
- 12022年安徽省安全员C证考试模拟100题及答案_以下( )的模板支撑,应组织专家论证,必要时编制应急预案。
- 2解决更新Xcode 15.2后,下载 iOS_17 Simulator失败_ios_17.2_simulator_runtime.dmg
- 3《安富莱嵌入式周报》第258期:2022.03.21--2022.03.27_dsp教程 安富莱
- 4【算法模板】图论单源|多源最短路
- 5Eclipse 获取Git远程分支 Eclipse 拉取Git远程分支_仓库创建的git分支eclipse无法看到
- 6python目标识别算法_深度学习目标检测系列:一文弄懂YOLO算法|附Python源码
- 7latex 1图加标题_LaTeX是什么?能做什么?在中学数学中的应用
- 8rnn神经网络模型_循环神经网络——反对称RNN模型
- 9UE4.27_ParticleSystem(没写完的材料)
- 10DPU on PYNQ-Z2系列—1.1 硬件准备—在Vivado中集成DPU IP_vivado dpu集成
c++并行计算(基于cuda)_deviceprop.major == 9999
赞
踩
1. 检查NVIDIA显卡驱动程序,我这里装系统时就已经安装了,于是去官网下载更新了版本;
GeForce Game Ready 驱动程序 | 511.79 | Windows 10 64-bit, Windows 11 | NVIDIA下载 Chinese (Simplified) GeForce Game Ready 驱动程序 匹配 Windows 10 64-bit, Windows 11 操作系统. 发布日期 2022.2.14![]() https://www.nvidia.cn/Download/driverResults.aspx/187102/cn/
https://www.nvidia.cn/Download/driverResults.aspx/187102/cn/
2. 查看驱动程序对应的CUDA版本,如图所示

3.安装cuda11.6,官网下载:
CUDA Toolkit 11.6 Downloads | NVIDIA Developer![]() https://developer.nvidia.com/cuda-downloads4. 测试是否安装成功;
https://developer.nvidia.com/cuda-downloads4. 测试是否安装成功;
cmd下运行 nvcc -V
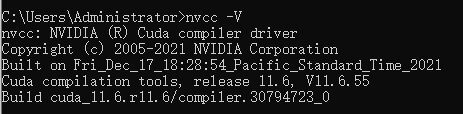
下载 cuda示例代码
https://github.com/nvidia/cuda-samples![]() https://github.com/nvidia/cuda-samples5. 安装cudnn,没有找到11.6对应版本,地址:
https://github.com/nvidia/cuda-samples5. 安装cudnn,没有找到11.6对应版本,地址:
https://developer.nvidia.com/rdp/cudnn-download![]() https://developer.nvidia.com/rdp/cudnn-download
https://developer.nvidia.com/rdp/cudnn-download
下载需要登录,但是注册失败,于是使用迅雷下载绕过登录,版本为8.2.1对应cuda11.X。

将cudnn解压并复制到cuda目录下同名文件夹
6. 打开VS2017,新建项目,选择

7. 自动生成一个.cu程序,实现数组相加功能。

CUDA程序执行过程:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
kernel核函数是在device上线程中并行执行的函数,用__global__符号声明,在调用时需要用<<<grid, block>>>来指定一个kernel函数要执行的线程数量,在CUDA中,每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
一个kernel核函数在device上执行时实际上启动了很多线程,一个kernel所启动的所有线程称为一个线程格(grid),同一个线程格上的线程共享相同的全局内存空间;一个线程格又分为很多线程块(block),一个线程块里面包含很多线程。
8.编写矩阵乘法运算程序:
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
-
- #include <stdio.h>
- #include <stdlib.h>
- #include <time.h>
-
- const int width = 1 << 3;
- const int height = 1 << 3;
-
- void getCudaInformation();
-
- // 矩阵相乘kernel函数,2-D,每个线程计算一个元素Cij
- __global__ void matMulKernel(float *A, float *B, float *C) {
- float Cvalue = 0.0;
- int row = threadIdx.y + blockIdx.y * blockDim.y;
- int col = threadIdx.x + blockIdx.x * blockDim.x;
- for (int i = 0; i < width; ++i) {
- Cvalue += A[row * width + i] * B[i * width + col];
- }
-
- //Cvalue = A[row * width + col] + B[row * width + col];
-
- C[row * width + col] = Cvalue;
- }
-
- cudaError_t mulWithCuda(float *A, float *B, float *C, unsigned int width, unsigned int height);
-
- int main()
- {
- //设备测试
- getCudaInformation();
-
- //数组运算
- float *A, *B, *C;
-
- //分配内存
- //int nBytes = width * height * sizeof(float);
-
- A = (float *)malloc(width * height * sizeof(float));
- B = (float *)malloc(width * height * sizeof(float));
- C = (float *)malloc(width * height * sizeof(float));
-
-
- // 初始化A矩阵所有元素为1.0,B矩阵所有元素为2.0
- for (int i = 0; i < width * height; ++i) {
- A[i] = 1.0;
- B[i] = 2.0;
- C[i] = 10.0;
- }
-
- //计时
- double startTime1 = clock();//1计时开始
- // Add vectors in parallel.
- cudaError_t cudaStatus = mulWithCuda(A, B, C, width, height);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
-
- //计时
- double endTime1 = clock();//1计时结束
-
- for (int i = 0; i < width * height; ++i)
- {
- printf("%f ", C[i]);
- if (((i + 1) / width != 0) && ((i + 1) % width == 0))
- printf("\n");
- }
-
- //运行时间
- printf("%.9f \n", (double)(endTime1 - startTime1) / CLOCKS_PER_SEC);
-
- // cudaDeviceReset must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaDeviceReset();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceReset failed!");
- return 1;
- }
-
- //释放内存
- free(A);
- free(B);
- free(C);
-
- return 0;
- }
-
- // 使用CUDA进行矩阵乘法
- cudaError_t mulWithCuda(float *A, float *B, float *C, unsigned int width, unsigned int height)
- {
- float *dev_a;
- float *dev_b;
- float *dev_c;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- int nBytes = width * height * sizeof(float);
- cudaStatus = cudaMalloc((void**)&dev_c, nBytes);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_a, nBytes);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_b, nBytes);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, A, nBytes, cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- cudaStatus = cudaMemcpy(dev_b, B, nBytes, cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- // 定义kernel的blocksize为(32, 32),那么grid大小为(32, 32)
- dim3 blockSize(32, 32);
- dim3 gridSize((width + blockSize.x - 1) / blockSize.x,
- (height + blockSize.y - 1) / blockSize.y);
-
- // Launch a kernel on the GPU with one thread for each element.
- matMulKernel << <gridSize, blockSize >> > (dev_a, dev_b, dev_c);
-
- // 同步device数据保证结果能正确访问
- //cudaDeviceSynchronize();
-
- // Check for any errors launching the kernel
- cudaStatus = cudaGetLastError();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
- goto Error;
- }
-
- // cudaDeviceSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaDeviceSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
-
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(C, dev_c, nBytes, cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
-
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
-
- return cudaStatus;
-
- }
-
-
- // 设备测试
- void getCudaInformation()
- {
- int deviceCount;
- cudaGetDeviceCount(&deviceCount);
- int dev;
- for (dev = 0; dev < deviceCount; dev++) {
- int driver_version(0), runtime_version(0);
- cudaDeviceProp deviceProp;
- cudaGetDeviceProperties(&deviceProp, dev);
- if (dev == 0)
- if (deviceProp.minor = 9999 && deviceProp.major == 9999)
- printf("\n");
- printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name);
- cudaDriverGetVersion(&driver_version);
- printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);
- cudaRuntimeGetVersion(&runtime_version);
- printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);
- printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
- printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem);
- printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);
- printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem);
- printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock);
- printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock);
- printf("Warp size: %d\n", deviceProp.warpSize);
- printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);
- printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);
- printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]);
- printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);
- printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);
- printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);
- printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);
- printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);
- printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);
- printf("--------------------------------------------------------------\n");
-
- }
-
- }

运行结果:

基于GPU实现了8*8的矩阵相乘。

