
- 1python web服务器部署_pythonweb服务器部署
- 2为什么有35岁「职业危机」的程序员不转做测试呢?_35岁可以从java转测试吗
- 3Anaconda+Cuda+Cudnn+Pytorch(GPU版)+Pycharm+Win11深度学习环境配置_anaconda与cuda,cudnn有什么版本要求
- 4CRT连接报错:Key exchange failed. ... No compatible key exchange method_no compatible key exchange method.
- 5已解决You should consider upgrading via the ‘e: \python\python.exe -m pip install --upgrade pip’ comma
- 6如何实现内网环境公网访问使用cpolar内网穿透
- 7过一遍mysql(4)(第六篇:select查下基础篇;第七篇:select条件查询)_mysql select 常量
- 8谈谈安卓的Bitmap与Drawable_安卓中drawable和bitmap
- 9nodejs新版本引起的:digital envelope routines::unsupported_nodejs升级 express file undefined
- 10遇到:PermissionError: [Errno 13] Permission denied: ‘./data\mnist\train-images-idx3-ubyte 错误应该如何解决
GPT系列训练与部署——GPT2环境配置与模型训练_gpt2本地部署需要什么配置
赞
踩
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
Colossal-AI提供了多种并行方式来运行GPT,不同并行方式的相应配置位于gpt2_configs文件夹下。运行示例程序的教程地址为“https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/gpt”。我们将根据该教程中的步骤来运行GPT训练程序。Colossal-AI环境搭建与运行测试请参考本专栏文章《GPT系列训练与部署——Colossal-AI环境配置与测试验证》,地址为“https://blog.csdn.net/suiyingy/article/details/130209217”。

图1 GPT训练教程页面
本节将重点介绍如何在Colossal-AI中运行GPT程序。更多AIGC类模型训练、推理及部署请参考本专栏文章《Python从零开始进行AIGC大模型训练与推理》,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。我们也会在文末下方公众号中进行同步更新。相关AIGC模型体验会在RdFast小程序中同步上线。
1 环境安装
1.1 Colossal-AI环境
Colossal-AI环境搭建与测试请参考本专栏文章《GPT系列训练与部署——Colossal-AI环境配置与测试验证》,地址为“https://blog.csdn.net/suiyingy/article/details/130209217”。
1.2 ColossalAI-Examples环境
ColossalAI-Examples包含了一些示例程序,例如 GPT训练程序,其环境搭建步骤如下所示。
- git clone https://github.com/hpcaitech/ColossalAI-Examples.git
- cd ColossalAI-Examples
- pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
1.3 Colossal-AI GPT环境
环境安装指令如下所示。其中,LSH安装依赖于早期版本GCC,即版本不易过高。教程指出9.3.0版本gcc满足要求,而10.3.0版本则不满足。
- pip install ftfy langdetect numpy torch pandas nltk sentencepiece boto3 tqdm regex bs4 newspaper3k htmlmin tldextract cached-path -i https://pypi.tuna.tsinghua.edu.cn/simple
- git clone https://github.com/mattilyra/LSH.git
- cd LSH
- python setup.py install
安装LSH时可能报如下错误,解决方式是用Colossal-AI的cMinhash.cpp替换LSH/lsh文件夹下文件,然后重新运行“python setup.py install”。文件替换参考命令为“cp ~/project/ColossalAI-Examples/language/gpt/tools/LSH/cMinhash.cpp lsh/cMinhash.cpp”。
- /root/miniconda3/envs/clai/lib/python3.8/site-packages/numpy/core/include/numpy/__multiarray_api.h: At global scope:
- /root/miniconda3/envs/clai/lib/python3.8/site-packages/numpy/core/include/numpy/__multiarray_api.h:1477:1: warning: ‘int _import_array()’ defined but not used [-Wunused-function]
- _import_array(void)
- ^~~~~~~~~~~~~
- error: command '/usr/bin/gcc' failed with exit code 1
2 数据下载
2.1 url文件下载
GPT2模型的数据集为OpenWebText,主要来源于网页文本,其完整数据集大小为38GB。Colossal-AI提供了OpenWebText数据集的下载地址,即“https://mega.nz/#F!EZZD0YwJ!9_PlEQzdMVLaNdKv_ICNVQ!cc4RgQQZ”。下载后文件为OpenWebText.zip的压缩文件,解压后文件目录为OpenWebText/Version 1/URLs。目录下包括161个文本文件,每个文件记录了网页内容的地址url。
2.2 数据清洗
由于OpenWebText数据集中的部分url可能已经无法访问,所以需要运行如下命令后完成数据清洗。
- cd path/to/tools
- python Megatron/blacklist_urls.py <path/to/URLs> <path/to/clean_urls.txt>
具体示例如下:
- cd ColossalAI-Examples/language/gpt/tools/
- python Megatron/blacklist_urls.py /data/data/clai/data/OpenWebText/Version\ 1/URLs/ /data/data/clai/data/OpenWebText/clean_urls.txt
