
- 1vue+element-ui搭建简易的后台管理系统页面布局_后台管理系统里面折叠和展示的ui
- 2听说有 Hugging Face 陪伴的春节,是这样的…
- 3Android项目打包,及高德地图服务配置_高德 android api key打包
- 4Cassandra 3.x官方文档_安装DataStax Distribution of Apache Cassandra 3.x_datastax cassandra driver3.x 流程
- 5PyQt5 技术篇-QWidget、QDialog程序窗口关闭closeEvent()触发事件方法重写_pyqt5重写dialog
- 6vue中的public文件夹的作用,vue实例部署在index.html_public文件夹下放index.html做什么用的
- 7Express项目搭建与配置
- 8论el-menu自定义样式_el-menu为mode=vertical 自定义省略图标
- 9基于JerseyToken安全设计
- 10element的table点击选中之后设置当前行高亮_el-table tbody tr.current-row > td
2018:数据科学20个最好的Python库
赞
踩

作者 | ActiveWizards
译者 | 婉清
编辑 | 阿司匹林
出品 | AI科技大本营(公众号ID:rgznai100)
Python 在解决数据科学任务和挑战方面继续处于领先地位。去年,我们曾发表一篇博客文章 Top 15 Python Libraries for Data Science in 2017,概述了当时业已证明最有帮助的Python库。今年,我们扩展了这个清单,增加了新的 Python 库,并重新审视了去年已经讨论过的 Python 库,重点关注了这一年来的更新。
我们的选择实际上包含了 20 多个库,因为其中一些库是相互替代的,可以解决相同的问题。因此,我们将它们放在同一个分组。
▌核心库和统计数据
1. NumPy (Commits: 17911, Contributors: 641)
官网:http://www.numpy.org/
NumPy 是科学应用程序库的主要软件包之一,用于处理大型多维数组和矩阵,它大量的高级数学函数集合和实现方法使得这些对象执行操作成为可能。
2. SciPy (Commits: 19150, Contributors: 608)
官网:https://scipy.org/scipylib/
科学计算的另一个核心库是 SciPy。它基于 NumPy,其功能也因此得到了扩展。SciPy 主数据结构又是一个多维数组,由 Numpy 实现。这个软件包包含了帮助解决线性代数、概率论、积分计算和许多其他任务的工具。此外,SciPy 还封装了许多新的 BLAS 和 LAPACK 函数。
3. Pandas (Commits: 17144, Contributors: 1165)
官网:https://pandas.pydata.org/
Pandas 是一个 Python 库,提供高级的数据结构和各种各样的分析工具。这个软件包的主要特点是能够将相当复杂的数据操作转换为一两个命令。Pandas包含许多用于分组、过滤和组合数据的内置方法,以及时间序列功能。
4. StatsModels (Commits: 10067, Contributors: 153)
官网:http://www.statsmodels.org/devel/
Statsmodels 是一个 Python 模块,它为统计数据分析提供了许多机会,例如统计模型估计、执行统计测试等。在它的帮助下,你可以实现许多机器学习方法并探索不同的绘图可能性。
Python 库不断发展,不断丰富新的机遇。因此,今年出现了时间序列的改进和新的计数模型,即 GeneralizedPoisson、零膨胀模型(zero inflated models)和 NegativeBinomialP,以及新的多元方法:因子分析、多元方差分析以及方差分析中的重复测量。
▌可视化
5. Matplotlib (Commits: 25747, Contributors: 725)
官网:https://matplotlib.org/index.html
Matplotlib 是一个用于创建二维图和图形的底层库。藉由它的帮助,你可以构建各种不同的图标,从直方图和散点图到费笛卡尔坐标图。此外,有许多流行的绘图库被设计为与matplotlib结合使用。
6. Seaborn (Commits: 2044, Contributors: 83)
官网:https://seaborn.pydata.org/
Seaborn 本质上是一个基于 matplotlib 库的高级 API。它包含更适合处理图表的默认设置。此外,还有丰富的可视化库,包括一些复杂类型,如时间序列、联合分布图(jointplots)和小提琴图(violin diagrams)。
7. Plotly (Commits: 2906, Contributors: 48)
官网:https://plot.ly/python/
Plotly 是一个流行的库,它可以让你轻松构建复杂的图形。该软件包适用于交互式 Web 应用程,可实现轮廓图、三元图和三维图等视觉效果。
8. Bokeh (Commits: 16983, Contributors: 294)
官网:https://bokeh.pydata.org/en/latest/
Bokeh 库使用 JavaScript 小部件在浏览器中创建交互式和可缩放的可视化。该库提供了多种图表集合,样式可能性(styling possibilities),链接图、添加小部件和定义回调等形式的交互能力,以及许多更有用的特性。
9. Pydot (Commits: 169, Contributors: 12)
官网:https://pypi.org/project/pydot/
Pydot 是一个用于生成复杂的定向图和无向图的库。它是用纯 Python 编写的Graphviz 接口。在它的帮助下,可以显示图形的结构,这在构建神经网络和基于决策树的算法时经常用到。
▌机器学习
10. Scikit-learn (Commits: 22753, Contributors: 1084)
官网:http://scikit-learn.org/stable/
这个基于 NumPy 和 SciPy 的 Python 模块是处理数据的最佳库之一。它为许多标准的机器学习和数据挖掘任务提供算法,如聚类、回归、分类、降维和模型选择。
利用 Data Science School 提高你的技能
Data Science School:http://datascience-school.com/
11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
官网:
http://xgboost.readthedocs.io/en/latest/
http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
https://github.com/catboost/catboost
梯度增强算法是最流行的机器学习算法之一,它是建立一个不断改进的基本模型,即决策树。因此,为了快速、方便地实现这个方法而设计了专门库。就是说,我们认为 XGBoost、LightGBM 和 CatBoost 值得特别关注。它们都是解决常见问题的竞争者,并且使用方式几乎相同。这些库提供了高度优化的、可扩展的、快速的梯度增强实现,这使得它们在数据科学家和 Kaggle 竞争对手中非常流行,因为在这些算法的帮助下赢得了许多比赛。
12. Eli5 (Commits: 922, Contributors: 6)
官网:https://eli5.readthedocs.io/en/latest/
通常情况下,机器学习模型预测的结果并不完全清楚,这正是 Eli5 帮助应对的挑战。它是一个用于可视化和调试机器学习模型并逐步跟踪算法工作的软件包,为 scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite 库提供支持,并为每个库执行不同的任务。
▌深度学习
13. TensorFlow (Commits: 33339, Contributors: 1469)
官网:https://www.tensorflow.org/
TensorFlow 是一个流行的深度学习和机器学习框架,由 Google Brain 开发。它提供了使用具有多个数据集的人工神经网络的能力。在最流行的 TensorFlow应用中有目标识别、语音识别等。在常规的 TensorFlow 上也有不同的 leyer-helper,如 tflearn、tf-slim、skflow 等。
14. PyTorch (Commits: 11306, Contributors: 635)
官网:https://pytorch.org/
PyTorch 是一个大型框架,它允许使用 GPU 加速执行张量计算,创建动态计算图并自动计算梯度。在此之上,PyTorch 为解决与神经网络相关的应用程序提供了丰富的 API。该库基于 Torch,是用 C 实现的开源深度学习库。
15. Keras (Commits: 4539, Contributors: 671)
官网:https://keras.io/
Keras 是一个用于处理神经网络的高级库,运行在 TensorFlow、Theano 之上,现在由于新版本的发布,还可以使用 CNTK 和 MxNet 作为后端。它简化了许多特定的任务,并且大大减少了单调代码的数量。然而,它可能不适合某些复杂的任务。
▌分布式深度学习
16. Dist-keras / elephas / spark-deep-learning (Commits: 1125 / 170 / 67, Contributors: 5 / 13 / 11)
官网:
http://joerihermans.com/work/distributed-keras/
https://pypi.org/project/elephas/
https://databricks.github.io/spark-deep-learning/site/index.html
随着越来越多的用例需要花费大量的精力和时间,深度学习问题变得越来越重要。然而,使用像 Apache Spark 这样的分布式计算系统,处理如此多的数据要容易得多,这再次扩展了深入学习的可能性。因此,dist-keras、elephas 和 spark-deep-learning 都在迅速流行和发展,而且很难挑出一个库,因为它们都是为解决共同的任务而设计的。这些包允许你在 Apache Spark 的帮助下直接训练基于 Keras 库的神经网络。Spark-deep-learning 还提供了使用 Python 神经网络创建管道的工具。
▌自然语言处理
17. NLTK (Commits: 13041, Contributors: 236)
官网:https://www.nltk.org/
NLTK 是一组库,一个用于自然语言处理的完整平台。在 NLTK 的帮助下,你可以以各种方式处理和分析文本,对文本进行标记和标记,提取信息等。NLTK 也用于原型设计和建立研究系统。
18. SpaCy (Commits: 8623, Contributors: 215)
官网:https://spacy.io/
SpaCy 是一个具有优秀示例、API 文档和演示应用程序的自然语言处理库。这个库是用 Cython 语言编写的,Cython 是 Python 的 C 扩展。它支持近 30 种语言,提供了简单的深度学习集成,保证了健壮性和高准确率。SpaCy 的另一个重要特性是专为整个文档处理设计的体系结构,无须将文档分解成短语。
19. Gensim (Commits: 3603, Contributors: 273)
官网:https://radimrehurek.com/gensim/
Gensim 是一个用于健壮语义分析、主题建模和向量空间建模的 Python 库,构建在Numpy和Scipy之上。它提供了流行的NLP算法的实现,如 word2vec。尽管 gensim 有自己的 models.wrappers.fasttext实现,但 fasttext 库也可以用来高效学习词语表示。
▌数据采集
20. Scrapy (Commits: 6625, Contributors: 281)
官网:https://scrapy.org/
Scrapy 是一个用来创建网络爬虫,扫描网页和收集结构化数据的库。此外,Scrapy 可以从 API 中提取数据。由于该库的可扩展性和可移植性,使得它用起来非常方便。
▌结论
本文上述所列就是我们在 2018 年为数据科学领域中丰富的 Python 库集合。与上一年相比,一些新的现代库越来越受欢迎,而那些已经成为经典的数据科学任务的库也在不断改进。
下表显示了 GitHub 活动的详细统计数据:
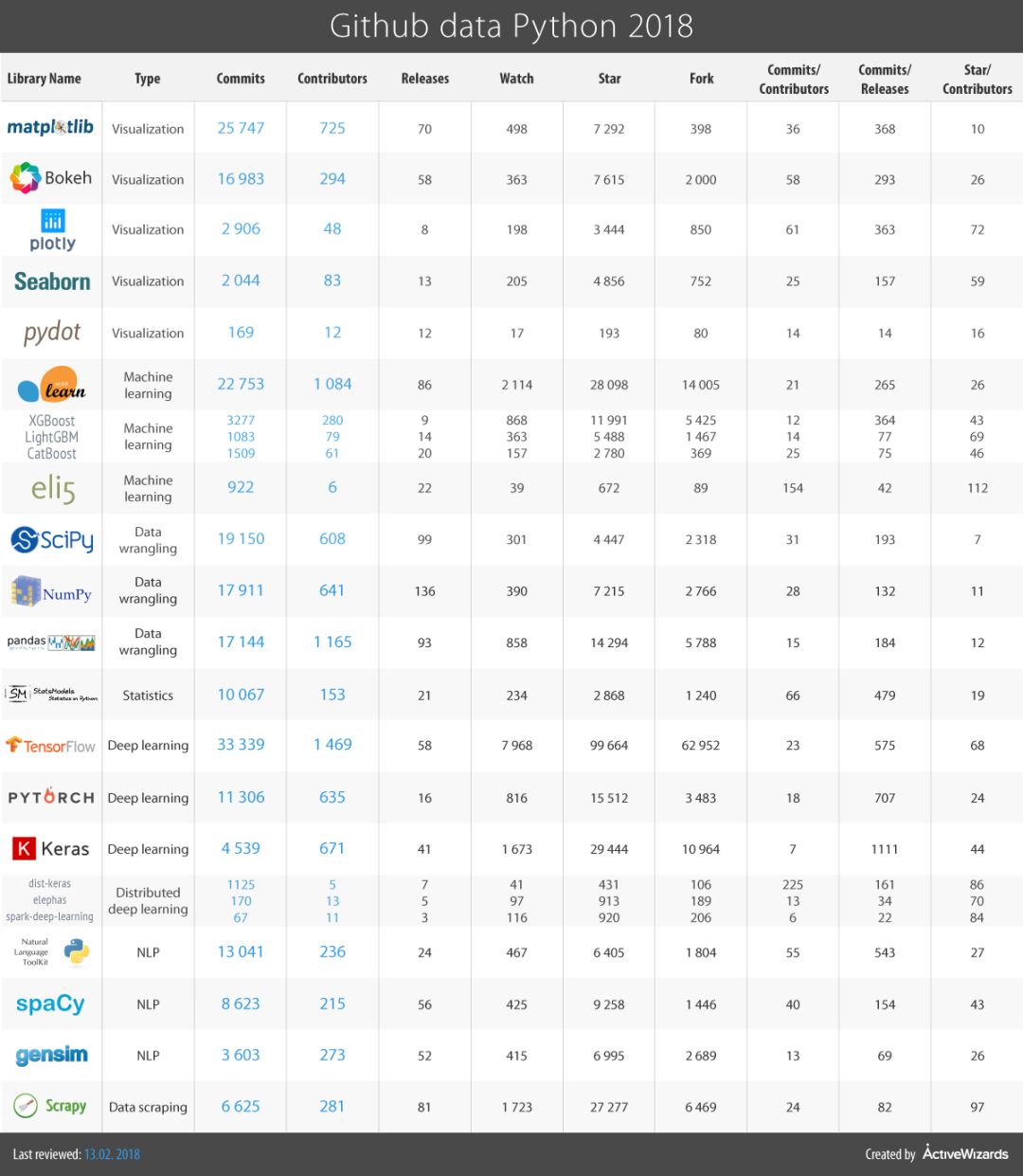
原文链接:
https://activewizards.com/blog/top-20-python-libraries-for-data-science-in-2018/
——【完】——
关注AI科技大本营,获取更多精彩内容添。加小助手csdnai,加入读者群


