
- 1python学习:zip文件_deflated lzma
- 2Bat脚本编写之Dos 基本操作命令_dos命令运行bat脚本怎么写
- 3Linux系统中常用的压缩、解压缩命令(tar、zip、gzip、bzip2、xz)_linux tar 压缩文件的时候忽略绝对路径 只压缩文件名
- 4WDS迁移注意事项
- 5香港高防服务器租用应该如何选择?
- 6Linux环境下Qt应用程序安装器(installer)制作_qtifw在linux中应用
- 7mysql数据库常用函数_使用mysql语句比较s1和s2两个字符串
- 8Go 工程化标准实践_go internal最佳实践
- 9理解RTF和RTX指标_asr rtf
- 10windows安装docker 异常解决_docker desktop requires windows 10 pro/enterprise/
爬虫python,巨细!Python爬虫详解
赞
踩
爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,他们沿着蜘蛛网抓取自己想要的猎物/数据。
爬虫的基本流程

网页的请求与响应
网页的请求和响应方式是 Request 和 Response
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,收到请求信息后返回数据(返回的数据中可能包含其他链接,如:image、js、css等)
浏览器在接收 Response 后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收 Response 后,是要提取其中的有用数据。
发起请求:Request
请求的发起是使用 http 库向目标站点发起请求,即发送一个Request
Request对象的作用是与客户端交互,收集客户端的 Form、Cookies、超链接,或者收集服务器端的环境变量。
Request 对象是从客户端向服务器发出请求,包括用户提交的信息以及客户端的一些信息。客户端可通过 HTML 表单或在网页地址后面提供参数的方法提交数据。
然后服务器通过 request 对象的相关方法来获取这些数据。request 的各种方法主要用来处理客户端浏览器提交的请求中的各项参数和选项。
Request 包含:请求 URL、请求头、请求体等
Request 请求方式: GET/POST
请求url: url全称统一资源定位符,一个网页文档、一张图片、 一个视频等都可以用url唯一来确定
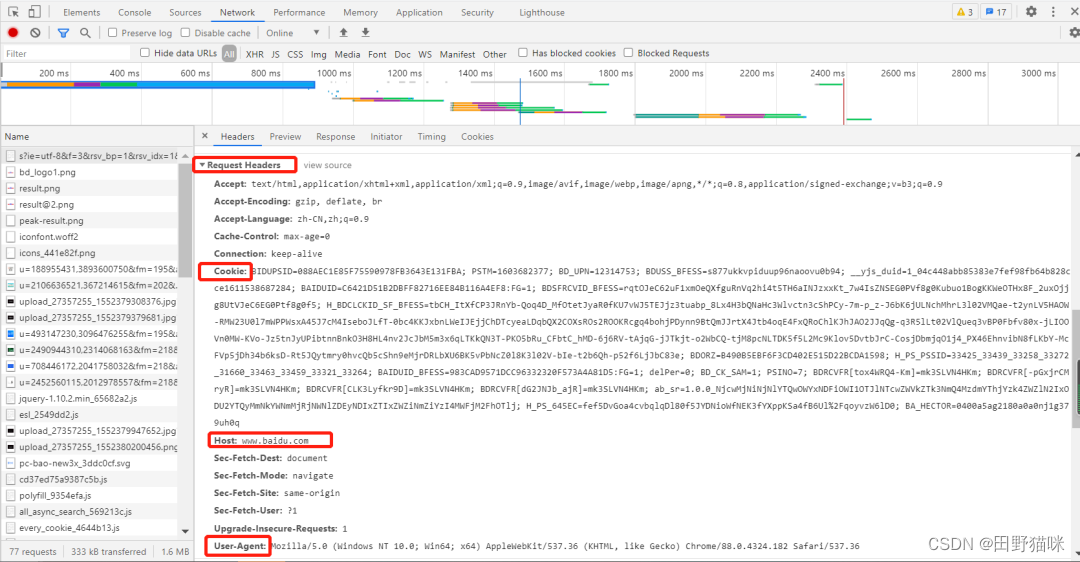
请求头: User-agent:请求头中如果没有 user-agent 客户端配置,服务端可能将你当做一个非法用户;
cookies: cookie 用来保存登录信息
一般做爬虫都会加上请求头
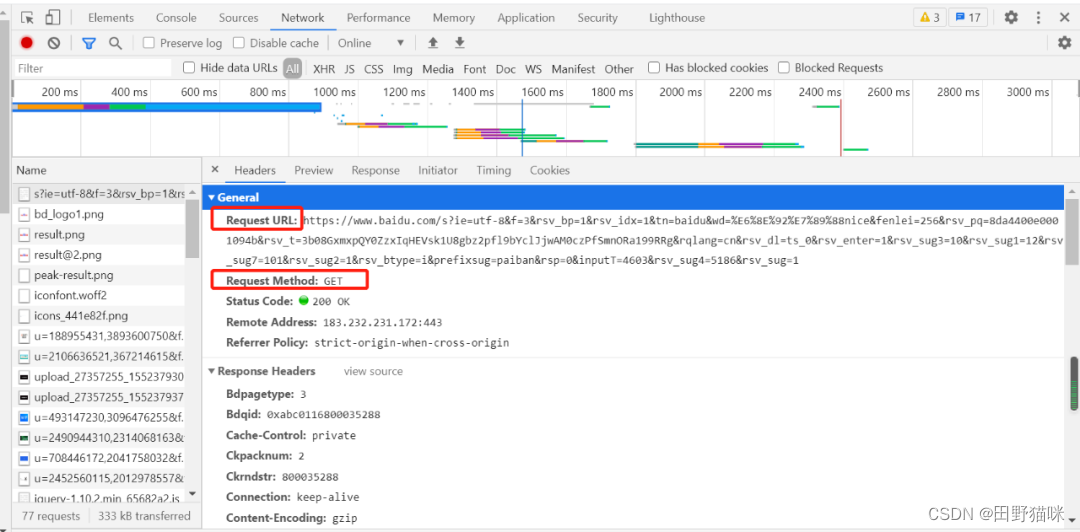
