
- 1分享成为高效程序员的7个重要习惯(转载)
- 2跨境电商平台搭建(小程序、软件、源码)_跨境软件源码
- 3AI 编程“神器”国产化!华为耗时 8 个月,这个能用中文生成代码的模型诞生了...
- 4滤波器简介:FIR与IIR_滤波器:fir、iir、ffr、集成、输出:fir、iir、ffr、集成、输出
- 5mos管驱动与米勒平台介绍、消除_米勒平台怎么改善
- 602333自考软件工程知识点总结、考点串讲、考前复习_02333软件工程
- 7腾讯云4核8G轻量服务器12M支持多少访客同时在线?并发数怎么算?_如何使用腾讯云做并发处理
- 8python统计词频_Python中文分词及词频统计
- 9CV 经典主干网络 (Backbone) 系列: CSPNet
- 10将Unicode转换成普通的Python字符串:“编码(encode)“_python unicode编码转换成字符
系列文章(十)丨边缘计算智能化加速_边缘计算模型推理加速
赞
踩
*本文作者系VMware中国研发中心研发总监 路广
之前的若干篇讨论了一般意义上的边缘计算,本篇将涉及一种特殊的计算形式,智能计算,和如何将其有效地集成到边缘计算中去。
第十篇 边缘计算智能化加速
人工智能与机器学习
在展开介绍之前先澄清几个容易混淆的概念。
人工智能(Artificial Intelligence)是指使计算机/机器展现出智慧的技术。机器学习(Machine Learning)是人工智能的子集,指通过数据不断改进(训练)计算机算法实现智能的方式。人工神经网络(Artificial Neural Network)是机器学习的子集,指通过模拟动物大脑中的生物神经网络来构造数据模型算法的方法。深度学习(Deep Learning)是人工神经网络的子集,指构造多层(深度)人工神经网络来实现训练目标的办法。
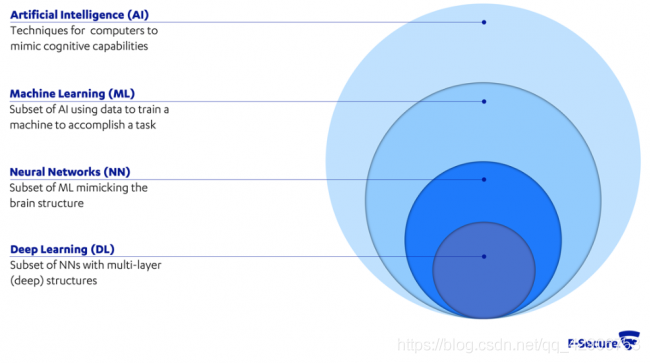
他们代表的领域范围可以用上图表示。一般来讲,非(人工)神经网络的机器学习方法对计算资源的需求并不高,而对(人工)神经网络来讲,多参数、大规模的深度学习,无论是训练还是推理阶段,计算资源消耗都非常大。但(人工)神经网络是近年来人工智能应用最火热和广泛的技术,因此有必要仔细研究如何提高它在边缘计算中的使用效率。
本篇讨论的重点就是(人工)神经网络。为简便起见,之后的篇幅我们都以神经网络来指代人工神经网络。
训练与推理
前面已经提到,对于机器学习技术来讲,都有训练(Training)和推理(Inference)两个过程。训练是利用大量数据和计算资源,反复迭代,最终得到符合精度要求的数据模型。推理是以训练得到的数据模型,应用于新数据来推断结论。这个过程对于无论是神经网络、还是支持向量机(Support Vector Machine)或随机森林(Random Forest)等其他机器学习方法,都是大同小异。但只有神经网络技术因为自身特性需要更大量计算资源来实现目标。
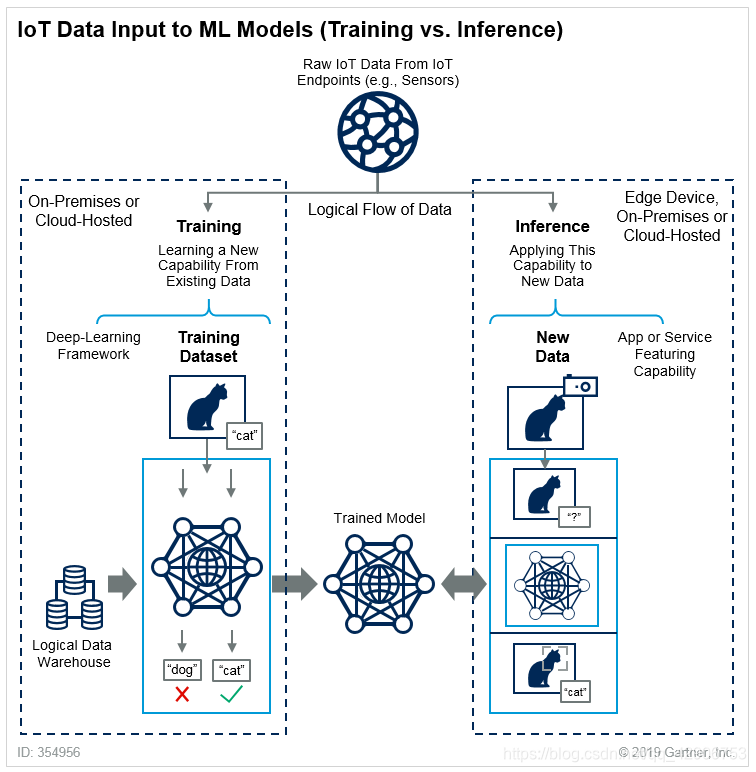
在实际生产环境中,实现神经网络技术的流程大多是在数据中心或云计算环境中训练,依据使用场景不同,在云中或边缘侧推理。
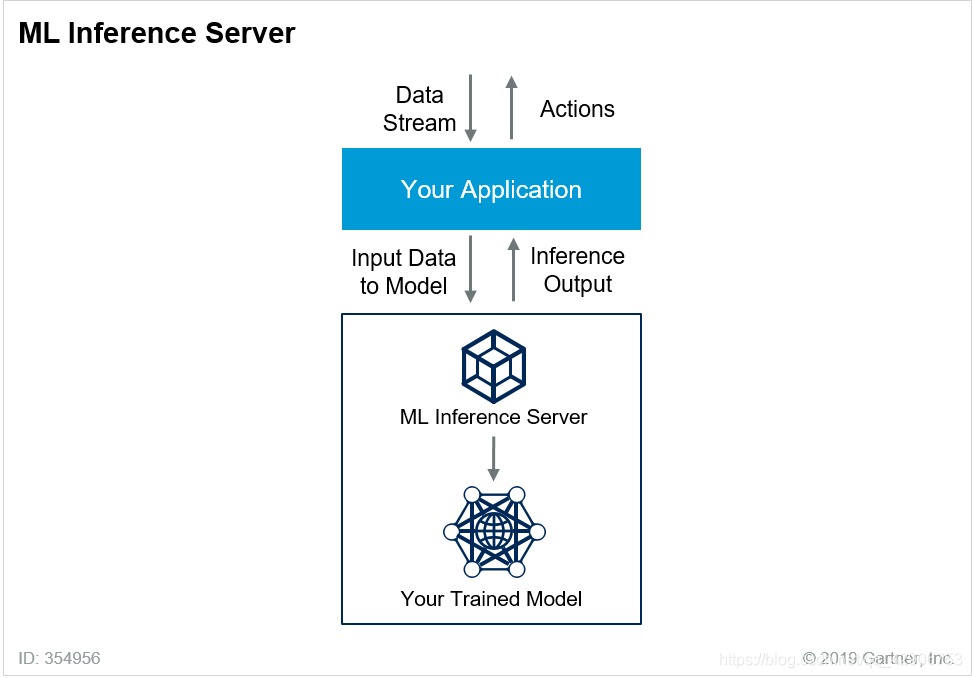
为了提高效率,用户常会搭建推理服务器(Inference Server),即输入神经网络模型和新数据,输出推理结果。把神经网络训练、推理和其他应用相集成,就能形成含机器学习和CI/CD的AI/ML DevOps完整流程。
数学内涵
篇首我们提到在机器学习各种算法中神经网络需要的计算资源相对更多,但由于它的推理结果可能达到更高的准确度,所以在各行业已经广泛应用。
神经网络需要更多的计算资源,原因在于它是模拟生物神经网络而建立模型。为了实现更高精度,常常需要更多的数据,以训练更大、更复杂的模型。
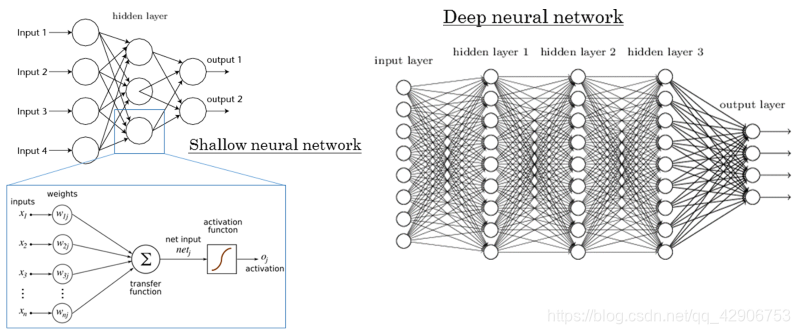
如上图所示,神经网络的模型越大,层数越多,对于解决复杂问题的效果可能越好。而运行该模型消耗的资源也水涨船高。比如对于某些大型社交网络,训练好的模型可能超过1TB。要完全加载到内存中才能运行,对计算资源的需求是很高的。
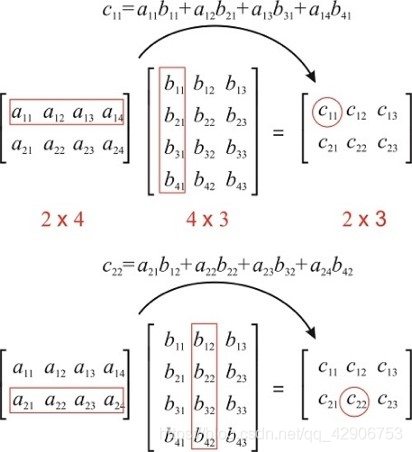
不仅需要更多的空间,处理神经网络模型本质上是进行多轮迭代的高维矩阵(Matrix)运算。这类运算的基本运算符是加法和乘法,运算数为高精度浮点数。矩阵运算实际上常常以单指令多数据(SIMD)的方式并行进行,而CPU这样为复杂指令、乱序执行而设计的器件已经不大适合执行此类并行计算任务了。
性能指标
讨论计算机系统的浮点性能指标,常会用到每秒浮点运算次数(FLOPS),它的理论值常可以用如下公式得出。
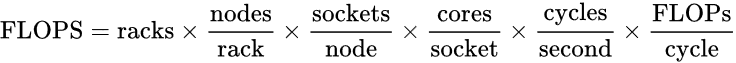
对于整个系统来讲,就是要想尽办法提高上面的每个乘数。对于单个CPU或其他计算器件来说,主要是要提高核心数、频率或SIMD。厂商以前常靠提高主频、后来采用添核的方式来提高CPU的浮点性能,SIMD相对比较稳定,直到最近像AVX-512这样的改进。而其他计算器件常以增加计算单元、辅以提高频率来达到目标。
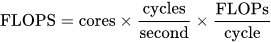
在现实环境中,还要考虑用电功耗和投资效率。由此每秒每瓦浮点运算次数(FLOPS / watt)和每秒每元浮点运算次数(FLOPS / dollar)这两个经济性指标也是考察重点。
以上讨论的都只是理论指标,还没有涉及特定器件、特定应用的优化工作。所以实际运行神经网络模型的性能可能低于理论性能指标。这也是用户希望看到的、未来有很大改进空间的领域。
异构加速器件
不同架构的计算模块一起运作的方式称为异构计算(Heterogeneous Computing)。这里只讨论用于加速机器学习的情形,非CPU的其他计算器件称作人工智能加速器件(AI Accelerator)。
因为现实中散热和功耗的限制,CPU已经普遍无法在浮点性能指标上满足要求,所以对于神经网络这样的的计算任务,就需要由异构加速器件来完成。
最常见的机器学习加速器件是GPU(包括GPGPU)、场可编程逻辑门阵列(FPGA,包括数字信号处理器/DSP)以及各种特殊应用集成电路(ASIC,包括但不限于TPU、VPU、NPU、XPU等)。

各种机器学习加速器件的架构各异,但共通之处是有大量可以执行并行计算的处理单元、与主机共享的高带宽内存、内置多层寄存器和缓冲区。本文的重点不是各种机器学习异构加速器件的硬件结构,所以在此不会详细介绍。
在这些机器学习加速器件中,有些是设计用来既做训练也做推理的,有些是专门用来做推理的,因为:

并行计算软件
为了驱动这些机器学习异构加速器件,支持各种主流的机器学习软件框架,需要合适的并行计算软件包。
以下是几种常见的并行计算软件:
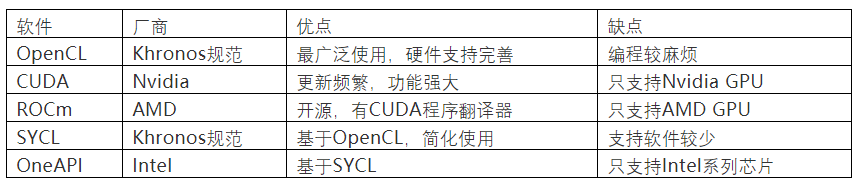
推理加速软件
类似地,为了加速机器学习推理,也有很多推理加速软件包,来驱动特定的推理专用加速器件。
机器学习推理加速软件的一般方法包括:
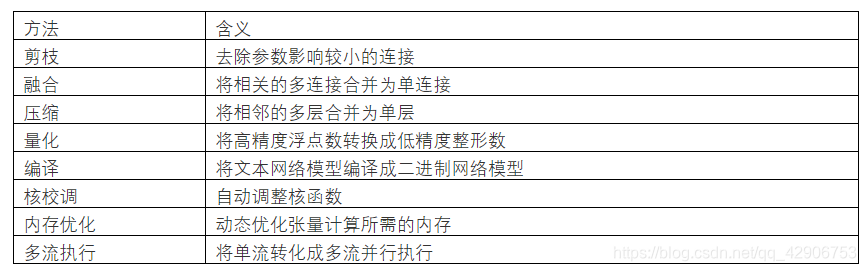
各种推理加速硬件不见得会利用以上所有的优化技术,更多地会采用其中的一部分。
以下是几种常见的推理加速软件:
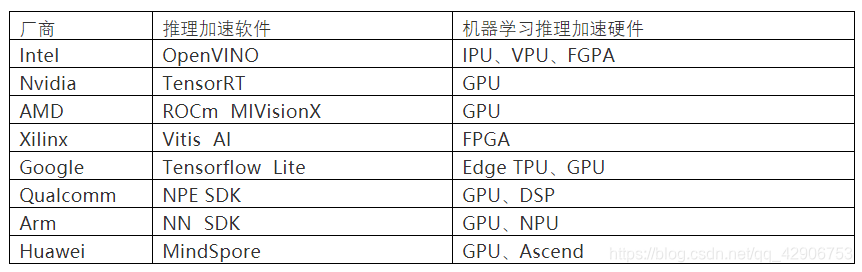
碎片化
很明显各厂商都希望各自推出的机器学习推理软件主要帮助自家的推理加速硬件实现更好的性能。
API/SDK各异的推理加速器件虽然能解决性能问题,但制造了软件生态碎片化的新问题。为了生产化部署,选定某型号的机器学习推理加速器件之后,就需要针对该特定硬件优化训练好的高维模型,为了最终能在部署后获得良好的效果。而几乎所有的集成和优化工作都是不可移植的。如果将来要改变推理加速器件,系统集成和优化过程基本上需要重做一遍。这对用户来讲不仅投入巨大,而且丧失了灵活性和互操作性。
