
热门标签
热门文章
- 1Python学习笔记——removebg库之抠图
- 2Air test 下载安装教程_airtest下载
- 3vue axios数据请求的两种请求头,一种是JSON序列化对象,一种是formData,这两种格式的处理方式_axios application/json
- 4matlab 工具函数 —— normalize(归一化数据)_matlab normalize函数
- 5java中几种JSON库的解析速度对比_不同机器json解析效率差异巨大 java
- 6鸿蒙应用runtime,鸿蒙OS初探
- 7Oauth2.0 自定义响应值以及异常处理_oauth2自定义异常
- 8Jaeger docker部署实操_jaeger docker 部署
- 9[力扣每日一题]1004. 最大连续1的个数 III_一个数组和一个k,数组a{1,1,1,0,0,1,1,0},k=2,能让最多k个0变为1,问连续1最
- 10鸿蒙2.0内核安卓,鸿蒙2.0终于来了,可否与安卓一战?
当前位置: article > 正文
RoBERTa tokenizer出现奇奇怪怪的“G”_\u0120
作者:菜鸟追梦旅行 | 2024-03-16 12:35:44
赞
踩
\u0120
在用Transformer RoBERTa的时候,使用RoBERTaTokenizer,分词之后每个token前面会出现奇奇怪怪的“G”(上面还有个点号,其实试unicode 字符\u0120)
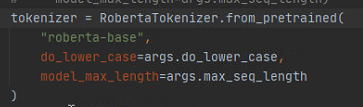
原因是RoBERTa和GPT-2等一样,词表用的是BPE(original BPE paper by Sennrich et al),它不同于我们用的普通BERT的tokenizer,即WordPiece vocabulary,把未知的word不停按照subword分下去(比方说“#T”,"##ok",按照分的级数确定前面“#”的个数)
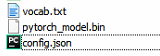
其实在下载RoBERTa的时候就会发现,它和普通BERT相比,下载文件有点不一样
普通BERT:
RoBERTa:
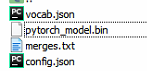
RoBERTa的vocab里面打开会发现所有的word前面都会有个"G",同时它还多了个merge.txt

还有为什么会出现“G”?
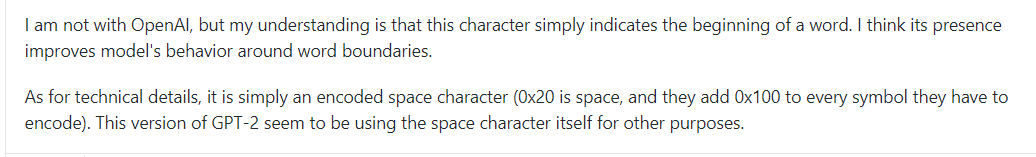
有关tokenization:
机器如何认识文本 ?NLP中的Tokenization方法总结
参考资料
github-为什么会出现“G”
github-为什么要有merge.txt
Difficulty in understanding the tokenizer used in Roberta model
Tokenization issue with RoBERTa and DistilRoBERTa
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

