- 1LeetCode(力扣) 刷题注意事项 持续更新 ~ ~_leetcode怎么删除提交的题目
- 2若依-cloud启动报错_error creating bean with name 'sysconfigcontroller
- 3怎么用AI绘画?手把手教你使用_如何使用ai绘画软件
- 4Mybatis与Jdbc批处理_sqlsessionfactory.opensession(executortype.batch,
- 5【转】递归函数导致栈溢出之改写成尾递归_递归函数改写
- 6地位位置索引查询介绍——Geohash_geohash7位范围 12 位
- 7linux密码重置及基础命令_linux数据库怎么重置前端网页的密码设置
- 8Django学习记录04——靓号管理整合
- 9Linux 命令篇 之 内核命令_linux内核操作的主要命令
- 10谷歌2017新品发布会:赋能AI 三大原则 软硬结合
CUDA11.8编程学习_cudamalloc
赞
踩
__global__用于定义核函数kernel,核函数在GPU上执行,从CPU端通过三重尖括号语法调用,可以有参数,不可以有返回值。有的编译器在三重尖括号处有报错,没有太大的影响,具体为啥会报错,原因不知。
//核函数的声明方式
__global__ void kernel()
{
....
}
int main()
{
kernel<<<>>>();//核函数调用,在CPU中以三重尖括号的方式调用
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
__device__用于定义设备函数,设备函数在GPU上执行,在GPU上调用,不需要三重尖括号,和普通函数用法一致,可以有参数和返回值。
调用关系:host__可以调用__global,global__可以调用__device,device__可以调用__device。
通过__host__ __device__双重修饰符可以把函数同时定义在CPU和GPU上,这样CPU和GPU都可以调用。
constexpr修饰函数自动变成CPU和GPU都可以调用。constexpr修饰的函数内部不能调用printf和__syncthreads类。
CUDA编译器具有多段编译的特点
一段代码会先送到CPU上的编译器(通常是系统自带的编译器 比如gcc和msvc)生成CPU部分的指令码。然后送到真正的GPU编译器生成GPU指令码。最后,再链接成同一个文件,看起来像是只编译了一次,实际上代码会被预处理多次。
threadIdx.x 获取当前线程
blockDim.x 获取当前线程数量
blockIdx.x 获取当前块编号
gridDim.x 获取块的数量
在头文件#include "device_launch_parameters.h"中
//线程<块<网格
unsigned int tid = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int tnum = blockDim.x * gridDim.x
- 1
- 2
- 3
CPU和GPU各种使用独立的内存。CPU的内存称为主机内存(host,主存)。GPU使用的内存称为设备内存(device),为显卡上板载的,速度更快,又称显存。
不论是栈还是malloc分配的都是CPU上的内存,无法被GPU访问
cudaMalloc可以分配GPU上的显存,结束时cudaFree进行释放,并且cudaMalloc的返回值用来表示错误代码,所以指针只能通过&pret二级指针
比较新的显卡上支持的特性,那就是统一内存(managed),只需要把cudaMalloc换成cudaMallocManaged即可,释放时也是通过cudaFree。这样分配出来的地址,不论在CPU还是GPU上都是一样的。
原子操作的问题:影响性能
不过由于原子操作要保证同一时刻只能有一个线程在修改同一个地址,一个线程修改完了,另一个线程才能进去,非常低效。
SM(Streaming Multiprocessors)与块(block)
GPU是由多个流式多处理器(SM)组成的,每个SM可以处理一个或者多个块block。
SM又由多个流式单处理器(SP)组成,每个SP可以处理一个或多个线程。
每个SM都有自己的一块共享内存(shared memory),它的性质类似于CPU中的缓存,和主存相比很小,但是很快,用于缓存临时数据。
通常块数量总是大于SM的数量,这时英伟达驱动就会在多个SM之间调度所提交的各个板块。正如操作系统在多个CPU核心之间调度线程那样。
一个SM可同时运行多个块,这时多个块共同用一块共享内存(每个块分到的内存就减少了)。
块内部的每个线程是被进一步调度到SM上的每个SP。
同一块block中的每个线程都共享着一块存储空间,即共享内存,在CUDA的语法中,共享内存可以通过定义一个修饰了__shared__ 的变量来完成创建。
GPU优化总结:
1.线程组分歧(wrap divergence):尽量保证32个线程都进同样的分支,否则两个分支都会执行;
2.延时隐藏(latency hiding):需要有足够的blockDim供SM在陷入内存等待时调度其他线程组;
3.寄存器打翻(register spill):如果核函数用到很多局部变量(寄存器),则blockDim不宜过大;
4.共享内存(shared memory):全局内存比较低效,如果需要多次使用,可以先读到共享内存;
5.跨步访问(coalesced access):建议先顺序读到共享内存,让高宽带的共享内存来承受跨步;
6.区块冲突(bank conflict):同一个warp中多个线程访问共享内存中模32相等的地址会比较低效,可以把数组故意搞成不对齐的33跨步来避免。
英伟达的warp大小是32。
GPU计算能力(Compute Capability)
计算能力(Compute Capability)并不是指gpu的计算性能
nvidia发明计算能力这个概念是为了标识设备的核心架构、gpu硬件支持的功能和指令,因此计算能力也被称为“SM version"。
计算能力包括主修订号X和次修订号Y来表示, 主修订号标明核心架构,次修订号标识在此核心架构上的增量更新。
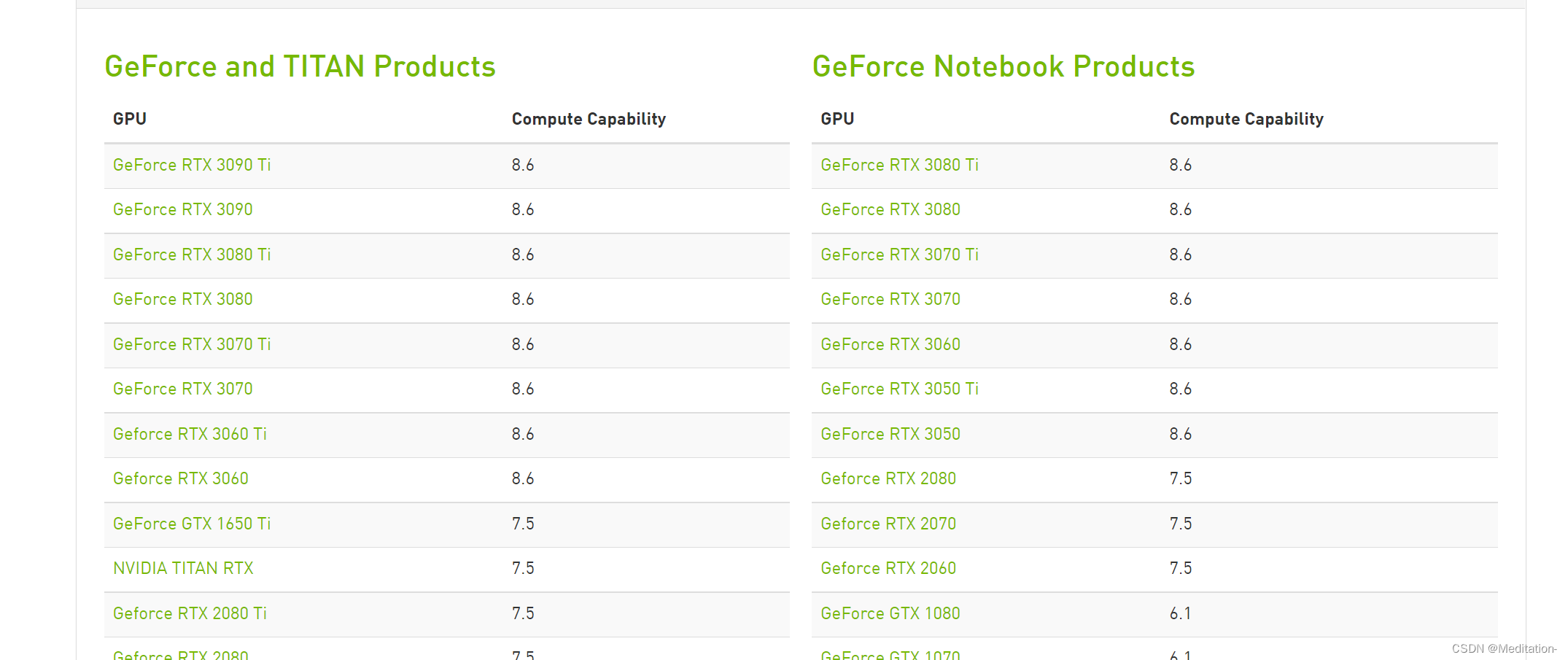
GPU计算能力查询网址:https://developer.nvidia.com/cuda-gpus#compute
本人用的是3060,很容易就查询到其Compute Capability是8.6
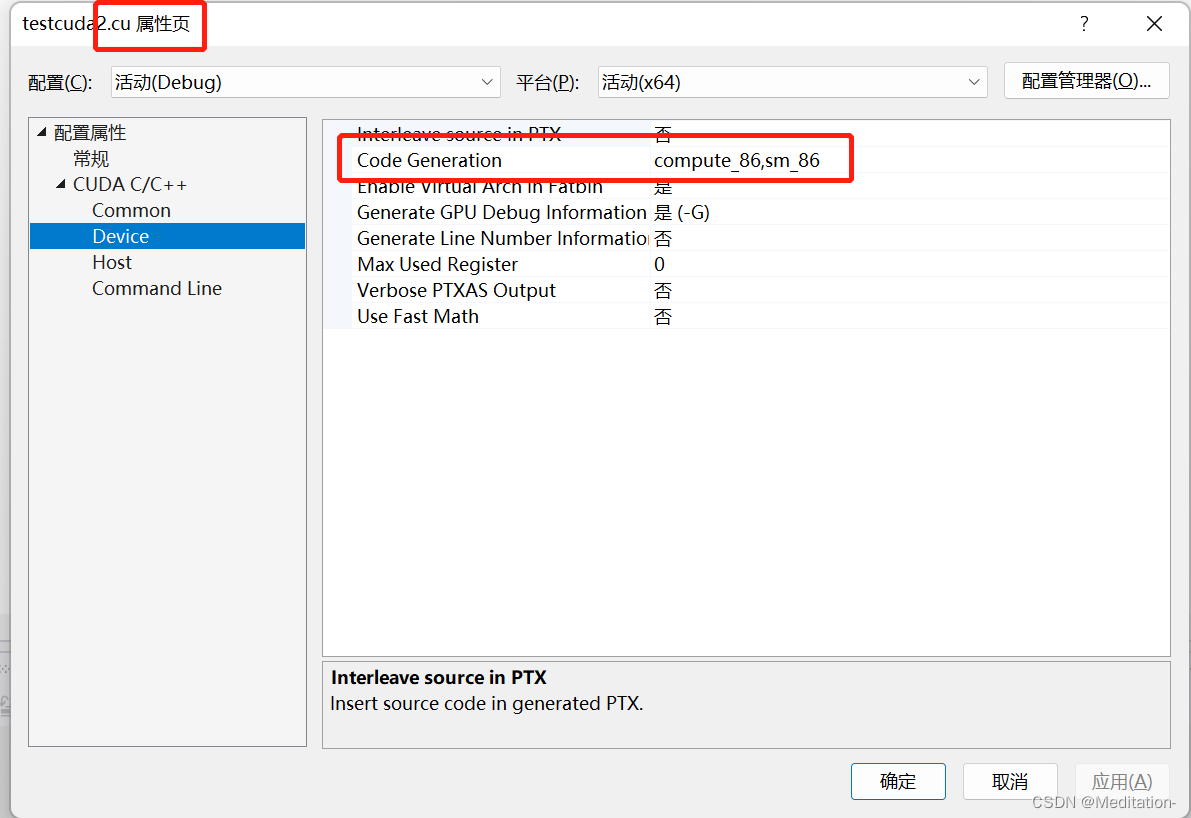
在VS2019中,右键选中.cu文件,CUDA C/C++中 Device的Code Generation就可以改成compute_86,sm_86。