
热门标签
热门文章
- 1Vue Baidu Map--点标记bm-marker的使用、注意事项
- 2python cocos2dx_VS2017中搭建Cocos2dx开发环境图文详解
- 3VSCode 中,TS 提示 ”无法找到 *.vue 声明文件“ 的解决方案,ts(2307)_无法找到.vue声明文件
- 4sysystemd日志 journalctl日志持久化存储(journal日志、持久化日志)(/etc/systemd/journald.conf)log日志容量上限、无法持久化失败
- 5canvas画布 案例——1、心电图 2、绘制矩形——柱状图 3、挂钟 4、饼状图 5、评分空间——五角星 6、动图
- 6[转载]git 添加源地址和查看源地址_git 查看源地址
- 7深度学习:开启人工智能的未来探索之旅
- 8js之es新特性
- 9Unity编辑器扩展?什么是PropertyDrawer? 自定义脚本变量绘制?_unity propertydrawer dll
- 10文件操作:打开、关闭、读取、定位_c:\\users\\lenovo\\desktop
当前位置: article > 正文
预训练语言模型的使用方法_预训练要相似到什么程度
作者:菜鸟追梦旅行 | 2024-02-21 13:19:31
赞
踩
预训练要相似到什么程度
如何使用预训练模型
一、思路
首先要考虑目标模型的数据量及目标数据与源数据的相关性。
一般要根据数据集与预训练模型数据集的不同相似度,采用不同的处理方法。

上图中
1、数据集小,数据相似度高
理想情况,可以将预训练模型当做特征提取器使用,所以有时候称为特征抽取。
做法:去掉输出层,将剩下的整个网络当做一个固定的特征提取机,应用到新的数据集中。

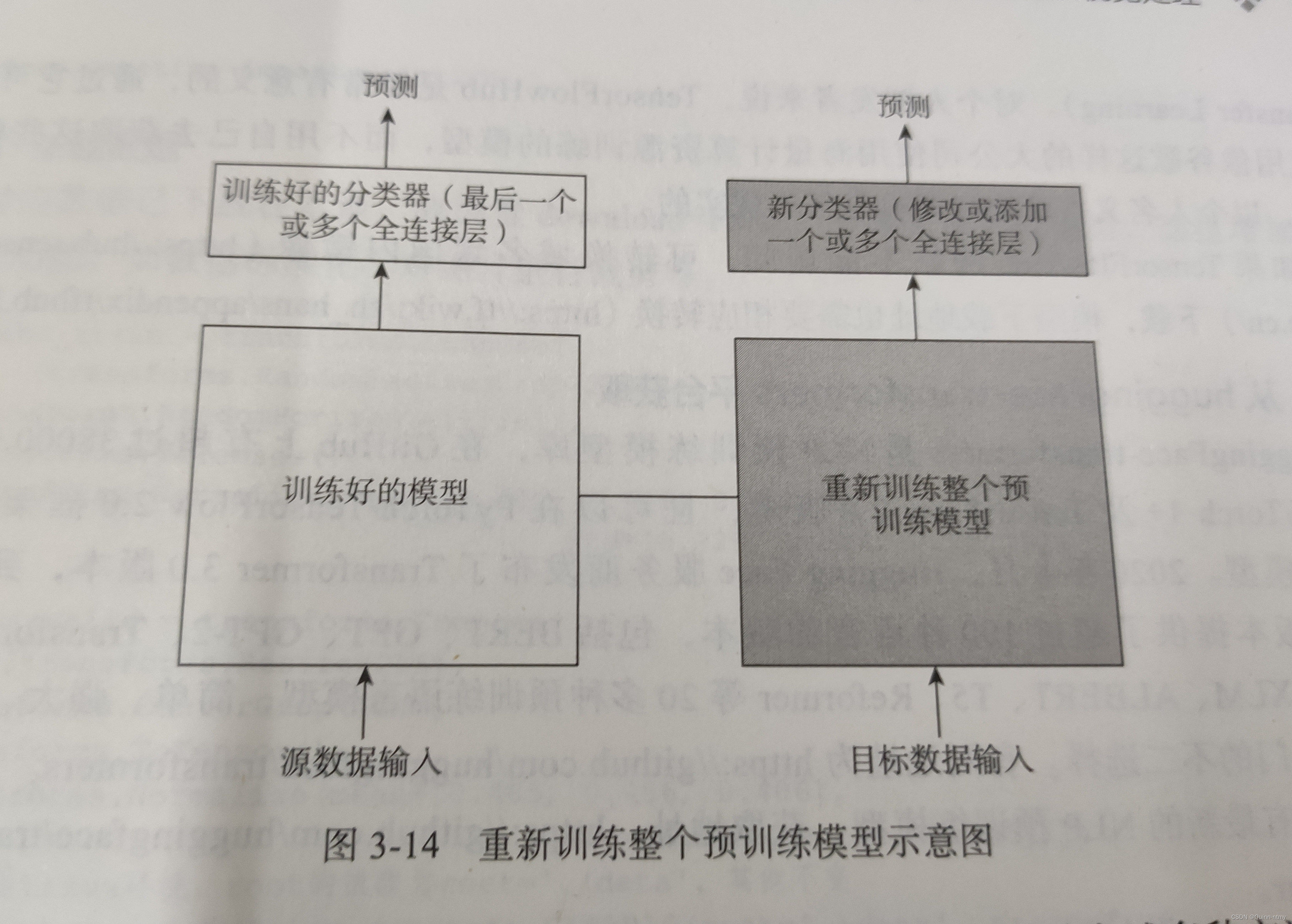
2、数据集大,数据相似度高
冻结预处理模型中少量较低层,修改分类器,然后在新数据集的基础上重新开始训练。
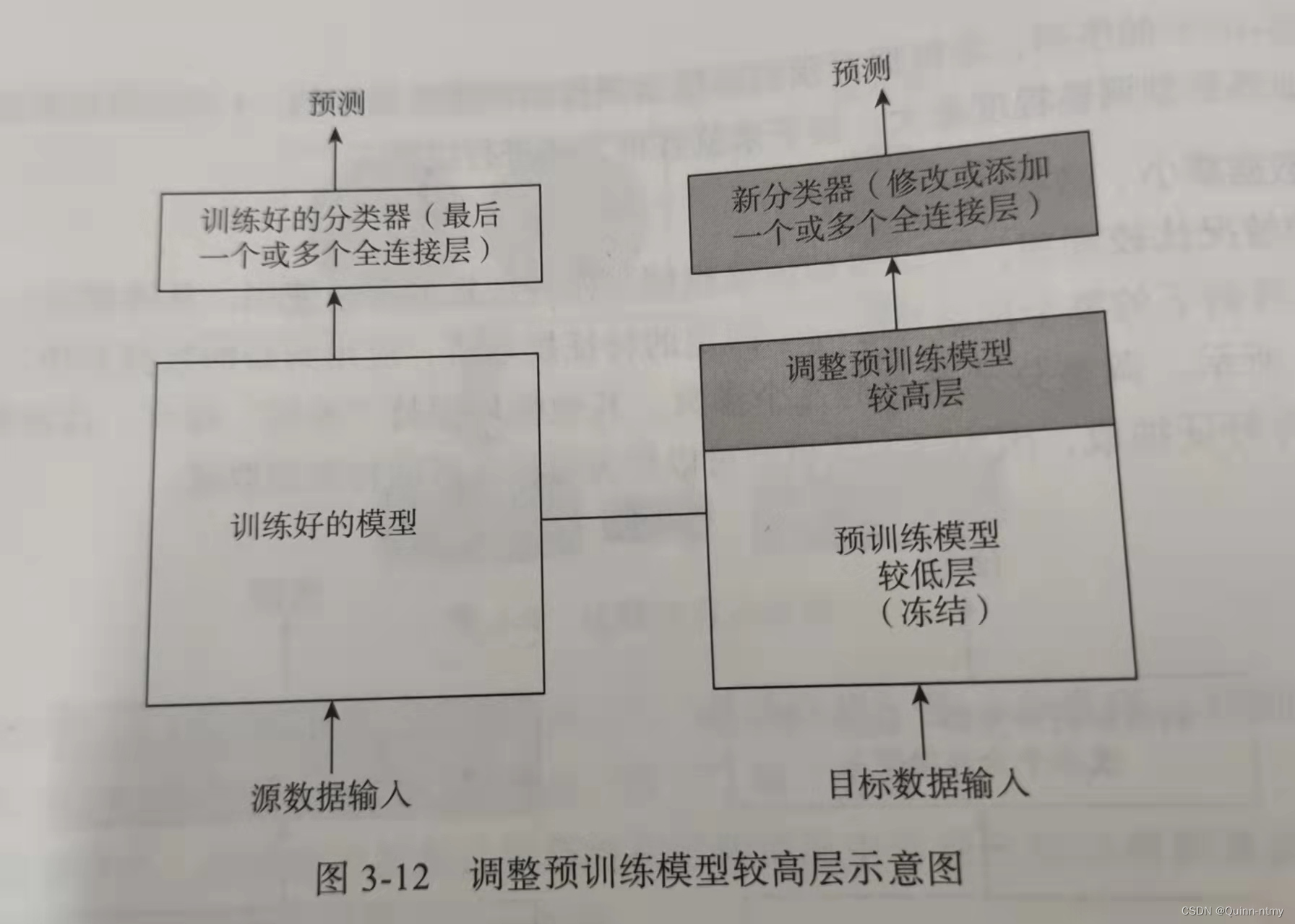
3、数据集小,数据相似度不高
冻结预训练模型中较少的网络高层,然后重新训练后面的网络,修改分类器。相似度不高,so 重新训练的过程很关键!!
