
- 1安卓手机安卓Mysql,Termux安装MariaDB/MySQL数据库_最新termux安装 mariadb
- 2史诗手册!微信小程序新手自学入门宝典!你想要的都在这里
- 3mysql 将数据库中的所有表结构和数据 导入到另一个库(亲测有效)_数据库表结构怎么导
- 4HarmonyOS与Android:全面对比解析_android 与 harmonyos 开发区别简述
- 5mysql数据库代理--mycat_mysql 代理
- 6干洗店管理系统洗鞋店预约上门小程序洗护流程;
- 7minecraft服务器搭建教程_我的世界游戏服务器搭建详细教程
- 8计算机网络实验---Wireshark 实验_wireshark捕获fcs
- 9物联网云原生云边协同
- 10python中subprocess模块subprocess.run,subprocess.getoutput,subprocess.Popen、subprocess.call的使用
一文了解GPU并行计算CUDA
赞
踩
了解GPU并行计算CUDA
一、CUDA和GPU简介
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
GPU(Graphic Processing Unit):图形处理器,显卡的处理核心。电脑显示器上显示的图像,在显示在显示器上之前,要经过一些列处理,这个过程有个专有的名词叫“渲染"。以前的计算机上没有GPU,渲染就是CPU负责的。
渲染是个什么操作呢,其实就是做了一系列图形的计算,但这些计算往往非常耗时,占用了CPU的一大部分时间。而CPU还要处理计算机器许多其他任务。因此就专门针对图形处理的这些操作设计了一种处理器,也就是GPU。这样CPU就可以从繁重的图形计算中解脱出来。
NVIDIA公司在1999年发布Geforce 256图形处理芯片时首先提出GPU的概念,随后大量复杂的应用需求促使整个产业蓬勃发展至今。
最早的GPU是专门为了渲染设计的,那么他也就只能做渲染的那些事情。渲染这个过程具体来说就是几何点、位置和颜色的计算,这些计算在数学上都是用四维向量和变换矩阵的乘法,因此GPU也就被设计为专门适合做类似运算的专用处理器了。但随着GPU的发展,GPU的功能也越来越多,比如现在很多GPU还支持了硬件编解码。
全球GPU巨头:NVIDIA(英伟达)AMD(超威半导体)。

二、GPU工作原理与结构
GPU采用流式并行计算模式,可对每个数据行独立的并行计算。
GPU与CPU区别:
- CPU基于低延时设计,由运算器(ALU,Arithmetic and Logic Unit 算术逻辑单元)和控制器(CU,Control Unit),以及若干个寄存器和高速缓冲存储器组成,功能模块较多,擅长逻辑控制,串行运算。
- GPU基于大吞吐量设计,拥有更多的ALU用于数据处理,适合对密集数据进行并行处理,擅长大规模并发计算,因此GPU也被应用于AI训练等需要大规模并发计算场景。

2.1、基础GPU架构
GPU为图形图像专门设计,在矩阵运算,数值计算方面具有独特优势,特别是浮点和并行计算上能优于CPU的数十数百倍的性能。

GPU的优势在于快,而不是效果好。比如用美团软件给一张图要加上模糊效果,CPU处理的时候从左到右从上到下进行处理。可以考虑开多核,但是核数毕竟有限制,比如4核、8核 分块处理。
使用GPU进行处理,因为分块之前没有相互的关联关系,可以通过GPU并行处理,就不单只是4、 8分块了,可以切换更多的块,比如16、64等。
2.2、GPU编程模型
软件层面上不管什么计算设备,大部分异构计算都会分成主机代码和设备代码。整体思考过程就是应用分析、内存资源分配、线程资源分配再到具体核函数的实现。
CUDA中线程也可以分成三个层次:线程、线程块和线程网络。
- 线程是CUDA中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block)是若干线程的分组,Block内一个块至多512个线程、或1024个线程(根据不同的GPU规格),线程块可以是一维、二维或者三维的;
- 线程网络(Grid)是若干线程块的网格,Grid是一维和二维的。
线程用ID索引,线程块内用局部ID标记threadID,配合blockDim和blockID可以计算出全局ID,用于SIMT(Single Instruction Multiple Thread单指令多线程)分配任务。
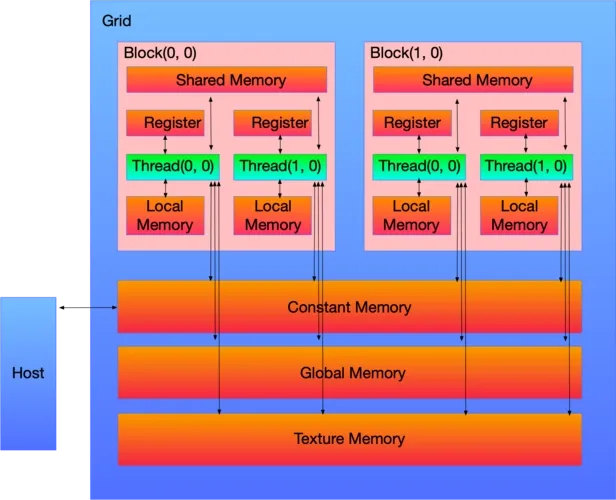
首先需要关注的是具体线程数量的划分,在并行计算部分里也提到数据划分和指令划分的概念,GPU有很多线程,在CUDA里被称为thread,同时我们会把一组thread归为一个block,而block又会被组织成一个grid。
假如我们要对一个长度为1024的数组做reduce_sum(减少和求和),恰好我们正好有1024个thread,此时直接一一对应就行,但如果是一张很大的图片呢?
如果有很多核函数要处理不同的数据呢?GPU上有很多thread,但要完全和实际应用中需要处理的数据大小完全匹配是不可能的,事实上在满足规定的情况下我们可以给一个block内部分配很多thread,对于到硬件上也真的是相应数量的thread会自动归为一组直接在一个SM上实行吗?答案当然不是,此时我们就要关注硬件,引入了wrap概念,GPU上有很多计算核心也就是Streaming Multiprocessor (SM),在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA里叫warp,直接可以理解这组硬件线程会在这个SM上同时执行一部分指令,这一组的数量一般为32或者64个线程。一个block会被绑定到一个SM上,即使这个block内部可能有1024个线程,但这些线程组会被相应的调度器来进行调度,在逻辑层面上我们可以认为1024个线程同时执行,但实际上在硬件上是一组线程同时执行,这一点其实就和操作系统的线程调度一样。 意思就是假如一个SM同时能执行64个线程,但一个block有1024个线程,那这1024个线程是分1024/64=16次执行。

解释完了执行层面,再来分析一下内存层面上的对应,一个block不光要绑定在一个SM上,同时一个block内的thread是共享一块share memory(一般就是SM的一级缓存,越靠近SM的内存就越快)。GPU和CPU也一样有着多级cache还有寄存器的架构,把全局内存的数据加载到共享内存上再去处理可以有效的加速。所以结合具体的硬件具体的参数(SM和寄存器数量、缓存大小等)做出合适的划分,确保最大化的利用各种资源(计算、内存、带宽)是做异构计算的核心。
2.3、软件和硬件的对应关系
GPU在管理线程(thread)的时候是以block(线程块)为单元调度到SM上执行。每个block中以warp(一般32个线程或64线程)作为一次执行的单位(真正的同时执行)。
- 一个 GPU 包含多个 Streaming Multiprocessor ,而每个 Streaming Multiprocessor 又包含多个 core 。Streaming Multiprocessors 支持并发执行多达几百的 thread 。
- 一个 thread block 只能调度到一个 Streaming Multiprocessor 上运行,直到 thread block 运行完毕。一个Streaming Multiprocessor 可以同时运行多个thread block (因为有多个core)。
通俗点讲:stream multiprocessor(SM)是一块硬件,包含了固定数量的运算单元,寄存器和缓存。
写cuda kernel的时候,跟SM对应的概念是block,每一个block会被调度到某个SM执行,一个SM可以执行多个block。 cuda程序就是很多的blocks(一般来说越多越好)均匀的喂给这80个SM来调度执行。具体每个block喂给哪个SM没法控制。
不同的GPU规格参数也不一样,比如 Fermi 架构(2010年的比较老):
- 每一个SM上最多同时执行8个block。(不管block大小)
- 每一个SM上最多同时执行48个warp。
- 每一个SM上最多同时执行48*32=1,536个线程。
当warp访问内存的时候,processor(处理器)会做context switch(上下文切换),让其他warp使用硬件资源。因为是硬件来做,所以速度非常快。
三、GPU应用领域
GPU适用于深度学习训练和推理,图像识别、语音识别等;计算金融学、地震分析、分子建模、基因组学、计算流体动力学等;高清视频转码、安防视频监控、大型视频会议等;三维设计与渲染、影音动画制作、工程建模与仿真(CAD/CAE)、医学成像、游戏测试等等。
GPU常见的应用领域如下所示:
- 游戏:GeForce RTX/GTX系列GPU(PCs)、GeForce NOW(云游戏)、SHIELD(游戏主机)。
- 专业可视化:Quadro/RTX GPU(企业工作站) 。
- 数据中心:基于GPU的计算平台和系统,包括DGX(AI服务器)、HGX(超算)、EGX(边缘计算)、AGX(自动设备) 。
- 汽车:NVIDIA DRIVE计算平台,包括AGX Xavier(SoC芯片)、DRIVE AV(自动驾驶)、DRIVE IX(驾驶舱软件)、Constellation(仿真软件) 。
- 消费电子:智能手机市场占据了全球GPU市场份额的主导地位,此外,智能音箱、智能手环/手表、VR/AR眼镜等移动消费电子都是GPU潜在的市场。比如拍照、导航地图的合成、UI图标、图像框、照片的后处理等都需要GPU来完成。
更详细的应用场景参考:华秋元器件:一文看完GPU八大应用场景,抢食千亿美元市场
GPU算力 TOPs: OPS是Tera Operations Per Second的缩写,1TOPS代表处理器每秒钟可进行一万亿次操作。
四、GPU+CPU异构计算
异构计算从常见的搭配有CPU+GPU、CPU+FPGA、CPU+DSP等。
CPU的核心少但每一个核心的控制和计算能力都不弱,因此常作为主机。而GPU的计算核心很多, 所以当遇到大数据量且逻辑简单的任务,CPU就会交给GPU来进行计算,同时CPU的核心虽少但也是有多个线程的,多线程可以调度并同时控制多张GPU同时完成多个任务,这本身也是一种并行思想,并且GPU也可以在接收到任务后让CPU的线程先去处理别的事情完成异步控制来进一步提高效率(这本质上也是一种时域上的并行)。
之所以出现GPU+CPU异构计算,因为CPU和GPU各自有优缺点:
- CPU 适用于一系列广泛的工作负载,特别是那些对于延迟和单位内核性能要求较高的工作负载。作为强大的执行引擎, CPU 将它数量相对较少的内核集中用于处理单个任务,并快速将其完成。这使它尤其适合用于处理从串行计算到数据库 运行等类型的工作。
- GPU 最初是作为专门用于加速特定 3D 渲染任务的 ASIC 开发而成的。随着时间的推移,这些功能固定的引擎变得更加可编程化、更加灵活。尽管图形处理和当下视觉效果越来越真实的顶级游戏仍是 GPU 的主要功能,但同时,它也已经演 化为用途更普遍的并行处理器,能够处理越来越多的应用程序。
五、MPI与CUDA的区别
MPI全称Massage Passing Interface是支持c、c++等语言的并行编程的拓展库,主要是负责多进程之间的通信。用于编写并行计算程序。我们通过MPI并行库来编写并行化的程序。
由于“天河二号”等高性能计算机在运行的时候是同一个程序会运行在很多节点上,每个节点上都是一个进程。这些进程也就是这些节点之间需要相互通信来达到程序的并行。因此想要利用“天河二号”的计算能力来帮助自己运行程序,就需要将自己的程序改为MPI的并行程序,至于超级计算机分配哪些任务给哪些节点是我们不需要知道的,以及节点之间如何通信,利用中心架构进行通信还是非中心架构进行通信也是我们不需要知道的,我们要了解的就是如何将自己在个人计算机上运行的普通程序改成可以在超级计算机上运行的MPI程序即可。
MPI框架下,同一个程序在多个节点中以进程形式存在,这些进程组成一个group,每个进程都有唯一的进程号,MPI的点对点通信有两种,一种是消息发送,一种是消息的接收,最简单的为MPI_Send()和MPI_Recv()。
相对应的,还有另外三种通信方式缓存通信、同步通信、就绪通信。
(1)缓存通信:用户提供通信缓冲区,避免了系统内存拷贝,提高了通信效率,但是缓冲区需用户自己管理。
(2)同步通信:发送进程只有当接受进程开始接收(不需要全部接收)的时候才返回。
(3)就绪通信:发送进程的发送操作只有当接受进程已经开启了接收操作的时候才能够成功调用,否则发送操作将会出错。


