
- 1令人不悦的Error--requests.exceptions.ProxyError
- 2python 安装serial及No module named ‘serial.tools‘等问题解决方案_no module named 'serial.tools
- 3windows怎么在文件夹中打开终端_怎么在某个文件夹里打开终端
- 4TurtleBot4快速入门教程-远程PC安装
- 5Linux C 程序性能测试 valgrind callgrind分析函数耗时、perf分析函数CPU消耗_valgrind cpu使用率分析
- 6【正点原子STM32连载】 第三十七章 DAC输出实验 摘自【正点原子】APM32E103最小系统板使用指南
- 7jwt使用详解_jjwt使用
- 8阿里云服务器(Ubuntu 12.04 64位)搭建 Nginx、MySQL、PHP Web服务器 (一)_阿里云搭建php nginx web服务器
- 9关于支持向量机(SVM)的一个简单应用实例及matlab代码_svm模型调用完整代码matlab
- 10免费、简单、可用于MC国际版联机/开服内网穿透推荐,让你假期和远方朋友玩游戏_租服务器mc需要内网穿透
机器学习实战——kaggle 泰坦尼克号生存预测——六种算法模型实现与比较_使用随机森林和朴素贝叶斯对泰坦尼克号生存者进行分类和预测
赞
踩
一、初识 kaggle
kaggle是一个非常适合初学者去实操实战技能的一个网站,它可以根据你做的项目来评估你的得分和排名。让你对自己的能力有更清楚的了解,当然,在这个网站上,也有很多项目的教程,可以跟着教程走,慢慢熟悉各种操作。在平时的学习中,我们了解到的知识更多的是理论,缺少一个实战的平台,项目的练习。我对kaggle的了解也是基于实战的需要,想做一些项目来巩固我的认知,发现更多有用的技能。
kaggle 竞赛,里面有很多项目,对熟悉数据处理与学习各种算法帮助很大。
二、项目介绍
完整代码见 kaggle kernel 或 Github
比赛页面:https://www.kaggle.com/c/titanic

项目的背景是大家都熟知的发生在1912年的泰坦尼克号沉船灾难,这次灾难导致2224名船员和乘客中有1502人遇难。而哪些人幸存那些人丧生并非完全随机。比如说你碰巧搭乘了这艘游轮,而你碰巧又是一名人见人爱,花见花开的一等舱小公主,那活下来的概率就很大了,但是如果不巧你只是一名三等舱的抠脚大汉,那只有自求多福了。也就是说在这生死攸关的情况下,生存与否与性别,年龄,阶层等因素是有关系的,如果把这些因素作为特征,生存的结果作为预测目标,就可以建立一个典型的二分类机器学习模型。在这个项目中提供了部分的乘客名单,包括各种维度的特征以及是否幸存的标签,存在train.csv文件中,这是我们训练需要的数据;另一个test.csv文件是我们需要预测的乘客名单,只有相应的特征。我们要做的工作就是通过对训练数据的特征与生存关系进行探索,构建合适的机器学习的模型,再用这个模型预测测试文件中乘客的幸存情况,并将结果保存提交给kaggle。
三、项目实战
根据训练集中的乘客数据和存活情况进行建模,进而使用模型预测测试集中的乘客是否会存活。乘客特征总共有11个,以下列出。当然也可以根据情况自己生成新特征,这就是特征工程(featureengineering)要做的事情了。
- PassengerId => 乘客ID
- Pclass => 客舱等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 兄弟姐妹数/配偶数
- Parch => 父母数/子女数
- Ticket => 船票编号
- Fare => 船票价格
- Cabin => 客舱号
- Embarked => 登船港口
总的来说Titanic和其他比赛比起来数据量算是很小的了,训练集合测试集加起来总共891+418=1309个。因为数据少,所以很容易过拟合(overfitting),一些算法如GradientBoostingTree的树的数量就不能太多,需要在调参的时候多加注意。
下面我先列出目录,然后挑几个关键的点说明一下:
- 数据清洗(Data Cleaning)
- 探索性可视化(Exploratory Visualization)
- 特征工程(Feature Engineering)
- 基本建模&评估(Basic Modeling& Evaluation)
- 参数调整(Hyperparameters Tuning)
- 集成方法(EnsembleMethods)
3.1 数据清洗(Data Cleaning)
数据清洗也称为数据预处理,即:对数据的缺失值进行处理。
将训练集和测试集进行合并、然后查看数据的缺失情况。
- # -*-coding:utf-8-*-
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
-
- if __name__ == '__main__':
- train = pd.read_csv('Data/train.csv')
- test = pd.read_csv('Data/test.csv')
- # 将训练数据与测试数据连接起来,以便一起进行数据清洗。
- # 这里需要注意的是,如果没有后面的ignore_index=True,那么index的值在连接后的这个新数据中是不连续的 继续从 0开始,如果要按照index删除一行数据,可能会发现多删一条。
- full = pd.concat([train, test], ignore_index=True)
- # 显示所有列
- # pd.set_option('display.max_columns', None)
- # pd.set_option('display.max_columns', 5) # 最多显示五列
- # 显示所有行
- # pd.set_option('display.max_rows', None)
- print(full.head()) # 默认显示5行
- print(full.isnull().sum()) # 查看数据的缺失情况
-

输出结果:

首先来看缺失数据,上图显示Age,Cabin,Embarked,Fare这些变量存在缺失值(Survived是预测值)。其中Embarked和Fare的缺失值较少,可以直接用众数和中位数插补。
用众数填充 Embarked的缺失值:
full.Embarked.mode()- 0 S
- dtype: object
这里Embarked的众数是S,然后用 S 填充 Embarked缺失值。
Note:inplace 默认值False。如果为 Ture, 在原地填满。注意:这将修改此对象上的任何其他视图。
- full['Embarked'].fillna('S',inplace=True)
-
填充 Fare缺失值:
由于“Fare”主要与“ Pclass”相关,因此我们应该检查此人属于哪个类别。
full[full.Fare.isnull()]
这是来自Pclass = 3的乘客,因此我们将使用Pclass = 3的中位数票价来填补缺失的值。
full.Fare.fillna(full[full.Pclass==3]['Fare'].median(),inplace=True)Cabin 的填充:
Cabin的缺失值较多,可以考虑比较有Cabin数据和无Cabin数据的乘客存活情况。
- full.loc[full.Cabin.notnull(),'Cabin']=1 # loc 获取指定行索引的行,'Cabin' 只获取指定行的列、对这些满足条件的列赋值
- full.loc[full.Cabin.isnull(),'Cabin']=0
-
- full.Cabin.isnull().sum() # 验证填充效果
- # 统计有无Cabin 死亡率的情况
- pd.pivot_table(full,index=['Cabin'],values=['Survived']).plot.bar(figsize=(8,5))
- plt.title('Survival Rate')

我们还可以绘制“Cabin”的数量来进行查看。
- cabin=pd.crosstab(full.Cabin,full.Survived)
- cabin.rename(index={0:'no cabin',1:'cabin'},columns={0.0:'Dead',1.0:'Survived'},inplace=True)
- cabin

- cabin.plot.bar(figsize=(8,5))
- plt.xticks(rotation=0,size='xx-large')
- plt.title('Survived Count')
- plt.xlabel(' ')
- plt.legend()

从上述分析中可以得出结论,有Cabin数据的乘客的存活率远高于无Cabin数据的乘客,所以我们可以将Cabin的有无数据作为一个特征。
age缺失值处理:
这里采用的的方法是先根据‘Name’提取‘Title’,再用‘Title’的中位数对‘Age‘进行插补:
- full['Title']=full['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
-
- full.Title.value_counts()

pd.crosstab(full.Title,full.Sex)
除“Dr”外,所有“title”都属于一种性别。
获取 Title为 Dr 性别是female的记录信息
- full[(full.Title=='Dr')&(full.Sex=='female')]
-

