像还是不够优化, 我们虽然优化了拷贝次数, 但是上下文切换也很耗费时间的, 4次上下文切换能否可以优化呢?对于系统调用来说(read, write,mmp这类函数) 上下文切换是不可避免的, 想要优化就必然减少系统调用次数, 上述我们不可避免使用到了write函数,如果我们将read和write合并成一次系统调用, 在内核中实现磁盘和网课数据传输, 就能够减少上下文切换了, 也就是sendfile优化
-
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
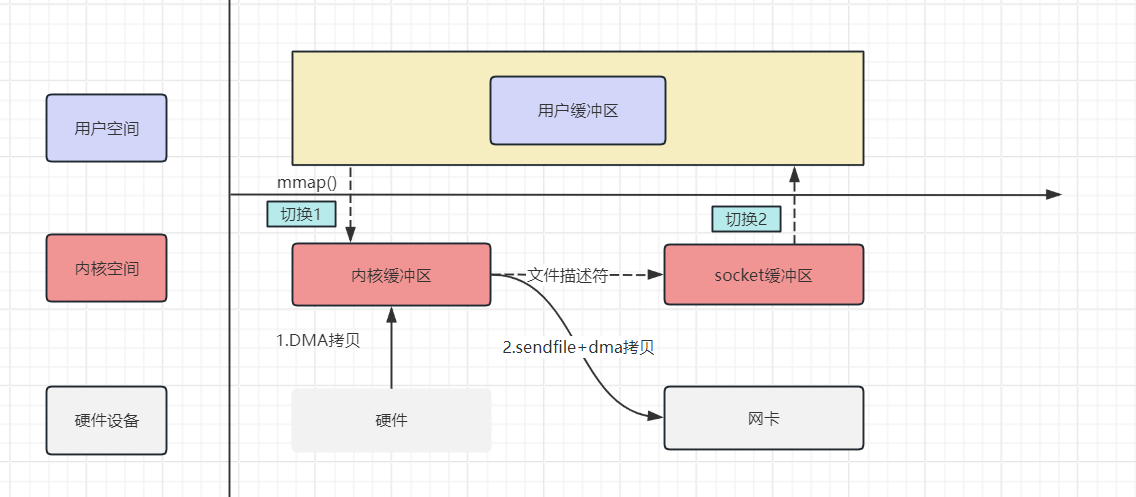
sendfile优化
当引入sendfile优化后的IO操作
- 用户进程发起sendfile进行IO,用户态切换至内核态
- DMA拷贝数据从硬盘到内核缓冲区
- CPU拷贝内核缓冲区到socket缓冲区
- DMA拷贝数据从socket缓冲区到网卡
- 内核态切换到用户态, sendfile函数返回
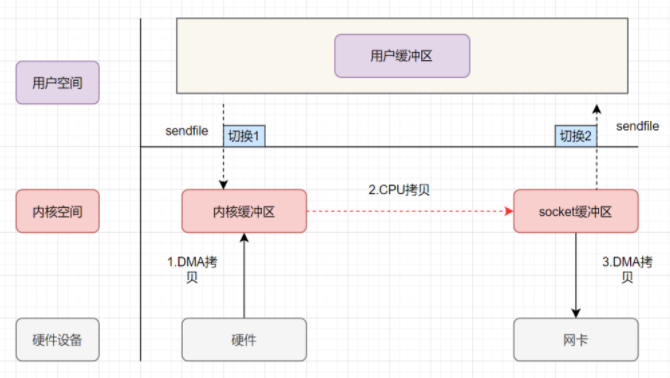
- 上述操作发现, 我们只进行了2次上下文切换, 这下上下文切换好像是优化到极致了,但是依旧是3次拷贝, 如何继续优化拷贝次数? Linux 2.4 版本之后,对 sendfile 做了升级优化,引入了 SG-DMA技术,其实就是对DMA拷贝加入了 scatter/gather 操作,它可以直接从内核空间缓冲区中将数据读取到网卡,无需将内核空间缓冲区的数据再复制一份到 socket 缓冲区,从而省去了一次 CPU拷贝。
sendfile +DMA scatter/gather优化
当使用优化后的IO操作
- 用户进程发起sendfile进行IO,用户态切换至内核态
- DMA拷贝数据从硬盘到内核缓冲区
- CPU直接将文件描述符等信息(内核缓冲区的地址+偏移量)复制到socket缓冲区中
- DMA根据文件描述符拷贝内核区数据到网卡
- 内核态切换到用户态, sendfile函数返回
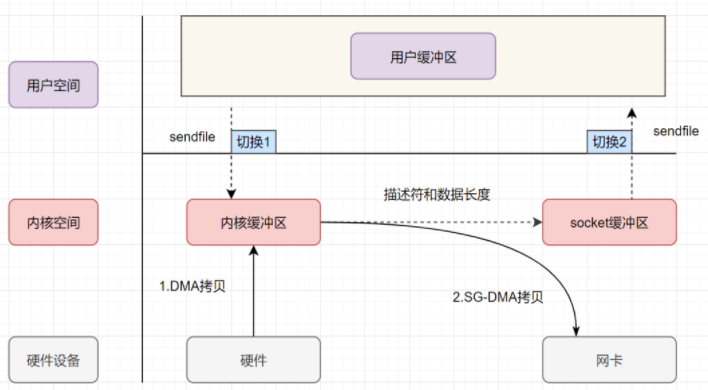
- 至此, 我们通过两次上下文切换+两次拷贝完成零拷贝终极优化
- 这里的两次拷贝不是cpu拷贝, 而是DMA拷贝, 零拷贝的意义也是在减少cpu拷贝, 使用mmp和sendfile实现的也叫做零拷贝, 只是不够那么零
Kafka是怎么使用零拷贝的
简单来说:
Kafka的两个过程
- Producer生产数据到broker ->数据持久化到磁盘 -> 使用了mmp
- Consumer从broker获取数据 ->磁盘文件发送到网卡 -> 使用了sendfile
mmap也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
RocketMQ选择了mmap + write这种零拷贝方式,适用于业务级消息这种小块文件的数据持久化和传输;而Kafka采用的是sendfile这种零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输。但是值得注意的一点是,Kafka的索引文件使用的是mmap+write方式,数据文件使用的是sendfile方式。
这里有一篇详细一点的文章, 网上讲kafka中如何实现零拷贝的好像比较少, 大部分围绕着零拷贝是什么展开的, 找了半天觉得这个比较好,感兴趣的可以戳这个大佬的链接

