- 1python 无限循环小数_你怕是学了个假Python吧
- 2【css技巧】css实现边框渐变_css边框渐变样式
- 3PyTorch-Kaldi工具箱简介及核心代码注解
- 4【games101】作业笔记——作业3_games101笔记
- 5springboot日志DEBUG级别配置_springboot开启debug日志
- 6Ubuntu各种常用快捷键详解_byobu ctrl+s
- 7Typora文件别人打开不显示图片-图像处理_typora的图片转载给别人无法查看
- 8html主题网站设计代码示例,网页设计参考:很不错的15个HTML网页表单设计实例
- 9ChatGLM源码解析 main.py_tokenizer.bos_token_id
- 10自定义指令directives:防抖,节流,element-ui的无限滚动在el-table上使用的封装_throttlecall
头歌平台——(3)Pandas初体验_头歌pandas基本操作
赞
踩
第1关:了解数据处理对象–Series
根据提示,在右侧编辑器Begin-End处补充代码:
创建一个名为series_a的series数组,当中值为[1,2,5,7],对应的索引为[‘nu’, ‘li’, ‘xue’, ‘xi’];
创建一个名为dict_a的字典,字典中包含如下内容{‘ting’:1, ‘shuo’:2, ‘du’:32, ‘xie’:44};
将dict_a字典转化成名为series_b的series数组。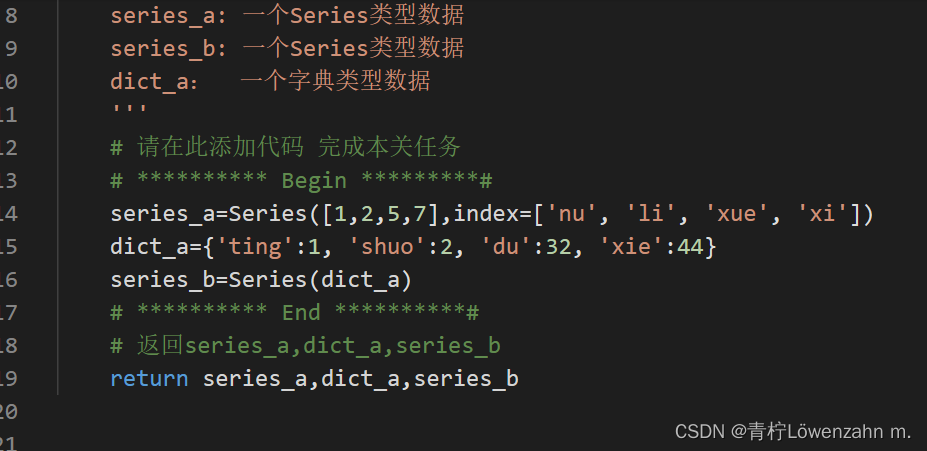
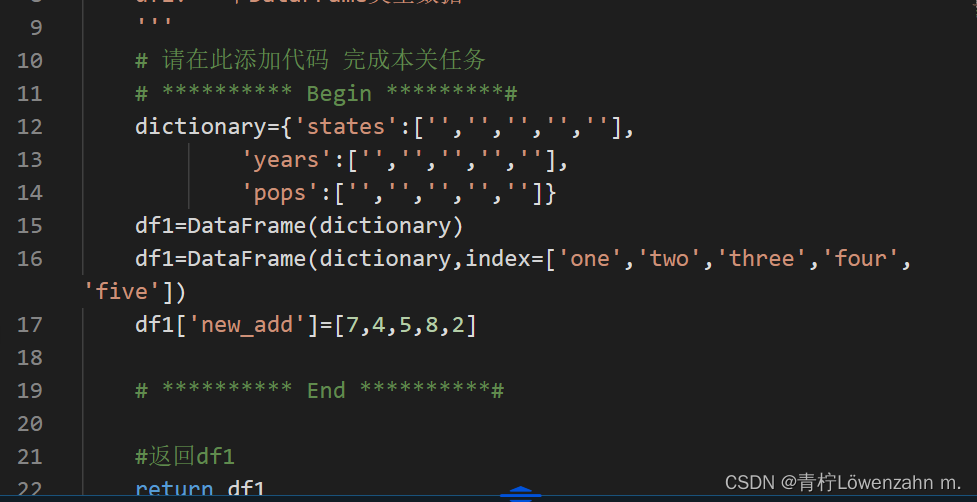
第2关:了解数据处理对象-DataFrame
根据提示,在右侧编辑器begin-end处补充代码:
创建一个五行三列的名为df1的DataFrame数组,列名为 [states,years,pops],行名[‘one’,‘two’,‘three’,‘four’,‘five’];
