
- 1鸿蒙系列--组件介绍之其他基础组件(下)_鸿蒙scrollbar组件讲解
- 2新版 Microsoft Edge浏览器 使用Alt+Tab 键 切换 窗口显示多个Edge浏览器页面_edge alt+tab
- 3IOS面试题object-c 146-150
- 4Error while executing: am start -n错误解决方案_error while executing: am start -n "com.example.ls
- 5【HarmonyOS】1、HarmonyOS应用开发基础详解(持续更新)
- 6(10-2)大模型优化算法和技术:模型并行和数据并行_大模型并行计算什么意思
- 7java project clean_如何在Java maven项目的命令提示符中执行'project> clean'
- 8使用Jan下载AI模型失败_download failedmodelundefined downloadfailed:conne
- 9python各种空变量问题_python中检测多个变量中哪一个或多个变量为空
- 10Android-dp、sp等像素单位以及48dp调和原则_48dp dp单位
史上最全因果推断合集-2(阿里大文娱智能营销增益模型)_广告与因果推断
赞
踩
1.智能营销面临的挑战
智能化的营销手段越来越普及,商家可以通过多种渠道触达消费者,比如,在手淘上商家可以圈定他想要的目标人群,进行广告推送,为店铺拉新,也可以通过短信或旺旺这些渠道定向发放优惠券。无论是红包还是广告,我们都称为营销的干预手段,其背后都是有成本的。营销的目标就是在成本有限的情况下最大化营销的总产出,这里面最关键的一点是我们能否准确找到真正能被营销打动的用户,我们称他们为营销敏感人群,可以通过下面的图进行简单的解释:
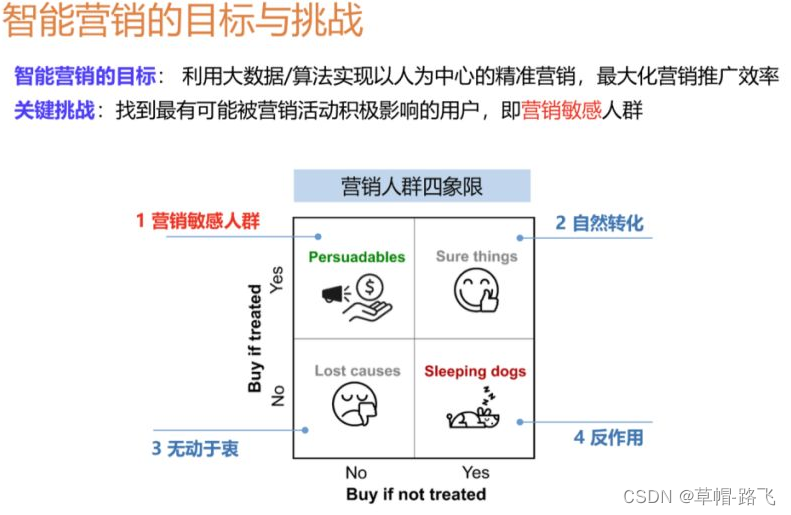
我们对人群做四象限的划分,横纵坐标分别是用户在有干预和无干预情况下的购买状况。如上图,左上角人群的购买状况在干预后发生了正向变化,如果我们不对这类人群进行干预,那他有可能是不购买的,但是干预之后的购买概率有极大提升,所以这类人群是我们真正想要触达的用户,即营销敏感人群。而其他人群比如第2类和第3类,在干预前后的购买状况没有变化,所以预算花费可能是浪费。右下角是一类比较特殊的人群,虽然其在干预前后的状态有跳变,但这种跳变不是我们希望看到的,因为确实有一些人群对营销是反感的,所以对这类人群我们应该极力避免触达。Uplift Model正是为了识别我们想要的营销敏感人群。
2.Uplift Model的价值
以广告投放为例,对于两个用户群,我们知道他们对广告投放的转化率分别是0.8%和2%,假如只有一次广告曝光的机会,应该向哪类用户投放广告?

按照以往的经验和直觉,可能会向第二类用户群投放广告,因为其转换率是最高的,但这个结论是对的吗?经过进一步分析,除了广告曝光转化率之外,我们还能知道这两类用户群体在没有广告触达情况下的自然转化率,从而推算出广告所带来的增量。比如第一类用户的广告转化率虽然低,但在没有广告触达情况下的转化率更低,即广告所带来的增量反而是比第二个用户更高的,而我们要最大化总体的转化率其实等价于最大化广告的增量,按照这个逻辑,我们应该向第一个用户投放广告。也就是说Response Model很有可能会误导我们做出错误的决策,Uplift Model和Response Model之所以有差异,主要在于两个模型的预测目标不一样。
❶ Response Model的目标是估计用户看过广告之后转化的概率,这本身是一个相关性,但这个相关性会导致我们没有办法区分出自然转化人群;
❷ Uplift Model是估计用户因为广告而购买的概率,这是一个因果推断的问题,帮助我们锁定对营销敏感的人群。所以Uplift Model是整个智能营销中非常关键的技术,预知每个用户的营销敏感程度,从而帮助我们制定营销策略,促成整个营销的效用最大化。
Uplift Model建模与评估方法
1. 什么是Uplift Model
Uplift Model是一个增量模型,目的是预测某种干预对于个体状态或行为的因果效应。在数学上可以表达为两个条件概率的差值形式,如下图所示:

Y代表的结果 ( 比如用户的点击,转化等 ),X是用户维度的特征,T代表的是营销的变量 ( 1代表有干预,0代表无干预 ),因此这个概率差值表示的是用户在有干预和没有干预情况下的变化,这个模型建模的难点在于我们获取到的训练数据是不完整的,对于个体来说,我们不可能同时观测到在有干预和没有干预两种情况下的表现,也就是因果推断中经常提到的反事实的问题。我们应当如何去建模呢?可以换一种思路,从人群的角度来对平均因果效应做统计,假设我们有两群同质用户,均来自一线城市/年龄段为25-35/女性,我们可以对其中一组用户进行广告投放,另外一组不进行任何干预,之后统计这两群人在转化率上的差值,这个差值可以被近似认为是具备同样特征的人可能的平均因果效应。所以Uplift Model本质是从训练样本中学习条件的平均因果效应,同时因为模型是具有一定的泛化能力,可以对没有见过的样本也进行预测。
但这里需要强调的是,Uplift建模对样本的要求是比较高的,需要服从CIA ( Conditional Independence Assumption ) 条件独立假设,要求X与T是相互独立的。什么样的样本有这样的特征,又如何获取呢?最简单的方式就是随机化实验A/B Test,因为通过A/B Test拆分流量得到的这两组样本在特征的分布上面是一致的,也就是X和T是相互独立的。因此随机化实验是Uplift Model建模过程中非常重要的基础设施,可以为Uplift Model提供无偏的样本。
2. Uplift Model建模算法