业内现在并没有被众多厂商广泛接受的、统一的机器学习推理加速器件接口,现存的几个项目(比如ONNX Runtime和Adlik)在加速器件支持度、跨云连接性等方面的适用范围都相当有限。
通用机器学习推理接口:Supernova项目
为了在保证足够推理精度和效率的同时,解决配套软件API/SDK碎片化的问题,我们在2020年5月发布了Supernova项目技术预览版。
这也是支持VMware的战略愿景:运行在任何设备上、集成任何应用、连接任何云。
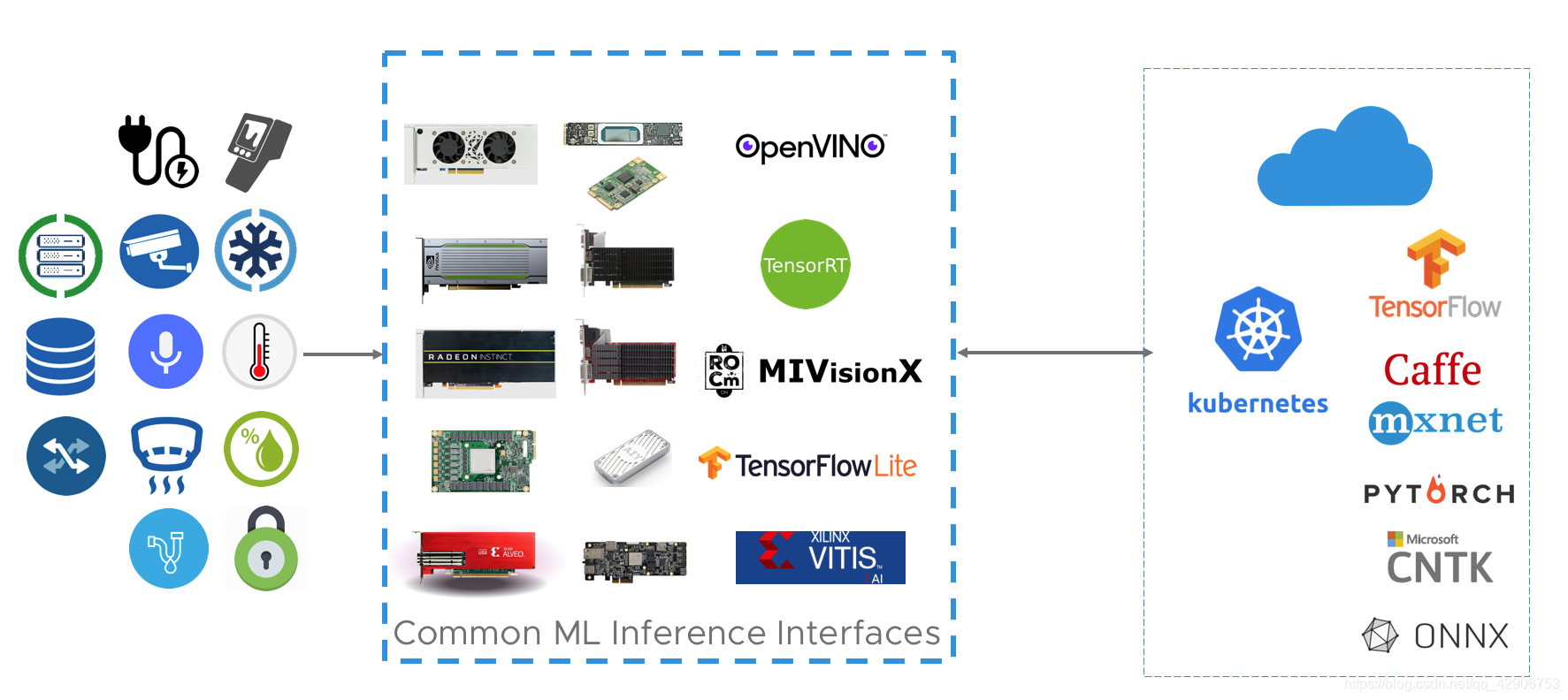
总体架构

上图是Supernova项目的总体架构,它由三类关键服务组成:
- 硬件系统服务:连接推理加速硬件、与各种输入设备;
- 管理服务:管理推理容器镜像、网络模型、硬件资源、输入/输出数据、任务调度、执行状态;
- 推理服务:根据提供的加速硬件、网络模型和输入数据,具体执行推理过程。
Supernova项目的整体技术方案是:
- 基于微服务、提供完整的Restful API
- 支持所有领先的机器学习推理异构加速器件/软件包
- 支持编译文本网络模型至二进制模型
- 对机器学习训练框架中立
- 支持从边缘到云的各种部署方式
主要功能
在Supernova项目已经发布的技术预览版中,支持如下系统的多种组合方式:
- X86-64和Arm64两种CPU架构
- Intel Movidius芯片的VPU、Nvidia GPU、Google Edge TPU三类推理加速器件
- Intel OpenVINO、Nvidia TensorRT、Tensorflow Lite三种推理软件
- Ubuntu 16.04+或CentOS 7.x以上
- Docker 19.03.4或以上
使用案例
在技术预览版中内置了种常见的使用案例,以驱动不同加速硬件的模型和推理程序。
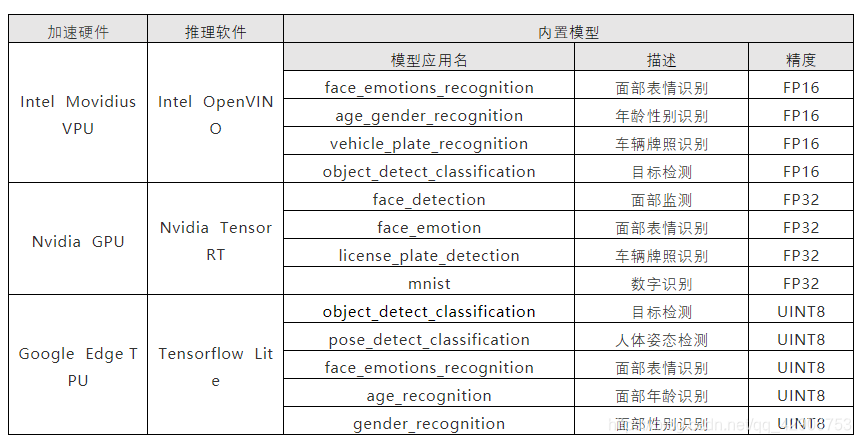
操作步骤
以Intel基于Movidius VPU的OpenVINO上的面部表情识别为例:
- 下载Supernova项目软件包,按照使用说明的步骤安装完成。
- 复制SSL/TLS证书:Supernova项目的Restful API基于SSL/TLS,需要:
-把cert.pem和 key.pem文件复制到~/supernova/res/cert目录下,
-将client.crt和 client.key文件复制到~/supernova/res/mqtt/certs目录下,
-将ca.crt文件复制到~/supernova/res/mqtt/ca_certificates目录下。
- 下载推理软件:下载所用推理加速硬件对应的推理软件包,本用例中是OpenVINO。
- 下载模型:有些模型的许可证禁止第三方再次分发,需要单独下载。在本用例中,要执行推理软件包里的如下命令:
downloader.py --name face-detection-retail-0004 --precisions FP16
downloader.py --name emotions-recognition-retail-0003 --precisions FP16
然后将其复制到~/supernova/inferencemodel/openvino/public目录。
- 调用Restful API,执行推理任务。Supernova项目的任务调度器使用8080端口,启动前需保证它没有被占用。
-查询支持的推理模型
GET https://localhost:8080/api/v1/inference/public/models

-查询支持的推理软件包
GET https://localhost:8080/api/v1/inference/inferkits

-提交一个新推理任务
POST https://localhost:8080/api/v1/task
将前两个API操作返回的结果作为参数填入下面的JSON格式:
- 1
- 2
- 3

在上面的例子中:
device.name是推理加速设备名”dev-intel-vpu-1”
inferenceModel.name是推理用的模型名”face_emotions_recognition”
inputDataSource是本机USB摄像头”0”
inferkit是推理软件名”OpenVINO”
在特定推理加速硬件上首次运行推理任务时,Supernova任务调度器会利用先前下载的推理软件包构建相应的容器镜像,所以需要时间较长,之后再执行该加速器件上的推理就不会再构建了。
-注册推理结果导出服务
POST https://localhost:8080/api/v1/inference/export

支持以MQTT、HTTP或其他协议导出。这里的taskName是之前提交推理任务的参数。
如果以Mosquitto为导出服务接收端获取推理任务结果,需要执行:
可以得到类似如下的结果:
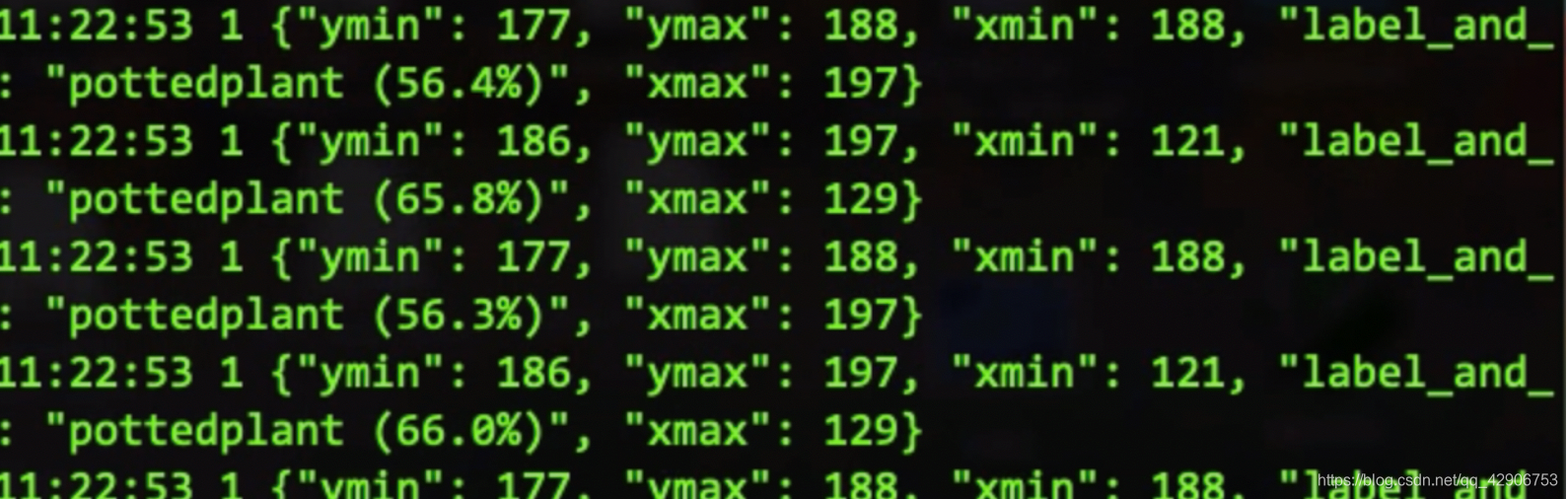
每行中的ymin, ymax, xmin, xmax就是识别出对象的坐标,百分比代表相应标签的概率。
- 预览推理结果
https://localhost:8080/api/v1/inference/video/preview/my-inference
除了导出推理任务文字结果,Supernova项目里还附带了一个简单的预览网页,将识别对象的坐标和最可能标签标注在图片或视频流上。
为避免隐私问题,下图是物体检测、而非面部表情识别预览结果。

我们即将刷新Supernova项目技术预览版,增加对AMD GPU和Xilinx FPGA的支持,允许用户上传自定义模型,发布通用Python推理脚本SDK等新功能,更全面地支持x86-64和Arm64平台,敬请期待。
- 未完待续 -
系列文章(十一)预告
本篇介绍了机器学习(神经网络)推理的基本原理和硬件加速方法,以及如何利用Supernova项目来实现跨加速器件、操作系统、网络模型的通用推理过程。
下一篇将转换焦点,从整体上分析边缘计算和云边协同中的安全问题,以及加固技术方案。

