
- 1Unity 创建/实例化对象_unity实例化对象
- 2电脑操作常用快捷键_win+ u+i
- 3Jquery 点击当前的标签对象获取值 与JS整理_jq循环点击当前元素获取属性值
- 4Vue + ElementUI 实现后台管理系统模板 -- 前端篇(三):引入 element-ui 定义基本页面显示_vui element后台管理模板
- 5从一个HTML返回所有的图片链接_html中图片连接如何返回
- 6Mysql运维篇(四) Xtarbackup--备份与恢复练习
- 7pyautogui桌面自动化基础使用方法_pyautogui 激活窗口
- 8opencv-python 学习笔记(7) ------直方图_tilegirdsize' is an invalid keyword argument for c
- 9Android 10.0 SystemUI下拉状态栏UI定制化开发系列(十三)_android 9.0 systemui默认展开下拉框
- 10【Bug】ERROR: Could not build wheels for opencv-python, which is required to install pyproject.toml-ba_error: could not build wheels for opencv-contrib-p
30分钟搞懂 HTTP 缓存_http缓存
赞
踩
无论你是前端,还是后端,日常工作中都免不了遇到和HTTP缓存相关的问题。比如发现本该更新的文件因为缓存而没有更新,通常的做法给请求资源的文件路径加个时间戳,简单粗暴又有效,但作为一个有追求的程序员,我们不应该仅停留在把问题解决了就OK了的层面上,更进一步,思考是否还有更好的解决方案?针对不同的场景、不同类型的资源,有没有更高效的缓存设计方案?希望你读完这篇文章之后,能对HTTP缓存有更深刻全面的理解,掌握它们,对我们解决日常一些复杂问题会有帮助。
一、HTTP 缓存是什么?
简单地说,HTTP 缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。也就是说,当 HTTP 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的副本,而不会去源服务器重新下载。
如果没有缓存会有什么问题?
假设没有缓存,试想一下,客户端多次访问一个原始服务器页面时,服务器会多次传输同一份文档,每次传送给一个客户端。一些相同的内容会在网络中一遍遍地传输。这些冗余的数据传输会耗尽昂贵的网络带宽,降低传输速度,加重Web服务器的负载。
有了缓存,就可以保留第一条服务器响应的副本,后继请求就可以由缓存的副本来应对了,这样可以减少那些流入/流出原始服务器的、被浪费掉了的重复流量。通过复用以前获取的资源,可以显著提高网站和应用程序的性能。除此之外,其他连带的好处也显而易见,比如可以减少网络请求时间、降低带宽消耗、提升性能。
什么样的 HTTP 响应会被客户端缓存?
那什么样的响应会被缓存呢?
- 默认情况下,请求方法如 GET、HEAD的响应内容是可缓存的,在包含新鲜度信息的情况下,POST的响应内容也可以被缓存;
- 默认情况下,响应码如 200、206、300、301、302、404 等的响应内容可以被缓存;
- 响应头和请求头没有指明不使用缓存,如 Cache-Control: no-store。
以上是几种比较常见的情况。
二、什么是私有缓存和共享缓存?
私有缓存
仅供一个客户端使用的缓存,即客户端上的缓存仅供自己使用,通常只存在于如浏览器这样的客户端上。
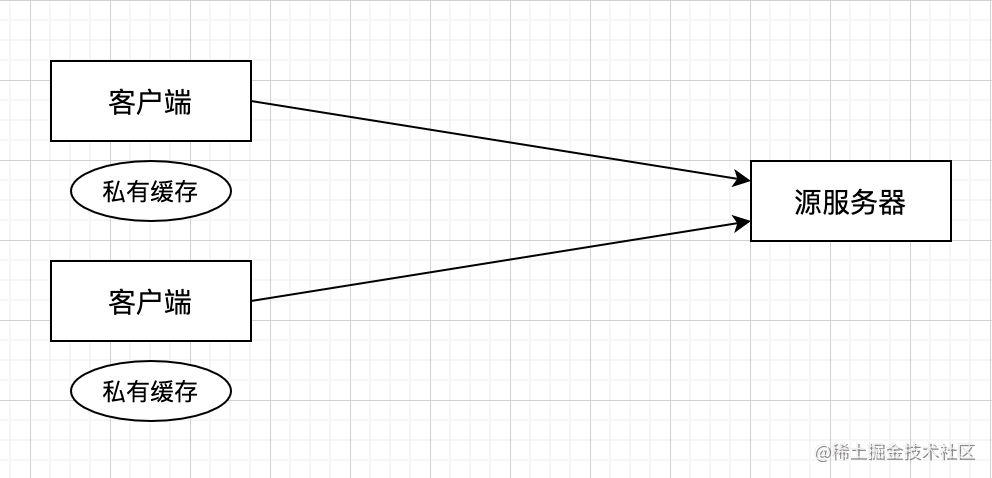
每个客户端发起的第一个请求都会被源服务器处理。在缓存生效的情况下,同一个客户端后续的相同请求甚至不会被发送,而是由本地缓存提供服务。
共享缓存
可以供多个客户端使用的缓存,通常依赖于代理服务器。
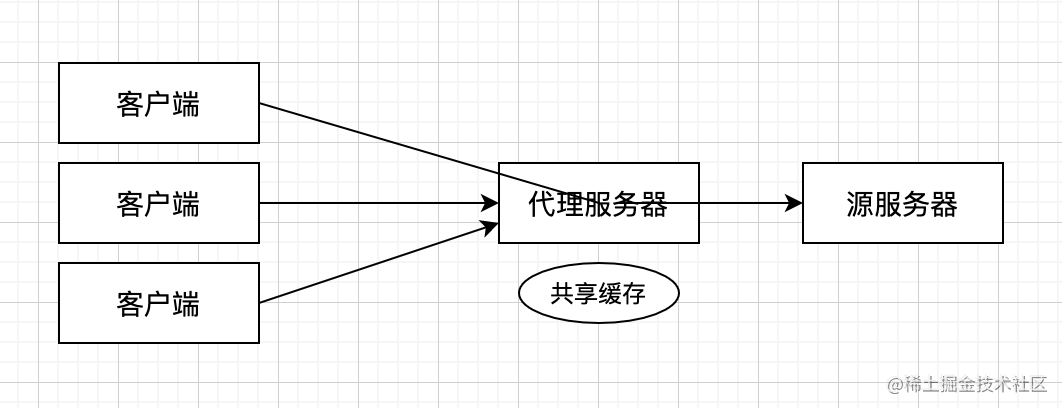
客户端发起的第一个请求通过代理服务器访问源服务器,缓存生效后会存放在代理服务器,后续客户端发起的相同请求,均由代理服务器提供缓存服务,共享缓存可以减轻源服务器的压力。
概念相关的内容讲完,我们开始深入HTTP缓存具体的工作机制。
三、HTTP 缓存的处理流程
在正式开始之前,我们通过下面这张图通过宏观视角了解下HTTP 缓存的处理流程(执行顺序)。