最简单的Uplift建模方法是基于Two Model的差分响应模型,它的形式和前面介绍的Uplift Model的定义非常相似,包含了两个响应模型,其中一个模型G用来估计用户在有干预情况下的响应,另外一个模型G'是用来学习用户在没有干预情况下的响应,之后将两个模型的输出做差,就得到我们想要的uplift。这种建模方法的优点是比较简单容易理解,同时它可以套用我们常见的机器学习模型,如LR,GBDT,NN等,所以该模型的落地成本是比较低的,但是该模型最大的缺点是精度有限,这一方面是因为我们独立的构建了两个模型,这两个模型在打分上面的误差容易产生累积效应,第二是我们建模的目标其实是response而不是uplift,因此对uplift的识别能力比较有限。
进一步地,还有一个基于One Model的差分响应模型,它和上一个模型最大差别点在于,它在模型层面做了打通,同时底层的样本也是共享的,之所以能实现这种模型层面的打通,是因为我们在样本的维度上做了一个扩展,除了user feature之外,还引入了与treatment相关的变量T ( T如果是0,1的取值可以建模single treatment,T也可以扩展为0到N,建模multiple treatment,比如不同红包的面额,或者不同广告的素材 ),One Model版本和Two Model版本相比最大的优点是训练样本的共享可以使模型学习的更加充分,同时通过模型的学习也可以有效的避免双模型打分误差累积的问题,另外一个优点是从模型的层面可以支持multiple treatment的建模,具有比较强的实用性。同时和Two Model版本类似,它的缺点依然是其在本质上还是在对response建模,因此对uplift的建模还是比较间接,有一定提升的空间。
所以后续也有相关研究提出了第三种建模方法,通过对现有的模型内部进行深层次的改造来直接刻画uplift,其中研究较多的是基于树模型的uplift建模,下面主要介绍它的思想,在传统的决策树构建中,最重要的环节是分裂特征的选择,我们常用的指标是信息增益或者信息增益比,其背后的含义还是希望通过特征分裂之后下游节点的正负样本的分布能够更加的悬殊,也就代表类的纯度变得更高。类似的,这种思想也可以引入到Uplift Model的建模过程中,虽然我们并没有用户个体的uplift直接的label,但是我们可以通过treatment组和control组转化率的差异来刻画这个uplift,以图中左下角的图为例,我们有T和C两组样本,绿色的样本代表正样本,红色的代表负样本,可以看到在分裂之前T和C两组正负样本的比例比较接近,但是经过一轮特征分裂之后,T和C组内正负样本的比例发生了较大的变化,左子树中T组全是正样本,C组全是负样本,右子树正好相反,C组的正样本居多,意味着左子树的uplift比右子树的uplift更高,即该特征能够很好的把uplift更高和更低的两群人做一个区分。如何从数学上度量这种概率分布的差异的方式呢?一些文章提出了可行的方法,比如基于KL散度,欧式距离,卡方距离的等等。这种模型的优点是可以直接对uplift进行建模,因此它的精度理论上是更高的,但是在应用层面我们需要做大量的改造和优化,除了前面介绍的分裂规则之外,我们还需要改造它的loss函数,后续的剪枝等一系列的过程,所以它的实现成本是比较高的。
3. Uplift Model建模评估
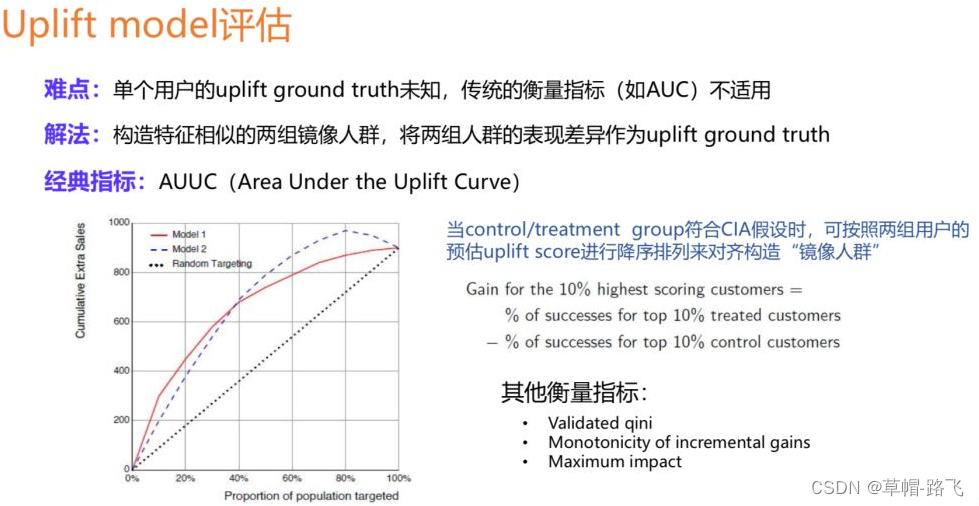
有了以上三种常见uplift的建模方法,我们需要对uplift模型进行评估,因为uplift评估最大的难点在于我们并没有单个用户uplift的ground truth,因此传统的评估指标像AUC是无法直接使用的,解决的一个思路是通过构造镜像人群的方式来间接拿到uplift的ground truth,比如说经典的AUUC的指标就是这样去计算的,假设现在有两个满足CIA条件假设的样本组,我们可以对两群人分别预估他们的uplift score,之后将人群按照uplift score进行降序排列,通过score分数这一桥梁,可以把两组人群进行镜像人群的对齐,之后分别截取分数最高的比如10%的用户出来,计算这一部分人转化率的差异,这个差异就可以近似地认为是分数最高的这群人真实的uplift,类似地,我们可以计算前20%,40%一直到100%的点上面的值,连线就能得到uplift curve。理论上如果模型对uplift的识别比较准确,我们预测uplift比较高的区间段,真实的uplift也较高,uplift curve就会呈现上凸的形式,我们也可以计算曲线下的面积度量不同模型的表现差异。当然除了这种方法之外,还有一些其他的指标如Validated qini等,在此不展开介绍。
 下面以淘票票实际场景为例,来说明uplift model如何在实际场景中进行应用。该项目的目标是希望对进入到首页的用户个性化地发送红包,实现在预算和ROI的双重约束下提升平台总体购票转化率。我们的权益就是首页的红包,红包的使用规则、红包类型、预算和交互样式由产品运营设计,算法的作用是实现人和权益的精准匹配,我们需要确定应该给哪些用户发放以及发放哪种类型的权益。
下面以淘票票实际场景为例,来说明uplift model如何在实际场景中进行应用。该项目的目标是希望对进入到首页的用户个性化地发送红包,实现在预算和ROI的双重约束下提升平台总体购票转化率。我们的权益就是首页的红包,红包的使用规则、红包类型、预算和交互样式由产品运营设计,算法的作用是实现人和权益的精准匹配,我们需要确定应该给哪些用户发放以及发放哪种类型的权益。

我们以平台通用券为例来说明问题是如何抽象和形式化的。在该场景下,每个用户最多只能发放一个红包,同时面额有固定几个分档,因此问题就精细化到如何对用户进行个性化的面额发放上,这可以通过经典的背包问题来抽象,如图所示,第一个公式是我们的目标,最大化的是红包撬动效率,下面的约束条件一个是ROI约束,一个是预算约束。目标函数公式中标红的部分是第i个用户在第k个红包下转化的uplift,Xik是是否对用户i发放第k个红包,因此我们最终要决策的变量就是X矩阵。
该问题的求解中有两个关键点,一个是用户红包敏感度的建模,第二是在敏感度已知的情况下怎么进行全局效用最大化的求解。下面重点介绍uplift model模块。Uplift model的目标是预测每个用户在不同的红包金额下的转化率,从而构建出千人千面的敏感度曲线。
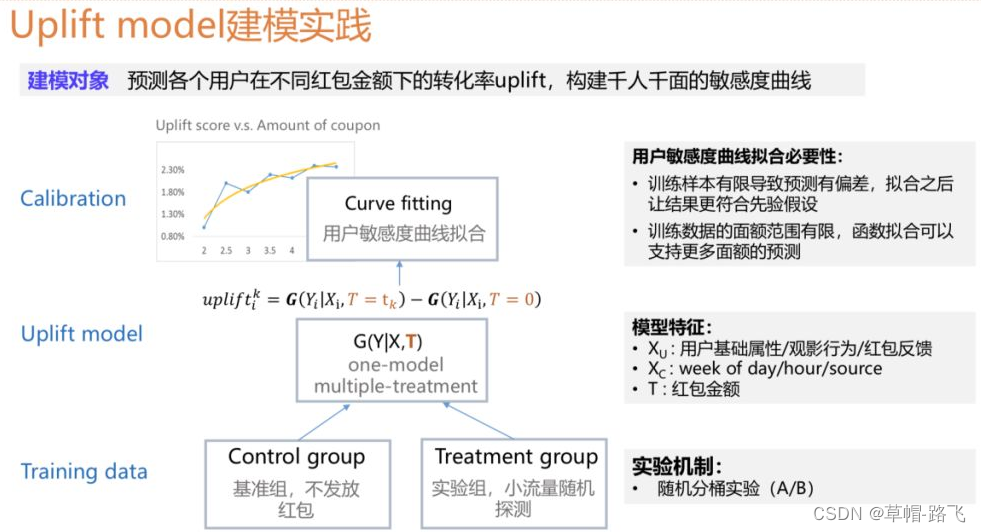
我们将建模的任务拆分成三个步骤:
❶ 收集训练样本
训练样本的收集和我们的实验是强相关的,我们采用的是随机化的分桶实验,它有两个好处,一是可以严谨公平地进行效果的评估,二是可以为uplift model的建模提供无偏的样本。建模中control组我们取的是随机化实验中的基准组,这部分用户是不进行红包发放的,而treatment组选用的是随机化实验中专为uplift model建模预留的一小部分随机探测的流量,之所以没有用有算法干预下的样本是因为用户的发放的面额与用户的特征是强相关的,并不满足CIA条件,因此这一部分样本虽然量较大,但是不能用于训练。
❷ 模型的构建和训练
收集到样本之后可以进行建模,考虑到业务迭代的周期,我们使用的是前面介绍的One Model的差分响应模型,特征层面,除了user维度的基础属性,还有历史的观影行为,以及历史红包的反馈,同时也会引入线上实时的环境特征,最重要的是跟营销相关的特征T,目前T代表的是红包的金额。
❸ 面向业务层的模型校准和优化
理论上到模型训练完成,就可以直接把模型放到线上去应用了,但是在离线调研时,我们发现一个问题,我们绘制的用户敏感度曲线和我们的预期不太一样,并不是严格的平滑递增的走势。我们分析有两个可能的原因:
一是与我们整体的样本规模比较有限有关,因为这种无偏样本目前大概只有几百万的量级;
二是由于用户行为的稀疏性,在这种场景下我们比较难收集到用户在不同面额下的历史数据,因此也会加剧这种不平滑性。
针对该问题,我们做了校准处理,把原始曲线做了一个函数的拟合,一方面可以让结果更加符合我们先验的假设,一方面经过这种函数化之后可以在后续支持更多面额的预测,但这种做法是否是最优的还值得进一步探讨。
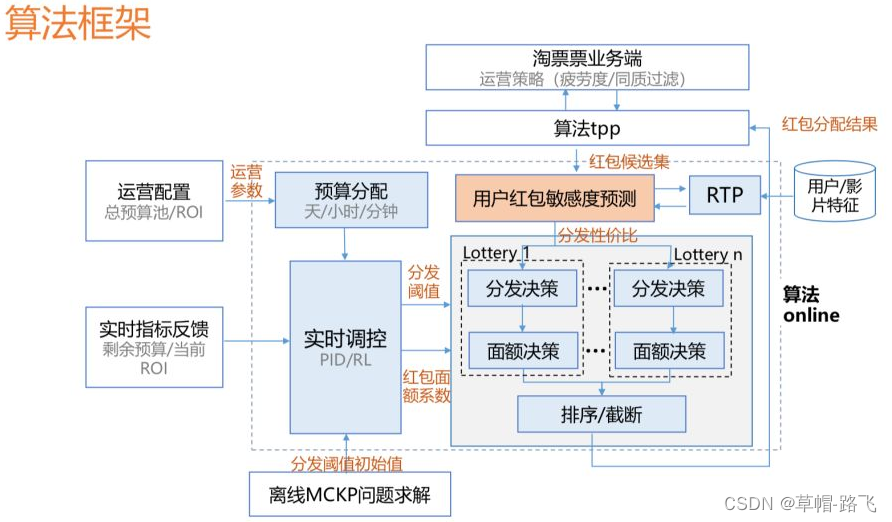
模型在线上应用的框架图,如上图所示,黄色区域是基于uplift model的实时预测的模块,当一条用户的请求过来的时候,我们会实时去数据库中取用户的特征以及影片的特征,同时结合当前的环境特征预测用户在当前状态下真实的敏感度,基于这个敏感度可以进行后续分发的面额决策等。
▌技术思考与后续规划

之后智能营销的发展态势是营销手段会越来越复杂,玩法也会越来越多,比如之前我们发放的更多是平台的通用券,后面也会发一些和影片相关的影片券或者影院券,这意味treatment的维度是在不断增长的,除了红包的金额之外还需要考虑不同的红包类型,这会给算法带来两个方面的挑战,一是我们需要对问题的建模形式做一个升级,除了之前单一维度的建模之外,我们可能还要考虑多维度的建模,同时维度的剧增会对样本的量级要求越来越高,样本的稀疏性问题会更加严重,针对这个问题我们有两个可能的解法:
❶ 可以采用多任务学习的方式,联合其他场景一起建模缓解单场景样本的压力,同时也可以通过人为构造无偏样本的方式增加整体的样本量。当然除了技术侧,整个营销上面还有非常多很有意思的研究方向,比如之前更多考虑的是单个营销场景,但其实多个场景下怎么去建模和刻画他们之间的相互影响也是非常有意思的课题;
❷ 我们之前uplift model建模更多考虑的是单次或者短期用户行为的增益,但实际上的营销往往是常态化或持续化的,用户的心智可能会不断发生变化,如何去建模长期的uplift也值得进一步去探讨。

