
- 1Git 关于SSH密钥的生成
- 21.4_12 Axure RP 9 for mac 高保真原型图 - 案例11 【动态面板-滚动条1】_axure动态面板滚动条样式可以修改吗
- 3解决Could not autowire.No beans of ‘ ‘ type found
- 4为微软键盘添加小鹤双拼——编程学习_微软拼音如何添加小鹤双拼
- 5IPC进程间通信 D-Bus(Desktop Bus)快速入门(以libdbus-glib库为例)_arm unable to get on d-bus
- 6react-native 修改android打包的包名_react native 修改release包名称apk
- 7Java小区车位智能管理系统(毕设源码+mysql+lw)_小区车位检测管理系统毕业设计
- 8numpy常用函数学习
- 9论文阅读-Time-series clustering – A decade review_time series cluster
- 10【开发问题】vue的前端和java的后台,用sm4,实现前台加密,后台解密_sm4 addprovider
[人工智能-深度学习-39]:环境搭建 - 训练主机硬件选择全指南(CPU/GPU/内存/硬盘/电源)_台式机 大模型训练
赞
踩
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121207211
目录
2.1 GPU是深度学习训练的必然选择:为什么需要选择GPU
前言
深度学习是非常消耗计算资源的,毫无疑问这就需要多核高速的CPU。
但买一个更快的CPU有没有必要?
在构建深度学习系统时,最糟糕的事情之一就是把钱浪费在不必要的硬件上。
本文探讨如何使用低价的硬件构建一个高性能的训练系统。
第1章 汇总
1.1 选择台式机还是笔记本
(1)笔记本适用场合(没有太多的要求)
- 理论学习
- 浅层网络训练
- 深层网络运算
(2)台式机(有一定的性能)
- 深度网络训练 (AlexNet之后的网络,就需要GPU训练了)
- 通过增加GPU卡,升级并行计算性能
- 通过升级RAM,升级主机的内存
- 通过升级CPU, 提升CPU的性能
- 通过硬盘,扩充数据集和模型的数量
因此,建议配置一台台式机。
1.2 简单汇总
(1)GPU:
- RTX 2070 (高)、RTX 2080 Ti、
- GTX 1070 、GTX 1080, 和 GTX 1080 Ti
- 内存>=8G
(2)CPU:

- 每个GPU分配1-2个两个CPU核,这取决于你是怎么处理数据的。
- 对于2个GPU的系统,4核CPU就可以了。i5或i7即可,i9超配。
- 频率 > 2GHz。CPU应该要能够支持你要运行的GPU数量。
- PCIE通道并不重要。
(3)RAM:
- 最少要购买和你最大的GPU显存大小的内存, 如果GPU是8G, 内存至少8G。
- 只有在需要的时候再购买更多的内存
- 如果你经常处理大数据集的话,更多的内存是非常有帮助的。
- -时钟频率不重要 - 买最便宜的内存
(4)硬盘/SSD:
- 存放数据的硬盘(500G)
- 使用SSD可以快速处理小数据集
(5)电源
- - 把GPU和CPU需要的功率瓦数加起来,然后乘以总数的110%得到需要的功率瓦数
- - 如果使用多个GPU,要选择高效率的电源。
- - 确保电源有足够的PCIE接口(6+8引脚)
(6)散热
- - CPU:使用标准的CPU散热或者是一体式的水冷解决方案
- - GPU:风扇散热
- - 如果购买多个GPU的话使用“鼓风式”的风扇
- - 在Xorg配置中设置coolbits标志以控制风扇速度
(7)主板
- - 为(未来的)GPU预留尽可能多的PCIe插槽(一个GPU需要两个插槽;每个系统最多4个GPU)
(8)显示器
- - 一个额外的显示器比一个额外的GPU更能提高你的效率
第2章 台式机的GPU选择
2.1 GPU是深度学习训练的必然选择:为什么需要选择GPU
假设你将用GPU来进行深度学习或者你正在构建或者升级用于深度学习的系统,那么抛开GPU是不合理的。GPU是深度学习应用的心脏——训练过程速度的提升是非常的大的,不容忽视。
(1)白话说法
简单的讲, CPU的并行计算的性能太差,GPU可以是CPU计算性能几十倍到上百倍。
AlexNet之前的深度学习网络的训练,CPU是可以搞定的,十几分的训练时间。
然后到AlexNet网络,通用的CPU就非常吃力了,这么浅层的神经网络,需要按天的训练时间 ,对于学习者而言,很显然是不合适的。
但如果选GPU, CPU一天才能训练完成的,GPU可能只需要1个小时。通用CPU半小时完成的,GPU只需要一分钟。这对于提升学习效率是非常有帮助的。
(2) 专业说法
对于深度学习训练来说,GPU已经成为加速器的最佳选择。大多数计算本质上是并行的浮点计算,即大量的矩阵乘法,其最佳性能需要大量的内存带宽和大小,这些需求与HPC的需求非常一致,GPU正好可以提供高精度浮点计算、大量VRAM和并行计算能力。
2.2 GPU选择的常见错误
如何选择GPU在深度学习系统中相当关键。
在选择GPU时,你可能会犯这三个错误:(1)性价比不高,(2)内存不够大,(3)散热差。
2.3 为什么要选择英伟达NVIDIA的GPU?
总的来说,本地运算首选英伟达GPU,它在深度学习上的支持度比AMD好很多;
云计算首选谷歌TPU,它的性价比超过亚马逊AWS和微软Azure。
学习“深度学习”,几乎必须使用英伟达品牌的显卡,这已经成为了一种“惯例”或者说“主流”。
这并不是因为NVIDIA的性能表现或者内在的硬件架构更加适合进行深度学习的训练,而是因为N卡能够支持NVIDIA开发的高效的CUDA库。该库可以说是抢占到了市场先机,因此迅速占据了大量市场,一些基于CUDA编写的深度学习开源项目,进一步强化了这种马太效应。
而AMD(或者说ATI),并没有把握住市场先机。尽管它也推出了自己的ROCm,但是仿佛并不算很流行。基于ROCm编写的深度学习项目更是鲜有。
也就是主要得益于驻留的深度学习框架提供CUDA库的支持。
2.4 什么是CUDA库
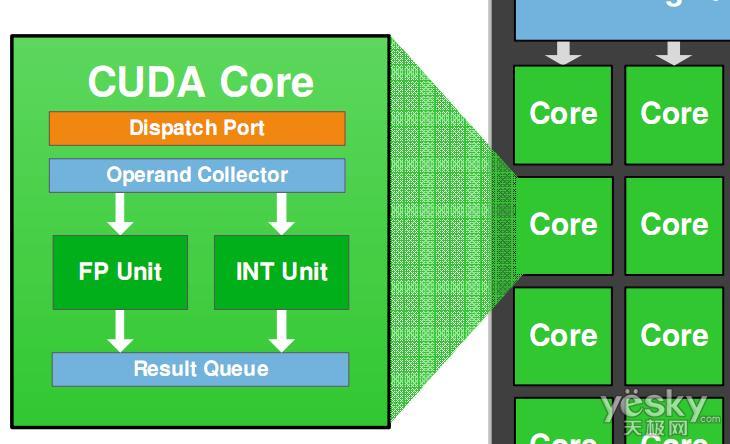
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。
CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
它包含了CUDA指令集架构(ISA)以及算GPU内部的并行计引擎。
通过CUDA运算平台,程序员和深度学习框架,都不需要关心,如何把需要计算任务,分配到不同的GPU核上执行。GPU核的管理,有CUDA完成。
开发人员可以使用C语言来为CUDA™架构编写程序,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
该架构为大多数的深度学习框架所支持。
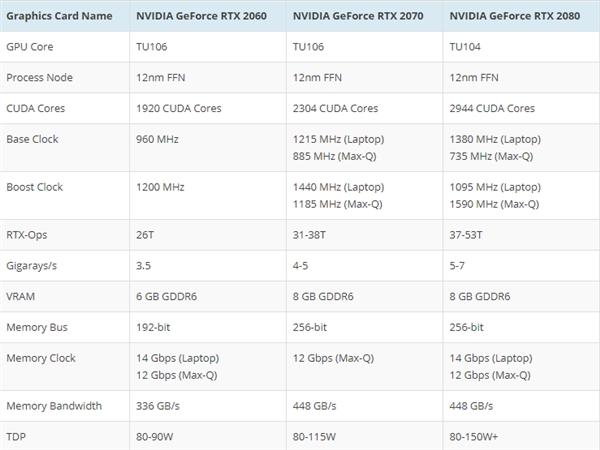
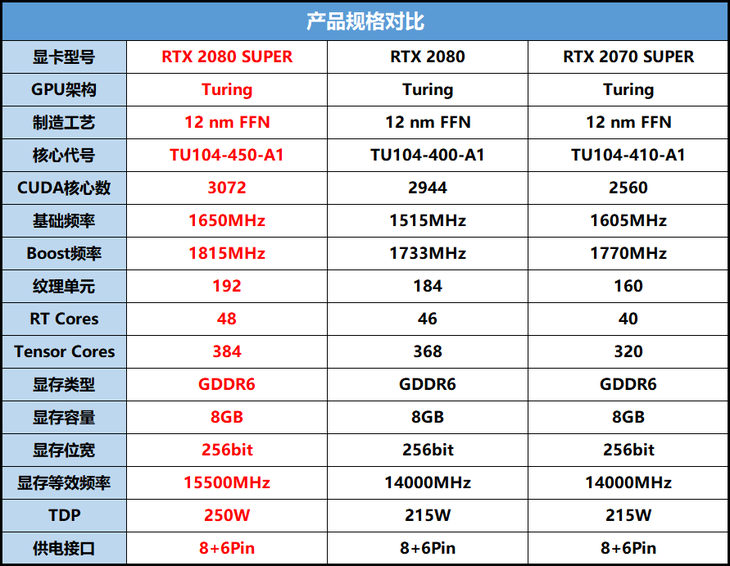
2.5 NVIDIA GPU的型号
NVIDIA GPU 比较表 | NVIDIA![]() https://www.nvidia.cn/studio/compare-gpus/(1)RTX系列
https://www.nvidia.cn/studio/compare-gpus/(1)RTX系列
(2)GTX系列 (适合移动端)
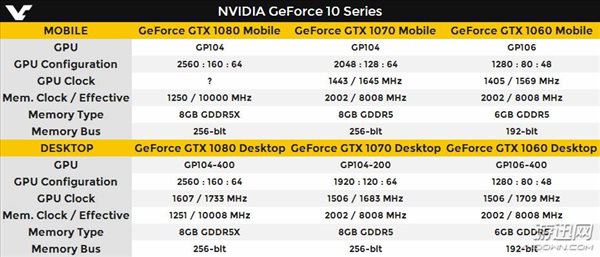
2.6 性能比较
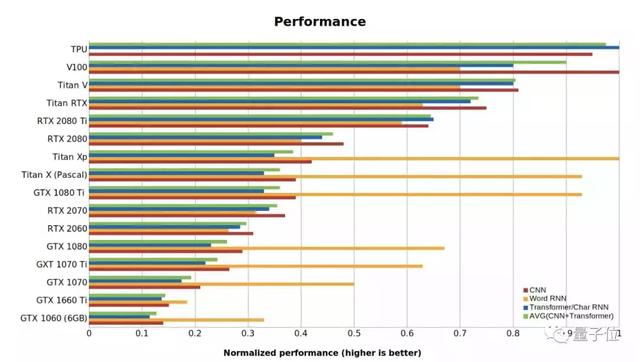
RTX 2080 > GTX1080 > RTX2070 > RTX2060 > GTX1070 > GTX1060