给df1添加新列,列名为new_add,值为[7,4,5,8,2]。
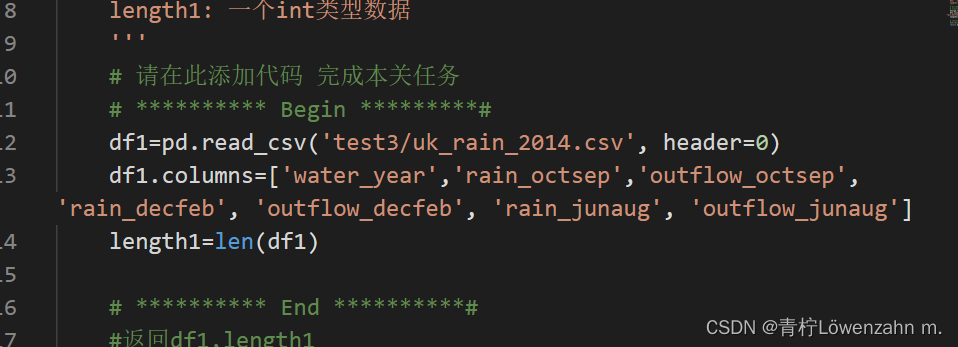
第3关:读取CSV格式数据
根据提示,在右侧编辑器begin-end处补充代码:
将test3/uk_rain_2014.csv中的数据导入到df1中;
将列名修改为[‘water_year’,‘rain_octsep’,‘outflow_octsep’,‘rain_decfeb’, ‘outflow_decfeb’, ‘rain_junaug’, ‘outflow_junaug’];
计算df1的总行数并存储在length1中。
第4关:数据的基本操作——排序
根据提示,在右侧编辑器Begin-End处补充代码:
对代码中s1进行按索引排序,并将结果存储到s2;
对代码中d1进行按值排序(index为f),并将结果存储到d2。
第5关:数据的基本操作——删除
根据提示,在右侧编辑器Begin-End处补充代码:
在s1中删除z行,并赋值到s2;
d1中删除yy列,并赋值到d2。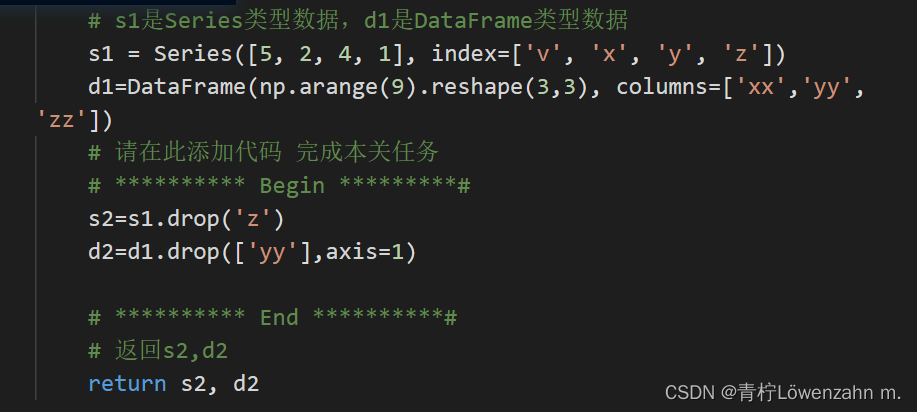
第6关:数据的基本操作——算术运算
根据提示,在右侧编辑器Begin-End处补充代码:
让df1与df2相加得到df3,并设置默认填充值为4。
第7关:数据的基本操作——去重
根据提示,在右侧编辑器Begin-End处补充代码:
去除df1中重复的行,并把结果保存到df2中。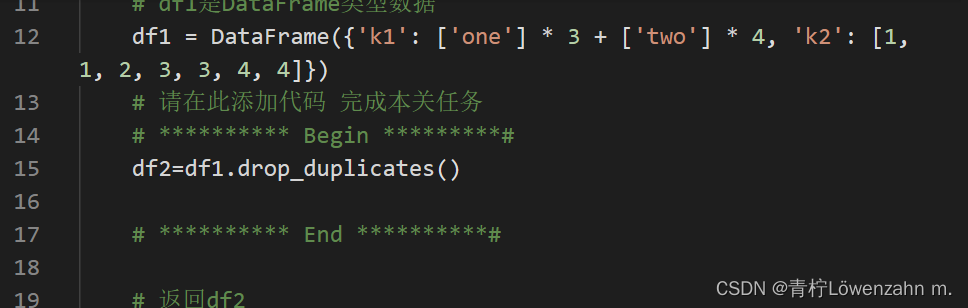
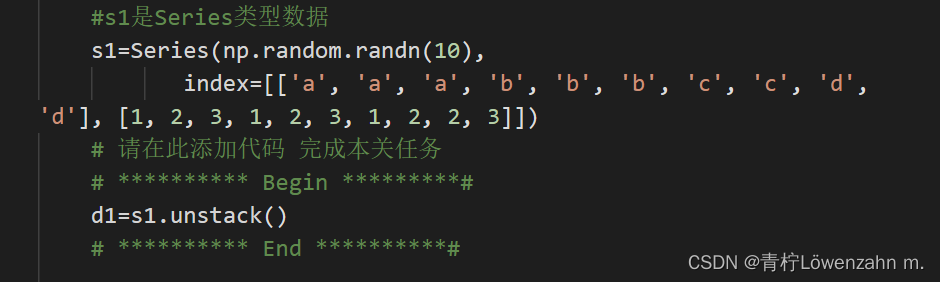
第8关:层次化索引
根据提示,在右侧编辑器Begin-End处补充代码:
对s1进行数据重塑,转化成DataFrame类型,并复制到d1。