
- 1毕设项目:电影院售票管理系统(JSP+java+springmvc+mysql+MyBatis)
- 2linux shell读取命令行参数_shell脚本获取cli输入的参数
- 3Redis底层数据结构详解_redis数据结构
- 4ret2dlresolve超详细教程(x86&x64)
- 5Linux中如何快速切换目录_返回到当前目录的家目录
- 6Axure RP9基本操作_axurerp9 bilibili
- 7基于STM32的多功能智能手环设计(可以当做毕设与简历项目)_简历上智能穿戴项目描述
- 8聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut_partitioning methods: k-means and k-medoids algori
- 92022华为ICT大赛全国总决赛网络赛道实验解析及验证_华为ict国赛讲解
- 10八大排序时间复杂度与稳定性_各种排序方法的时间复杂度与稳定性
顶刊TPAMI 2023!用于视觉识别的相互对比学习在线知识蒸馏
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!

转载自:智能感知与物联网技术研究所
本次文章介绍我们于 TPAMI-2023 发表的一项用于视觉识别的相互对比学习在线知识蒸馏(Online Knowledge Distillation via Mutual Contrastive Learning for Visual Recognition)工作,该工作是我们发表在 AAAI-2022 论文 Mutual contrastive learning for visual representation learning [1] 的扩展版本,论文讲解链接为:
https://zhuanlan.zhihu.com/p/574701719
摘要:无需教师的在线知识蒸馏联合地训练多个学生模型并且相互地蒸馏知识。虽然现有的在线知识蒸馏方法获得了很好的性能,但是这些方法通常关注类别概率作为核心知识类型,忽略了有价值的特征表达信息。
本文展示了一个相互对比学习(Mutual Contrastive Learning,MCL)框架用于在线知识蒸馏。MCL 的核心思想是在一个网络群体中利用在线的方式进行对比分布的交互和迁移。MCL 可以聚合跨网络的嵌入向量信息,同时最大化两个网络互信息的下界。这种做法可以使得每一个网络可以从其他网络中学习到额外的对比知识,从而有利于学习到更好的特征表达,提升视觉识别任务的性能。
相比于会议版本,期刊版本将 MCL 扩展到中间特征层并且使用元优化来训练自适应的层匹配机制。除了最后一层,MCL 也在中间层进行特征对比学习,因此新方法命名为 Layer-wise MCL(L-MCL)。在图像分类和其他视觉识别任务上展示了 L-MCL 相比于先进在线知识蒸馏方法获得了一致的提升。此优势表明了 L-MCL 引导网络产生了更好的特征表达。

论文地址:
https://arxiv.org/pdf/2207.11518.pdf
代码地址:
https://github.com/winycg/L-MCL

引言
传统的离线知识蒸馏需要预训练的教师模型对学生模型进行监督。在线知识蒸馏在无需教师的情况下同时联合训练两个以上的学生模型。深度相互学习(Deep Mutual Learning,DML)[2] 表明了模型群体可以从相互学习类别概率分布(图像分类任务最后的输出预测)中获益。每一个模型在同伴教授的模式下相比传统的单独训练效果更好。
现有的在线知识蒸馏方法通常仅仅关注结果驱动的蒸馏,但是忽略了在线蒸馏特征方面的应用。虽然先前的 AFD [3] 尝试通过在线的方式在多个网络间对齐中间特征图,Zhang 等人 [2] 指出这种做法会减少群体多样性,降低相互学习能力。为了学习更有意义的特征嵌入,我们认为一个更好的方式是从视觉表征学习角度的对比学习。
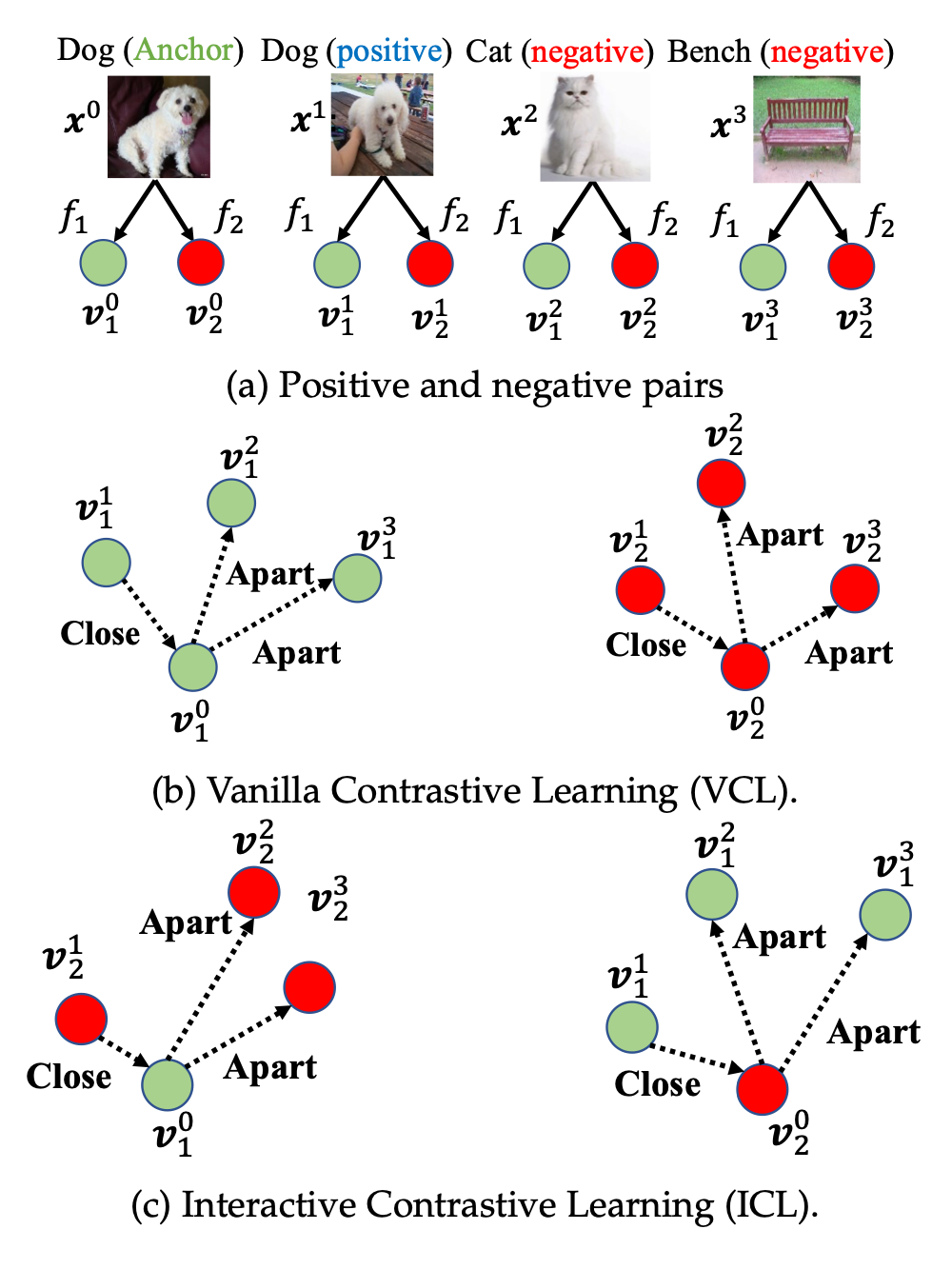
▲ 图1. 相互对比学习基本思想示意图
图中, 和 分别表示两个不同的网络, 是推理来自网络 和输入样本 产生的特征向量。虚线和箭头代表要逼近或者远离的方向。从图中可以看出,MCL 包含了朴素对比学习(Vanilla Contrastive Learning,VCL)和交互式对比学习(Interactive Contrastive Learning,ICL)。
相比于传统的 VCL,提出的 ICL 从两个不同网络间建模对比相似度分布。本文证明 ICL 的误差函数等价于最大化两个网络互信息的下界,这可以被理解为一个网络可以学习到另外网络额外的知识。
MCL 主要是发表于 AAAI-2022 的方法,期刊版本将 MCL 从卷积网络的最后一层扩展到多个模型的中间特征层,命名为 Layer-wise MCL。此外,传统的中间特征层蒸馏使用手工的匹配,本文则提出一个自适应的层匹配机制,然后通过元优化来训练该机制。

方法
2.1. 相互对比学习MCL(AAAI-2022)
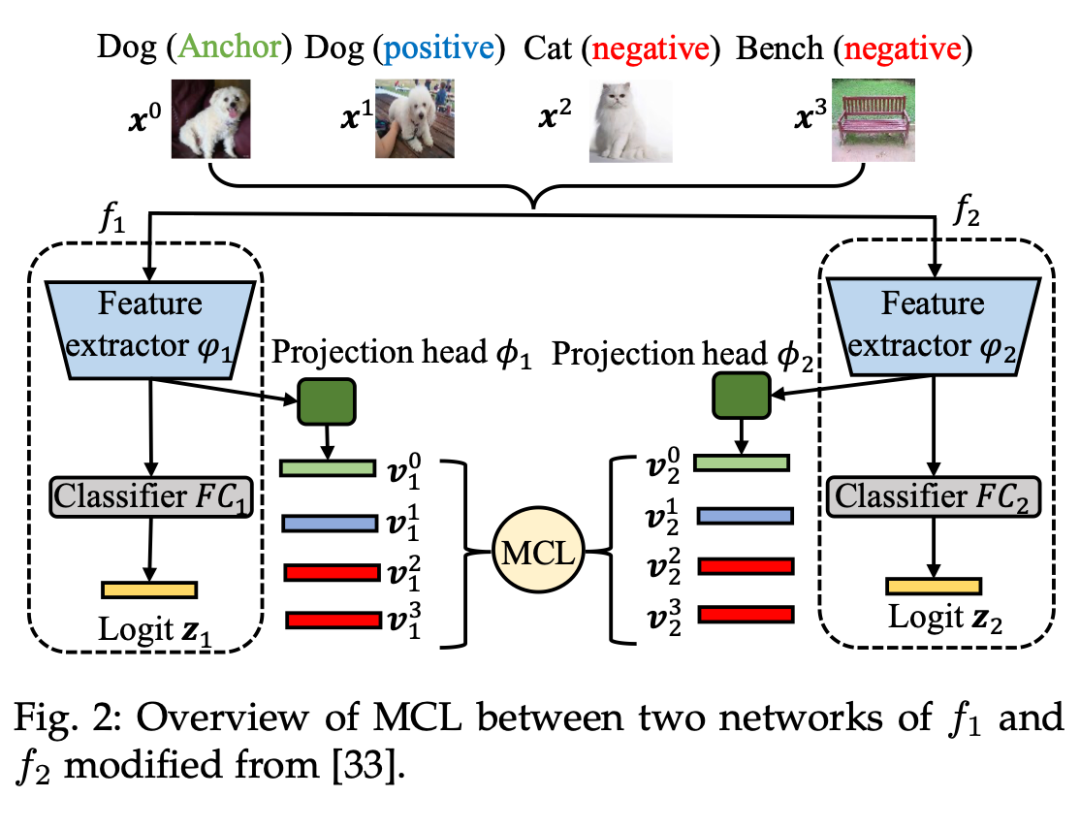
▲ 图2. 相互对比学习整体示意图
2.1.1 传统对比学习(Vanilla Contrastive Learning,VCL)
为了便于描述,本方法将 anchor 样本向量表示为 , 正样本向量表示为 和 个负样本向量表达为 。 表示向量产生自网络 。这里,特征向量通过 标准化进行预处理。使用基于 InfoNCE 的交叉熵作为对比误差:

对于总共 个网络来说,所有的对比误差表示为:
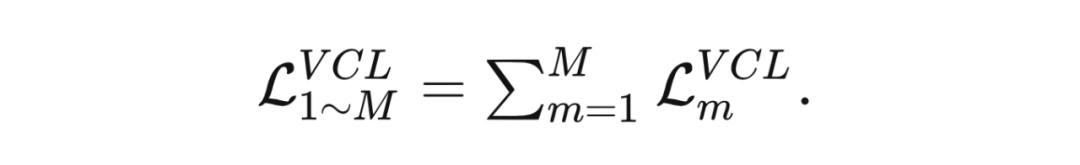
2.1.2 交互式对比学习(Interactive Contrastive Learning,ICL)
VCL 不能建模跨网络的关系来进行联合学习,因为对比分布来自于网络自身的嵌入空间。ICL 的 anchor 样本与对比样本产生自不同的网络,但在误差形式上依旧与传统的对比学习误差相同:
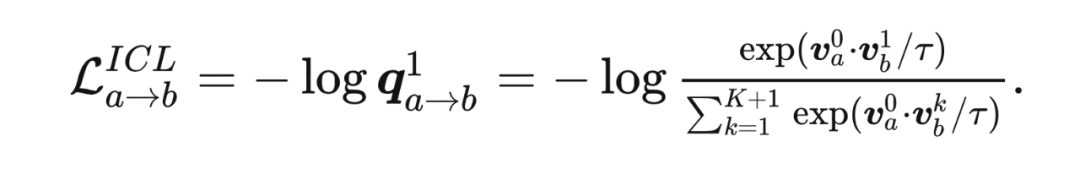
对于总共 个网络来说,所有的对比误差表示为:
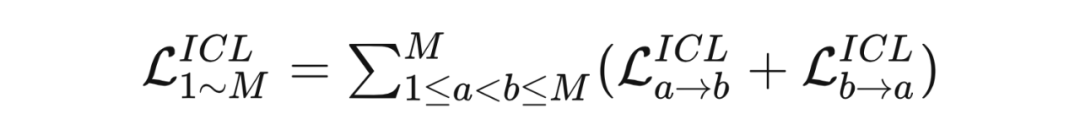
理论分析:
相比于误差 ,最小化 等价于最大化网络 互信息 的下界:
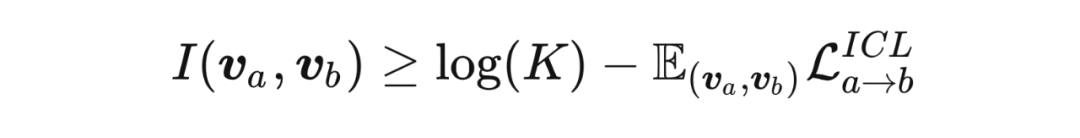
直觉上,当来自 的 anchor 特征向量已知时,互信息 衡量了来自 对比特征向量的不确定性,这可以理解为每一个网络可以从其他网络中学习到对比知识,从而更有利于表征学习。
2.1.3 基于在线相互迁移的软对比学习
收到深度相互学习(Deep Mutual Learning,DML)[1] 的启发,本方法利用 KL 散度来对齐网络间的对比分布,根据本文提出的两种对比学习方法 VCL 和 ICL 来进行对比分布的双向迁移:
2.1.3.1 Soft VCL:
对于产生 的分布 来说,其监督信号是其他网络 产生的分布 ,利用 KL 散度使得 与其他分布接近:
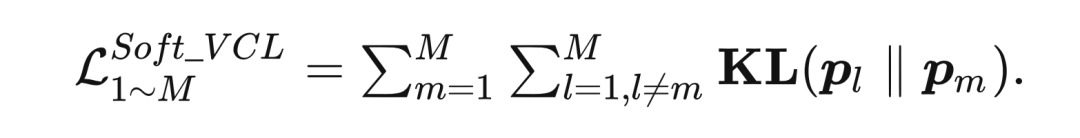
2.1.3.2 Soft ICL
给定两个网络 和 ,可以得到两个ICL对应的对比分布 和 ,使用 KL 散度的形式使得两个分布尽可能接近。对于 个网络来说,每两个网络进行对比分布的迁移:
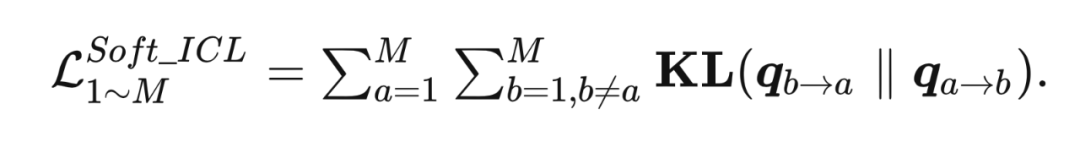
2.1.4 MCL的整体误差
为了尽可能利用联合学习的优势,本方法将所有的对比误差项作为一个整体的误差训练 个网络:
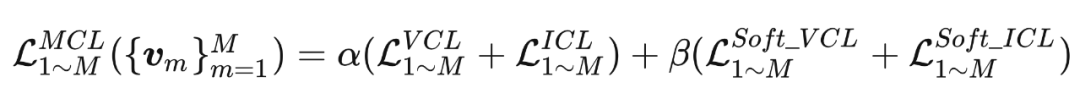
2.2 逐层的相互对比学习(Layer-wise MCL)
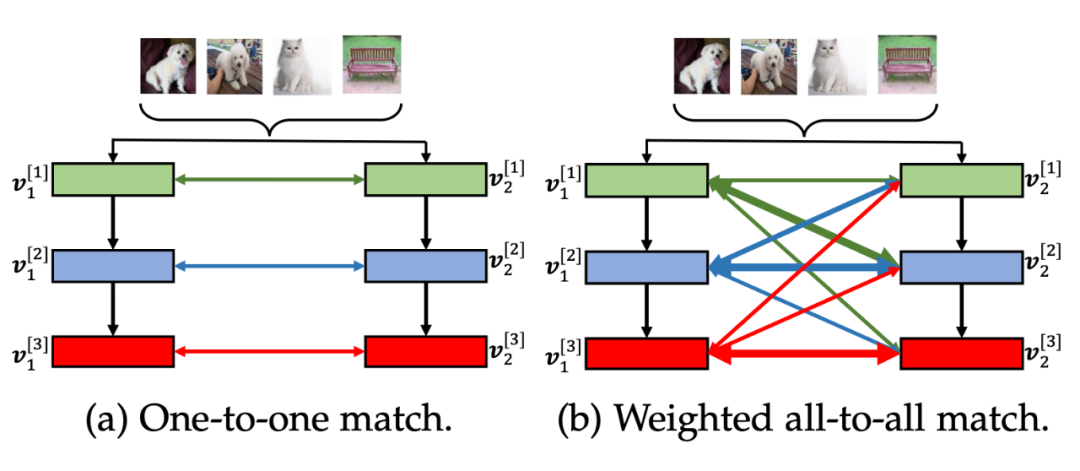
▲ 图3. 一对一匹配和加权的多对多匹配示意图
2.2.1 基础框架
给定网络群体 ,每一个网络具有 个阶段,原始的 MCL 在最后的特征嵌入 上进行学习。Layer-wise MCL(L-MCL)进一步扩展相互对比学习到中间特征层和最后特征层,并且采用跨层的方式。
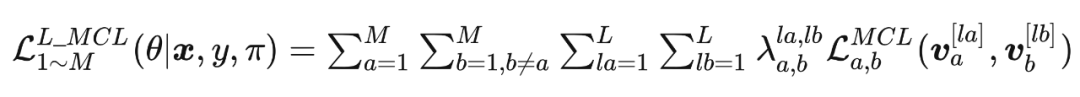
下一个章节,本文展示如何利用元网络 来优化匹配权重 。
2.2.2 训练元网络
2.2.2.1 交叉熵任务误差
使用交叉熵误差训练 个网络:
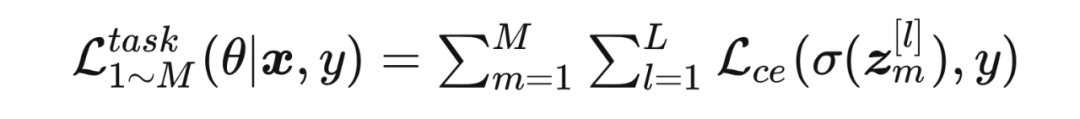
将基础的任务误差和 L-MCL 误差相加作为总误差来进行特征层面的在线蒸馏误差:
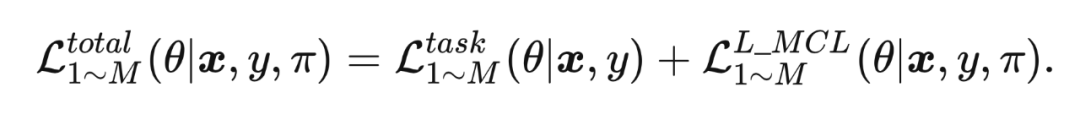
2.2.2.2 元优化
受到元学习的启发,本文采用交替优化的方式来训练学生网络和元网络:
(1)更新 来 次最小化 。
(2)更新 来一次最小化 。
(3)衡量 并且更新 来最小化它。
2.2.2.3 元网络 结构
元网络包含了两个线性转换层 和 ,来对输入的特征向量 进行转换。转换之后,特征向量通过 正则化 来进行标准化。受到自注意力机制的启发,本文利用点乘得到匹配特征的相似性,从而衡量匹配层的相关性,然后引入 sigmoid 激活函数 来将输出值缩放到 作为层匹配权重 。整体的过程被规则化为:
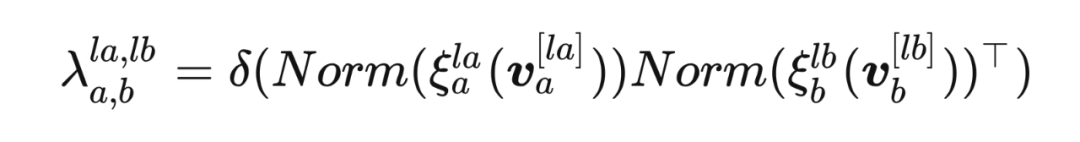

实验
在 ImageNet 上的实验结果如下所示,表 1 和表 2 分别展示了两个同构和异构网络利用相互对比学习的实验结果。
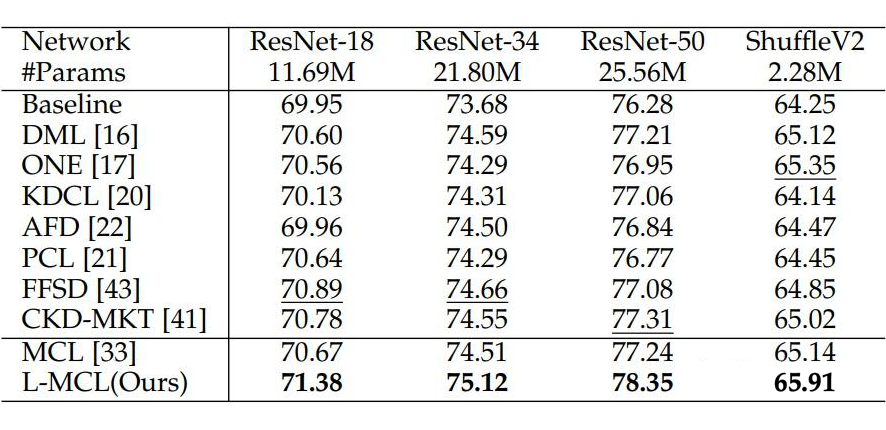
▲ 表1. 两个同构网络利用相互对比学习的实验结果
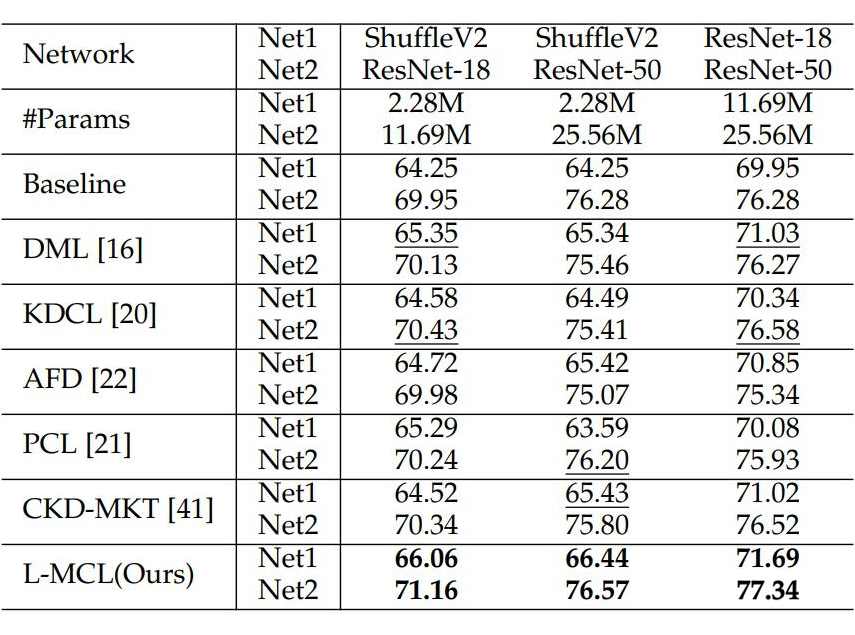
▲ 表2. 两个异构网络利用相互对比学习的实验结果
实验结果表明本文提出的 L-MCL 相比于 baseline 以及先前流行的在线知识蒸馏方法都获得了显著的性能提升,表明在多个网络之间使用特征层面的对比学习蒸馏相比概率分布效果更好。在下游的目标检测和实例分割实验上表明了该方法相比先前的蒸馏方法引导网络学习到了更好的视觉表征,从而提升了视觉识别效果。
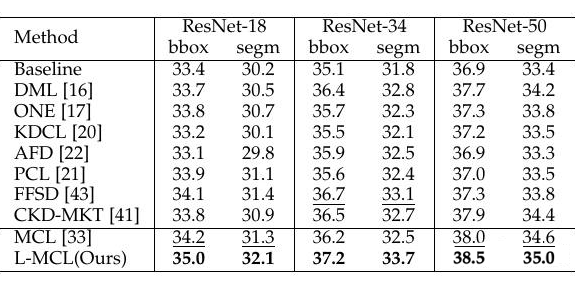
▲ 表3. 通过在线蒸馏的预训练网络迁移到下游的目标检测和与实例分割的实验

参考文献
[1] Yang C, An Z, Cai L, et al. Mutual contrastive learning for visual representation learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(3): 3045-3053.
[2] Zhang Y, Xiang T, Hospedales T M, et al. Deep mutual learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4320-4328.
[3] Chung I, Park S U, Kim J, et al. Feature-map-level online adversarial knowledge distillation[C]//International Conference on Machine Learning. PMLR, 2020: 2006-2015.
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集- 计算机视觉和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
- ▲扫码或加微信号: CVer444,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
-
- ▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号·

