
- 1androidstudio 修改包名和应用名称_android 根据包名 设置 应用名
- 2Django运行错误:WinError 10013_error: [winerror 10013] an attempt was made to acc
- 3TVM框架详解
- 4zabbix监控磁盘IO low-level-discory方式-iostat说明_disco low level data browser
- 5Redis学习二、 基础篇 5大基本数据结构、数据库底层操作、持久化功能、主从模式,所有常用命令(全)_redisdb基本数据结构
- 6若依框架(前后端分离)打war包部署到linux_若依打war包
- 7Linux 中的zip命令使用_zip打包命令 linux
- 8群晖搭建ArtiPub – 一款开源的一文多发平台(让你的文章随处可阅)_群晖搭建发卡平台
- 9监控流媒体服务器连接监控摄像头的配置方式 - GB28181和ONVIF_onvif和gb28181区别
- 10easyexcel 根据模板导出_SpringBoot整合easyexcel
一文详解DeepMind最新模型SUNDAE,了解迭代去噪模型的前世今生
赞
踩

©作者 | 中森
单位 | 粤港澳大湾区数字经济研究院
研究方向 | 条件受控下的文本生成
近期笔者在做些去噪语言模型的预训练和迭代生成语言模型的实验和探索,在读到谷歌 DeepMind 实验室的新作圣代 SUNDAE 模型后,便决定写篇迭代生成语言模型的整理和对比。

导言:自回归式语言模型建模的缺陷
在 NLP 的文本生成(序列建模)领域,无论是开放域文本生成、主题生成、还是翻译任务,最主流的方式还是自回归式的语言建模。即给定一个序列 我们使用一个神经网络来对序列里的每一个变量进行条件概率建模。而每一个变量的条件概率依赖于当前变量在序列里的所有前置变量,即 << 。无疑,自回归式的语言模型符合人类单向阅读的直觉与思维方式,并在一系列任务里展现出了良好的效果;但它同样有其阿克琉斯之踵。首先,其对序列的单向依赖导致其无法并行,解码速度慢。
其次,当我们试图在解码过程中试图搜索最大似然序列 时,自回归的语言建模要求我们在序列长度为 T,每个变量有|V|种可能的情况下搜索最大可能,其中 V 代表词表大小,一共有 种可能。由于我们显然无法处理天文数字般的计算复杂度,我们只能依赖于贪心搜索,柱搜索等策略近似求解这个解码过程。那么,我们是否有其他方式对语言模型建模,来规避以上两个问题?

迭代去噪模型的数学假设
如果我们以类似于朴素贝叶斯的方法,假设序列里的每一个变量 都是依赖于某个序列 而互相间条件独立的话,我们可以将 基于序列 的条件概率因式分解为:
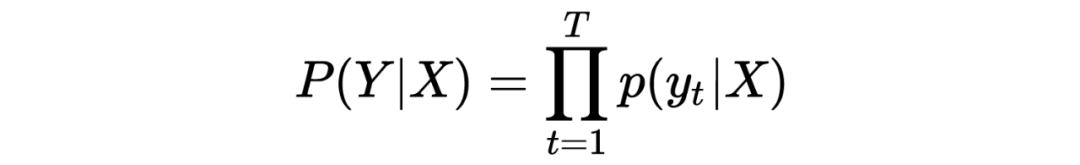
显然,将语言模型以该种方式建模的好处在于:首先,生成序列里的所有词之间条件独立,无需再按次序逐个生成,可以平行解码,极大加速解码过程。其次,因为规避了联合概率的建模,我们不再需要在一个极大的搜索空间里寻找最大似然序列,对于每一个变量,我们只需简单地对其进行 argmax 操作即可。这两个特性完美对应了以上提到的自回归式生成的缺陷。
但是,该方法最大的问题在于建模一个只依赖于输入序列的条件独立的语言模型难度远大于建模一个自回归式的语言模型!
为了缓解这个难题的同时,依然保留条件独立所带来的速度和解码优势,近几年的 NLP 学界的主流做法是引入一系列隐变量且让该隐变量的形式与输出 Y 保持一致。这样子,我们的条件概率建模便等同于在一个模型架构上进行多轮迭代生成。每一次迭代我们所获得的中间过程输出 即为我们所依赖的隐变量。每一步的修正可表示为 ,其中 是我们当前所迭代的步数。
笔者认为,将隐变量和输出Y的形式保持一致的做法实质上将朴素贝叶斯的条件独立假设打破,使得输出 Y 不仅依赖于输入 X,且依赖于生成词间的相互联系。但这种巧妙的建模方式,使我们依然可以保留平行解码的速度优势!
将多轮迭代合并起来讨论的话,我们建模的是以下式子。其中序列 包含 T 个独立变量, 迭代次数 。且如上文所假设,输出序列 Y 里的所有独立变量,互相对输入序列 X 条件独立,即 。所以我们有
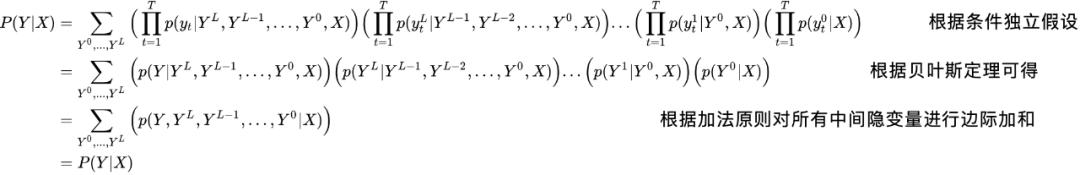
其中,如果我们引入时齐马尔可夫假设,认为每轮迭代只与上一轮的隐变量相关的话,上面式子的第一行可以改写为
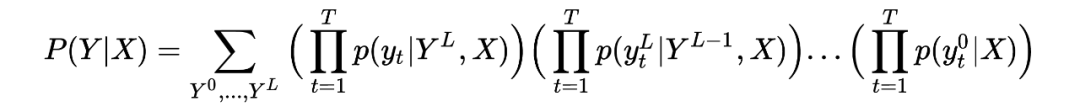
这样,每一轮的迭代我们只依赖于输入和上一轮的隐状态表达。如果熟悉 transformer 的读者会发现,这种建模方式天然适合于 transformer 里的 encoder+decoder 架构, 并且非常适用于翻译任务。

对中间过程隐变量的不同条件依赖建模
在有了上面提纲挈领的条件概率建模公式后,以下四篇论文的理解就显得水到渠成了。以下四篇论文的核心思想并没有太大差别,只是在具体的中间过程隐变量的依赖上做了不同程度的假设与变换。下面我将逐一介绍其核心思想与互相间的差异。
3.1 CMLM

论文标题:
Mask-Predict: Parallel Decoding of Conditional Masked Language Models
收录会议:
EMNLP 2019
论文链接:
https://arxiv.org/abs/1904.09324
代码链接:
https://github.com/facebookresearch/Mask-Predict
CMLM 的全称是条件掩码语言模型(conditional masked language model)。CMLM 的模型预测的是一系列掩码词 在给定输入 和部分已生成且未被掩码的中间输出 的概率分布,即 。在这个条件概率下,序列 里所有的独立变量都互相对输入和未掩码词条件独立。并且因为每一轮迭代不改变输出 的长度,模型也隐式地条件于生成序列的长度 。
CMLM 的模型架构是 transformer 里的 encoder+decoder 架构。对输入 的条件依赖由编码器负责建模,对 的条件依赖由解码器负责建模。但因为对 的条件依赖不像自回归式的建模有时序要求,CMLM 里的解码器并没有我们常见的自回归式的解码器里的因果注意力掩码(causal attention mask,即使得每个词的自注意力机制只能看到当前位置之前的掩码)。并且,由于平行解码的特点,模型必须事先得知解码的长度以进行多轮迭代(迭代过程只替换词但不增删词)。所以作者在 encoder 里加入了一个类似于 BERT 里 的额外的特殊 字符,来进行生成目标的长度预测。
CMLM 在训练时的每一轮迭代,都会随机选取部分词进行 BERT 式的掩码进行更新。并对每一个掩码词计算交叉熵的损失。值得注意的是,这个步骤是可以并行处理的,因为所有的字符都是条件独立的。而交叉熵的和会与长度预测的损失放在一起进行梯度回传。
CMLM 在预测和解码的具体过程如下:迭代的次数T是个常数或是与输入序列 的长度 N 相关的函数。对于第一轮生成,我们对所有词进行掩码,即第一轮我们建模 。在之后的每一轮里,我们会选取 n 个概率分数最低的词进行掩码预测。n 是一个随着迭代轮次 t 不断减小的数值,作者使用的是一个简单方程 。对于每个掩码词,我们使用 argmax 选取其预测词。对于未掩码词我们保留其不变。
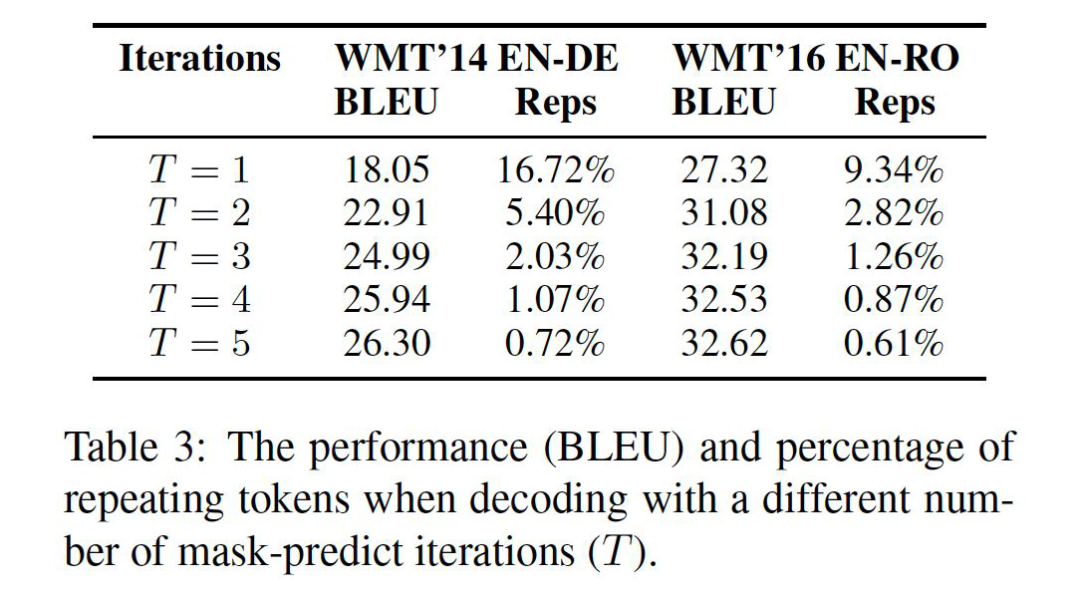
值得一提的是,输出序列里的每一个独立变量互相间关于输入序列条件独立这个假设,会使得模型在预测掩码词时极容易出现重复的词。因为条件概率分布里可能同时存在多个模态(modal),模型在生成时会同时考虑多个可能的输出序列,而独立预测的做法使得每个预测互不干涉,从而使得不同模态的预测会叠加,导致重复词的出现。但作者经过具体实验发现,迭代预测的做法极大缓解了多模态的问题。如下图所示,我们可以看到,翻译的 BLEU 分数和重复率在第二轮迭代后有了极为显著的改善!这可能说明引入隐变量的做法的确极大降低了建模条件独立分布的难度。
3.2 DisCo

论文标题:
Non-autoregressive Machine Translation with Disentangled Context Transformer
收录会议:
ICML 2020
论文链接:
https://arxiv.org/abs/2001.05136
代码链接:
https://github.com/facebookresearch/DisCo
Disco 的全称是 Disentangled Context transformer。这篇文章可以看做是对 CMLM 的部分改进。相较于 CMLM 每轮迭代只更新部分掩码词的做法,Disco 每轮迭代会对所有的解码词进行更新。每个解码词的更新条件依赖于输入与部分高置信度的上一轮预测词,即 ,其中
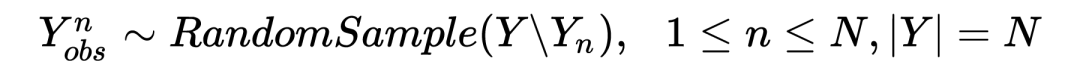
在 CMLM 的算法里, 可观测词和掩码词泾渭分明。可在 Disco 里,因为更新的是所有词且仍需要依赖部分上一轮预测词,所以解码器的输入里并没有掩码词的存在。这就会带来一个很直接的问题:信息泄漏。如果使用和 CMLM 一致的双向无因果推断的注意力掩码,那么在解码器的第一层,我们只需要在每个词的注意力掩码里对不可观测的部分词进行掩码即可。如下图所示:
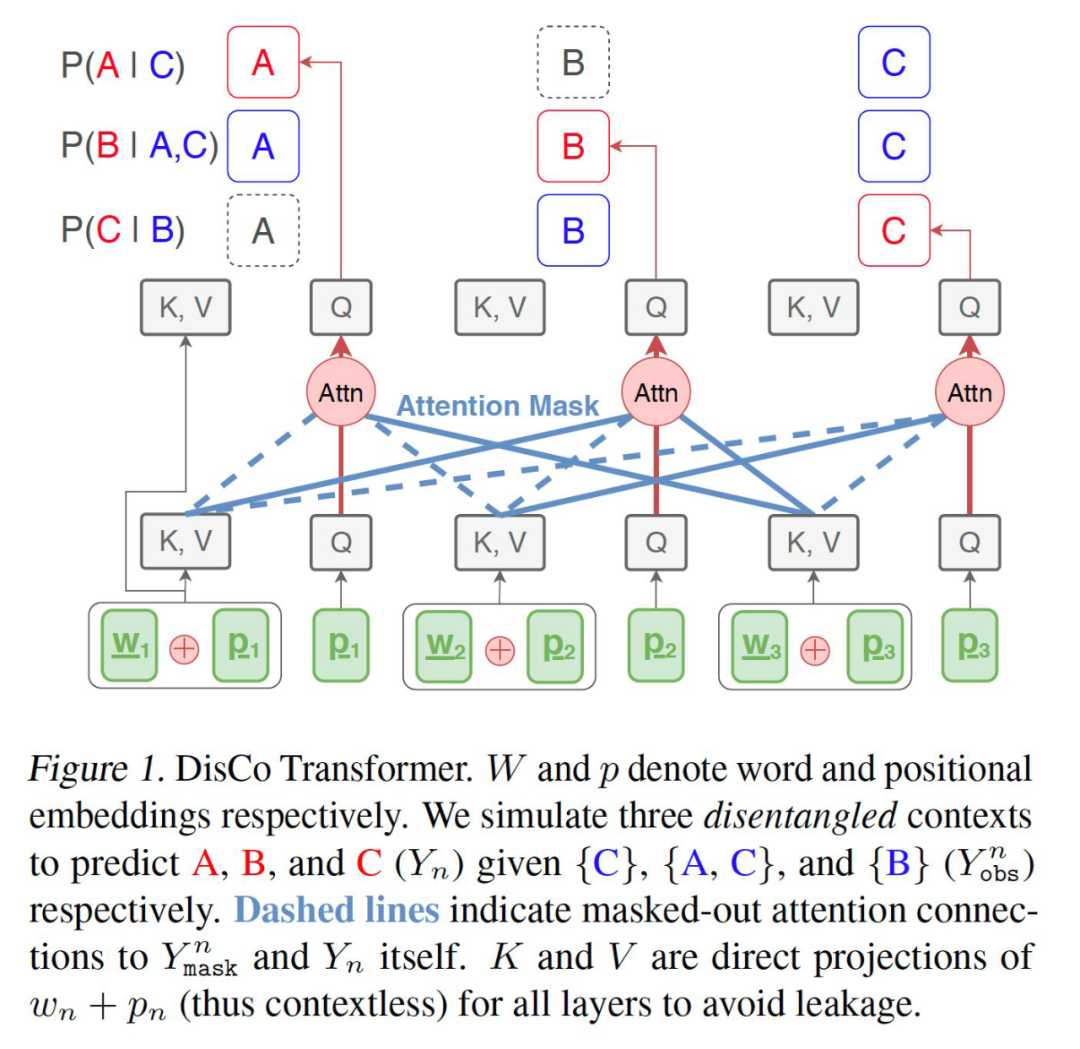
但一旦我们开始堆叠 transformer 的解码器结构时,信息泄漏就随着自注意力机制出现了。回顾一下在 transformer 里注意力机制的表达:对于第 层第 个位置的注意力 qkv,我们有以下式子 ,其中代表 词嵌入向量。那么,理所当然的,从第二层开始,每个位置的隐层表示 开始包含了上一层的部分位置的词义信息,并且这些位置很有可能对于其他词来说是正是其所期望预测或不应该看到的词义信息!为了解决这个问题,作者更改了解码器的 qkv 表达式,使其成为 ,其中 代表位置向量嵌入。这样修改后,结合第一层里我们对注意力掩码的修改,每一层的解码器的注意力只对其所依赖的词的位置和词嵌入进行查询,便成功避免了信息泄漏的问题。
使用了经典 encoder(含有特殊 length 字符)和修改过的 decoder 架构的 Disco 在预测时的算法简短描述如下:在第一轮的预测时,如 CMLM 一样只基于输入预测所有的位置词,即 。从第二轮开始,我们对所有词开始预测。对于上一轮预测词的依赖是根据其词概率进行倒排,每个词只依赖于输入和上一轮置信度比其高的词,即:
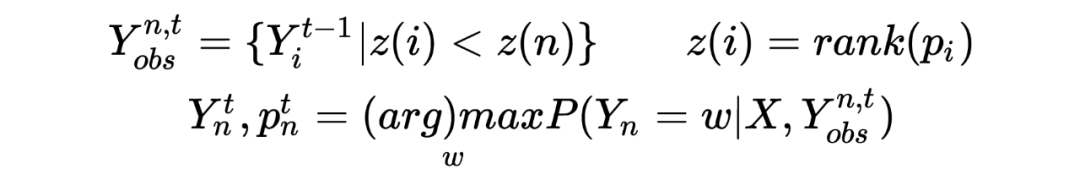
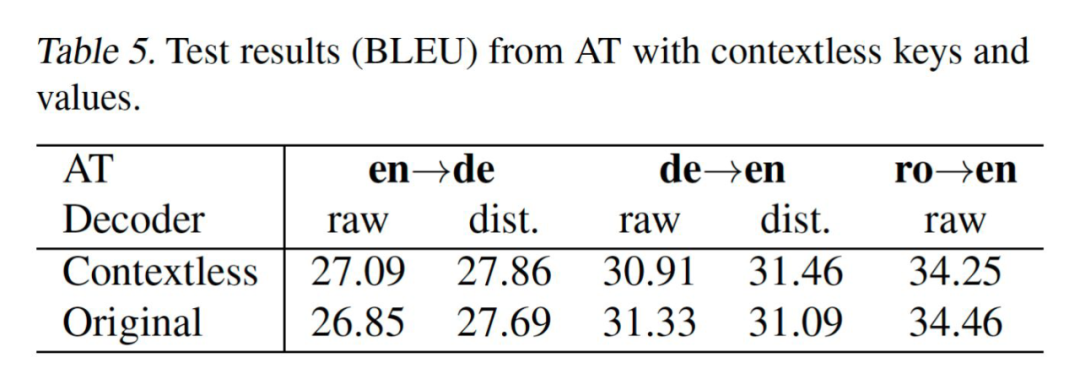
值得一提的是,作者在剥离实验时提到,哪怕是在自回归式的语言模型里对于解码器的魔改实际上也并没有造成太多性能损失。这点其实特别值得做所有做 transformer 生成的研究者深思,如图所示:
3.3 NARSM

论文标题:
Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement
收录会议:
EMNLP 2018
论文链接:
https://arxiv.org/abs/1802.06901
代码链接:
https://github.com/nyu-dl/dl4mt-nonauto/tree/multigpu
在我们正式介绍本文的主角 SUNDAE 模型前,还要最后介绍一篇笔者认为在形式上和思想上 SUNDAE 最为接近的论文。因为作者并没有起一个缩写,所以为了指代方便,笔者便将其强行缩写为 NARSM。
这篇论文的架构依然是经典的 encoder+ 双向注意力掩码的 decoder(这篇文章在四篇文章里其实是第一个发表在 arXiv 上的)。但其条件建模是基于输入 X 和上一轮迭代的整个预测序列 Y 对序列里每一个词进行更新。所以其训练的目标函数是:

其中 是迭代的轮次。同时,作者以去噪自编码器 DAE 的角度来理解这个迭代过程,即:

其中函数 C 代表的是加噪方程, 是任务的真实输出。最后的训练损失函数是这两者的加权结合(加权比例是用户指定的超参),即每一轮我们训练两个函数的迭代,一个依赖于上一轮的输出,一个依赖于真实输出的加噪结果:

在实际预测中,作者的做法和前文介绍的几篇迭代过程类似,但值得一提的是,作者提供了几个可选的迭代终止条件。分别是以每轮更新后序列里词的不同个数,或者更新后序列的条件概率的差别作为终止条件。
3.4 SUNDAE

论文标题:
Step-unrolled Denoising Autoencoders for Text Generation
论文链接:
https://arxiv.org/abs/2112.06749
介绍完前面一系列的论文后,我们就可以比较轻易地理解这篇论文的创新点了。笔者认为主要在以下几个方面:首先,SUNDAE 把多轮迭代过程当成一个纯粹的去噪过程(即上一篇的去噪自编码器的角度)。其次,SUNDAE 在几个翻译领域里无需蒸馏便可超越同类型的非自回归式模型。再次,作者使用 SUNDAE 在无条件文本生成和文本填充几个任务里也展现了比较好的效果(前面几篇论文主要集中在条件生成任务上)。
SUNDAE 的全称是 Step-unrolled Denosing Autoencoder。作者从 DAE 和时齐马尔可夫链的角度出发来理解我们上面所提及的多轮迭代的条件概率建模这个过程。即对于一个序列空间 我们考虑一个随机过程,这个过程里每个序列服从 ,其中 指的是一个参数转移方程,代表一个序列迭代到下一个序列的转移概率。如果我们依旧按照上文提到的序列里每一个独立变量基于上一轮的输出互相条件独立的话,我们可以得到下面这个式子。其中上标表示的序列里的位置。
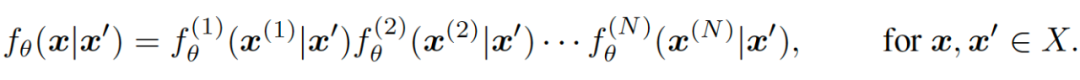
作者对迭代生成的任务的理解其实没有太多新意,可谓前人之述备矣。但笔者认为 SUNDAE 和之前的一系列论文最大的区别在于对损失函数的设计上。我们之前讨论的三篇论文里,训练过程中每一轮迭代的生成词都会与我们的真实任务输出做交叉熵,没有建模过中间过程。但 SUNDAE 引入了一个作者称为两步训练的展开去噪过程。如图所示(绿色为原文,红色为噪音):

大部分的非自回归模型只建模了从原始噪音到最终输出间的联系(第二行到第一行),但 SUNDAE 引入了个中间过程的交叉熵训练(第二行到第三行再到第一行)。而中间过程与原文间的配对则是模型在做真正推理的时候更常遇到的状态!
所以模型的损失函数可以用下列式子表示:其中上标 t 表示将第几轮迭代输出作为交叉熵的真实标签。
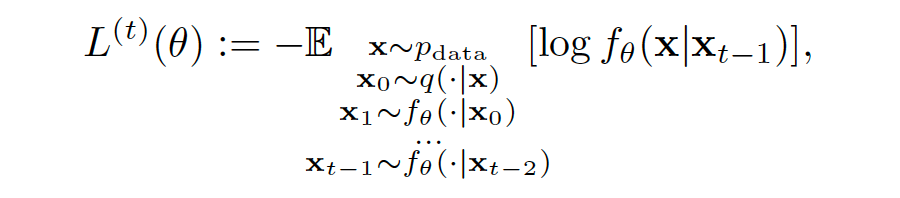
作者在实验中发现,多引入几轮中间过程增益不大,但极大的降低了训练速度,所以仅仅选择了两步训练的方式。
在真正进行多轮迭代解码推理的时候,作者提供了几种解码思路。文章里没有显式地提及过作者所宣称的所谓加速收敛的算子是什么。但根据上下文,最合理的猜测是算子指代的是以下几种接码策略:第一种是低温采样。首先第一轮生成时按模型所预测的长度进行随机平均采样,得到一个初始输出 。之后的每一轮里,作者采用的不是前几篇论文里的确定性的 argmax 解码,而是用温度平滑了词概率分布后再进行采样得到每个词,并迭代 T 轮。
第二种解码方式是 argmax-unrolled,收敛速度比低温采样更快。具体的做法是前两轮采用常规的计算和采样操作得到输出序列 和词概率 logits 。之后的每一轮解码输出词时,部分高概率词(由 排序所得)用来自上一轮的词概率 做 argmax,部分词来自当前迭代轮次的词概率 取 argmax 所得。每一轮都将当前的输出词 和词概率 传至下一轮。值得一提的是,因为 的词来自于 ,所以在第 t 轮迭代时,对 的某个位置取 argmax 时所得到的词很有可能与 序列里对应位置的词不同。
对于开放性文本生成,这个非自回归式模型通常难以很好建模的问题,SUNDAE 也做了一番探索。因为是无条件生成,架构上只用了没有因果注意力掩码的 decoder 架构。为了加速收敛和多样性,每轮迭代时只更新随机的部分词。为了收敛到较好的效果,作者显式地设置了一千步的迭代次数为收敛条件。笔者认为,虽然 SUNDAE 使得非自回归式生成方式在无条件生成的情况下取得了不错的效果,但其过高的迭代步数,使得其完全丧失了生成速度的优势和实际落地的可能。

总结
本文梳理了一种非传统自回归式的文本生成方式的演进路程。从假设输出序列里的每一个词关于输入条件独立开始,本文逐步讨论了引入中间过程作为隐变量的必要性,并对不同论文对隐变量的不同条件依赖方式进行了讲解。沿着这根主线展开,不同论文的异同点就显得一目了然了。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