2.7 型号选择
性价比方面,通常推荐 RTX 2070或者 RTX 2080 Ti。使用这些显卡的时候,你应该使用16位的模型,除此以外,GTX 1070, GTX 1080 和 GTX 1080 Ti 是非常好的选择,选择他们时,可以使用32位的模型,但不能是16位的模型。
在选择GPU时,要十分留意你的内存需求。在消耗同样内存的情况下,相比GTX,能跑16位模型的RTX能够训练2倍大小的模型。正是因为RTX有着内存优势,选择RTX、学习高效地使用16位模型,能够带给你更好的的使用体验。
GPU对内存取决于使用GPU的目的:
- 追求最高水平分数的研究:>=12 GB
- 探寻有趣架构的研究:>=8 GB
- 其他的研究:8 GB
- Kaggle:4 – 8 GB
- 初学者:8 GB (但是要注意检查下应用领域的模型大小)
- 企业:8 GB 用于原型, >=11 GB 用于训练
在买了多块RTX显卡时,需要留意散热问题。
如果你想将 GPU 固定在彼此相邻的 PCIe 插槽中,应该确保使用带有鼓风机式风扇的 GPU。
否则,您可能会遇到温度问题,并且您的 GPU 速度会变慢(约30%)并且损耗得更快。
2.8 GPU选择建议
训练阶段使用TPU,原型设计和推理阶段使用本地GPU,可以帮你节约成本。
如果对项目deadline或者灵活性有要求,请选择成本更高的云GPU。
总之,在GPU的选择上有三个原则:
1、至少选GTX 1060,或更好的GPU;
2、购买带有张量核心的RTX GPU;
3、在GPU上进行原型设计,然后在TPU或云GPU上训练模型。
针对不同研究目的、不同预算,给出了如下的建议:
最佳GPU:RTX 2070
避免的坑:所有Tesla、Quadro、创始人版(Founders Edition)的显卡,还有Titan RTX、Titan V、Titan XP
高性价比:RTX 2070(高端),RTX 2060或GTX 1060 (6GB)(中低端)
穷人之选:GTX 1060 (6GB)
破产之选:GTX 1050 Ti(4GB),或者CPU(原型)+ AWS / TPU(训练),或者Colab
Kaggle竞赛:RTX 2070
计算机视觉或机器翻译研究人员:采用鼓风设计的GTX 2080 Ti,如果训练非常大的网络,请选择RTX Titans
NLP研究人员:RTX 2080 Ti
已经开始研究深度学习:RTX 2070起步,以后按需添置更多RTX 2070
尝试入门深度学习:GTX 1050 Ti(2GB或4GB显存)
第3章 台式机的CPU选择?
3.1 常见错误
(1)人们常犯的第1个常见错误是花太多的时间纠结CPU的PCIe通道数。
其实,你并不需要太在意CPU的PCIe通道数。取而代之的是,应该注重你的CPU和主板的组合是否能够支撑起想要运行的GPU数量。
(2)第2个最常见错误是购买功能过于强大的CPU。
3.2 CPU概述
CPU的全称是Central Processing Unit,而GPU的全称是Graphics Processing Unit。在命名上。这两种器件相同点是它们都是Processing Unit——处理单元;不同点是CPU是“核心的”,而GPU是用于“图像”处理的。在我们一般理解里,这些名称的确非常符合大众印象中它们的用途——一个是电脑的“大脑核心”,一个是图像方面的“处理器件”。但是聪明的人类并不会被简单的名称所束缚,他们发现GPU在一些场景下可以提供优于CPU的计算能力。
于是有人会问:难道CPU不是更强大么?这是个非常好的问题。为了解释这个疑问,我们需要从CPU的组织架构说起。由于Intel常见的较新架构如broadwell、skylake等在CPU中都包含了一颗GPU,所以它们不能作为经典的CPU架构去看待。我们看一款相对单纯的CPU剖面图

这款CPU拥有8颗处理核心,其他组件有L3缓存和内存控制器等。
可以见得该款CPU在物理空间上,“核心”并不是占绝大部分。就单颗Core而言(上图CPU属于Haswell-E架构,下面截图则为Haswell的Core微架构。“Intel processors based on the Haswell-E microarchitecture comprises the same processor cores as described in the Haswell microarchitecture, but provides more advanced uncore and integrated I/O capabilities. ”——《64-ia-32-architectures-optimization-manual》)
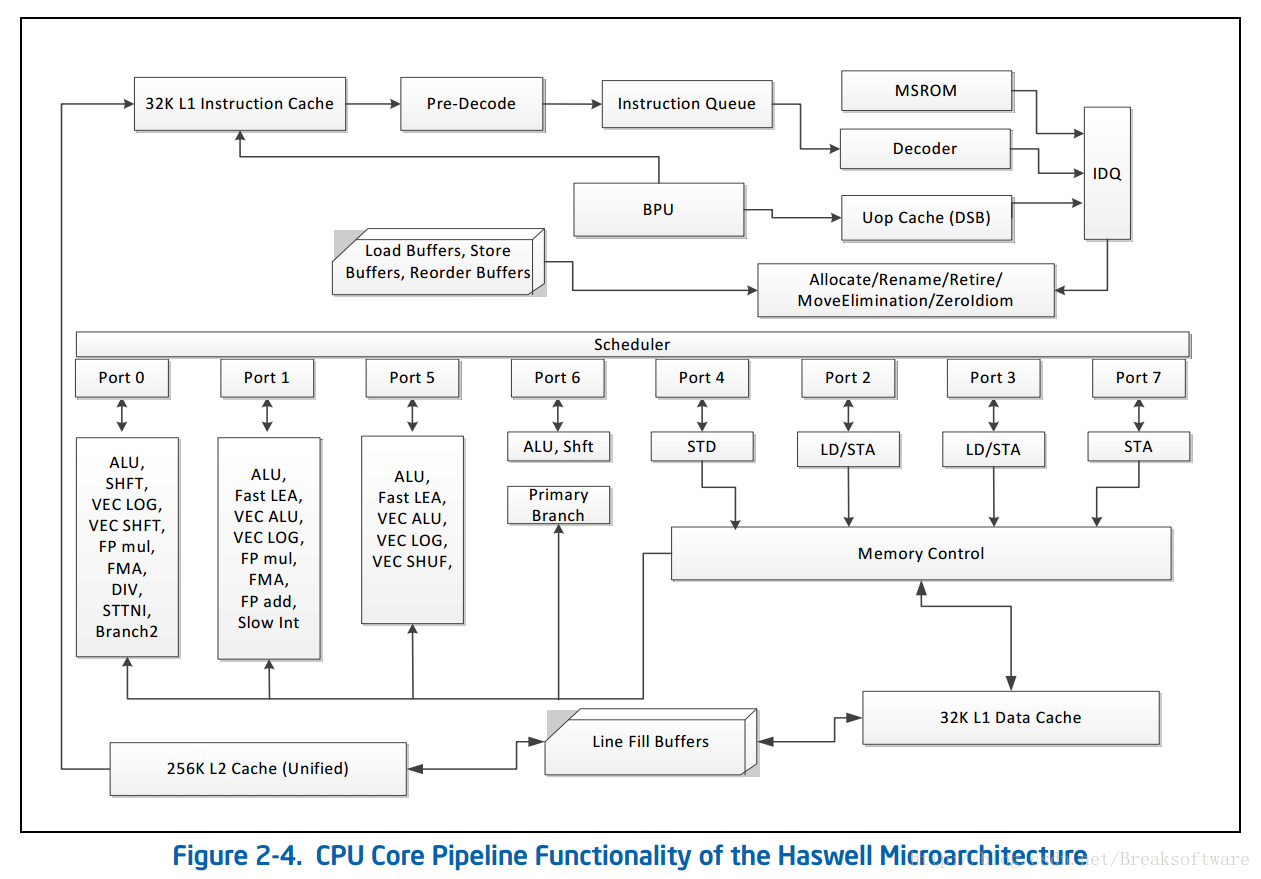
可以看到,CPU有20多种“执行单元”(Execution Units), 如ALU、FMA、FP add和FP mul等。
每个“执行单元”用于处理的数据运算。
3.3 CPU的优势在与复杂的逻辑运算
可以见得,CPU是个集各种运算能力的大成者,擅长处理复杂的逻辑运算。
这就如同一些公司的领导,他们可能在各个技术领域都做到比较精通。但是一个公司仅仅只有这样的什么都可以做的领导是不行的,因为领导的价值并不只是体现在一线执行能力上,还包括调度能力。
CPU是一个拥有多种功能的优秀领导者。它的强项在于“调度”而非纯粹的计算。
而GPU则可以被看成一个接受CPU调度的“拥有大量计算能力”的员工。
3.4 CPU的发展瓶颈

可以见得CPU的主频在2000年以前还是符合摩尔定律的。
但是在2005年左右,各大厂商都没有投放更高主频的CPU(理论上现在主频应该达到10GHz了),有的反而进行了降频。为什么?
(1)CPU的主频发展在当前环境下已经接近极限,而且功耗也会随着主频增加而增加。
(2)通过增加核数提升了性能,最近10来年,市面上桌面版intel系列CPU还是集中在2、4、8核心数。
3.5 intel CPU的型号与选择
市面上台式机CPU目前主要分为intel和AMD两大品牌,虽然只有两家,但是在产品的竞争中,战场硝烟从未停止,尤其是AMD近几年推出锐龙产品,对标intel家酷睿,利用性价比优势抢占了部分市场份额。那么目前热门性价比CPU有哪些型号?

Inetel的CPU分为高中低端:
如今的酷睿系列处理器已经到了11代了,酷睿系列队伍从i3、i5、i7扩充到了i9和X。
最低端的G系列,然后是低端i3系列,中端i5系列,高端i7系列和至尊i9系列。

为了不至于过早的遭到淘汰,可以选择i7系列:8核。
3.6 CPU选择的注意事项
人们常犯的最大错误是:
(1)花太多的时间纠结CPU的PCIe通道数(外设的访问速度)
其实,你并不需要太在意CPU的PCIe通道数。取而代之的是,应该注重你的CPU和主板的组合是否能够支撑起想要运行的GPU数量。
CPU和PCI-Express(新一代总线接口)
很多人痴迷于PCIe的通道数。然而,事情的真相是PCIe(的通道数)几乎不会影响深度学习的表现。如果你只有一个单一的GPU,PCIe通道唯一的作用是能够快速地将数据从你的CPU 内存中转换到GPU 内存中。但是,一个具有32张图片的ImageNet数据集批次(数据集的shape为32*225*225*3)和32位模型,在16通道PCIe上训练需要1.1毫秒,在8通道上需要2.3毫秒,在4通道上需要4.5毫秒。这些仅仅是理论上的数值,而在实际中你常常会发现PCIe会比理论速度慢上两倍——但是它仍然像闪电一样快。PCIe 通道的延时通常在纳秒范围内,因此其延时问题可以被忽视。
综上考虑后,我们提出了使用152层残差网络训练一个具有32张图片的小批量ImageNet数据集所需的时间,如下所示:
- 向前传播和向后传播用时:216毫秒(ms)
- 使用16通道PCIe将数据从CPU内存转换到GPU内存用时:大概2ms(理论上1.1ms)
- 使用8通道PCIe将数据从CPU内存转换到GPU内存用时:大概5ms(理论上2.3ms)
- 使用4通道PCIe将数据从CPU内存转换到GPU内存用时:大概9ms(理论上4.5ms)
因此将4通道的PCIe换成16通道的PCIe将给你的训练表现带来大概3.2%的提升。然而,如果你的pyTorch数据下载器含有CUDA页锁定内存,那么(改变PCIe的通道)其实给你的训练表现带来的提升是0%。所以如果你仅使用1个GPU,那么不要把你的钱浪费在PCIe上!
当你在选择CPU的PCIe通道和主板PCIe通道时,(一定要)明确所选的CPU和主板组合能够支持期望的GPU数量。
如果你买了一个支持2个GPU的主板,并且你最终确实需要用到2个GPU,那么就需要确认你购买的CPU能够支持2个GPU,而没有必要纠结PCIe的通道数。
PCIe通道数和多GPU并行
如果你在多GPU上并行的训练数据时,PCIe的通道数是重要的吗?
如果你有96个GPU那么PCIe的通道数确实非常重要。
然而如果你只有4个或者更少的GPU,那么PCIe通道数的影响不大。
如果在两到三个GPU上训练,完全不会关心PCIe的通道数。
由于大多数会在超过4个GPU上面运行一个系统,那么记住一个经验准则:不要为了在每个GPU中得到更多的PCIe花额外的钱——这没有必要!
(2)第二个最常见错误是购买功能过于强大的CPU。
所需的 CPU 核数
为了能够在CPU上作出明确的选择,我们首先需要了解CPU以及它和深度学习间的关系。
CPU为深度学习做了什么?
当你在一个GPU上运行你的深度网络时,CPU仅进行很简单的运算。它主要主要(1)启动GPU函数调用,(2)执行CPU函数。
目前,CPU最大的应用是数据预处理。常用的两种数据预处理策略有着不同的CPU需求。
一种策略是在训练过程中进行预处理:
循环以下(三个)步骤:
- 1. 导入小批量数据
- 2. 预处理小批量数据
- 3. 训练小批量数据
第二种预处理策略是在训练之前进行预处理操作:
- 1. 导入数据
- 2. 循环以下(两个)步骤:
- 1)导入小批量数据
- 2)训练小批量数据
对于第一种策略,一个多核CPU可以明显地加强训练表现。
对于第二种策略,你不需要一个很好的CPU。
对第一种训练策略,建议每个GPU至少有4个线程——通常每个GPU有两个核心。
对于第二种策略,建议每个GPU最少有2个线程——通常每个GPU有一个核心。
如果你使用第二种策略,那么更多的内核并不会给你带来明显的性能提升。
因此:
- 1个GPU时,CPU核数需要4核
- 2个GPU时, CPU核数需要8核
所需的 CPU 主频(时钟频率)
当人们考虑(购买)快速的CPU时,他们通常首先查看时钟频率。4GHz的CPU比3.5GHz的好,是吗?这对于比较具有相同结构的处理器来说通常是正确的,例如“Ivy Bridge微架构”,但是对于不同架构的处理器来说这并不好比较。此外,CPU主频并不总是衡量性能的最佳方法。
在深度学习中CPU仅仅做一些微不足道的计算:增加一些参数,评估布尔表达式,在GPU或程序内进行函数调用——这些都取决于CPU核心的时钟频率。
虽然这些理由看似合理,但是当我运行深度学习程序时却发现CPU使用率为100%,那么这是为什么呢?为了找寻答案,有人做了一些CPU降频实验。
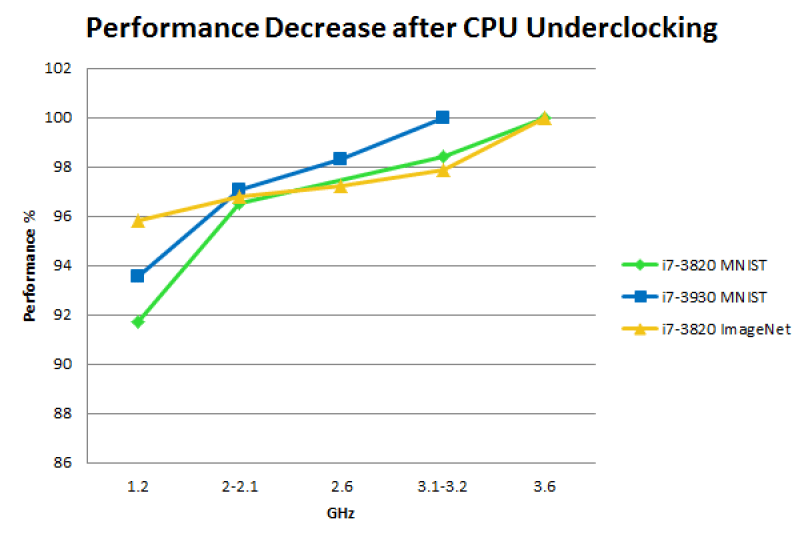
在MNIST和ImageNet数据集上的GPU降频实验:不同CPU时钟频率的性能以训练200个epoch的MNIST数据集和50个epoch的ImageNet数据集所花费的时间来衡量, 其中最大的时钟频率作为每个CPU的基线。作为比较:从GTX 680升级到GTX Titan的性能提升约为 15%; 从GTX Titan到GTX 980又提升20%的性能; GPU超频可为任何GPU带来5%的性能提升。
值得注意的是,这些实验是在落后过时的硬件设备上进行的,然而,对于现代的CPU/GPU它的结果仍然不变。
总之,CPU的频率最训练的性能影响非常小。
第4章 台式机的内存选择
4.1 内存
购买内存最大的错误就是买了主频太高的内存。
第二个错误是没有购买足够大的内存,导致在原型构建上出问题。
(1)需要的主频
主频是内存公司引诱你购买“更快”的内存的一种营销手段,实际上几乎没有产生任何性能的提升。这个关于RAM的视频很详细地解释了内存在Linux上的技术窍门:内存速度真的重要吗?
此外,重要的是要知道内存速度与快速CPU RAM-> GPU RAM传输几乎无关。这是因为(1)如果你使用固定内存(pinned memory),那么你的mini-batch会直接传输到GPU中而不需要CPU的干预,(2)如果你不使用固定内存的话,快的和慢的内存获得的性能差别只有0-3%——把你的钱花到别处去!
(2)内存大小
内存大小不会影响到深度学习的性能。
但是,它可能会阻碍你轻松执行GPU代码(无需交换到磁盘)。
你应该有足够的内存来愉快地配合GPU工作。
这意味你至少应该有匹配GPU的内存大小。比如说,如果你有一张24GB显存的Titan RTX,那你至少应该有24GB的内存。
但是,如果你有多块GPU的话,你不需要更多的内存。
“在内存上匹配最大的GPU显存”策略在于,如果你在处理大数据集时,你可能够还是会内存不足。最好的方式是和你的GPU匹配,如果你觉得内存不够,再买更大的内存。
通常情况下,32G的内存可以了。
第5章 台式机的硬盘选择
一般来说硬盘不是深度学习的瓶颈。主要的影响,就是硬盘的文件到内存的读取的效率。
5.1 HDD机械硬盘
5.2 SSD固态硬盘
固态硬盘(Solid State Disk或Solid State Drive,简称SSD),又称固态驱动器,是用固态电子存储芯片阵列制成的硬盘。
普通硬盘为机械硬盘,从生产效率来说,选择SSD,因为程序启动反应更快,大文件的预处理速度也更快。另外,NVMe SSD会带给你更好的使用体验。
5.3 比较
(1)两者最大区别是固态硬盘由多个闪存颗粒和主控芯片组成,没有运动结构设计,而机械硬盘采用的是碟盘和读写磁头组成;
(2)固态硬盘读写速度快:采用闪存作为存储介质,读取速度相对机械硬盘更快。固态硬盘不用磁头,寻道时间几乎为0,持续写入的速度较高;
(3)固态硬盘防震抗摔性好:传统硬盘都是磁碟型的,数据储存在磁碟扇区里。而固态硬盘是使用闪存颗粒(即mp3、U盘等存储介质)制作而成,所以SSD固态硬盘内部不存在任何机械部件;这样即使在高速移动甚至伴随翻转倾斜的情况下也不会影响到正常使用,而且在发生碰撞和震荡时能够将数据丢失的可能性降到最小。相较传统硬盘,固态硬盘占有绝对优势;
(4)固态硬盘低功耗:固态硬盘的功耗上要低于传统硬盘;固态硬盘无噪音:固态硬盘没有机械马达和风扇,工作时噪音值为0分贝。基于闪存的固态硬盘在工作状态下能耗和发热量较低(但高端或大容量产品能耗会较高)。内部不存在任何机械活动部件,不会发生机械故障,也不怕碰撞、冲击、振动。由于固态硬盘采用无机械部件的闪存芯片,所以具有了发热量小、散热快等特点;
对于深度学习,是什么内存,对训练性能的影响不大。
5.4 硬盘大小
由于数据集需要加大的内存空间,最好选择500G以上的硬盘。
第6章 电源PSU
6.1 电源的功率需求
你得确保你的电源能够满足所有预留GPU的功率需求。
一般来说,GPU能耗会越来越低,所以不用更换电源,买个好的电源是个值当的买卖。
在计算需要的功率时,你最好加上所有CPU和GPU功耗的10%作为功率峰值的缓冲。举个例子,你有四个250瓦的GPU和一个150瓦的CPU,那我们需要一个最少4×250 + 150 + 100 = 1250瓦的电源。一般我会加上至少10%来确保一切正常,那么在这种情况下一共需要1375瓦。最后需要买一个1400瓦的电源。
你得注意有些电源即使达到了要求的功率,但是没有足够的8针或者6针PCIe插槽接口。你得多多注意这点。
另外请尽量购买高功率功效的电源——特别是你运行多个GPU且长时间运行。
满负载运行一个4GPU系统(1000-1500瓦)来训练卷积神经网络两周会消耗300-500千瓦时。
鉴于此,如果GPU的个数超过1,就不建议在个人电脑上进行训练了,可以选择利用公司的资源进行训练。
第7章 CPU 和 GPU 的冷却系统
冷却非常重要,是整个系统中一个重要的瓶颈。
相比较于糟糕的硬件选择,它更容易降低性能。
对于CPU,你可以使用标准散热器或者一体化(AIO)水冷解决方案。
但是对于GPU,你需要特别注意。
风冷 GPUs
如果你有多颗GPU并且他们中间有足够的空间(在3-4颗GPU的位置放置2颗GPU),风冷是安全可靠的。
当你想去冷却3-4颗GPU的时候,可能会犯一个巨大的错误。这时候你需要认证考虑在这个案例中的选择。
运行一个算法的时候,现代GPU会提高他们的速度以及功耗,直至最大值。
一旦GPU达到温度临界值(通常为80°C),GPU就会降低运算速度防止达到温度阙值。这样可以在保持GPU过热的同时实现最佳性能。
对于深度学习程序而言,典型的风扇速度预编程时间表设计得很糟糕。启动一个深度学习程序后几秒钟就会达到温度阙值,结果就是性能会下降0-10%。多个GPU之间相互加热,性能会下降的更明显(10%-25%)。
因为 NVIDIA GPU 在大部分情况下是作为游戏 GPU,它们对windows进行了优化。在Windows中点一点鼠标就能改变风扇计划的方式在Linux中行不通。可是大多数深度学习库都是针对Linux编写。
如果你有一台Xorg服务器(Ubuntu),唯一的选项是用“coolbits”来设置温度。对于单个GPU来说,这种方法非常奏效。当有多个GPU的时候,其中一些没有监视器,模拟出监视器来监测他们是很艰难晦涩的工作。我曾经花过很长的时间尝试使用实时启动CD来恢复我的图形设置,但是从没有在无监视器GPU上成功运行过。
在风冷系统下运行3-4颗GPU需要尤其重视风扇设计。“鼓风机式”风扇设计让冷风进入GPU,然后从机箱背部吹出热风。“非鼓风机式”风扇吸入GPU附近的空气来冷却它。但是如果是多颗GPU,那么它们的周围就没有冷空气,使用“非鼓风机式”风扇的GPU会越来越热,最终通过降低性能来降温。我们应该不惜一切代价来必变在3-4颗GPU的环境中使用“非鼓风机式”风扇。
多GPU使用的水冷系统
另一种更棒更昂贵的方式是使用水冷系统。如果你只有一颗GPU或者两颗GPU之间有足够的空间(比如在3-4颗GPU的主板上有两颗GPU),不建议使用水冷系统。
在4GPU配置中,水冷保证即使最强劲的GPU也能保持低温,而这在风冷中是不可能实现的。水冷的另一个优点是运行很安静,这对于在公共区域运行多GPU来说是一个巨大的优势。
每颗GPU需要100美金的成本安装水冷,另外需要一些额外的前期成本(大约50美金)。组装有水冷的计算机也会需要一些额外工作,但是不用担心,会有详细的指南来指导你安装,仅仅需要你多付出几个小时。维护工作也没有那么的复杂费力。
一个冷却的案例
大型的塔式服务器在GPU位置有额外的风扇,所以我为深度学习集群购买了他们。然后我发现太不划算了,只下降了2-5°C却要付出大量的投资。最重要的部分是直接在GPU上安装冷却系统,完全没必要为冷却系统买贵不啦叽的壳子。
冷却的总结
对于一个GPU来说,风冷足够了。如果你有多个GPU, 你可以在接受性能损失(10% - 15%)的情况下使用“鼓风式”风冷系统,或者花更多的钱购置水冷系统,虽然难以设置但是它可以保证没有性能损失。对于不同的场景,我们可以因地制宜选择风冷或者水冷。我建议使用风冷就好--使用“鼓风式”GPU。如果你想使用水冷, 请使用一体化水冷(AIO)方案。
第8章 其他
8.1 主板
你的主板上应该有足够的PCIe端口来支持你需要运行的GPU数量(即使你有更多的PCIe 插槽,但是一般限制最多4颗GPU);
另外,铭记大部分GPU都会占据两个PCIe卡槽的宽度,所以如果想使用多颗GPU,请确保购买的主板有足够的预留空间。主板不仅需要有足够的PCIe插槽位置,而且需要支持你购买的GPU。
8.2 电脑机箱
买个能放下全尺寸长度GPU的机箱。
大部分的机箱都没问题,不过还是查看尺寸规格来确保没有买了个小号的。
另外如果使用定制化水冷系统,得确保你的机箱有足够空间来放置散热器。因为每个GPU的散热器都需要单独的空间。
8.3 显示器
当使用多显示器的时候,生产力提升很多。只有一台显示器的话,我会感觉完全干不了活。
第9章 台式机的型号选择
9.1 机型与品牌
9.2 新机还是二手机?
如果资金紧张,由需要较高性能的配置,可以考虑选择8-9成新的二手,价格可以降低一半。
参考:
https://www.sohu.com/a/330189099_717210
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121207211

