
- 1Python 做个小爬虫对CSDN热榜变冷榜的指标数据进行分析_冷热点分析python
- 2软件项目管理 --SVN目录结构_项目管理svn目录结构
- 3大模型(LLMs)算法工程师相关的面试题和参考答案
- 4信息技术服务 运行维护_【ITSS新闻动态 】信息技术服务 运行维护 第1部分:通用要求 国家标准封闭编写会在上海召开...
- 5error: macro “H“ requires 3 arguments, but only 1 given FORALL_NS_SYMBOLS(DEFINE_SYMBOL)_macro "accept" requires 3 arguments, but only 1 gi
- 6Python pandas 染色体 SNP 位点提取 并排序_提取某一位点的碱基时cigar字符串的操作
- 7边缘计算和云边端协同网络的融合_协同融合网络
- 8学习前端的前置知识(认识前端三大件)_前端最基础的三大件是什么
- 9鸿蒙 API9 接入 Crypto库_error: failed :entry:default@mergeprofile... > hvi
- 10利用nativefier和electron-winstaller实现将前端网站打包成桌面程序exe文件。_nativefier electron
GO语言slice详解(结合源码)_make([]int32, 0)
赞
踩
一、GO语言中slice的定义
石头网 https://www.10tou.comslice 是一种结构体类型,在源码中的定义为:
src/runtime/slice.go
- type slice struct {
- array unsafe.Pointer
- len int
- cap int
- }
从定义中可以看到,slice是一种值类型,里面有3个元素。array是数组指针,它指向底层分配的数组;len是底层数组的元素个数;cap是底层数组的容量,超过容量会扩容。
二、初始化操作
slice有三种初始化操作,请看下面代码:
- package main
- import "fmt"
- func main() {
- //1、make
- a := make([]int32, 0, 5)
- //2、[]int32{}
- b := []int32{1, 2, 3}
- //3、new([]int32)
- c := *new([]int32)
- fmt.Println(a, b, c)
- }
这几种初始化方式,在底层实现是不一样的。有一种了解底层实现好的方法,就是看反汇编的调用函数。运行下面命令即可看到代码某一行的反汇编:
go tool compile -S plan9Test.go | grep plan9Test.go:行号
1、make初始化
make函数初始化有三个参数,第一个是类型,第二个长度,第三个容量,容量要大于等于长度。slice的make初始化调用的是底层的runtime.makeslice函数。
- func makeslice(et *_type, len, cap int) slice {
- // NOTE: The len > maxElements check here is not strictly necessary,
- // but it produces a 'len out of range' error instead of a 'cap out of range' error
- // when someone does make([]T, bignumber). 'cap out of range' is true too,
- // but since the cap is only being supplied implicitly, saying len is clearer.
- // See issue 4085.
- maxElements := maxSliceCap(et.size)
- if len < 0 || uintptr(len) > maxElements {
- panic(errorString("makeslice: len out of range"))
- }
-
- if cap < len || uintptr(cap) > maxElements {
- panic(errorString("makeslice: cap out of range"))
- }
-
- p := mallocgc(et.size*uintptr(cap), et, true)
- return slice{p, len, cap}
- }

主要就是调用mallocgc分配一块 个数cap*类型大小 的内存给底层数组,然后返回一个slice,slice的array指针指向分配的底层数组。
2、[]int32{} 初始化
这种初始化底层是调用 runtime.newobject 函数直接分配相应个数的底层数组。
- // implementation of new builtin
- // compiler (both frontend and SSA backend) knows the signature
- // of this function
- func newobject(typ *_type) unsafe.Pointer {
- return mallocgc(typ.size, typ, true)
- }
3、new([]int32) 初始化
这种初始化底层也是调用 runtime.newobject ,new是返回slice 的地址,所以要取地址里面内容才是真正的slice。
三、reSlice(切片操作)
所谓reSlice,是基于已有 slice 创建新的 slice 对象,以便在容量cap允许范围内调整属性。
- data := []int32{0,1,2,3,4,5,6}
- slice := data[1:4:5] // [low:high:max]
切片操作有三个参数,low、high、max,新生成的 slice 结构体三个参数,指针array指向原slice 底层数组元素下标为low的位置, len = high - low, cap = max - low。如下图所示:
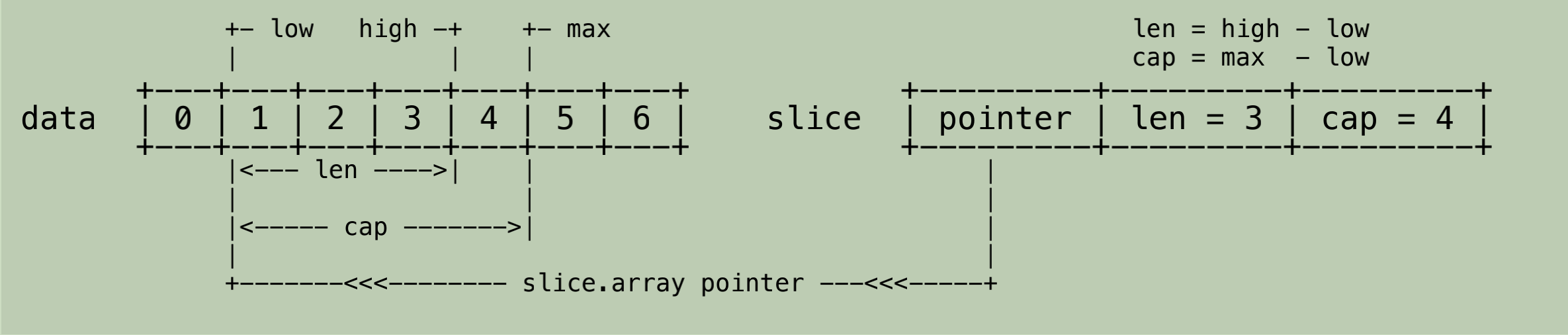
切片操作主要要注意的就是在原slice 容量允许范围,超出容量范围会报panic。
四、append 操作
slice 的 append 操作是向底层数组尾部添加数据,返回 新的slice对象。
请看下面一段代码:
- package main
- import (
- "fmt"
- )
- func main() {
- a := make([]int32, 1, 2)
- b := append(a, 1)
- c := append(a, 1, 2)
- fmt.Printf("a的地址:%p, 第一个元素地址:%p,容量:%v
- ", &a, &a[0], cap(a))
- //a的地址:0xc42000a060, 第一个元素地址:0xc42001a090,容量:2
- fmt.Printf("b的地址:%p, 第一个元素地址:%p,容量:%v
- ", &b, &b[0], cap(b))
- //b的地址:0xc42000a080, 第一个元素地址:0xc42001a090,容量:2
- fmt.Printf("c的地址:%p, 第一个元素地址:%p,容量:%v
- ", &c, &c[0], cap(c))
- //c的地址:0xc42000a0a0, 第一个元素地址:0xc42001a0a0,容量:4
- }
从上面代码的打印结果中可以看出:a 是一个底层数组有一个元素,容量为2的slice;append 1个元素后,没有超出容量,产生了一个新的slice b,a 和 b 底层数组首元素相同地址,说明a,b共用底层数组;append 2个元素,超出了容量,产生一个新的slice c,c的底层数组地址变了,容量也翻倍了。
那么得出结论,append操作的运行过程:
1、如果添加数据后没有超过原始容量,新的slice对象 和原始slice共用底层数组,len 数据会变化,cap数据不变;
2、添加数据后超过了容量那就会扩容,重新分配一个新的底层数组,然后拷贝底层数组数据过去,那么append后产生的新slice对象和原始的slice就没有任何关系了。
扩容机制
看汇编代码可以知道,扩容调用的是底层函数 runtime.growslice。
这个函数是这样定义的:func growslice(et *_type, old slice, cap int) slice {}
这个函数传入三个参数:slice的原始类型,原始slice,期望的最小容量;返回一个新的slice,新slice 至少是拥有期望的最小容量,元素从原slice copy过来。
扩容规则主要是下面这段代码:
- newcap := old.cap
- doublecap := newcap + newcap
- if cap > doublecap {
- newcap = cap
- } else {
- if old.len < 1024 {
- newcap = doublecap
- } else {
- for newcap < cap {
- newcap += newcap / 4
- }
- }
- }
扩容规则就是两点:
- 如果期望的最小容量大于原始的两倍容量时,那么新的容量就是等于期望的最小容量;
- 不满足第一种情况,那么判断原slice的底层数组元素长度是不是小于1024。小于1024,新容量是原来的两倍;大于等于1024 ,新容量是原来的1.25倍。
上面是扩容的基本规则判断,实际上扩容还要考虑到内存对齐情况:
- var lenmem, newlenmem, capmem uintptr
- const ptrSize = unsafe.Sizeof((*byte)(nil))
- switch et.size {
- case 1:
- lenmem = uintptr(old.len)
- newlenmem = uintptr(cap)
- capmem = roundupsize(uintptr(newcap))
- newcap = int(capmem)
- case ptrSize:
- lenmem = uintptr(old.len) * ptrSize
- newlenmem = uintptr(cap) * ptrSize
- capmem = roundupsize(uintptr(newcap) * ptrSize)
- newcap = int(capmem / ptrSize)
- default:
- lenmem = uintptr(old.len) * et.size
- newlenmem = uintptr(cap) * et.size
- capmem = roundupsize(uintptr(newcap) * et.size)
- newcap = int(capmem / et.size)
- }
内存对齐之后,扩容的倍数就会 >= 2 或则 1.25 了。为什么要内存对齐?
