
- 1单片机(一):VScode+SDCC+Make的Windows下51(CH552)单片开发环境搭建_visual studio code单片机开发
- 2Ubuntu18.04怪问题:/usr/bin/python: No module named pip
- 3ubuntu 选择独立显卡或则intelcpu内集成显卡_ubuntu独立显卡和自带共存
- 4Unity 常用脚本:Transform_通常用 的transform组件 表示脚本所挂在的游戏物体身上
- 5【Spring Boot Bean 注入详解】
- 6K8S-001-Virtual box - Network Config
- 7纯CSS制作3D动态相册【流星雨3D旋转相册】HTML+CSS+JavaScriptHTML5七夕情人节表白网页制作_h5 3d 旋转 相册
- 82020腾讯暑期游戏客户端实习面经(已OC)_腾讯 ieg 游戏客户端开发 暑期实习 oc
- 9UNREAL ENGINE 4.12 RELEASED!
- 10解决微信小程序支付后,回调函数重复执行的问题_微信支付的回调函数
OpenAI超级视频模型Sora登上央视,LeCun强推的「世界模型」雏形相继诞生,AGI如何能够以人类的理解方式看世界?_三维 3d 通用人工智能 lecun
赞
踩
OpenAI超级视频模型Sora热度不减
Sora一经面世,瞬间成为顶流,话题热度只增不减,一度登上央视新闻报道。
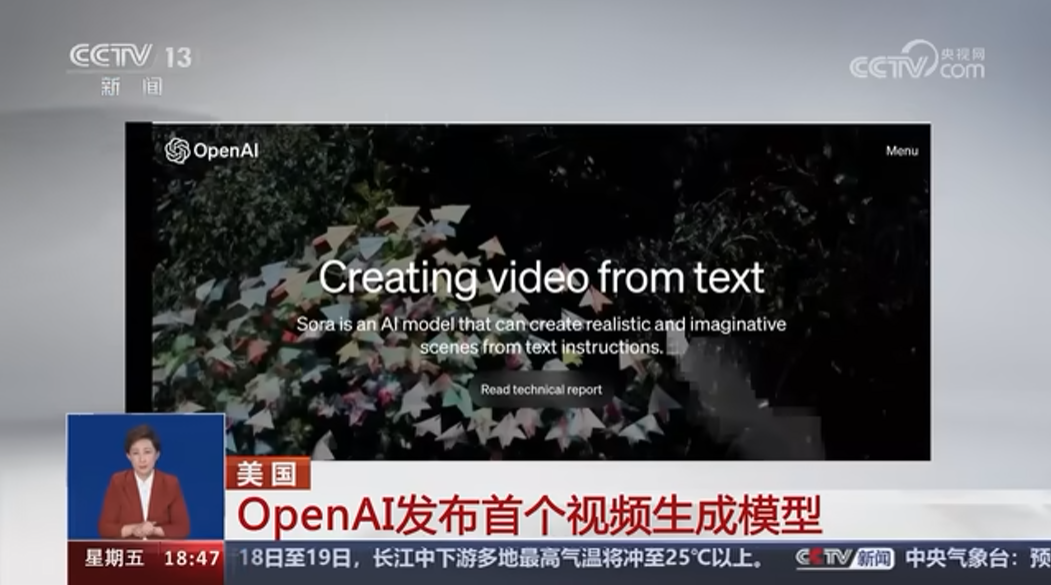
强大的逼真视频生成能力,让许多人纷纷惊呼「现实不存在了」。
OpenAI官方技术报告
OpenAI官方Sora技术报告:Video generation models as world simulators

甚至,OpenAI技术报告中也强调,Sora能够深刻地理解运动中的物理世界,堪称为真正的「世界模型」。
Video generation models as world simulatorsWe explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.![]() https://openai.com/research/video-generation-models-as-world-simulatorsOpenAI官方:“我们探索在视频数据上进行大规模生成模型的训练。具体来说,我们联合在变化时长、分辨率和宽高比的视频和图像上训练文本条件扩散模型。我们利用一个在视频和图像潜在编码的时空补丁上操作的变换器架构。我们最大的模型,Sora,能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型是通往构建物理世界通用模拟器的有希望途径。”
https://openai.com/research/video-generation-models-as-world-simulatorsOpenAI官方:“我们探索在视频数据上进行大规模生成模型的训练。具体来说,我们联合在变化时长、分辨率和宽高比的视频和图像上训练文本条件扩散模型。我们利用一个在视频和图像潜在编码的时空补丁上操作的变换器架构。我们最大的模型,Sora,能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型是通往构建物理世界通用模拟器的有希望途径。”
什么是世界模型?
去年初,Meta 首席 AI 科学家 Yann LeCun 针对「如何才能打造出接近人类水平的 AI」提出了全新的思路。他勾勒出了构建人类水平 AI 的另一种愿景,指出学习世界模型(即世界如何运作的内部模型)的能力或许是关键。这种学到世界运作方式内部模型的机器可以更快地学习、规划完成复杂的任务,并轻松适应不熟悉的情况。
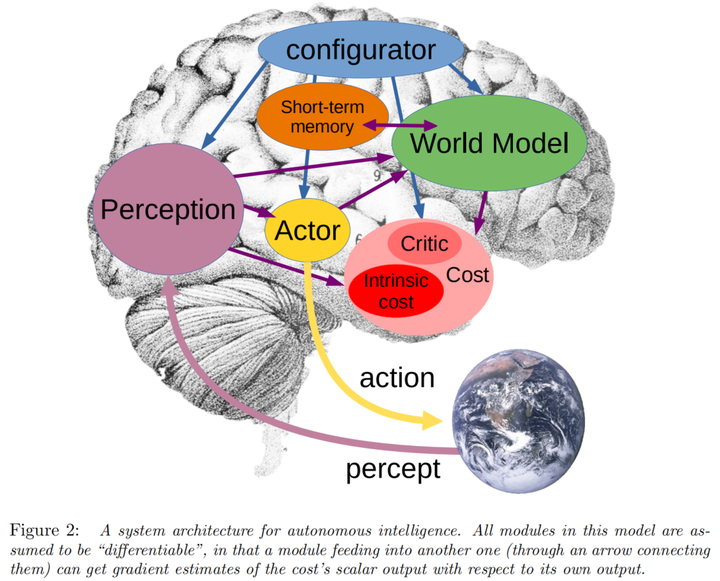
LeCun 根据动物的大脑运行机制,提出了一个端到端的仿生架构。该模型内部包含几个重要模块:感知模块、世界模型、短期记忆模块、执行者模块、代价模块(固定代价模块 & 批评家代价模块)以及配置模块。
该系统可以对世界进行分层表达,并在不同层级上实现最佳动作序列的规划和推理。在高层级可能会规划出一些粒度非常粗糙的任务,然后可以指导在低层级上产生更细粒度的子任务,达到一个自主拆解任务的目的。
该系统中有一个世界模型,它里面装了很多世界知识,能够帮助完成一些推理任务。该系统中还有一个记忆模块,他可以记录自己的第一反应和深度推理结果的差异,然后自我训练以达到不需要多思考就规划出优秀的动作序列的水平。
整个系统的驱动力是目标,也就是Cost模块让代价最小化。Cost模块里可以给智能体人工设置一些粗线条的规则可以称为机器人准则(是不可改变的准则),智能体未来在学习过程中,学出新的准则以指导自身的行动(新的准则也是根据机器人准则的自我衍生出来的,因此整个系统是安全的)。
LeCun 认为,构造自主 AI 需要预测世界模型,而世界模型必须能够执行多模态预测,对应的解决方案是一种叫做分层 JEPA(联合嵌入预测架构)的架构。该架构可以通过堆叠的方式进行更抽象、更长期的预测。
23年6 月 9 日,在 2023 北京智源大会开幕式的 keynote 演讲中,LeCun 又再次讲解了世界模型的概念,他认为基于自监督的语言模型无法获得关于真实世界的知识,这些模型在本质上是不可控的。

23年6月13日Meta 推出了首个基于 LeCun 世界模型概念的 AI 模型。该模型名为图像联合嵌入预测架构(Image Joint Embedding Predictive Architecture, I-JEPA),它通过创建外部世界的内部模型来学习, 比较图像的抽象表示(而不是比较像素本身)。
Meta官方:I-JEPA: The first AI model based on Yann LeCun’s vision for more human-like AI
https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/![]() https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/I-JEPA(Image Joint Embedding Predictive Architecture)是基于Yann LeCun愿景的第一个AI模型,旨在创建能够学习内部世界模型的机器,而更快地学习、规划复杂任务,并适应不熟悉的情况。I-JEPA通过创建外部世界的内部模型,使用图像的抽象表示(而非像素本身)进行学习,提高了多个计算机视觉任务的性能,同时比其他广泛使用的计算机视觉模型更为计算效率高。此模型代表了向能够像人类和动物那样通过观察和解释周围世界来学习的机器迈出的一步。
https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/I-JEPA(Image Joint Embedding Predictive Architecture)是基于Yann LeCun愿景的第一个AI模型,旨在创建能够学习内部世界模型的机器,而更快地学习、规划复杂任务,并适应不熟悉的情况。I-JEPA通过创建外部世界的内部模型,使用图像的抽象表示(而非像素本身)进行学习,提高了多个计算机视觉任务的性能,同时比其他广泛使用的计算机视觉模型更为计算效率高。此模型代表了向能够像人类和动物那样通过观察和解释周围世界来学习的机器迈出的一步。
Sora 世界模型惹争议

转载推特上AI大V Jim Fan的观点,
如果您认为 OpenAI Sora 是像 DALLE 一样的创意玩具,...再想一想。 Sora 是一个 数据驱动的物理引擎。它是对许多世界的模拟,无论是真实的还是幻想的。模拟器通过一些去噪和梯度数学来学习复杂的渲染、“直观”物理、长期推理和语义基础。
如果 Sora 使用 虚幻引擎 5 对大量合成数据进行训练,我不会感到惊讶。它必须如此!
我们来分解一下下面的视频。提示:“两艘海盗船在一杯咖啡内航行时互相战斗的逼真特写视频。”

- 模拟器实例化了两种精美的 3D资产:具有不同装饰的海盗船。 Sora 必须在其潜在空间中隐式地解决文本到 3D 的问题
- 3D 对象在航行并避开彼此路径时始终保持动画效果。
- 咖啡的流体动力学,甚至是船舶周围形成的泡沫。流体模拟是 计算机图形学的一个完整子领域,传统上需要非常复杂的算法和方程。
- 照片写实主义,几乎就像 光线追踪渲染一样。
- 模拟器考虑到杯子与海洋相比尺寸较小,并应用 移轴摄影来营造“微小”的氛围。
- 场景的语义在现实世界中并不存在,但引擎仍然实现了我们期望的正确物理规则。
接下来:添加更多模式和条件,然后我们就有了一个完整的数据驱动的 Unreal Engine,它将取代所有手工设计的图形管道。
这次OpenAI的技术报告「视频生成模型作为世界模拟器」,直接就把 Scaling video generation 称为走向通用物理世界模拟器的 promising path。

在后面的OpenAI官方技术报告里也提到:从这一部分开始,Sora 所展现出的能力是超出原有预期的,属于「智能涌现」。
这些能力使得Sora能够模拟出一些来自物理世界的人、动物和环境的某些方面。
同时,OpenAI 也在强调,这些能力完全来自于 Scale。Scale Law 还在上分!
然而,在LeCun 看来,「仅根据文字提示生成逼真的视频,并不代表模型理解了物理世界。生成视频的过程与基于世界模型的因果预测完全不同」。

接下来,LeCun更详细地解释道:
- 虽然可以想象出的视频种类繁多,但视频生成系统只需创造出「一个」合理的样本就算成功。
- 而对于一个真实视频,其合理的后续发展路径就相对较少,生成这些可能性中的具代表性部分,尤其是在特定动作条件下,难度大得多。
- 此外,生成这些视频后续内容不仅成本高昂,实际上也毫无意义。
- 更理想的做法是生成那些后续内容的「抽象表示」,去除与我们可能采取的行动无关的场景细节。
- 这正是JEPA(联合嵌入预测架构)的核心思想,它并非生成式的,而是在表示空间中进行预测。
然后,他用自家的研究VICReg、I-JEPA、V-JEPA以及他人的工作证明:
- 与重建像素的生成型架构,如变分自编码器(Variational AE)、掩码自编码器(Masked AE)、去噪自编码器(Denoising AE)等相比,「联合嵌入架构」能够产生更优秀的视觉输入表达。
- 当使用学习到的表示作为下游任务中受监督头部的输入(无需对主干进行微调),联合嵌入架构在效果上超过了生成式架构。
也就是在Sora模型发布的当天,Meta重磅推出一个全新的无监督「视频预测模型」——V-JEPA。
自2022年LeCun首提JEPA之后,I-JEPA和V-JEPA分别基于图像、视频拥有强大的预测能力。
号称能够以「人类的理解方式」看世界,通过抽象性的高效预测,生成被遮挡的部分。
论文地址:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video
V-JEPA看到下面视频中的动作时,会说「将纸撕成两半」。

再比如,翻看笔记本的视频被遮挡了一部分,V-JEPA便能够对笔记本上的内容做出不同的预测。

Perplexity AI的首席执行官表示:
- Sora虽然令人惊叹,但还没有准备好对物理进行准确的建模。并且Sora的作者非常机智,在博客的技术报告部分提到了这一点,比如打碎的玻璃无法很好地建模。
Sora,以及V-JEPA真的能够理解世界吗?未来的通用智能(AGI)模型又将如何发展呢?
探索智能边界,发现无限可能
欢迎加入智慧地球社区AIO通用智能(AGI)服务交流QQ群:949698745,共同探讨未来智能科技!
欢迎添加助理VX:AIEarth_Phoenixash或AIEarth_AIO,加入智慧地球社区Sora 世界模型vx交流群!
智慧地球(AI·Earth)社区AIO通用智能服务中心是您踏入人工智能世界的理想门户。我们致力于打造一个友好、开放、创新的平台,让每个人都能感受到AI技术的力量,享受科技进步带来的红利。加入我们,体验一站式AGI服务,成为智慧地球(AI·Earth)社区的一员,共同探索未来技术的边界!