程序运行完成之后会在指定的路径下生成clean_urls.txt文件,文件包含了经过清洗后的21269934个url地址。
2.3 内容下载
根据清洗后的url地址,我们需要下载其中的网页内容。下载命令如下所示,其中n_procs是线程数量。
- Cd /language/gpt/tools
- python download/download.py <path/to/clean_urls.txt> --n_procs 50 --output <path/to/raw.json>
由于完整数据集下载时间较久,我们可以通过下面的命令仅下载一部分数据。其中,max_urls可指定最多下载的url数量,timeout用于设定url访问的超时时间。设置超时时间的好处是快速跳过无法连接的url地址。
python download/download.py /data/data/clai/data/OpenWebText/clean_urls.txt --output /data/data/clai/data/OpenWebText/raw.json --max_urls 1000 --timeout 30下载后的网页内容存储在所指定路径下的raw.json文件。文件包含了一系列由json格式数据组成的列表,每个json数据对应一个url中的网页内容。Json格式为{'text': text, 'url': unique_url},示例如下所示。
{"text": "The space station looks like an airplane or a very bright star moving across the sky, except it doesn't have flashing lights or change direction. It will also be moving considerably faster than a typical airplane (airplanes generally fly at about 600 miles per hour; the space station flies at 17,500 miles per hour).\n\nBelow is a time-lapse photo of the space station moving across the sky.\n\nThe International Space Station is seen in this 30 second exposure as it flies over Elkton, VA early in the morning, Saturday, August 1, 2015. Photo Credit: NASA/Bill Ingalls\n\nVisit the NASA Johnson Flickr Photostream", "url": "http://spotthestation.nasa.gov/sightings/view.cfm?country=United_States®ion=Arizona&city=Phoenix#.UvPTWWSwLpM"}
图2 raw.json中原始数据
3 数据处理
相关程序位于language/gpt/tools文件夹下。
3.1 删除长度过短的文本。
运行“python Megatron/cleanup_dataset.py <path/to/raw.json> <path/to/clean.json>”可删除长度少于128个token的数据。示例程序如下。程序中提供的cleanup_fix_dataset.py支持更多清理数据选项。清理后的数据保存于clean.json。
python Megatron/cleanup_dataset.py /data/data/clai/data/OpenWebText/raw.json /data/data/clai/data/OpenWebText/clean.json3.2 删除相似数据
程序使用LSH找出可能相似的数据,然后对相似度较高的数据进行分组,每组数据最后仅保留其中一个数据,删除其它所有相似数据。
- #查找相似数据
- python Megatron/find_duplicates.py --inputs <path/to/clean.json> url --output <path/to/process_stage_one.json>
- #相似数据分组
- python Megatron/group_duplicate_url.py <path/to/process_stage_one.json> <path/to/process_stage_two.json>
- #删除相似数据
- python Megatron/remove_group_duplicates.py <path/to/process_stage_two.json> <path/to/clean.json> <path/to/dedup.json>
示例程序如下,处理后结果保存在dedup.json。
- python Megatron/find_duplicates.py --inputs /data/data/clai/data/OpenWebText/clean.json url --output /data/data/clai/data/OpenWebText/process_stage_one.json
- python Megatron/group_duplicate_url.py /data/data/clai/data/OpenWebText/process_stage_one.json /data/data/clai/data/OpenWebText/process_stage_two.json
- python Megatron/remove_group_duplicates.py /data/data/clai/data/OpenWebText/process_stage_two.json /data/data/clai/data/OpenWebText/clean.json /data/data/clai/data/OpenWebText/dedup.json
3.3 打乱数据顺序
使用命令“shuf <path/to/dedup.json> -o <path/to/train_data.json>”随机打乱数据,并保存于train.json。处理后的数据结构与第二部分的数据结构完全一致,即{'text': text, 'url': unique_url}。
shuf /data/data/clai/data/OpenWebText/dedup.json -o /data/data/clai/data/OpenWebText/train_data.json4 中文数据集处理
中文数据集使用的是浪潮提供的“源数据”,可在“ https://air.inspur.com/home”网站进行申请。其分词表下载地址为“https://github.com/Shawn-Inspur/Yuan-1.0/blob/main/src/vocab.txt”。完整源数据下载后的目录结构形式如下所示。
- |--dataset
- | |--001.txt
- | |--002.txt
- | |--...
- |--vocab.txt
使用该数据集训练时需要替换train_gpt.py的44行,如下所示。
- import dataset.yuan import YuanDataset
- train_ds = YuanDataset(os.environ['DATA'], vocab_path='/path/to/data/vocab.txt'seq_len=gpc.config.SEQ_LEN)
5 模型训练
5.1 设置训练数据路径
这里以OpenWebText数据集来进行训练。数据集路径可以通过设置环境变量的方法来进行设置,即“export DATA=/path/to/train_data.json”,也可通过将train_gpt.py的第44行更改为“ train_ds = WebtextDataset('/data/data/clai/data/OpenWebText/train_data.json', seq_len=gpc.config.SEQ_LEN)”来实现。
5.2 模型训练
模型训练命令为“colossalai run --nproc_per_node=<num_gpus> train_gpt.py --config=gpt2_configs/<config_file>”。其中,num_gpus为GPU数量,config可加载不同配置的GPT2或GPT3训练参数。
示例程序为“colossalai run --nproc_per_node=2 train_gpt.py --config=gpt2_configs/gpt2_vanilla.py”。运行过程中两块GPU分别占用显存4621MB。训练过程如下图所示。如果运行报错,请继续阅读下面内容。

图3 GPT2训练示意图
其它GPT2模型训练配置下的显存和并行训练方式如下表所示。TP、PP和DP代表三种并行模式,分别表示Tensor Parallel、Pipeline Parallel、Data Parallel。GPU数量由三者相乘得到,即TP * PP * DP,且DP取值是自动计算的。
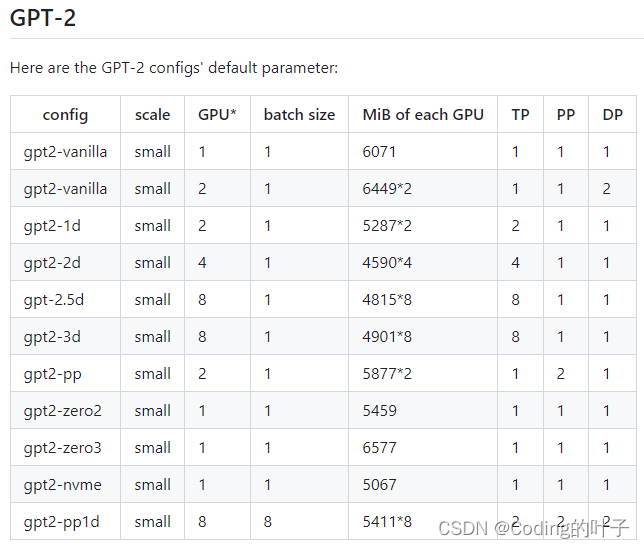
图4 GPT2训练配置
如果运行报错“ModuleNotFoundError: No module named 'colossalai.zero.init_ctx'”,那么建议通过pip uninstall卸载colossalai,并重新通过pip install colossalai进行安装。安装过程中建议不使用镜像或更换不同镜像,这是因为个别镜像网站上的资源可能仍然存在该问题。
如果运行报错“KeyError: 'SLURM_PROCID'”,那么需要将运行命令替换为“colossalai run --nproc_per_node=2 train_gpt.py --config=gpt2_configs/gpt2_1d.py --from_torch”,即增加--from_torch。
6 配置文件介绍
配置文件可参考官方介绍,主要是并行方式、训练迭代次数、Batch Size和隐藏变量维度设置,https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/gpt。这里不作额外介绍,后续文章将结合训练程序调试过程详细介绍。
GPT3模型训练参数配置如下所示。
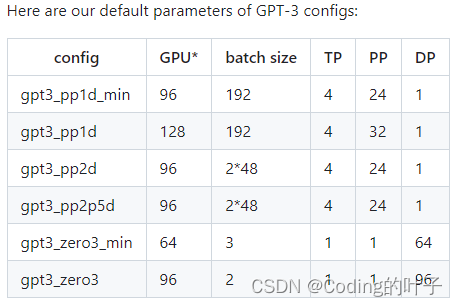
图5 GPT3训练配置
更多AIGC类模型训练、推理及部署请参考本专栏文章《Python从零开始进行AIGC大模型训练与推理》,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。我们也会在文末下方公众号中进行同步更新。相关AIGC模型体验会在RdFast小程序中同步上线。
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。

