
- 1【视频教程】苹果推送证书生成及如何对接环信推送
- 2用Python做数据分析之数据统计_python统计分析
- 3让你的数据更好看——pyecharts图表的自动生成_自动生成echarts图表
- 4弹性布局_display:fix
- 5python实现进度条_python进度条设计函数代码
- 6【npm淘宝镜像源更新】教你完整的解决方案_npm淘宝源
- 7mac下生成ssh key_mac os 生成sha ket
- 8干货:如何让GPT写长文?(突破上下文长度最大限制)_gpt 上下文限制
- 9Azure学习笔记:Storage(3)_cloudstorageaccount
- 10python为什么适用于人工智能-python适合人工智能的理由和优势
Python+OpenCV实用案例应用教程:人脸检测和识别_opencv人脸检测属于计算机视觉中的那个应用案例
赞
踩
计算机视觉使很多任务成为现实,其中两项任务就是人脸检测
(在图像中定位人脸)和人脸识别(将人脸识别为特定的人)。
OpenCV实现了一些人脸检测和识别的算法。从安全到娱乐,这些技术
在现实环境中都有应用。
本章介绍OpenCV的一些人脸检测和识别功能,并定义特定类型的
可跟踪物体的数据文件。具体来说,将研究Haar级联分类器,通过分
析相邻图像区域之间的对比度,确定给定图像或子图像是否与已知类
型匹配。我们来考虑如何在层次结构中组合多个Haar级联分类器,以
便用一个分类器识别父区域(就我们的目标而言,是一张人脸),用
其他分类器识别子区域(比如眼睛)。
我们还介绍了“矩形”这个不起眼但却很重要的主体。通过绘
制、复制及调整矩形图像区域的大小,我们可以对正在跟踪的图像区
域执行简单的操作。
本章将介绍以下主题:
·理解Haar级联。
·找到OpenCV自带的预训练Haar级联,包括了一些人脸检测器。
·利用Haar级联检测静态图像和视频中的人脸。
·采集图像训练和测试人脸检测器。
·使用多种不同的人脸识别算法:Eigenface、Fisherface以及局部
二值模式直方图(Local Binary Pattern Histogram,LBPH)。
·将矩形区域从一幅图像复制到另一幅图像,即可包括也可不包
括掩模。
·使用深度摄像头基于深度区分人脸和背景。
·在交互式应用程序中交换两个人的脸。
本章结束时,我们将人脸跟踪和矩形操作集成到我们在前几章中
开发的交互式应用程序Cameo中。最后,我们将会有一些人脸到人脸的
交互!
5.1 技术需求
本章使用了Python、OpenCV以及NumPy。作为OpenCV的一部分,使
用了可选的opencv_contrib模块,其中包括人脸识别功能。本章的某
些部分使用了OpenCV对OpenNI 2的可选支持来从深度摄像头捕捉图
像。安装说明请参阅第1章。
本章的完整代码可以在本书的GitHub库
(https://github.com/PacktPublishing/Learning-OpenCV-4-
Computer-Vision-with-Python-Third-Edition)的chapter05文件夹
中找到。示例图像在本书GitHub库的images文件夹中。
5.2 Haar级联的概念化
在谈到分类物体并跟踪其位置时,我们到底想要探究什么呢?构
成物体的可识别部分的是什么?
即使来自网络摄像头的摄影图像,也可能包含很多赏心悦目的细
节。但是,因为光线、视角、视觉距离、摄像头抖动和数字噪声的变
化,图像细节往往不稳定。此外,即使物理细节上的真实差异也不可
能会引起我们对分类的兴趣。约瑟夫·豪斯(本书作者之一)在学校
学过,在显微镜下,没有两片雪花看起来是一样的。幸运的是,作为
一个加拿大的孩子,他已经学会了不用显微镜就能识别雪花,因为雪
花在整体上的相似之处更明显。
因此,抽象图像细节的一些方法有助于产生稳定的分类和跟踪结
果。这些抽象称为特征,据说是从图像数据中抽象的。尽管任何像素
都可能影响多个特征,但是特征应该比像素少。把一组特征表示为一
个向量,可以根据图像的对应特征向量之间的距离来度量两幅图像之
间的相似程度。
类Haar特征是应用于实时人脸检测的常用特征之一。在论文
“Robust Real-Time Face Detection”(International Journal of
Computer Vision 57(2),137–154,Kluwer Academic
Publishers,2001)中,作者Paul Viola和Michael Jones首次将类
Haar特征用于人脸检测。可以在
http://www.vision.caltech.edu/html-files/EE148-2005-
Spring/pprs/viola04ijcv.pdf处找到这篇论文的电子版。每个类Haar
特征描述了相邻图像区域之间的对比度模式。例如,边、顶点和细线
都生成了一种特征。有些特征是独特的,因为这些特征通常出现在某
一类对象(如人脸)上,而不会出现在其他对象上。可以把这些特征
组织成一个层次结构,称为级联,其中最高层包含最显著的特征,使
分类器能够快速拒绝缺乏这些特征的主体。
对于任意给定的主体,特征可能会根据图像大小和正在评估对比
度的邻域大小而有所不同。正在评估对比度的邻域大小称为窗口大
小。为使Haar级联分类器尺度不变,或者对尺度变化具有鲁棒性,窗
口大小应保持不变,但是将图像重新缩放多次,因此在某种程度上缩
放时对象(如人脸)大小可能匹配窗口的大小。原始图像和缩放图像
一起称为图像金字塔,图像金字塔中的每个连续的层都是一幅更小的
缩小图像。OpenCV提供了一个尺度不变的分类器,可以以一种特定的
格式从XML文件加载级联分类器。这个分类器在内部将任意给定的图像
转换为图像金字塔。
用OpenCV实现的Haar级联分类器对旋转角度或者透视图的变化并
不鲁棒。例如,认为倒立的人脸和正立的人脸不一样,认为侧面看的
脸和正面看的脸不一样。通过考虑图像的多种变换以及多个窗口大
小,更复杂、资源更密集的实现可以提升Haar级联对旋转角度的鲁棒
性。但是,我们将只介绍OpenCV的实现。
5.3 获取Haar级联数据
OpenCV 4源代码或者安装的OpenCV 4预包构建,应该包含名为
data/haarcascades的子文件夹。如果无法找到这个文件夹,请回到第
1章获取OpenCV 4的源代码说明。
data/haarcascades文件夹包含可以由名为
cv2.CascadeClassifier的OpenCV类加载的XML文件。该类的实例把给
定的XML文件解释为Haar级联,为某种类型的物体(如人脸)提供一个
检测模型。cv2.CascadeClassifier可以检测任意图像中的这种类型的
物体。通常,我们可以从文件中获取静态图像,或者从视频文件或视
频摄像头获取一系列帧。
找到data/haarcascades后,在其他地方为项目创建一个目录。在
这个文件夹中创建名为cascades的子文件夹,把下面的文件从
data/haarcascades复制到cascades:

顾名思义,这些级联就是用来跟踪脸和眼睛的。它们需要是观察
对象正面、直立的视图。稍后,在建立人脸检测器时将会用到这些级
联。
如果你想知道如何生成这些级联文件,请参阅约瑟夫·豪斯
的OpenCV 4 for Secret Agents [1] (原书于2019年由Packt出版社出版)中
第3章。只要有足够的耐心和一台强大的计算机,你就可以自己创建级
联,并针对各种类型的对象对创建的级联进行训练。
[1] 本书第2版的中文版《OpenCV项目开发实战(原书第2版)(ISBN
978-7-111-65234-2)已于2020年由机械工业出版社出版。——编辑注
5.4 使用OpenCV进行人脸检测
不论是在静态图像还是在视频回传信号上进行人脸检测,
cv2.CascadeClassifier几乎没有任何区别。视频只是连续的静态图
像:视频中的人脸检测只是将人脸检测应用于每一帧。自然,有了更
先进的技术,就可以在多帧中连续跟踪检测到的人脸,并确定每一帧
中的人脸是否相同。但是,最好知道基本的顺序方法也是有效的。
我们来检测一些人脸。
5.4.1 在静态图像上进行人脸检测
进行人脸检测的第一个也是最基本的方法是加载一幅图像并检测
其中的人脸。为了使结果在视觉上有意义,我们将在原始图像中的人
脸周围绘制矩形。请记住,人脸检测器是针对直立的正面人脸设计
的,我们将使用有多人(伐木工)站成一排的图像,他们肩并肩站
立、面对镜头。
将Haar级联XML文件复制到级联文件夹后,我们创建下列基本脚本
来执行人脸检测:

我们逐步浏览一下前面的代码。首先,使用必要的cv2导入,本书
的每个脚本都有这个导入。然后,声明一个face_cascade变量,这是
一个CascadeClassifier对象,用于加载人脸检测级联:

然后,用cv2.imread加载图像文件,将其转换成灰度图像,因为
Cascade Classifier需要灰度图像。下一步,用
face_cascade.detectMultiScale进行实际的人脸检测:

detectMultiScale的参数包括scaleFactor和minNeighbors。
scaleFactor参数应该大于1.0,确定人脸检测过程中每次迭代时图像
的降尺度比率。正如5.2节介绍的,这种降尺度的目的是通过把不同的
人脸与窗口大小匹配实现尺度不变性。minNeighbors参数是为了保留
检测结果所需要的最小重叠检测次数。通常,我们期望可以在多个重
叠窗口中检测到某人脸,更多的重叠检测使我们更加确信检测到的人
脸是一个真正的人脸。
从检测操作返回的值是一个表示人脸矩形的元组列表。OpenCV的
cv2.rectangle函数允许我们在指定的坐标处绘制矩形。x和y分别表示
左边坐标和顶部坐标,w和h分别表示人脸矩形的宽度和高度。通过循
环遍历faces变量,在所有人脸周围绘制蓝色矩形,请确保使用的是原
始图像,而不是灰度图像:
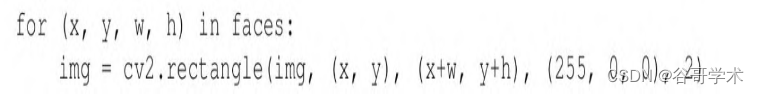
最后,调用cv2.imshow显示处理后的图像。通常,为了防止图像
窗口自动关闭,插入一个对waitKey的调用,当用户按下任意键时返
回:

好了,我们在图像中检测到一群伐木工,如图5-1所示。

这个例子中的照片是谢尔盖·普罗库金–戈尔斯基(Sergey
Prokudin-Gorsky)(1863—1944)的作品,普罗库金–戈尔斯基是彩色
摄影的先驱。沙皇尼古拉二世让普罗库金–戈尔斯基拍摄俄罗斯帝国
的人物和地点,将其作为一个庞大的纪录片项目。1909年,普罗库金–
戈尔斯基在俄罗斯西北部的丝薇尔河附近拍摄了这些伐木工人。
5.4.2 在视频上进行人脸检测
现在,我们了解了如何在静态图像上进行人脸检测。如前所述,
我们可以在视频(摄像头回传信号或者预先录制的视频文件)的每一
帧上重复人脸检测的过程。
下一个脚本将打开一个摄像头回传信号,读取一帧,检查该帧中
的人脸,并在检测到的人脸内扫描眼睛。最后,在人脸周围绘制蓝色
的矩形,在眼睛周围绘制绿色的矩形。以下是完整的脚本:

我们将上面的例子分解成更小、更容易理解的部分:
(1)像往常一样,导入cv2模块。之后,初始化两个
CascadeClassifier对象,一个用于人脸,另一个用于眼睛:

(2)就像大多数交互式脚本一样,打开一个摄像头回传信号,开
始迭代帧。继续,直到用户按下某个键。当成功捕捉到一帧时,将其
转换为灰度作为处理的第一步:

(3)利用人脸检测器的detectMultiScale方法对人脸进行检测。
正如之前所述,我们使用了scaleFactor和minNeighbors参数。我们还
使用minSize参数指定了人脸的最小尺寸,具体为120×120,因此不会
尝试去检测比这个尺寸小的脸。(假设用户坐在摄像头附近,可以有
把握地说,图像中用户的脸将大于120×120像素。)以下是对
detectMultiScale的调用:

(4)迭代检测到的人脸。在原始彩色图像的每个矩形周围绘制一
个蓝色边界。然后,在灰度图像的同一个矩形区域内进行眼睛检测:

眼睛检测器的准确率比人脸检测器要低一些。你可能会看到
阴影、部分镜框或其他被误认为是眼睛的人脸区域。为了改善结果,
可以尝试将roi_gray定义为人脸的一个较小区域,因为我们很容易猜测
到眼睛在直立人脸中的位置。还可以试着使用maxSize参数来避免那些
太大不可能是眼睛的误报。此外,可以调整minSize和maxSize,使尺寸
与w和h(即检测到的人脸大小)成比例。作为一个练习,你可以随意
更改这些参数和其他参数。
(5)循环遍历生成的眼睛矩形,并在其周围绘制绿色轮廓:

(6)最后,在窗口中显示生成的帧:
运行脚本。如果检测器产生了准确的结果,而且如果有任何人脸
在摄像头的视野内,应该会看到人脸周围有一个蓝色的矩形,眼睛周
围有一个绿色的矩形,如图5-2所示。
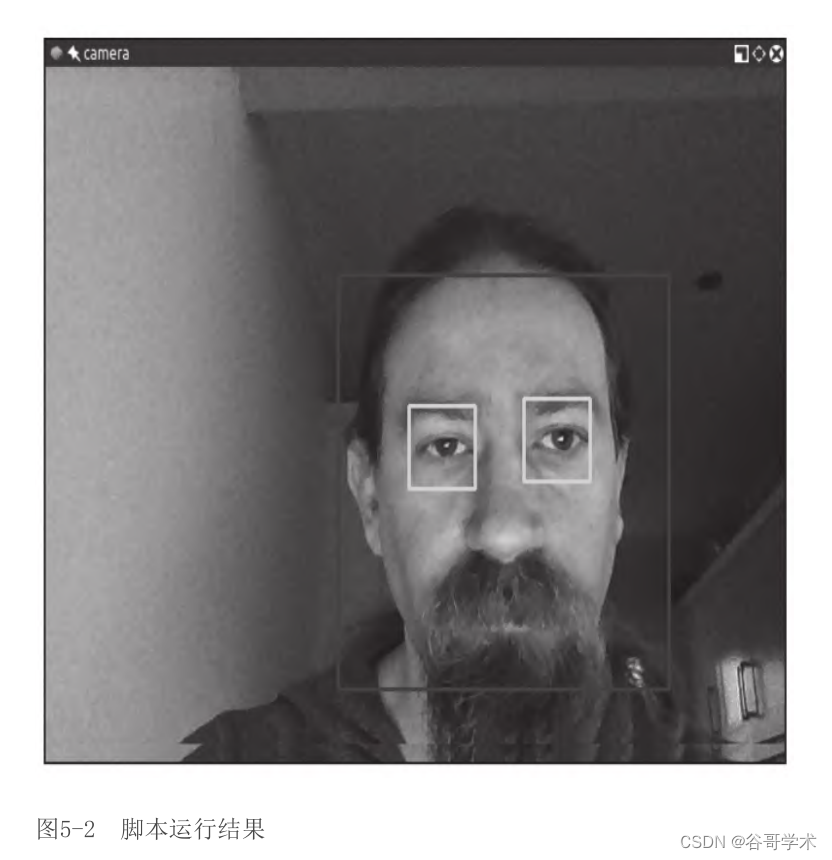
图5-2 脚本运行结果
用此脚本进行实验,研究人脸和眼睛检测器在不同条件下的表
现。试着在更亮或更暗的房间进行。如果戴着眼镜,试着摘掉眼镜再
进行一次。尝试在不同人脸和不同的表情下进行。调整脚本中的检测
参数,看看这些参数对结果的影响。当你感到满意时,我们再来考虑
在OpenCV中还可以做些什么。
5.4.3 进行人脸识别
人脸检测是OpenCV的一个非常棒的特性,也是构成更高级的操作
——人脸识别——的基础。什么是人脸识别?人脸识别是程序在给出
包含人脸的图像或视频时识别此人的能力。实现这一目标的方法之一
(也是OpenCV所采用的方法)是通过为程序提供一组分类图片(人脸
数据库)来训练程序,然后根据这些图片的特征进行识别。
OpenCV人脸识别模块的另一个重要特征是,每次识别都有一个置
信度,这允许我们在实际应用程序中设置阈值以限制错误识别的发生
率。
让我们从头开始。为了进行人脸识别,我们需要待识别的人脸。
人脸可以通过两种方式来获取:自己提供图像或者获取免费的人脸数
据库。在http://www.face-rec.org/databases/上有一个大的人脸数
据库在线可用。以下是其中几个著名的例子:
·耶鲁大学人脸数据库(Yalefaces),网址为
http://vision.ucsd.edu/content/yale-face-database。
·扩展的耶鲁大学人脸数据库B,网址为
http://vision.ucsd.edu/content/extended-yale-face-database-b-b。
·人脸数据库(来自剑桥AT&T实验室),网址为
http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html。
为了对这些样本进行人脸识别,我们必须对包含被采样人的人脸
图像进行人脸识别。这个过程可能是有教学意义的,但是可能不如提
供我们自己的图像那样令人满意。许多计算机视觉学习者有同样的想
法:是否可以编写一个程序来识别自己的脸并且有一定的置信度。
1.生成人脸识别数据
我们来编写生成这些图像的脚本。包含不同表情的图像正是我们
所需要的,但是训练图像最好是正方形的,并且大小相同。我们的示
例脚本要求图像的大小为200×200,但是大多数免费可用的数据集的
图像都比这个尺寸小。
下面是脚本:


在这里,我们利用新掌握的如何在视频中检测人脸的知识来生成
样本图像。我们检测人脸,裁剪灰度转换帧的人脸区域,将其大小调
整为200×200像素,然后保存为PGM文件,并在特定文件夹中指定名称
(在本例中为jm,其中一个作者姓名的首字母,你可以使用自己姓名
的首字母)。与许多窗口应用程序一样,程序会一直运行,直到用户
按下某个键。
之所以出现count变量是因为我们需要图像的累加名称。运行脚本
几秒钟,更改几次脸部表情,并检查脚本中指定的目标文件夹。运行
脚本几秒钟,改变面部表情几次,检查你在脚本中指定的目标文件
夹。你会发现很多你的脸部图像,它们变为了灰度版本,调整了大
小,并用<count>.pgm格式命名。
修改output_folder变量,使其与你的名字匹配。例如,你可以选
择'../data/at/my_name'。运行脚本,等待它在许多帧(比如20帧或
更多)中检测到你的脸,然后按任意键退出。现在,再次修改
output_folder变量,使其与你想要识别的一个朋友的名字匹配。例
如,你可以选择'../data/at/name_of_my_friend'。不改变文件夹的
基本部分(本例中为'../data/at'),因为在后面“加载人脸识别的
训练数据”部分,我们将编写代码从这个基本文件夹的所有子文件夹
中加载训练图像。让你的朋友坐在摄像头前,再次运行脚本,让它在
许多帧中检测你朋友的脸,然后退出。对你想识别的其他任何人重复
这个过程。
现在,我们继续尝试在视频回传信号中识别用户的脸。这会很好
玩!
2.识别人脸
OpenCV 4实现了3种不同的人脸识别算法:特征脸
(Eigenface)、Fisherface和局部二值模式直方图(Local Binary
Pattern Histogram,LBPH)。特征脸和Fisherface来源于一个名为主
成分分析(Principal Component Analysis,PCA)的通用算法。有关
算法的详细描述,请参见以下链接:
·PCA:Jonathon Shlens在http://arxiv.org/pdf/1404.1100v1.pdf上提
供了一个直观的介绍。该算法是由卡尔·皮尔森(Karl Pearson)在
1901年发明的,并且原创论文“On Lines and Planes of Closest Fit to
Systems of Points in Space”网址为http://pca.narod.ru/pearson1901.pdf。
·Eigenface:见论文“Eigenfaces for Recognition”(1991)(作者
是Matthew Turk和Alex Pentland),网址为
http://www.cs.ucsb.edu/~mturk/Papers/jcn.pdf。
·Fisherface:开创性论文“The Use of Multiple Measurements in
Taxonomic Problems”(1936)(作者是R.A.Fisher),网址为
http://onlinelibrary.wiley.com/doi/10.1111/j.1469-
1809.1936.tb02137.x/pdf。
·局部二值模式:介绍该算法的第一篇论文是“Performance
evaluation of texture measures with classification based on Kullback
discrimination of distributions”(1994)(作者是T.Ojala、M.Pietikainen和
D.Harwood),网址为https://ieeexplore.ieee.org/document/576366。
就本书而言,我们对这些算法做一个概述。首先,这些算法都遵
循一个相似的过程:进行一组分类观察(我们的人脸数据库,每个人
都包含大量样本),在此基础上训练一个模型,对脸部图像(这可能
是我们在图像或视频中检测到的脸部区域)进行分析并确定两件事
——主体的身份以及对这个身份是正确的信心的度量。后者通常被称
为置信度。
特征脸算法执行主成分分析(PCA),识别某一组观察数据(同样
是人脸数据库)的主成分,计算当前观测值(图像或帧中检测到的人
脸)相对于数据集的散度,并产生一个值。该值越小,人脸数据库与
检测到的人脸之间的差异就越小,因此值为0表示精确匹配。
Fisherface也是从主成分分析(PCA)衍生的,并应用了更复杂的
逻辑。虽然计算更密集,但是产生的结果往往比特征脸算法更准确。
相反,LBPH将检测到的人脸分成小单元格,并为每个单元格建立
一个直方图,描述在比较给定方向的邻域像素时图像的亮度是否在增
加。这个单元格的直方图可以与模型中相应的单元格进行比较,从而
产生相似性度量。在OpenCV的人脸识别器中,LBPH的实现是唯一允许
模型样本人脸和检测到的人脸具有不同形状、不同大小的人脸识别
器。因此,它很方便,本书的作者发现该算法的准确度优于其他两个
算法。
3.加载人脸识别的训练数据
无论选择什么样的人脸识别算法,我们都可以用同样的方式加载
训练图像。在前面的“生成人脸识别数据”部分中,我们生成了训练
图像,并将它们保存在根据人名或人名首字母进行组织的文件夹中。
例如,下面的文件夹结构可以包含本书作者Joseph Howse(J.H.)和
Joe Minichino(J.M.)的脸部图像样本:

我们编写一个脚本加载这些图像,并以一种OpenCV的人脸识别器
能够理解的方式对它们进行标签。要处理文件系统和数据,我们将使
用Python标准库的os模块以及cv2和numpy模块。我们创建以下面
import语句开头的脚本:

我们添加以下read_images函数,该函数可以遍历目录的子目录,
加载图像,将这些图像调整为指定的大小,并将调整后的图像放入一
个列表中。同时,该函数还构建了另外两个列表:第一个是人名或人
名首字母列表(基于子文件夹名称),第二个是与加载的图像相关联
的标签列表或数字ID列表。例如,jh是一个名称,0可以是从jh子文件
夹加载的所有图像的标签。最后,该函数将图像和标签列表转换为
NumPy数组,并返回3个变量:名称列表、图像的NumPy数组和标签的
NumPy数组。以下是该函数的实现:

通过添加如下代码调用read_images函数:

编辑之前代码块中的path_to_training_images变量,以确保该变
量与之前“生成人脸识别数据”部分的代码中定义的output_folder变量
的基本文件夹相匹配。
到目前为止,我们已经有了有用格式的训练数据,但是还没有创
建人脸识别器,也没有进行任何训练。我们将在接下来的内容中完成
这些任务,同时将继续实现同一脚本。
4.基于特征脸进行人脸识别
既然有了训练图像数组及其标签数组,只用两行代码就可以创建
和训练一个人脸识别器:

我们在这里做了什么?我们使用OpenCV的
cv2.EigenFaceRecognizer_create函数创建特征脸人脸识别器,通过
传递图像数组和标签(数字ID)数组训练识别器。我们还可以选择将
两个参数传递给cv2.EigenFaceRecognizer_create:
·num_components:这是PCA需要保留的主成分量数。
·threshold:这是一个浮点值,指定置信度阈值。丢弃置信度低于
阈值的人脸。默认情况下,该阈值是最大浮点值,因此不会丢弃任何
人脸。
为了测试识别器,我们使用一个人脸检测器和一个摄像头的回传
视频信号。正如在前面的脚本中所做的那样,我们可以使用以下代码
来初始化人脸检测器:

下面的代码初始化摄像头回传信号,遍历帧(直到用户按下任意
键)并对每一帧进行人脸检测和识别:
 我们来看看前面代码块中最重要的功能。对于每个检测到的人
我们来看看前面代码块中最重要的功能。对于每个检测到的人
脸,我们对它进行转换并调整它的大小,以便获得匹配预期大小的灰
度版本(在本例中,预期大小是“加载人脸识别的训练数据”小节中
training_image_size变量定义的200×200像素)。然后,将调整后的
灰度人脸传递给人脸识别器的predict函数。该函数将返回一个标签和
置信度。我们查找对应于这张脸的数字标签的人名。(请记住,我们
在“加载人脸识别的训练数据”中创建了names数组。)我们在识别的
人脸上方用蓝色文本给出姓名和置信度。在遍历所有检测到的人脸之
后,显示带注释的图像。
我们采用了一种简单的方法进行人脸检测和识别,其目的是
让你能够运行一个基本应用程序,并理解OpenCV 4中的人脸识别过
程。要想改进方法并使其更加鲁棒,可以采取进一步的步骤,例如,
正确地对准并旋转检测到的人脸从而最大限度地提高识别准确度。
运行脚本,你应该会看到类似于图5-3的效果。

接下来,我们将考虑如何调整这些脚本,用其他人脸识别算法来
替换特征脸。
5.基于Fisherface进行人脸识别
如何基于Fisherface进行人脸识别?这个过程与上述过程并无多
大变化,只需要实例化一个不同的算法。使用默认参数,model变量的
声明如下:

cv2.face.FisherFaceRecognizer_create接受与
cv2.createEigenFace-Recognizer_create相同的两个可选参数:要保
留的主成分数量和置信度阈值。
6.基于LBPH进行人脸识别
最后,我们快速了解一下LBPH算法。同样,该过程也类似上述过
程。可是,算法工厂接受以下可选参数(按顺序):
·radius:用于计算单元格直方图的邻域之间的像素距离(默认为
1)。
·neighbors:用于计算单元格直方图的邻域数(默认为8)。
·grid_x:水平分割人脸的单元格数量(默认为8)。
·grid_y:垂直分割人脸的单元格数量(默认为8)。
·confidence:置信度阈值(默认情况下,为可能的最高浮点值,
这样就不会丢弃任何结果)。
使用默认参数,model声明如下所示:

请注意,使用LBPH,我们不需要调整图像的大小,因为划分
为网格允许对每个单元格中识别的模式进行比较。
7.基于置信度丢弃结果
predict方法返回一个元组,其中第一个元素是识别到的个体的标
签,第二个元素是置信度。所有的算法都带有设置置信度阈值的选
项,该阈值测量识别到的人脸与原始模型的匹配程度,因此,分值为0
表示完全匹配。
在某些情况下,你可能宁愿保留所有的识别结果,再应用进一步
的处理,这样你就可以提出自己的算法来估计识别结果的置信度。例
如,如果你尝试着识别视频中的人,你可能希望分析随后帧中的置信
度,以确定是否识别成功。在这种情况下,你可以查看算法获得的置
信度,并得出自己的结论。
置信度典型的取值范围取决于算法。特征脸和Fishface产生的
值的范围(大致)在0~20 000,低于4000的所有分值都表示是一个相
当有信心的识别结果。对于LBPH,好的识别结果的参考值低于50,所
有超过80的值都被认为是糟糕的置信度。
常规的自定义方法是,直到有足够多的具有令人满意的任意置信
度的帧数时,才在识别到的人脸周围绘制矩形,但是你完全可以使用
OpenCV的人脸识别模块来根据需要定制应用程序。
5.5 在红外线下换脸
人脸检测和识别并不局限于可见光谱。在近红外(Near-
Infrared,NIR)摄像头和近红外光源下,即使在人眼看来是全黑的场
景中,人脸检测和识别也是可能的。这个功能在安全和监视应用程序
中非常有用。
在第4章中,我们研究了华硕Xtion PRO等近红外深度摄像头的基
本用法。我们扩展了交互式应用程序Cameo的面向对象代码。我们用深
度摄像头拍摄了一些画面。根据深度,我们将每一帧分割成一个主层
(如用户的脸)和其他层。把其他图层涂成黑色,这样就达到了隐藏
背景的效果,使得交互视频信号中只有主层(用户的脸)出现在屏幕
上。
现在,我们修改Cameo,练习之前的深度分割技能以及人脸检测的
新技能。我们来检测人脸,当同一帧中检测到至少两张人脸时,交换
这两张脸,使一个人的头出现在另一个人的身体上。我们不会复制检
测到的人脸矩形中的所有像素,而是只复制该矩形主深度层的一部分
像素。这应该实现了换脸的效果,而不交换脸周围的背景像素。
一旦完成修改,Cameo将能够产生类似图5-4的输出。

我们看到约瑟夫·豪斯的脸和他母亲珍妮特·豪斯(Janet
Howse)的脸互换了。尽管Cameo是从矩形区域复制像素(在前景中,
交换区域的底部清晰可见),一些背景像素没有交换,所以我们不会
看到所有地方都有矩形边缘。
你可以在https://github.com/PacktPublishing/Learning-
OpenCV-4-Computer-Vision-with-Python-Third-Edition处找到本书
库中对Cameo源代码的所有相关更改,特别是在chapter05/cameo文件
夹中的修改。为简单起见,我们不会在本书中讨论所有的修改,但是
将在接下来的两个小节中讨论一些重点内容。
5.5.1 修改应用程序的循环
为了支持换脸功能,Cameo项目有两个新模块,名为rects和
trackers。rects模块包含用于复制和交换矩形的函数,带有一个可选
的掩模,可将复制或交换操作限制在特定像素。trackers模块包含一
个名为FaceTracker的类,它使OpenCV的人脸检测功能适应面向对象的
编程风格。
因为我们已经在本章前面介绍了OpenCV的人脸检测功能,并且已
经在前面的章节中演示了面向对象的编程风格,所以这里不再讨论
FaceTracker的实现。你可以在本书的库中查看FaceTracker的实现。
打开cameo.py,这样就可以浏览对应用程序的全部更改:
(1)在文件的顶部,需要导入新的模块,如下列代码块中的粗体
所示:

(2)现在,我们把注意力转向对CameoDepth类的__init__方法的
修改。更新后的应用程序使用了一个FaceTracker实例。作为其功能的
一部分,FaceTracker可以在检测到的人脸周围绘制矩形。我们给
Cameo的用户一个选项来启用或禁用脸部矩形的绘制。我们将通过一个
布尔变量跟踪当前选择的选项。下面的代码块显示了初始化
FaceTracker对象和布尔变量所需的更改(以粗体显示):

我们在CameoDepth的run方法中使用了FaceTracker对象,该方法
包含捕获和处理帧的应用程序主循环。每成功捕获一帧,就调用
FaceTracker的方法来更新人脸检测结果,并获取最新检测到的人脸。
然后,对于每张脸,根据深度摄像头视差图创建掩模。(在第4章中,
我们针对整个图像创建了一个这样的掩模,而不是针对每个人脸矩形
创建掩模。)然后,调用函数rects.swapRects来执行人脸矩形的掩模
交换。(稍后,我们将在5.5.2节中讨论swapRects的实现。)
(3)根据当前选择的选项,我们可能会让FaceTracker在人脸周
围绘制矩形。所有相关的更改在下面的代码块中以粗体显示:


(4)最后,修改onKeypress方法以便用户可以按X键开始或停止
显示检测到的人脸周围的矩形。同样,相关的更改在下面的代码块中
以粗体显示:

接下来,我们来看在本节前面导入的rects模块的实现。
5.5.2 掩模复制操作
rects模块是在rects.py中实现的。在5.5.1节中,我们已经看到
对rects.swapRects函数的一个调用。可是,在考虑swapRects的实现
之前,我们首先需要一个更基本的copyRect函数。
回到第2章,我们学习了如何使用NumPy的切片语法将数据从一个
感兴趣的矩形区域复制到另一个感兴趣的矩形区域。在感兴趣的矩形
区域之外,源和目标图像不受影响。现在,我们想进一步限制这个复
制操作。我们想要使用一个与源矩形相同大小的给定掩模。
我们将只复制源矩形中掩模值不为零的那些像素。其他像素应保
留目标图像的原始值。这个逻辑包含一个条件数组和两个可能的输出
值数组,可以用numpy.where函数简洁地表达。
牢记这种方法,我们来考虑copyRect函数。它接受一幅源图像和
目标图像、一个源矩形和目标矩形,以及一个掩模作为参数。后者可
能是None,在这种情况下,只需调整源矩形的内容大小以匹配目标矩
形,然后将调整后的内容分配给目标矩形即可。否则,接下来就要确
保掩模和图像有相同的通道数。假设掩模有一个通道,但是图像可能
有三个通道(BGR)。我们可以使用numpy.array的repeat和reshape方
法将重复通道添加到掩模中。最后,使用numpy.where执行复制操作。
完整的实现如下:

