
- 1更新Microsoft.PowerShell遇到 尝试更新源失败: winget_尝试更新源失败: winget
- 2[MySQL] SQL优化之性能分析
- 3powershell一行代码批量修改文件名(附命令详解)_命令控制程序批量处理文件名称代码
- 42022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅_毕设 csdn
- 5基于微信山西太原某大学球馆预约预约小程序系统设计与实现 研究背景和意义、国内外现状
- 6ssm+mysql校园信息交流平台的设计与实现-计算机毕业设计源码28259_校园空间数据库管理系统开发
- 7深度学习框架-keras_.keras
- 8linux nohup命令如何使用?_linux中nohup怎么用
- 9FaceChain V2,Human AIGC开源应用平台
- 10Java连接Mysql报错:javax.net.ssl.SSLException: Received fatal alert: internal_error_caused by: javax.net.ssl.sslexception: received fa
将隐式神经表示(INR)用于2D图像
赞
踩

©PaperWeekly 原创 · 作者 | 张一帆
学校 | 中科院自动化所博士生
研究方向 | 计算机视觉
以图像为例,其最常见的表示方式为二维空间上的离散像素点。但是,在真实世界中,我们看到的世界可以认为是连续的,或者近似连续。于是,可以考虑使用一个连续函数来表示图像的真实状态,然而我们无从得知这个连续函数的准确形式,因此有人提出用神经网络来逼近这个连续函数,这种表示方法被称为“隐式神经表示“ (Implicit Neural Representation,INR)。
举几个例子,图像、视频、体素,都能用 INR 来表示,其数学表达如下:
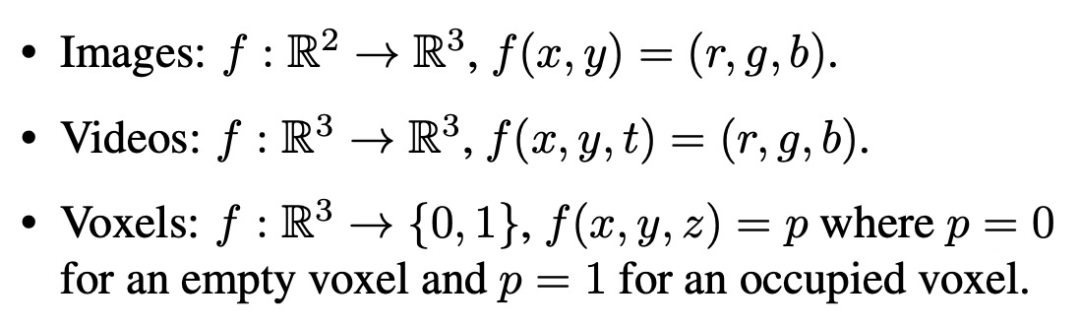
对于图像,INR 函数将二维坐标映射到 rgb 值。

对于视频,INR 函数将时刻 t 以及图像二维坐标 xy 映射到 rgb 值。对于一个三维形状,INR 函数将三维坐标 xyz 映射到 0 或 1,表示空间中的某一位置处于物体内部还是外部。当然还有其他形式,如 NERF 将 xyz 映射到 rgb 和 sigma。总而言之,这个函数就是将坐标映射到目标值。一旦该函数确定,那么一个图像/视频/体素就确定了。
本文挑选了近几年来 INR 用于 2D 图像的文章,对其发展做一个大致的介绍。

SIREN

论文标题:
Implicit Neural Representations with Periodic Activation Functions
论文链接:
https://arxiv.org/abs/2006.09661
收录会议:
NeurIPS 2020
项目地址:
https://vsitzmann.github.io/siren/
虽然 INR 非常的有效而且与传统方法相比有很多好处,但是目前的网络架构不能有效的非常详细的对信号进行建模,而且无法对信号的高阶导数进行求解,而高阶导数又是求解偏微分方程的必经之路,这就大大的限制了 INR 表达在物理信号上的使用。
而这些缺点主要是因为传统网络大多数使用了 ReLU,TanH 等激活函数,本文使用周期性的激活函数(sin 函数),并将网络称之为 SIREN,本文发现 SIREN 非常适合于表示复杂的自然信号及其导数,而且在 2D,3D 信号表示上也比传统激活函数好很多。


X-Fields

论文标题:
X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
论文链接:
https://arxiv.org/abs/2010.00450
收录会议:
SIGGRAPH Asia 2020
项目地址:
https://xfields.mpi-inf.mpg.de/
它提出了一种新颖的方法来对 2D 图像的时间、光线和视图进行无缝插值,即使用稀疏数据 X-field。这个 X-field 是通过学习一个神经网络来表征,将时间、光线或视图坐标映射到 2D 图像上。
传感器从不同的点(视频)、角度(光场)或在变化的照明(反射场)下捕获场景的图像。人们可以利用这种多样化的信息来改善 VR(虚拟现实)的体验。利用此信息,可以插入新视图、光线等,实现从一个场景到另一个场景的无缝过渡。但是,无缝插值需要密集采样,从而导致过多的存储、捕获和处理需求。稀疏采样是一种替代方法,但很明显,这需要在时间、光线和视野范围内进行精确插值。
X-field 是跨不同视图、时间或照明条件(即视频、光场、反射场或其组合)拍摄的一组 2D 图像。作者提出了一种基于神经网络的架构,可以表示这种高维 X-fields。根据下面的图 1,可以理解本文的关键所在:利用在不同条件和坐标下观察到的稀疏图像(在这种情况下为时间),来训练神经网络(映射),可以在提供空间、时间或光线坐标作为输入的情况下,生成观察到的样本图像作为输出。对于未观察到的坐标,将对输出进行如实插值(如 GIF 所示)。

Overview of the Proposed Method
具体来说,X-Fields 就是学一个函数:
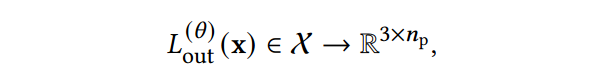
这里 是参数,函数将 维的输入映射为有 个像素值的 2D RGB 图像。X-Field 维度取决于捕获方式,四维的话就包括 即 2D 图像的坐标,时间维度和光照角度。
我们可将 X-field 视为高维连续空间。我们有有限的、非常稀疏的输入图像。这种稀疏观察到的 X-Field 坐标可以表示为 ,在已知坐标 处捕获了图像 。 很稀疏,即很小,例如 、 等。例如,给定一个 的光场图像序列,输入是 2D 坐标 ,其中 ,。在测试期间,我们可以为 给出 到 之间的任意连续值,为 给出 到 之间的任意连续值。学习的神经网络架构将如实地在给定范围内进行插值。
总之,这里训练了一个 架构,以将向量 映射到捕获的图像 ,同时也希望得到对于未观察到的向量 产生合理图像 。
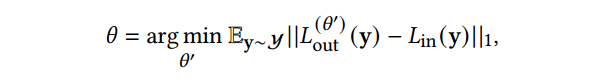
Architecture Design
本文的网络架构也是一个创新点,主要通过四个步骤来实现:
分离阴影和反照率:阴影是指在 3D 模型(3D 计算机图形学领域)或插图(2D 计算机图形学范围)中,通过改变暗度来进行深度感知的描述。反照率是入射光从表面反射出去的比例。换句话说,它是物体的整体亮度。
插值图像是变形图像(即训练数据出现的图像)的加权组合。
使用神经网络表示“flow(流)”。
解决不连续问题。
这部分比较复杂具体参见原文,本文在各个数据集上实现了非常平滑的插值,效果比目前的 SOTA 好很多。


LIIF

论文标题:
Learning Continuous Image Representation with Local Implicit Image Function
论文链接:
https://arxiv.org/abs/2012.09161
收录会议:
CVPR 2021
项目地址:
https://github.com/yinboc/liif
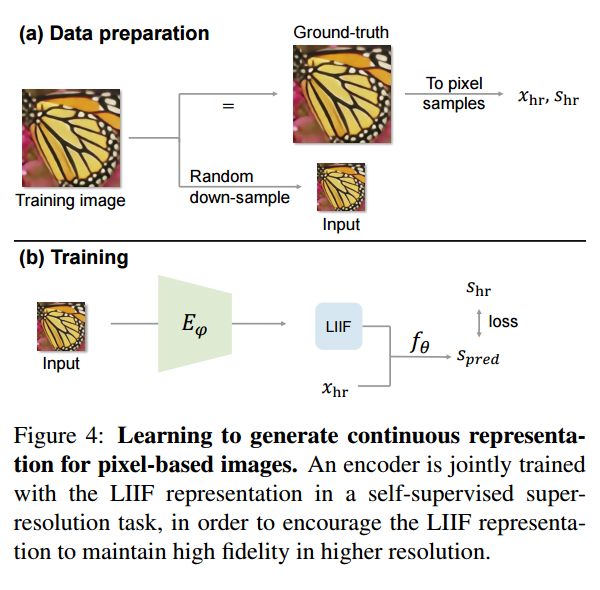
本次提出局部隐函数(Local Implicit Image Function,LIIF),以一个图像坐标和坐标周围的二维深度特征作为输入,预测给定坐标处的 RGB 值作为输出。由于坐标是连续的,所以 LIIF 可以呈现出任意分辨率。作者通过超分辨率的自监督任务来训练编码器和 LIIF 表示,以生成基于像素图像的连续表示。连续表示可以在任意分辨率下呈现,在没有提供训练任务的情况下,甚至可以放大到 ×30 更高的分辨率。
本文采用的是 encoder-decoder 架构,即使用一个 encoder 对所有的 object 预测 latent vectors,然后所有 object 共享一个 decoder,对于给定的坐标,根据坐标信息查询该坐标附近的局部 latent codes 作为函数输入,预测其 RGB 值。
公式化的描述,每个 image 会被表示为一个 2D 的特征图 。然后一个 decoder 用来进行预测:
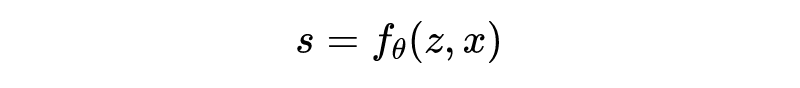
很好理解,二维坐标。 是本文理解的一个要点,即该位置附近的局部信息。
注意我们的图像是 的,比特征图要大,因此需要 decoder 进行一定的转换。即如下所示:
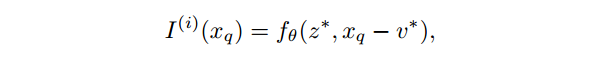
这里的 是距离位置 最近的 latent code, 是 所在的位置。也就是说每个 latent code 表示连续图像的一个局部信息,负责预测距离它最近的一组坐标的信号。
为了提升丰富 latent 蕴含的信息,作者进行了 feature unfolding,即将 范围内的 latent 进行连结。边角的地方进行 0 填充。
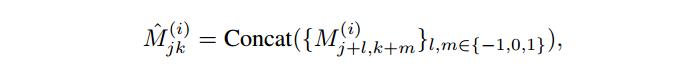
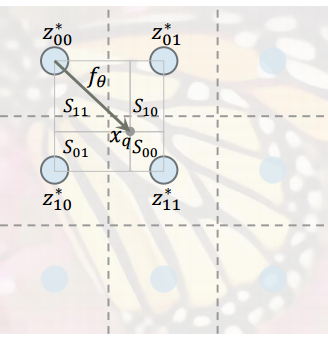
但是此时预测过程还有一个严重的问题,那就是不连续,如下图所示,因为 位置的临近信息只依赖于与他最近的那个 latent vector(此图中是 ),因此当 上移或者左移超过虚线的时候,预测结果就会立刻改变,即一个很小的输入扰动就会造成非常大的结果误差,这是不合理的,因此作者将最终的预测结果改为使用临近四个位置 latent code 的加权和。
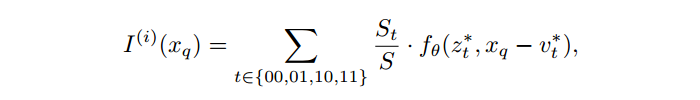
网络很简单,先将数据预处理成高分辨率和低分辨率的图片,对低分辨率图片过一个 encoder,得到 feature map,然后输入高分辨率图像坐标(x,y)和低分辨率的 feature map,使用一个 MLP 预测高分辨率的 rgb 值。
最后 INR 的 idea 确实非常惊艳,其表达能力也很出众,有着以下几个卓越的特点:1)输入输出自然对其,与数据的形式(1-D,2-D,3-D)无关;2)与训练数据的分辨率无关。INR 的思想已经被用在了超分,3D 渲染,跨模态生成等很多领域,相信这种对数据建模的思想还有这其他重要用途。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读



#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