因此,female“ Dr”的PassengerId为“ 797”。 然后我们映射“Title”。
- nn={'Capt':'Rareman', 'Col':'Rareman','Don':'Rareman','Dona':'Rarewoman',
- 'Dr':'Rareman','Jonkheer':'Rareman','Lady':'Rarewoman','Major':'Rareman',
- 'Master':'Master','Miss':'Miss','Mlle':'Rarewoman','Mme':'Rarewoman',
- 'Mr':'Mr','Mrs':'Mrs','Ms':'Rarewoman','Rev':'Mr','Sir':'Rareman',
- 'the Countess':'Rarewoman'}
full.Title=full.Title.map(nn)- # 将 female 'Dr' 的Title映射为 'Rarewoman'
- full.loc[full.PassengerId==797,'Title']='Rarewoman'
再次统计各个Title的数目
full.Title.value_counts()

Title 为 “Master”主要代表 little boy,但我们也想找到 little girl。 因为孩子往往有较高的成活率。
对于具有年龄记录的“Miss”,我们可以简单地确定“Miss”是否是按年龄划分的小女孩。
对于没有年龄记录的“Miss”,我们使用(Parch!= 0)。 因为如果是小女孩,她很可能会由父母陪伴。
我们将创建一个过滤 girls 的函数。 如果“年龄”为Nan,则无法使用该函数,因此首先我们用“ 999”填充缺失值。
- full.Age.fillna(999,inplace=True)
-
- def girl(aa):
- if (aa.Age!=999)&(aa.Title=='Miss')&(aa.Age<=14):
- return 'Girl'
- elif (aa.Age==999)&(aa.Title=='Miss')&(aa.Parch!=0):
- return 'Girl'
- else:
- return aa.Title
-
- full['Title']=full.apply(girl,axis=1)
-
- Tit=['Mr','Miss','Mrs','Master','Girl','Rareman','Rarewoman']
- for i in Tit:
- full.loc[(full.Age==999)&(full.Title==i),'Age']=full.loc[full.Title==i,'Age'].median()
-
- full.info()

至此,数据中已无缺失值。
3.2 探索性可视化(Exploratory Visualization)
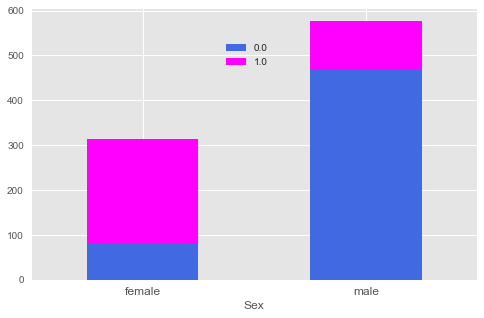
普遍认为泰坦尼克号中女人的存活率远高于男人,如下图所示:
- pd.crosstab(full.Sex,full.Survived).plot.bar(stacked=True,figsize=(8,5),color=['#4169E1','#FF00FF'])
- plt.xticks(rotation=0,size='large')
- plt.legend(bbox_to_anchor=(0.55,0.9))
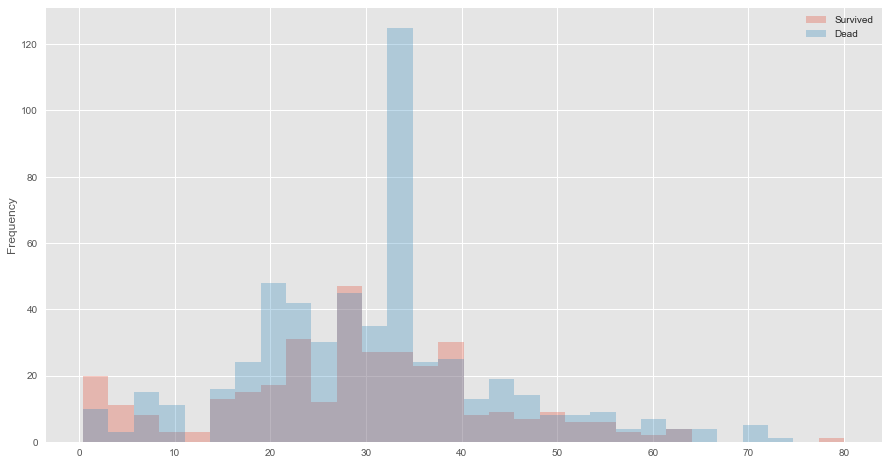
下图显示年龄与存活人数的关系,可以看出小于5岁的小孩存活率很高。
- agehist=pd.concat([full[full.Survived==1]['Age'],full[full.Survived==0]['Age']],axis=1)
- agehist.plot(kind='hist',bins=30,figsize=(15,8),alpha=0.3)
费用对死亡率的影响:尽管大多数“票价”都在100以下,但“票价”较高的人更有可能生存。
- farehist=pd.concat([full[full.Survived==1]['Fare'],full[full.Survived==0]['Fare']],axis=1)
- farehist.plot.hist(bins=30,figsize=(15,8),alpha=0.3,stacked=True,color=['blue','red'])

“ Rarewoman”具有100%的生存率,真是太神奇了!
- full.groupby(['Title'])[['Title','Survived']].mean().plot(kind='bar',figsize=(10,7))
- plt.xticks(rotation=0)

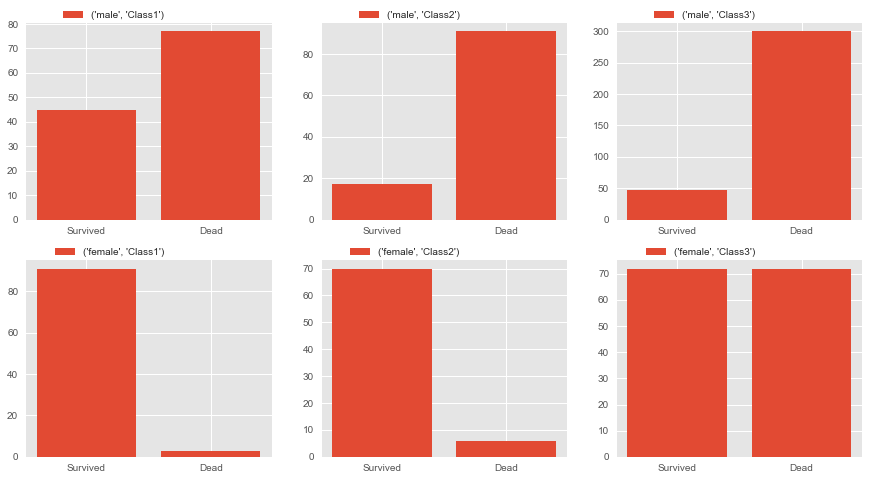
很自然地假设 客舱等级(Pclass) 也起着很大的作用,如下图所示。class 3 女性的生存率约为50%,而 class1/2 女性的生存率要高得多。
- fig,axes=plt.subplots(2,3,figsize=(15,8))
- Sex1=['male','female']
- for i,ax in zip(Sex1,axes):
- for j,pp in zip(range(1,4),ax):
- PclassSex=full[(full.Sex==i)&(full.Pclass==j)]['Survived'].value_counts().sort_index(ascending=False)
- pp.bar(range(len(PclassSex)),PclassSex,label=(i,'Class'+str(j)))
- pp.set_xticks((0,1))
- pp.set_xticklabels(('Survived','Dead'))
- pp.legend(bbox_to_anchor=(0.6,1.1))
3.3 特征工程(Feature Engineering)
查看各个年龄段人数的分布情况
- # 使用 pd.cut 将年龄平均分成5个区间
- full.AgeCut=pd.cut(full.Age,5)
- # 使用 pd.cut 将费用平均分成5个区间
- full.FareCut=pd.qcut(full.Fare,5)
查看结果:
full.AgeCut.value_counts().sort_index()
full.FareCut.value_counts().sort_index()
- # 根据各个分段 重新给 AgeCut赋值
- full.loc[full.Age<=16.136,'AgeCut']=1
- full.loc[(full.Age>16.136)&(full.Age<=32.102),'AgeCut']=2
- full.loc[(full.Age>32.102)&(full.Age<=48.068),'AgeCut']=3
- full.loc[(full.Age>48.068)&(full.Age<=64.034),'AgeCut']=4
- full.loc[full.Age>64.034,'AgeCut']=5
- # 根据各个分段 重新给 FareCut赋值
- full.loc[full.Fare<=7.854,'FareCut']=1
- full.loc[(full.Fare>7.854)&(full.Fare<=10.5),'FareCut']=2
- full.loc[(full.Fare>10.5)&(full.Fare<=21.558),'FareCut']=3
- full.loc[(full.Fare>21.558)&(full.Fare<=41.579),'FareCut']=4
- full.loc[full.Fare>41.579,'FareCut']=5
从图中可以看出,“ FareCut”对生存率有很大影响。
full[['FareCut','Survived']].groupby(['FareCut']).mean().plot.bar(figsize=(8,5))
查看字段之间的相关系数:
full.corr()
我们尚未从'Parch','Pclass','SibSp','Title' 生产任何特征,因此让我们使用数据透视表来实现。
- full[full.Survived.notnull()].pivot_table(index=['Title','Pclass'],values=['Survived']).sort_values('Survived',ascending=False)
-
- full[full.Survived.notnull()].pivot_table(index=['Title','Parch'],values=['Survived']).sort_values('Survived',ascending=False)
在上面的数据透视表中,'Survived','Title','Pclass','Parch' 之间肯定存在关系。 因此,我们可以将它们组合在一起。
- TPP.plot(kind='bar',figsize=(16,10))
- plt.xticks(rotation=40)
- plt.axhline(0.8,color='#BA55D3')
- plt.axhline(0.5,color='#BA55D3')
- plt.annotate('80% survival rate',xy=(30,0.81),xytext=(32,0.85),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))
- plt.annotate('50% survival rate',xy=(32,0.51),xytext=(34,0.54),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))
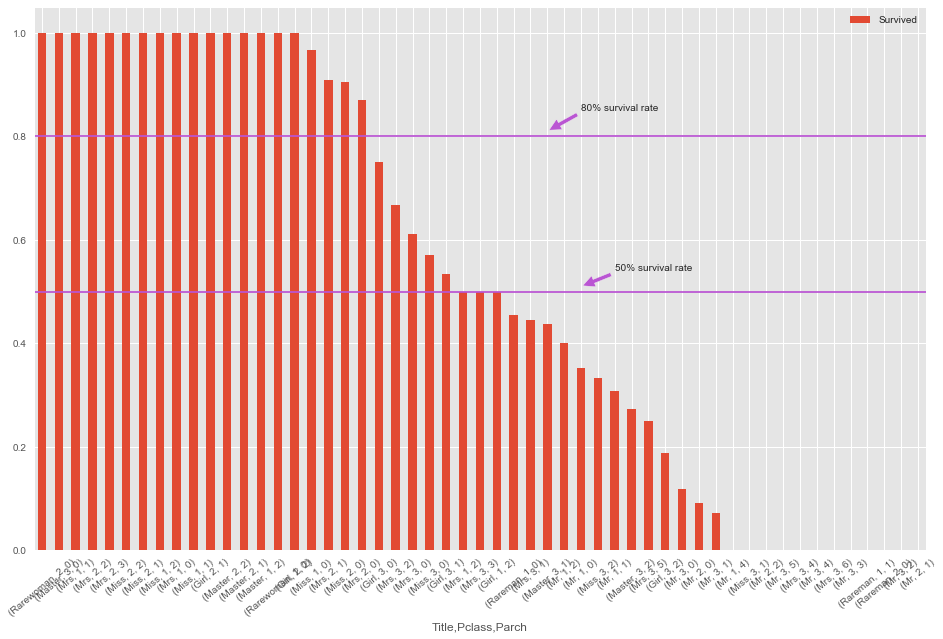
从图中可以绘制一些水平线并进行分类。 我只选择80%和50%,因为我害怕过拟合。
- # use 'Title','Pclass','Parch' to generate feature 'TPP'.
- Tit=['Girl','Master','Mr','Miss','Mrs','Rareman','Rarewoman']
- for i in Tit:
- for j in range(1,4):
- for g in range(0,10):
- if full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0.8:
- full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=1
- elif full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0.5:
- full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=2
- elif full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g)&(full.Survived.notnull()),'Survived'].mean()>=0:
- full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=3
- else:
- full.loc[(full.Title==i)&(full.Pclass==j)&(full.Parch==g),'TPP']=4
“ TPP = 1”表示生存的最高可能性,而“ TPP = 3”表示最低的生存可能性。
'TPP = 4'表示训练集中没有(Title&Pclass&Pclass)这样的组合。 让我们看看它包含什么样的组合。

我们可以简单地通过'Sex'&'Pclass'对它们进行分类。
- full.ix[(full.TPP==4)&(full.Sex=='female')&(full.Pclass!=3),'TPP']=1
- full.ix[(full.TPP==4)&(full.Sex=='female')&(full.Pclass==3),'TPP']=2
- full.ix[(full.TPP==4)&(full.Sex=='male')&(full.Pclass!=3),'TPP']=2
- full.ix[(full.TPP==4)&(full.Sex=='male')&(full.Pclass==3),'TPP']=3
full.TPP.value_counts()- 3.0 870
- 1.0 262
- 2.0 177
- Name: TPP, dtype: int64
full.info()
3.4 基本建模&评估(Basic Modeling & Evaluation)
- predictors=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Title','AgeCut','TPP','FareCut','Age','Fare']
-
- # 使用 one-hot encoding 将分类变量转为数值变量
- # pd.get_dummies使用方法 https://blog.csdn.net/maymay_/article/details/80198468
- full_dummies=pd.get_dummies(full[predictors])
-
- full_dummies.head()

选择了7个算法,分别做交叉验证(cross-validation)来评估效果:
- K近邻(k-Nearest Neighbors)
- 逻辑回归(Logistic Regression)
- 朴素贝叶斯分类器(Naive Bayes classifier)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 梯度提升树(Gradient Boosting Decision Tree)
- 支持向量机(Support Vector Machine)
1) 导入需要的包
- from sklearn.model_selection import cross_val_score
-
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.linear_model import LogisticRegression
- from sklearn.naive_bayes import GaussianNB
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.ensemble import GradientBoostingClassifier
- from sklearn.svm import SVC
2)切分数据集
- X=full_dummies[:891] # 训练集
- y=full.Survived[:891] # 标签
- test_X=full_dummies[891:] # 测试集
3)特征缩放
由于K近邻和支持向量机对数据的scale敏感,所以先进行标准化(standard-scaling):
- from sklearn.preprocessing import StandardScaler
- scaler=StandardScaler()
- X_scaled=scaler.fit(X).transform(X) # scaler.fit(X)计算出 X 均值和方差然后再转换成标准的正态分布
- test_X_scaled=scaler.fit(X).transform(test_X)
4)模型创建
- models=[KNeighborsClassifier(),LogisticRegression(),GaussianNB(),DecisionTreeClassifier(),RandomForestClassifier(),
- GradientBoostingClassifier(),SVC()]
交叉验证
- # evaluate models by using cross-validation
- names=['KNN','LR','NB','Tree','RF','GDBT','SVM']
- for name, model in zip(names,models):
- score=cross_val_score(model,X,y,cv=5)
- print("{}:{},{}".format(name,score.mean(),score))
-
-
- # 使用标准化的数据 scaled data
- names=['KNN','LR','NB','Tree','RF','GDBT','SVM']
- for name, model in zip(names,models):
- score=cross_val_score(model,X_scaled,y,cv=5)
- print("{}:{},{}".format(name,score.mean(),score))
- KNN:0.722876869778,[ 0.68156425 0.7150838 0.73033708 0.73033708 0.75706215]
- LR:0.831672250422,[ 0.83798883 0.82681564 0.80337079 0.83707865 0.85310734]
- NB:0.810311027039,[ 0.83798883 0.81005587 0.79775281 0.78089888 0.82485876]
- Tree:0.785673102259,[ 0.7877095 0.75418994 0.84269663 0.75280899 0.79096045]
- RF:0.800204518994,[ 0.79888268 0.81005587 0.84269663 0.75842697 0.79096045]
- GDBT:0.841822627028,[ 0.8547486 0.80446927 0.86516854 0.80337079 0.88135593]
- SVM:0.747564940189,[ 0.72067039 0.73184358 0.76404494 0.73595506 0.78531073]
- KNN:0.808133025651,[ 0.81564246 0.78212291 0.79775281 0.80898876 0.83615819]
- LR:0.832833650201,[ 0.82681564 0.81564246 0.8258427 0.83146067 0.86440678]
- NB:0.800337117662,[ 0.75418994 0.79888268 0.82022472 0.7752809 0.85310734]
- Tree:0.782302315742,[ 0.78212291 0.75977654 0.8258427 0.75280899 0.79096045]
- RF:0.812589532472,[ 0.82681564 0.7877095 0.85393258 0.7752809 0.81920904]
- GDBT:0.841822627028,[ 0.8547486 0.80446927 0.86516854 0.80337079 0.88135593]
- SVM:0.833944833422,[ 0.83798883 0.82681564 0.83146067 0.79775281 0.87570621]
“ k邻居”,“支持向量机”在标准化数据上的性能要好得多
然后,我们使用GradientBoostingClassifier中的(特征重要性)来查看哪些特征很重要。
5)查看特征的重要性
- fi=pd.DataFrame({'importance':model.feature_importances_},index=X.columns)
- fi.sort_values('importance',ascending=False)

柱状图的形式展示:
- fi.sort_values('importance',ascending=False).plot.bar(figsize=(11,7))
- plt.xticks(rotation=30)
- plt.title('Feature Importance',size='x-large')

根据条形图,“ TPP”,“票价”,“年龄”是最重要的。
接下来可以挑选一个模型进行错误分析,提取该模型中错分类的观测值,寻找其中规律进而提取新的特征,以图提高整体准确率。
用sklearn中的KFold将训练集分为10份,分别提取10份数据中错分类观测值的索引,最后再整合到一块。
- from sklearn.model_selection import KFold
- kf=KFold(n_splits=10,random_state=1)
-
- # extract the indices of misclassified observations
- rr=[]
- for train_index, val_index in kf.split(X):
- pred=model.fit(X.ix[train_index],y[train_index]).predict(X.ix[val_index])
- rr.append(y[val_index][pred!=y[val_index]].index.values)
-
-
- # combine all the indices
- whole_index=np.concatenate(rr)
- len(whole_index)
先查看错分类观测值的整体情况:
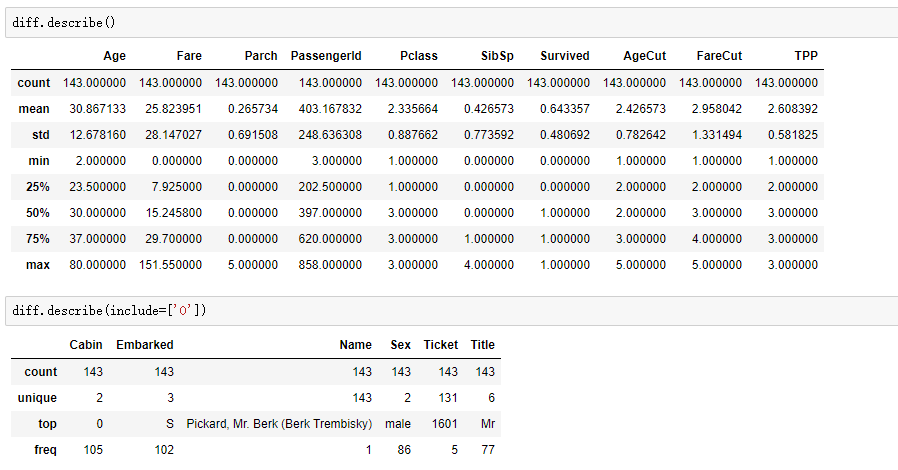
下面通过分组分析可发现:错分类的观测值中男性存活率高达83%,女性的存活率则均不到50%,这与我们之前认为的女性存活率远高于男性不符,可见不论在男性和女性中都存在一些特例,而模型并没有从现有特征中学习到这些。
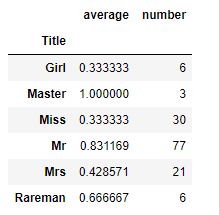
通过进一步分析我最后新加了个名为”MPPS”的特征。
- full.loc[(full.Title=='Mr')&(full.Pclass==1)&(full.Parch==0)&((full.SibSp==0)|(full.SibSp==1)),'MPPS']=1
- full.loc[(full.Title=='Mr')&(full.Pclass!=1)&(full.Parch==0)&(full.SibSp==0),'MPPS']=2
- full.loc[(full.Title=='Miss')&(full.Pclass==3)&(full.Parch==0)&(full.SibSp==0),'MPPS']=3
- full.MPPS.fillna(4,inplace=True)
3.5 参数调整(Hyperparameters tuning)
现在,让我们对一些算法进行网格搜索。 由于许多算法在按比例缩放的数据中表现更好,因此我们将使用按比例缩放的数据。
- predictors=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Title','AgeCut','TPP','FareCut','Age','Fare','MPPS']
- full_dummies=pd.get_dummies(full[predictors])
- X=full_dummies[:891]
- y=full.Survived[:891]
- test_X=full_dummies[891:]
-
- scaler=StandardScaler()
- X_scaled=scaler.fit(X).transform(X)
- test_X_scaled=scaler.fit(X).transform(test_X)
-
- from sklearn.model_selection import GridSearchCV
k-Nearest Neighbors
- param_grid={'n_neighbors':[1,2,3,4,5,6,7,8,9]}
- grid_search=GridSearchCV(KNeighborsClassifier(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'n_neighbors': 8}, 0.8271604938271605)Logistic Regression
- param_grid={'C':[0.01,0.1,1,10]}
- grid_search=GridSearchCV(LogisticRegression(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'C': 0.1}, 0.83052749719416386)
- # second round grid search
- param_grid={'C':[0.04,0.06,0.08,0.1,0.12,0.14]}
- grid_search=GridSearchCV(LogisticRegression(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'C': 0.06}, 0.83277216610549942)
Support Vector Machine
- param_grid={'C':[0.01,0.1,1,10],'gamma':[0.01,0.1,1,10]}
- grid_search=GridSearchCV(SVC(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
-
({'C': 10, 'gamma': 0.01}, 0.83164983164983164)
- #second round grid search
- param_grid={'C':[2,4,6,8,10,12,14],'gamma':[0.008,0.01,0.012,0.015,0.02]}
- grid_search=GridSearchCV(SVC(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'C': 4, 'gamma': 0.015}, 0.83501683501683499)
Gradient Boosting Decision Tree
- param_grid={'n_estimators':[30,50,80,120,200],'learning_rate':[0.05,0.1,0.5,1],'max_depth':[1,2,3,4,5]}
- grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 120},
0.84399551066217737)
- #second round search
- param_grid={'n_estimators':[100,120,140,160],'learning_rate':[0.05,0.08,0.1,0.12],'max_depth':[3,4]}
- grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
-
- grid_search.fit(X_scaled,y)
-
- grid_search.best_params_,grid_search.best_score_
({'learning_rate': 0.12, 'max_depth': 4, 'n_estimators': 100},
0.85072951739618408)