- 1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
五、函数调用中实参和形参的相互影响
1、slice值传递,在调用函数中直接操作底层数组
来看下面一段代码:
- package main
- import (
- "fmt"
- )
-
- func OpSlice(b []int32) {
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(b), cap(b), b)
- //len: 5, cap: 5, data:[1 2 3 4 5]
- fmt.Printf("b第一个元素地址:%p
- ", &b[0])
- //b第一个元素地址:0xc420016120
-
- b[0] = 100
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(b), cap(b), b)
- //len: 5, cap: 5, data:[100 2 3 4 5]
- fmt.Printf("b第一个元素地址:%p
- ", &b[0])
- //b第一个元素地址:0xc420016120
- }
-
- func main() {
- a := []int32{1, 2, 3, 4, 5}
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(a), cap(a), a)
- //len: 5, cap: 5, data:[1 2 3 4 5]
- fmt.Printf("a第一个元素地址:%p
- ", &a[0])
- //a第一个元素地址:0xc420016120
- OpSlice(a)
-
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(a), cap(a), a)
- //len: 5, cap: 5, data:[100 2 3 4 5]
- fmt.Printf("a第一个元素地址:%p
- ", &a[0])
- //a第一个元素地址:0xc420016120
- }
从这段代码的打印中可以看到:
main函数中的slice a 是实参,值传递给调用函数时,要临时拷贝一份给b,所以a,b 的地址是不一样的,slice b 结构体中的三个元素都是a中的拷贝,但是元素array是指针,指针的拷贝还是指针,他们指向同一块底层数组,所以a,b底层数组的第一个元素地址是一样的。a,b共用同一块底层数组,在调用函数中,直接改变b的第一个元素内容,函数返回后a的第一个元素也变了,相当于改变了实参。
2、slice 指针传递
slice 指针传递就没什么说的了,在被调用函数中相当于操作的是实参中同一个slice,所有修改都会反映到实参。
3、slice 切片传递
不扩容的情况,来看下面一段代码:
- package main
- import (
- "fmt"
- )
- func OpSlice(b []int32) {
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(b), cap(b), b)
- //len: 3, cap: 9, data:[1 2 3]
- fmt.Printf("b第一个元素地址:%p
- ", &b[0])
- //b第一个元素地址:0xc42007a064
-
- b = append(b, 100)
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(b), cap(b), b)
- //len: 4, cap: 9, data:[1 2 3 100]
- fmt.Printf("b第一个元素地址:%p
- ", &b[0])
- //b第一个元素地址:0xc42007a064
-
- }
-
- func main() {
- a := []int32{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
- fmt.Printf("a第2个元素地址:%p
- ", &a[1])
- //a第2个元素地址:0xc42007a064
-
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(a), cap(a), a)
- //len: 10, cap: 10, data:[0 1 2 3 4 5 6 7 8 9]
- fmt.Printf("a第一个元素地址:%p
- ", &a[0])
- //a第一个元素地址:0xc42007a060
- OpSlice(a[1:4])
-
- fmt.Printf("len: %d, cap: %d, data:%+v
- ", len(a), cap(a), a)
- //len: 10, cap: 10, data:[0 1 2 3 100 5 6 7 8 9]
- fmt.Printf("a第一个元素地址:%p
- ", &a[0])
- //a第一个元素地址:0xc42007a060
-
- }
前面已经讲过,切片和原slice是共用底层数组的。不扩容情况下,对切片产生的新的slice append 操作,新增加的元素会添加到底层数组尾部,会覆盖原有的值,反映到原slice中去;
总结
无论是slice的什么操作:拷贝,append,reSlice 等等都会产生新的slice,但是他们是共用底层数组的,不扩容情况,他们增删改元素都会影响到原来的slice底层数组;扩容情况下,产生的是一个“真正的”新的slice对象,和原来的完全独立开了,底层数组完全不会影响。
参考资料
- 深度解密Go语言之Slice.
- Go语言学习笔记.