数据集大小不足这方面通过冻结预训练模型中一些较低的网络层进行弥补。
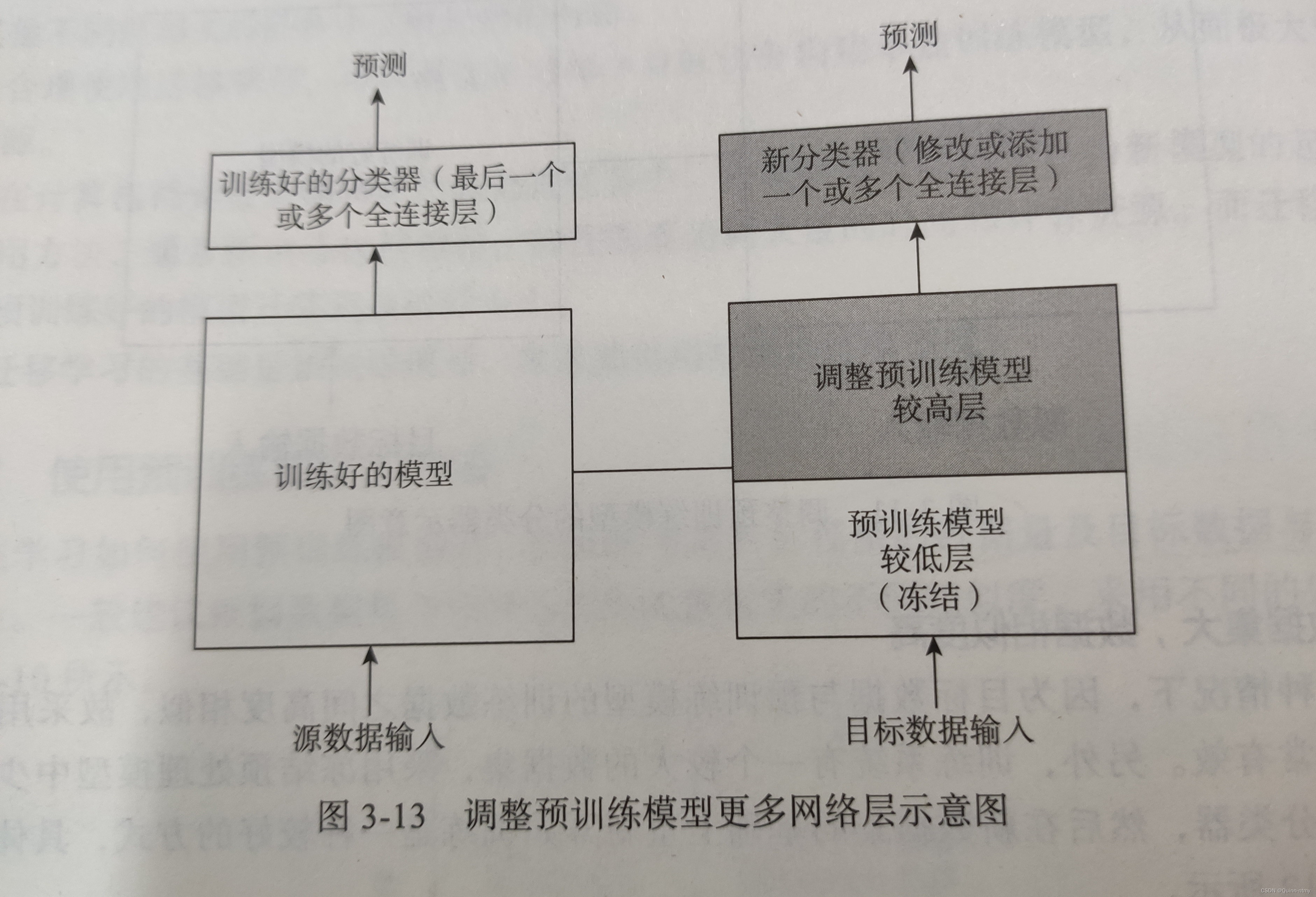
4、数据集大,数据相似度不大
大数据集,NN的训练过程比较有效率。但相似度不高时,预训练模型会很不高效,to do:将预训练模型中的权重全都初始化后再到新数据集的基础上重新开始训练。
【注】具体操作时,往往会同时尝试多种方法,从其中选最优。
二、获取预训练模型
1、PyTorch的工具包torchvision中的models模块(torchvision.models),使用时需设置 pretrained=True。
2、tensorflow.keras.application 或 可以在TensorFlowHub网站(https://tfhub.dev/google/)上下载。
3、huggingFace-transformers(NLP预训练模型库)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/124040
推荐阅读
相关标签