例如:抓取百度网址的数据请求信息如下:
获取响应内容
爬虫程序在发送请求后,如果服务器能正常响应,则会得到一个Response,即响应;
Response 信息包含:html、json、图片、视频等,如果没报错则能看到网页的基本信息。例如:一个的获取网页响应内容程序如下:
import requests
request_headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': 'BIDUPSID=088AEC1E85F75590978FB3643E131FBA; PSTM=1603682377; BD_UPN=12314753; BDUSS_BFESS=s877ukkvpiduup96naoovu0b94; __yjs_duid=1_04c448abb85383e7fef98fb64b828cce1611538687284; BAIDUID=C6421D51B2DBFF82716EE84B116A4EF8:FG=1; BDSFRCVID_BFESS=rqtOJeC62uF1xmOeQXfguRnVq2hi4t5TH6aINJzxxKt_7w4IsZNSEG0PVf8g0Kubuo1BogKKWeOTHx8F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbCH_ItXfCP3JRnYb-Qoq4D_MfOtetJyaR0fKU7vWJ5TEJjz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VMQae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjjChDTcyeaLDqbQX2COXsROs2ROOKRcgq4bohjPDynn9BtQmJJrtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW-KVo-Jz5tnJyUPibtnnBnkO3H8HL4nv2JcJbM5m3x6qLTKkQN3T-PKO5bRu_CFbtC_hMD-6j6RV-tAjqG-jJTkjt-o2WbCQ-tjM8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN8fLKbY-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2b6Qh-p52f6LjJbC83e; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33439_33258_33272_31660_33463_33459_33321_33264; BAIDUID_BFESS=983CAD9571DCC96332320F573A4A81D5:FG=1; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BD_HOME=1; H_PS_645EC=0c49V2LWy0d6V4FbFplBYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM; BA_HECTOR=0l05812h21248584dc1g38qhn0r; COOKIE_SESSION=1_0_8_3_3_9_0_0_7_3_0_1_5365_0_3_0_1614047800_0_1614047797%7C9%23418111_17_1611988660%7C5; BDSVRTM=1',
'Host':'www.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}
response = requests.get('https://www.baidu.com/s',params={'wd':'帅哥'},headers=request_headers) #params内部就是调用urlencode
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
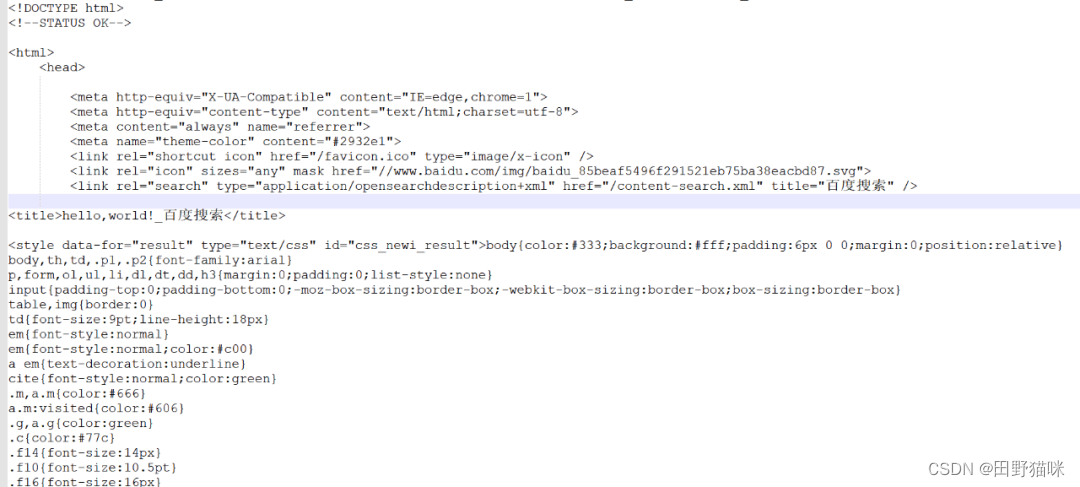
以上内容输出的就是网页的基本信息,它包含 html、json、图片、视频等,如下图所示:
Response 响应后会返回一些响应信息,例下:
1、响应状态
- 200:代表成功
- 301:代表跳转
- 404:文件不存在
- 403:权限
- 502:服务器错误
2、Respone header
- set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
3、preview 是网页源代码
- 最主要的部分,包含了请求资源的内容,如网页html、图片、二进制数据等
4、解析内容
-
解析 html 数据:解析 html 数据方法有使用正则表达式、第三方解析库如 Beautifulsoup,pyquery 等
-
解析 json 数据:解析 json数据可使用 json 模块
-
解析二进制数据:以 b 的方式写入文件
5、保存数据
爬取的数据以文件的形式保存在本地或者直接将抓取的内容保存在数据库中,数据库可以是 MySQL、Mongdb、Redis、Oracle 等……
写在最后
爬虫的总流程可以理解为:蜘蛛要抓某个猎物–>沿着蛛丝找到猎物–>吃到猎物;即爬取–>解析–>存储;
在爬取数据过程中所需参考工具如下:
- 爬虫框架:Scrapy
- 请求库:requests、selenium
- 解析库:正则、beautifulsoup、pyquery
- 存储库:文件、MySQL、Mongodb、Redis……
总结
今天的文章是对爬虫的原理做一个详解,希望对大家有帮助,同时也在后面的工作中奠定基础!

以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
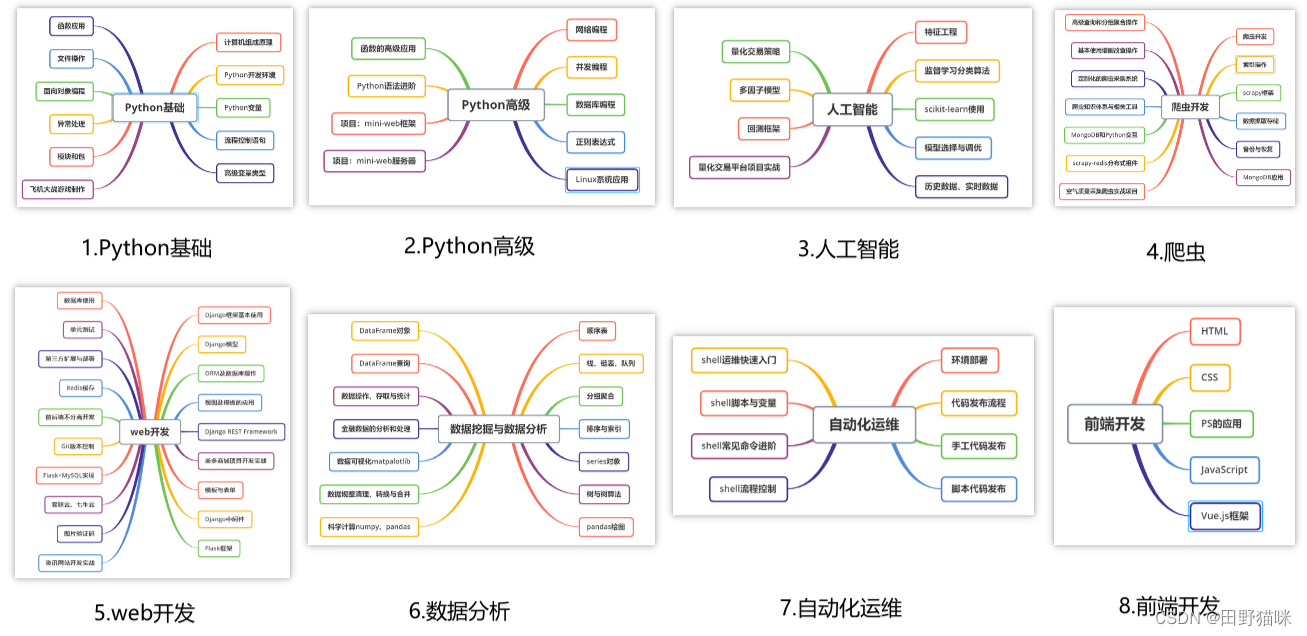
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
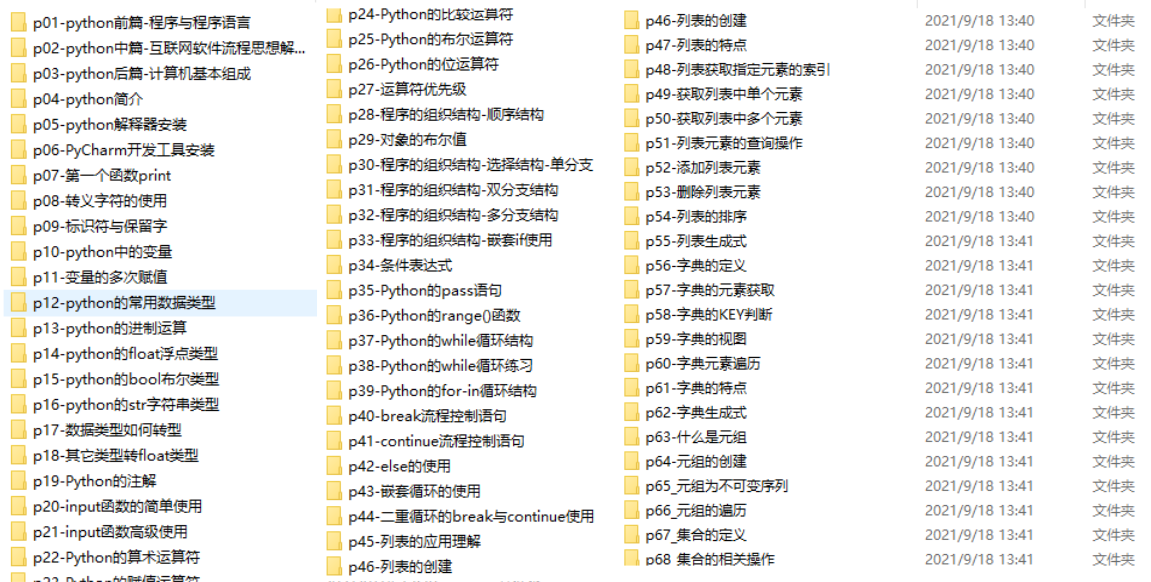
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !

