
- 1Android Studio中修改项目支持的最小SDK版本的方法_最小支持版本为?
- 2基于微信小程序小说平台系统设计与实现 毕业设计论文大纲提纲参考
- 3springBoot 启动指定配置文件环境多种方案_springboot指定配置文件启动
- 4VR拆装(HTC vive Pro开发)——3、项目开始前的预先知识_htc vive pro 开发
- 5Scapy数据包构建详解_import scapy
- 6python数据分析案例详解,python数据分析简单案例_python数据分析实例
- 7VS2017+Windows底层窗口的实现——“代码运行正确,但是无窗口”显示问题解决汇总_vs中代码正确但是运行不了
- 8dos打开计算机管理,小何 发布 DOS 命令打开控制面板各项东东 你们懂得...
- 9基于Springboot框架北京某电影院选座购票系统设计与实现 研究背景和意义、国内外现状_电影售票管理系统国内研究现状参考文献
- 10Python3pandas库DataFrame用法(基础整理)_class 'pandas.core.frame.dataframe
Pandas数据排序,人人都能学会的几种方法
赞
踩
来源:Python数据之道 (ID:PyDataLab)
作者:阳哥
大家好,我是阳哥。
Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。
Pandas是一种高效的数据处理库,它以 dataframe 和 series 为基本数据类型,呈现出类似excel的二维数据。
在数据处理过程中,咱们经常需要将数据按照一定的要求进行排序,以方便展示。
这里,阳哥来给大家分享下 在 Pandas 中排序的几种常用方法,主要包括 sort_index 和 sort_values 。
01 按索引排序
数据准备
文中主要使用了 pandas 和 numpy ,首先导入 Python 库,如下:
- import pandas as pd
- import numpy as np
- print(f'pandas version: {pd.__version__}')
-
- # pandas version 1.3.2
本次使用的数据如下:
- data = {
- 'brand':['Python数据之道','价值前瞻','菜鸟数据之道','Python','Java'],
- 'B':[4,6,8,12,10],
- 'A':[10,2,5,20,16],
- 'D':[6,18,14,6,12],
- 'years':[4,1,1,30,30],
- 'C':[8,12,18,8,2],
- }
-
- index = [9,3,4,5,2]
-
- df = pd.DataFrame(data=data,index=index)
- df
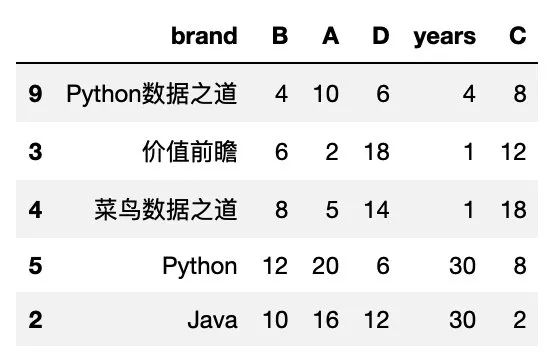
按行索引排序
sort_index() 是 pandas 中按索引排序的函数,默认情况下, sort_index 是按行索引来排序。

通过设置参数 ascending 可以设置升序或降序排列,默认情况下是 ascending=True ,为升序排列。
设置 ascending=False 时,为降序排列,如下:
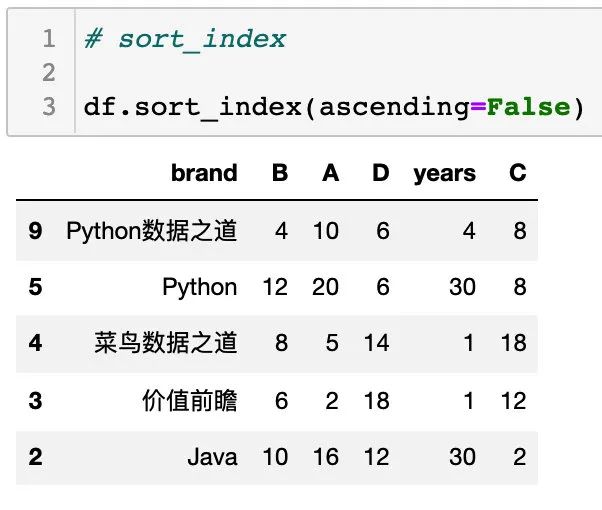
按列的名称排序
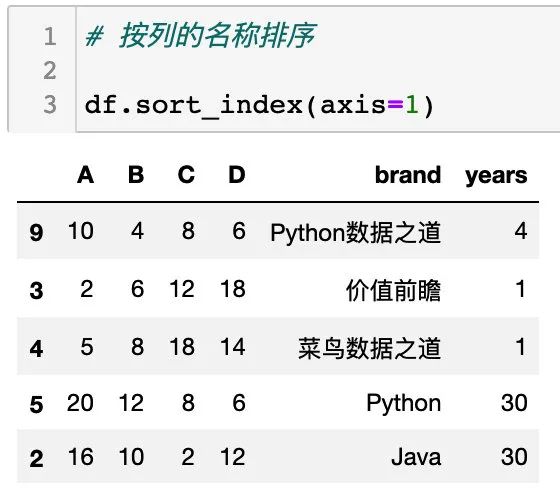
通过设置参数 axis=1 可实现按列的名称排序,如下:
同样的,可以设置 参数 ascending 的值,如下:
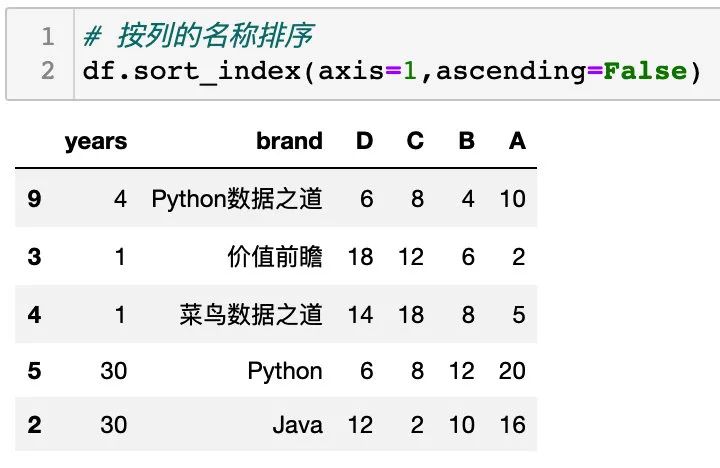
关于按列的名称排序,更多的方法,可以参考下面的内容:
02 按数值排序
sort_values() 是 pandas 中按数值排序的函数。
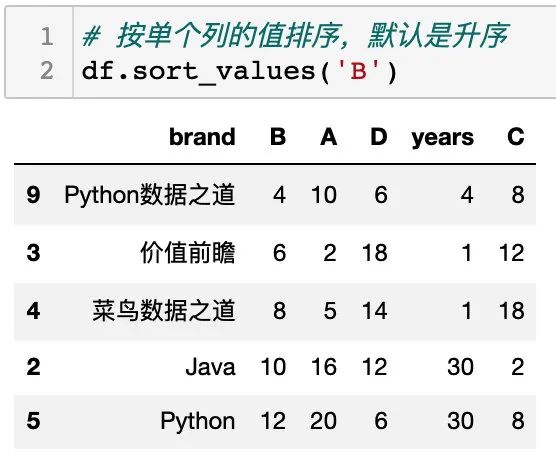
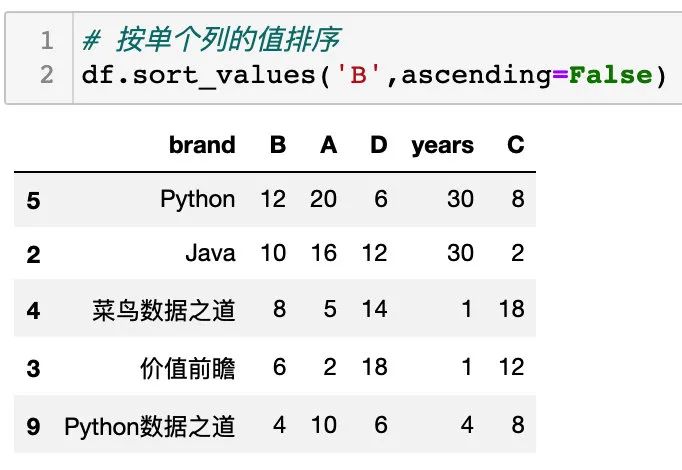
按单个列的值排序
sort_values() 中设置单个列的列名称,可以对单个列进行排序,通过设置参数 ascending 可以设置升序或降序排列,如下:
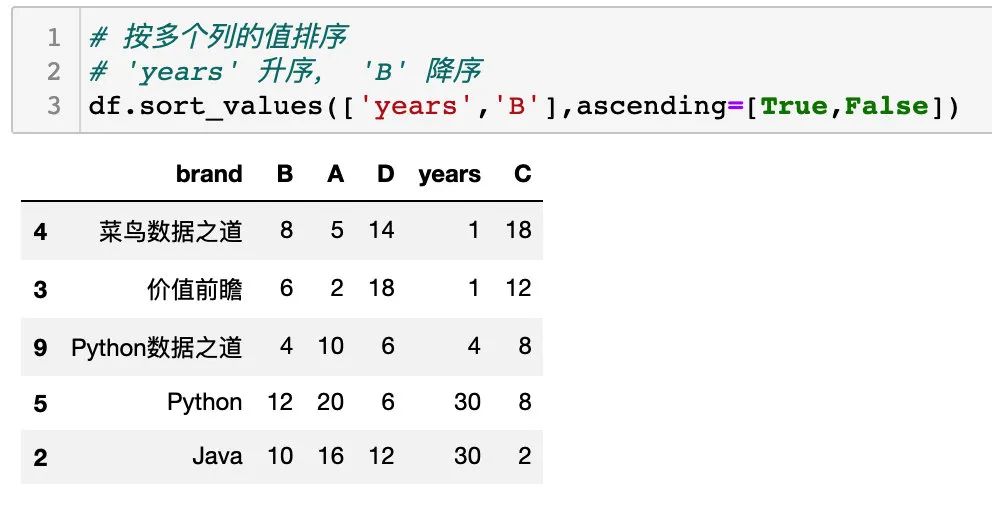
按多个列的值排序
同时,sort_values() 可以对多个列进行不同的排序,通过设置列明和排序方式组合来实现,如下:

设置参数 ascending ,years 列为升序,B 列为降序,如下:
选择排序算法
选择排序算法,参数 kind 默认是 'quicksort',其他算法有 mergesort, heapsort, stable。
该参数只针对单个列时才有效。

在 numpy 的 sort文档中,对几种排序的特点进行了描述,主要是程序运行时占用的资源和运行速度有差异。
numpy 文档地址:
https://numpy.org/doc/stable/reference/generated/numpy.sort.html#numpy.sort

示例如下:

忽略索引
在排序过程中,还可以引入 ignore_index 参数,来对行索引重新设置,如下:

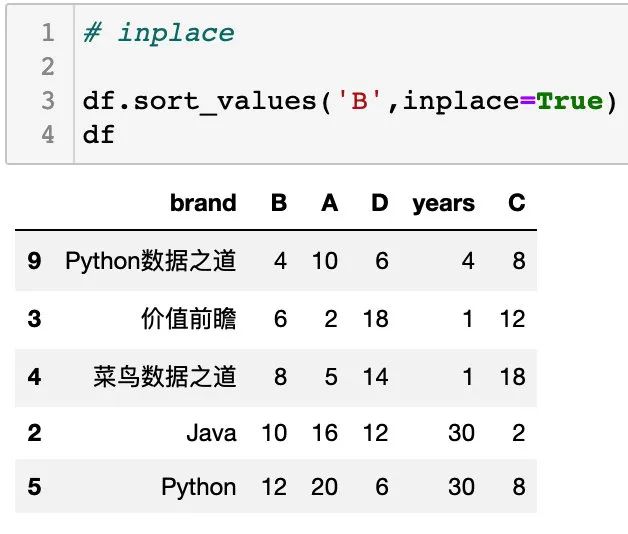
inplace
inplace 是 pandas 中常见的一个参数。
inplace = True:不创建新的对象,直接对原始对象进行修改;默认是 False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似。
缺失值
先构造一个含缺失值的 dataframe,如下:
- data = {
- 'brand':['Python数据之道','价值前瞻','菜鸟数据之道','Python','Java'],
- 'B':[4,6,8,np.nan,12],
- 'A':['Lemon','emma','ZW','app','John'],
- 'D':[6,18,14,6,12],
- 'years':[4,1,1,30,30],
- 'C':[8,12,18,8,2],
- }
-
- index = [9,3,4,5,2]
-
- df1 = pd.DataFrame(data=data,index=index)
- df1
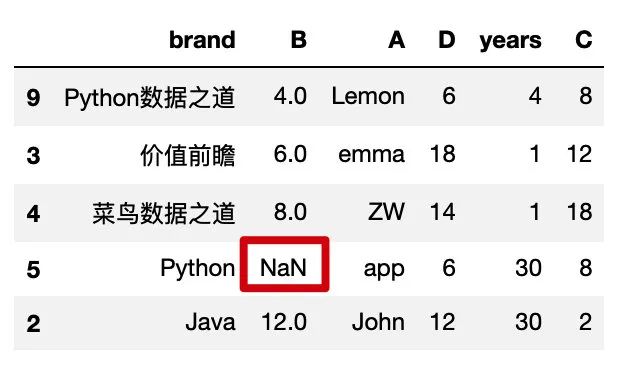
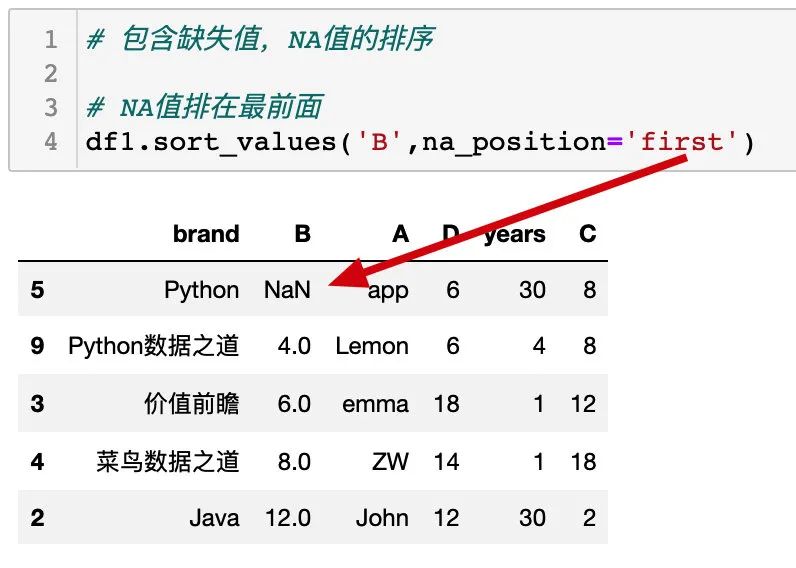
缺失值排在最前面:
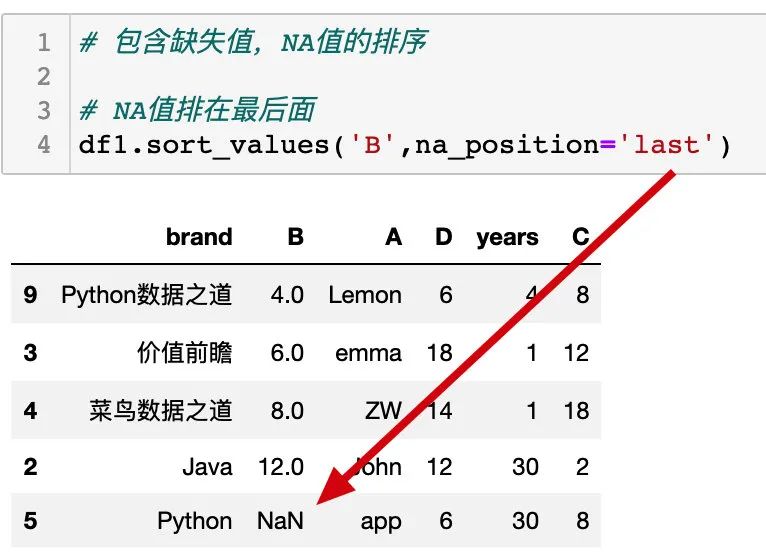
缺失值排在最后面:
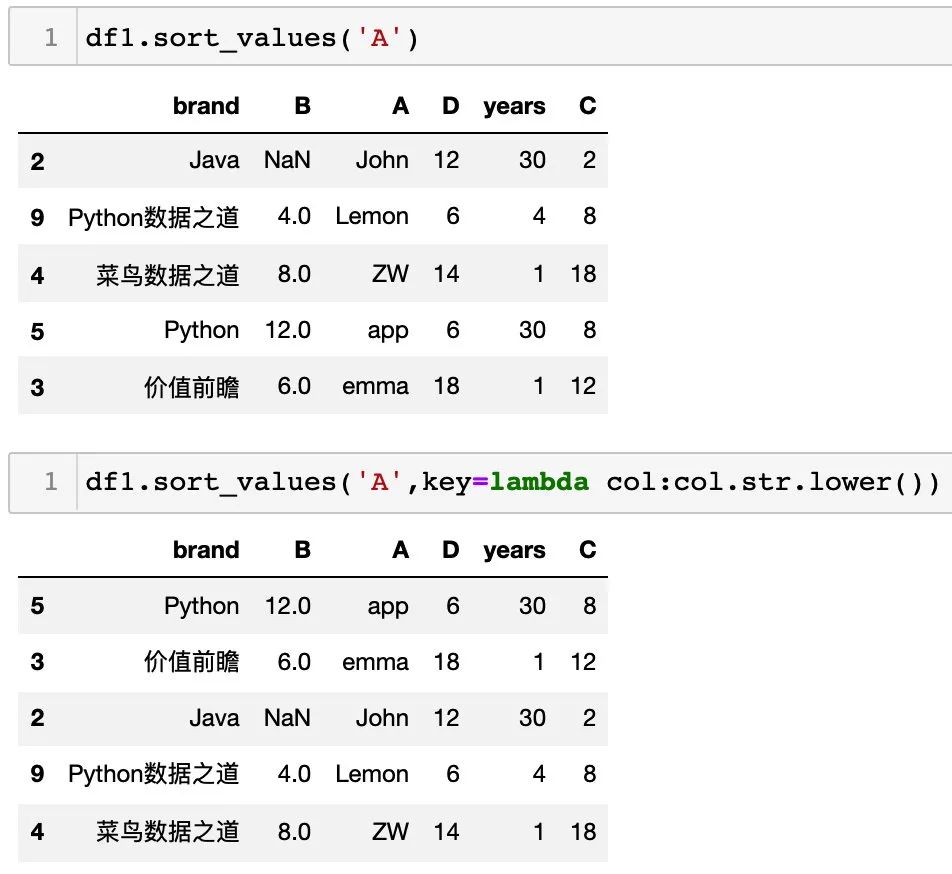
key 参数
通过设置 key 参数,可以将列按照特定条件进行排序,对比下下面的排序:
- ◆ ◆ ◆ ◆ ◆
- 麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
-
-
- 数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
- 管理员二维码:
- 猜你喜欢
- ● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
- ● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗

