
- 1java echo server_netty写Echo Server & Client完整步骤教程(图文)
- 2Unix域套接字简介_unix套接字
- 3深度学习100问-12:深度学习有哪些经典数据集?
- 4OpenVion22.3.x以及Opencv DNN部署yolov5(C++)全过程含代码_openvino-telemetry
- 5进程 zabbix_记录一次线上zabbix监控数据库占用硬盘过多处理
- 6【探索AI】十一 深度学习之机器学习基础
- 7SOTA技术概述
- 8基于springboot的短视频网站的设计与实现 毕业设计开题报告_短视频开发文献毕设
- 9论文翻译:Training Deep Networks with Synthetic Data:Bridging the Reality Gap by Domain Randomization_training deep networks with synthetic data: bridgi
- 10AI:134-基于深度学习的社交媒体图像内容分析
java httpresponse headres属性,http响应头首部Content-Length
赞
踩
本文讲述4个问题
gzip编码与Content-Length的关系
分块编码与Content-Length的关系
file文件已经在服务端进行gzip压缩,那为何在node中用request请求这张图片时(请求的方法为head/get)返回头首部Content-Length还是未压缩前的图片大小?
响应头一定会包含Content-Length首部吗?
在图片性能监控脚本中对站内某页面的所有图片进行请求(采用request模块),以获取图片的具体大小。(通过response.headers的Content-Length)
// 部分代码
request.head('http://file.showjoy.com/images/46/4695c19423cd40469fb89836373c1d45.jpg', function (error, response, body) {
console.log(response.headers['content-cength'])
// 'content-length': '812401'
})
对超过阈值的图片会邮件进行提醒:

但是在页面中用chrome查看这张图片时,却发现size只有227kb。

由于file开头的资源是文件服务器上的资源,将file改成cdn1再做尝试。可见图片尺寸大小还是812kb。
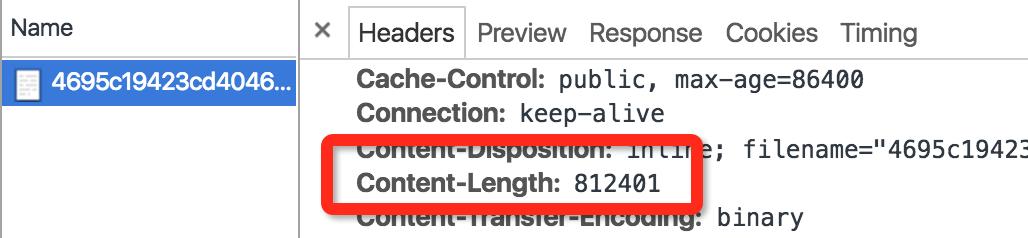
cdn1上的资源是由文件服务器上的资源同步上去的,这也意味着相同的资源size不同。造成这样的问题很有可能是服务器对资源做了压缩处理。
cdn http响应头
Accept-Ranges:bytes
Access-Control-Allow-Origin:*
Access-Control-Expose-Headers:X-Log, X-Reqid
Access-Control-Max-Age:2592000
Cache-Control:public, max-age=86400
Connection:keep-alive
Content-Disposition:inline; filename="4695c19423cd40469fb89836373c1d45.jpg"
Content-Length:812401
Content-Transfer-Encoding:binary
Content-Type:image/jpeg
Date:Thu, 04 Aug 2016 10:24:19 GMT
ETag:"FqxG8os4S6llXHllO2ublrIKagfY"
Last-Modified:Mon, 11 Apr 2016 09:05:23 GMT
Server:nginx
X-Log:mc.g;IO:1
X-Qiniu-Zone:0
X-Reqid:6VUAAKhrk3UAkmcU
X-Via:1.1 zhenjiang173:4 (Cdn Cache Server V2.0), 1.1 yzh229:1 (Cdn Cache Server V2.0)
file文件服务器 http响应头
HTTP/1.1 200 OK
Server: Tengine
Date: Thu, 04 Aug 2016 10:23:45 GMT
Content-Type: image/jpeg
Last-Modified: Mon, 11 Apr 2016 09:01:56 GMT
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Encoding
Expires: Thu, 31 Dec 2037 23:55:55 GMT
Cache-Control: max-age=315360000
Content-Encoding: gzip
可以看出文件服务器开启了Content-Encoding: gzip
内容编码gzip介绍
Accept-Encoding和Content-Encoding是HTTP中用来对「采用何种编码格式传输正文」进行协定的一对头部字段。
工作原理:
浏览器发送请求时,通过Accept-Encoding带上自己支持的内容编码格式列表,服务端从中挑选一种用来对内容编码,编好码的数据就放在实体主体中,再通过Content-Encoding响应头指明选定的格式,浏览器拿到相应正文后再依据Content-Encoding进行解压。
具体过程:
网站服务器生成原始响应报文,其中有原始的Content-Type和Content-Length首部。
内容编码服务器创建编码后的报文,编码后的报文有同样的Content-Type和不同的Content-Length,同时增加了Content-Encoding首部。
接收程序得到编码后的报文,进行解码,获得原始报文。
这就有了一系列问题:
file文件已经在服务端进行gzip压缩,那为何在node中用request请求这张图片时(请求的方法为head)返回头首部Content-Length还是未压缩前的图片大小?
响应头一定会包含Content-Length首部吗?
HTTP/1.1 200 OK
Server: Tengine
Date: Fri, 05 Aug 2016 08:08:05 GMT
Connection: keep-alive
Vary: Accept-Encoding
Transfer-Encoding: chunked
Content-Type: image/jpeg
Cache-Control: max-age=315360000
Content-Encoding: gzip
Expires: 0
Cache-Control: no-cache
内容...
HTTP实体首部描述了HTTP报文的内容。在这里可以将实体首部和实体主体想象结合成一个箱子,实体首部是箱子上部的描述信息,实体主体则是箱子内货真价实的物品。
响应头的实体首部列表:
Content-Type
Content-Length
Content-Language
Content-Encoding
Content-Location
Content-Range
Content-MD5
Last-Modified
Expires
Allow
ETag
Cache-Control
http的head方法与get方法返回的首行和首部完全相同,不同的是get方法的响应头中会有主体,而head方法在响应中只返回首部,不会返回主体部分,这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。
所以在编写爬虫的时候使用了request.head方法,快捷地获取所需要的Content-Length。但是为何获取的Content-Length是gzip压缩前的大小呢?
Content-Length 实体的大小
Content-Length首部指示出报文实体主体的字节大小,这个大小是包含了所有内容编码的。比如对文本文件进行了gzip压缩的话,Content-Length首部就是压缩后的大小,而不是原始大小。
另外Content-Length首部对于长连接是必不可少的,长连接代表在连接期间会有多个http请求响应在排队,而服务器不能够关闭连接,客户端只能通过Content-Length知道一条报文在哪里结束,下一条报文在哪里开始。
除非使用了分块编码Transfer-Encoding: chunked,否则响应头首部必须使用Content-Length首部。 [摘自http权威指南]
传输编码和分块编码
分块编码把「报文」分割成若干个大小已知的块,块之间是紧挨着发送的,这样就不需要在发送之前知道整个报文的大小了。(也意味着不需要写回Content-Length首部了)
当使用持久连接时,在服务器写主体之前,必须知道它的大小并在Content-Length首部中发送。如果服务器动态创建内容,可能在发送之前无法知道主体大小,分块编码就是为了解决这种情况。服务器把主体逐块发送,说明每一块的大小。服务器再用大小为0的块作为结束块。,为下一个响应做准备。
再回过头看请求file文件服务器的图片时响应头的首部信息发现了这个首部:Transfer-Encoding: chunked
这也说明了这个图片请求的响应是采用分块编码的传输方式,采用这种传输方式进行响应时,没必要带上Content-Length这个首部信息。因为即使带上了也是不准确的。再回过头看上述file图片的响应头中确实没有Content-Length首部。
但是在node中请求http://file.showjoy.com/images/46/4695c19423cd40469fb89836373c1d45.jpg这张图片,是能取得Content-Length的,这是什么原因?
request.head('http://file.showjoy.com/images/46/4695c19423cd40469fb89836373c1d45.jpg', function (error, response, body) {
console.log(response.headers)
})
===>
{ server: 'Tengine',
date: 'Sun, 07 Aug 2016 04:13:08 GMT',
'content-type': 'image/jpeg',
'content-length': '812401',
'last-modified': 'Mon, 11 Apr 2016 09:01:56 GMT',
connection: 'close',
vary: 'Accept-Encoding',
etag: '"570b6804-c6571"',
expires: 'Thu, 31 Dec 2037 23:55:55 GMT',
'cache-control': 'max-age=315360000',
'accept-ranges': 'bytes' }
上述原因在于在node中请求需要加上Accept-Encoding': 'gzip'首部信息,让服务器知道这个请求支持gzip压缩。不加这个首部,服务器就不会采取gzip压缩,同时我司服务器设定也不进行分块编码。所以返回响应头的Content-Length首部是必须的,但是这个值的大小肯定是没有进行过压缩的。
request(
{ method: 'get'
, uri: 'http://file.showjoy.com/images/46/4695c19423cd40469fb89836373c1d45.jpg'
, gzip: true
}
, function (error, response, body) {
// body is the decompressed response body
console.log(response.headers)
}
)
===>
{ server: 'Tengine',
date: 'Sun, 07 Aug 2016 04:16:10 GMT',
'content-type': 'image/jpeg',
'last-modified': 'Mon, 11 Apr 2016 09:01:56 GMT',
'transfer-encoding': 'chunked',
connection: 'close',
vary: 'Accept-Encoding',
expires: 'Thu, 31 Dec 2037 23:55:55 GMT',
'cache-control': 'max-age=315360000',
'content-encoding': 'gzip' }
同理上面请求示例开启了gzip,文件服务器根据这个标识同时开启了分块编码,致使Content-Length没有返回。
那么如何获取开启了分块编码的响应的文件大小呢?以下是node http原生写法,供大家参考。
var options = {
hostname: 'file.showjoy.com',
port: 80,
path: '/images/7a/7add9f81cd9b41a6aba6271c69719f71.jpg',
method: 'GET',
headers: {
'Accept-Encoding': 'gzip'
}
};
var req = http.request(options, function(res) {
console.log('STATUS: ' + res.statusCode);
console.log('HEADERS: ' + JSON.stringify(res.headers));
var chunks = [];
res.on('data', function (chunk) {
chunks.push(chunk);
})
res.on('end', function () {
console.log('SIZE: ' + chunks.toString().length) // file size
})
})
req.write('data\n');
req.end();
原创文章 欢迎转载。
参考:

