
- 1通义千问1.5(Qwen1.5)大语言模型在PAI-QuickStart的微调与部署实践
- 2ios 判断app 启动方式_ios 怎么区分是被第三发个app 拉起启动的
- 3“RuntimeError:Sizes of tensors must match except in dimension1.Expected size 512 but got size 256_runtimeerror: sizes of tensors must match except i
- 4Scratch 之 3D 画笔程序使用_scratch3d教程
- 5STM32开发,VScode+Embedded IDE,简单方便,没有keil版权困扰
- 6【网盘聚合神器】支持百度(不限速)、阿里、天翼、迅雷、蓝奏、谷歌等29款网盘,使用Docker部署Alist网盘直链程序,给电脑整个80亿GB硬盘_聚合网盘自助服务解析
- 7网络安全常见隐患及防护措施_网络安全隐患和防范措施
- 8PHP网上购物系统论文 超市管理系统动态网页设计与实现课程设计报告_php动态网页设计与实现实训报告
- 9SQL注入的测试_sql注入异常检测是什么
- 10Redis链接出错_factory method 'redissonclient' threw exception; n
TVM 结构学习总结_tvm编译opencl下的图
赞
踩
最近对深度学习编译器TVM学习了一下,了解各部分的功能,根据自己的理解进行总结,如有不正确请指正,话不多说上脑图:

TVM为解决各种深度学习训练框架的模型部署到各种硬件而诞生
下图是TVM经典技术栈图:

编译器层次抽象:
- 编译器前端:接收C/C++/Java等不同语言,进行代码生成,吐出IR
- 编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
- 编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文件
TVM结构介绍:
1. Frontends
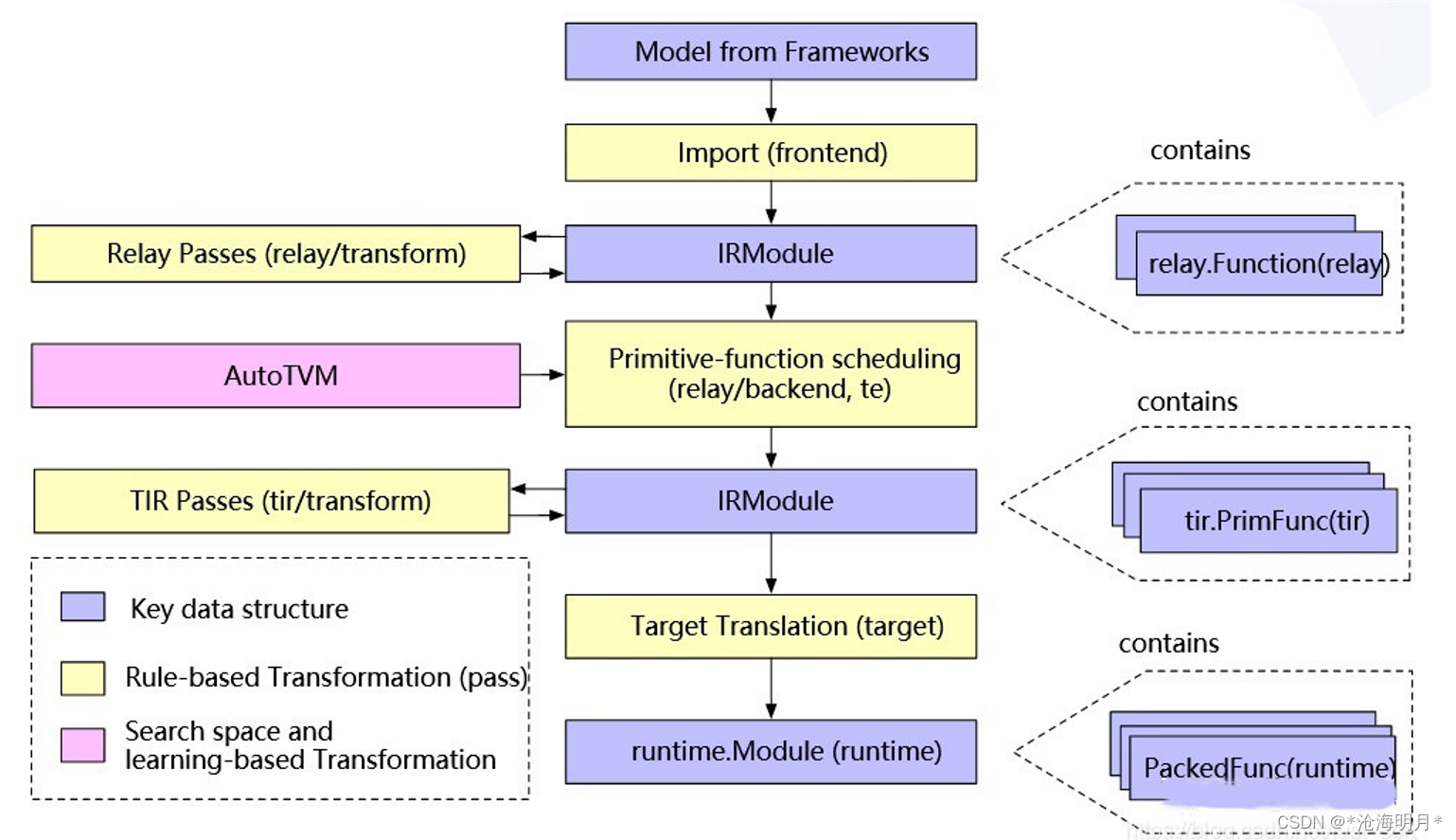
TVM的前端,完成各种深度学习框架的计算图到Relay IR的转化
2. IRModule
2.1 来源
Import(fronted): 各种深度学习框架的模型导入
Transform: IRModule等价转换达到优化的效果
2.2 结构:functions的集合
上层relay::Function(一个支持控制流,递归等计算图),在编译阶段,一个relay::Function可能会被lower成多个tir::PrimFunc
下层tir::PrimFunc(底层threading,vector/tensor的指令等OP执行单元)
2.3 IR 分类
前端的Relay IR:定义:high-level 计算图的描述,用IR表示来描述神经网络结构
LLVM的底层IR(Tir):借助Object元类实现统一的AST Node表示
2.4 主要模块
Topi:Tensor计算库,包含了很多神经网络通用的算子(矩阵乘法、卷积)
Te:Te表示Tensor Expression,用户可以通过调用te中的函数来构建Tir(可直接通过Te来写神经网络)
Node:可以允许用户对一些函数进行访问
Arith:这个和Tir有关,可以在Tir优化时进行一些分析
3. AutoTVM/Ansor
Relay Passes到TIR Passes的过程
1. 调度原语(scheduling primitives),比如循环变化(split, unrool..),内联,向量化,target搜索
2. 可选的自动调优模块。不断的跑程序,记录性能,调整调度选择,从log文件中选择最优的性能对应的调度方案来进行执行
4. Passes
定义:pass是对计算图的一些优化和转换,比如常量折叠,算符融合,死代码消除等。
4.1 按Transform分类
4.1.1 Relay Passes(relay transform)
常规:如constant folding、dead-code elimination
张量计算:如transformation,scaling factor folding
4.1.2 TIR Passes(Tir transform)
主要功能是lower和一些optimization
如多维数据扁平化、后端intrinsics扩展
4.2 按实现分类
Module Level Pass 基于全局信息进行优化,可以删减Function
Function Level Pass 对Module中的每个Function进行优化,只有局部信息
Sequential Level Pass 顺序执行一系列的Pass
4.3 新增pass步骤
通过遍历AST,修改node来实现的,通过TVM_REGISTER_GLOBAL宏来注册和暴露支持的Pass
1. 新增一个AST Traversers,用来确定哪些node是需要修改的
2. 新增一个Expression Mutators,用于修改和替换满足条件的node
5. Target Translation
编译器将TIR变换为目标硬件上可执行的格式(即代码生成)
对于X86和Arm CPU,TVM使用LLVM IR Builder在内存中构建llvm ir
生成源代码级别的语言,比如生成CUDA C或者OpenCL的源码
支持直接从Relay Function到特定后端的Codegen
6. Runtime Execution
6.1 runtime Module
封装编译DSO的核心单元,它包含了很多PackedFunc,可以根据name来获取
模式
模型是静态shape,没有控制流,则lower到graph runtime
模型是动态shape,有控制流,可以使用「virtual machine backend」
直接将子图级别的程序转换为executable and generated primitive functions的级别
6.2 runtime.PackedFunc
后端生成的函数,类似于深度学习框架中的核函数
6.3 runtime.NDArray
封装了执行期Tensor的结构
7. Executor
7.1 graph runtime
仅支持静态Tensor Shape以及没有控制流的程序
7.2 Relay Virtual Machine
解决动态Tensor shape和控制流的问题(动态Tensor shape只支持典型的推理场景,不支持训练)
7.3 Relay的解释器
只用来debug,因为解释器是通过遍历AST来执行程序,效率较低
 学习参考:
学习参考:
