
- 1mysql in条件值是以逗号分隔的字符串,如何处理_mysql in 字符串 逗号分隔
- 2linux查看防火墙状态及开启关闭命令_linux查看防火墙状态找不到命令
- 3*号的三个用途_代码*作用
- 4鸿蒙HarmonyOS实战-Stage模型(概述和组件配置)_鸿蒙 stage模式
- 5QGIS编译(跨平台编译)056:PDAL编译(Windows、Linux、MacOS环境下编译)
- 6java计算机毕业设计基于springboo+vue的房产出租销售门户网站(房屋租赁系统源代码+数据库+Lw文档)_vue门户网站源码
- 7AndroidAutoLayout--屏幕适配终结者_com.zhy:autolayout下载
- 8【热点资讯】交通银行 RPA+AI 全布局_交通银行rpa数量
- 9Jetson Nano b01安装qt_jetson orin安装qt creactor
- 10aspectj's load-time instrumentation_weaveinfo join point 'method-execution(void com.ly
图像搜索_图像检索综述
赞
踩
版权声明:转载自素质云笔记,微信公众号:素质云笔记,转载请注明来源“素质云博客”,谢谢合作!!
转自 https://blog.csdn.net/sinat_26917383/article/details/63306206
笔者在这几天看了一些关于图像特征化的内容,发现图像相似性搜索领域,一般先图像特征量化,然后进行相应的匹配。
- 1、方向一:描述符。先抽取图像局部特征符,根据一些匹配算法进行匹对,较多适合在图像比对,人脸比对等领域;
- 2、方向二:描述符的特征。先抽取图像局部特征符,描述符堆砌然后降维下来,成为拥有全局信息的图像特征向量,适合形成图指纹;
- 3、方向三:颜色特征。使用直方图,后计算两两之间的误差,较多使其向量化,比较适合多量图像。
- 4、方向四:哈希化。适合大规模搜索,哈希化之后去重,或进行搜索。
- 5、方向五:triplet loss。深度学习,从图片相似度学习图片的表示
描述符的定义:
理想的特征描述符应该具有:可重复性、可区分性、集中以及高效等特性;还需要能够应对图像亮度变化、尺度变化、旋转和仿射变换等变化的影响。
计算机视觉中通常把角点(corner)作为是图像的特征,而角点能够作为图像特征点的原因有以下两点:
- 1、角点具有唯一的可识别性,当然,这是基于两幅图像没有非常大的差别的前提下适用的;
- 2、角点具有稳定性,换句话说,就是当该点有微小的运动时,就会产生明显的变化。
于是,可以清晰的看到该点的移动,这有利于特征点的跟踪;对于图像上其它的特征描述,如边(edge),区域(patch)等,用数学的语言来描述,就是,这些特征点变化性比较小。如某一灰度相似的区域,其一阶导数为常数,二阶导数也为常数。
因此,若选取一幅图像中这样的某个区域作为特征,则在另一幅图像中,便很难找到同时满足唯一可识别性和稳定性要求的对应特征。
对于边特征,在垂直于边的方向上,其一阶导数和二阶导数均不为0;但是在平行于边的方向上,则不然。
故边特征不适合作为图像的特征。当发现某个点附近的一阶导数是不断变化时,该点便是角点,可作为图像的特征点。
.
一、方向一:描述符+匹配算法
SIFT、SURF、OBR三类特征描述符检测。笔者默认为SIFT/SURF/OBR这三个是升级版,SIFT->SURF->OBR.
本节参考:python+OpenCV
特征点检测
.
1、SIFT特征(尺度不变特征变换,scale-Invariant feature transform)
2004年提出的Scale Invariant Feature Transform (SIFT) 是改进的基于尺度不变的特征检测器。
该函数会对不同的的图像尺度输出相同的结果。注意:SIFT并不检测关键点,但SIFT会通过一个特征向量来描述关键点周围区域的情况。
SIFT并不检测DOG(difference of gaussians)

import cv2
img = cv2.imread('swan.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT(200)
# max number of SIFT points is 200
kp, des = sift.detectAndCompute(gray, None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中kp就是特征点,des就是描述符=200*128维向量。
特征点的属性:
- kp.pt:特征点的x,y坐标点
- kp.size:特征的直径
- kp.angle:特征的方向
- kp.response:关键点的强度,用来评估des特征的强度
- kp.octave:特征所在金字塔的层级,算法在每次迭代时候,作为参数的图像尺寸和相邻像素都会发生变化
- kp.class_id:对象关键点ID

.
2、SURF特征
SURF采用快速Hessian算法检测关键点+提取特征。
Surf在速度上比sift要快许多,这主要得益于它的积分图技术,已经Hessian矩阵的利用减少了降采样过程,另外它得到的特征向量维数也比较少,有利于更快的进行特征点匹配。
import cv2
img = cv2.imread('swan.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
surf = cv2.SURF(200)
# 200为hessian阈值
kp, des = surf.detectAndCompute(gray, None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
SURF受Hessian阈值影响很大,阈值越高能识别的特征就越少,所以最优的特征可以采用最优检测的方法。
换句话说,SURF抽取的特征点是随机的,不是固定的。
.
3、ORB特征
一种新的具有局部不变性的特征 —— ORB特征,从它的名字中可以看出它是对FAST特征点与BREIF特征描述子的一种结合与改进,这个算法是由Ethan Rublee,Vincent Rabaud,Kurt Konolige以及Gary R.Bradski在2011年一篇名为“ORB:An Efficient Alternative to SIFT or SURF”的文章中提出。
import cv2
img = cv2.imread('swan.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
orb = cv2.ORB()
kp1, des1 = orb.detectAndCompute(gray,None)
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
4、SIFT、SURF、OBR三者比较
- (1)SURF与SIFT效率对比
一般来说,SURF算法的效率是SIFT算法的3倍左右,而检测出的特征点的个数是SIFT算法的1/3左右,当然也和图像大小、纹理复杂程度、 算法参数设置有关。从第(5)组例子中可以看出,SURF算法在边缘抑制上做的似乎没有SIFT好,好多边缘都被检测成了特征点,从而导致特征点个数多于 SIFT。(本节转载于:SIFT算法与SURF算法特征检测效率对比)
- (2)专利情况
ORB是除了SIFT与SURF外一个很好的选择,而且它有很高的效率,最重要的一点是它是免费的,SIFT与SURF都是有专利的,你如果在商业软件中使用,需要购买许可。
- (3)三者在特征点选择的特征
SIFT输出的特征点,可以固定,
SURF、OBR,特征点弹性的,比sift要精练一些。
.
5、描述符+匹配
基于描述符的匹配代表着的意思是,得到特征点之后,匹配两张图,每张图的特征点之间进行匹配。

图中的对等线,就是先得到每张图的特征点,然后特征点-特征点,计算距离。
不做展开,主要有:
- 暴力匹配,brute-force:
遍历描述符,确定描述符是否已经匹配,然后计算匹配质量(距离)并排序,在一定置信度下显示前n匹配,以此得到哪两图是匹配的。
bf =cv2.BFMatcher(cv2.NORM_HAMMING , crossCheck=True)
matches = bf.match(des1,des2)
matcher = sorted(matches , key = lambda x : x.distance)
- 1
- 2
- 3
- 1
- 2
- 3
其他方法:
- k-最近邻匹配
- FLANN匹配:该机制可以根据数据本身选择最合适的算法来处理数据集。FLANN比其他近邻算法要快10倍
- FLANN单应性匹配,单应性是一个条件,表明当两幅图像一幅出现投影畸变时,他们还能彼此匹配。
.
二、方向二:描述符的特征与图像统计特征
1、基于描述符局部特征+k-means全局特征
参考博客:基于SIFT特征和SVM的图像分类
方法:
1. 按图片类别抽取训练集中所有图片的SIFT特征;
2. 将每一类图片的SIFT特征聚类为K类,构成该类的visual vocabulary(其size为K);
3. 对于训练集中的每一张图片,统计vocabulary中K个word的“词频”,得到相应的直方图;
4. 将直方图作为样本向量即可构建SVM的训练数据和测试数据;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
代码在他的博客里面。
2、描述符局部特征+fisher信息量全局特征
Fisher Vector的本质就是对于高斯分布-的变量求偏导!也就是对权重,均值,标准差求编导得到的结果。
在图像识别云平台中,微信图像技术组采用了基于全局特征的图像检索方法,通过SIFT+Fisher Vector得到一幅图像的全局描述子,然后通过量化,将全局描述子量化为低比特的码流,每幅图像对应一个图像识别指纹,在微信图像云平台服务中,已无需构建倒排表,开发者增、删图像时,后台只需在数据库对应的增加、删除指纹即可。对开发者的增删操作可以做出实时的响应。识别过程时,只需比对开发者数据库中的指纹即可。
在识别效果上,通过对多个数据集测试,检索效果上均与基于倒排表结构的图像检索技术相当,甚至某些数据集上优于基于倒排表结构的技术。
微信图像技术组与北京大学、新加坡南洋理工大学有密切合作,走在图像检索技术最前沿,努力为用户提供最优秀的图像识别技术。
参考:GMM、fisher vector、SIFT与HOG特征资料
.
三、颜色特征-方向梯度直方图(Histogram of Oriented Gradient, HOG)
本节转载于segmentfault《利用python进行识别相似图片(一)》
也可以参考博客python代码:OpenCV
Python教程(3、直方图的计算与显示)以及
计算图像相似度——《Python也可以》之一这里先用直方图进行简单讲述。
在图像识别中,颜色特征是最为常用的。(其余常用的特征还有纹理特征、形状特征和空间关系特征等)
其中又分为
- 直方图
- 颜色集
- 颜色矩
- 聚合向量
- 相关图
先借用一下恋花蝶的图片,

从肉眼来看,这两张图片大概也有八成是相似的了。
在python中可以依靠Image对象的histogram()方法获取其直方图数据,但这个方法返回的结果是一个列表,如果想得到下图可视化数据,需要另外使用 matplotlib,这里因为主要介绍算法思路,matplotlib的使用这里不做介绍。
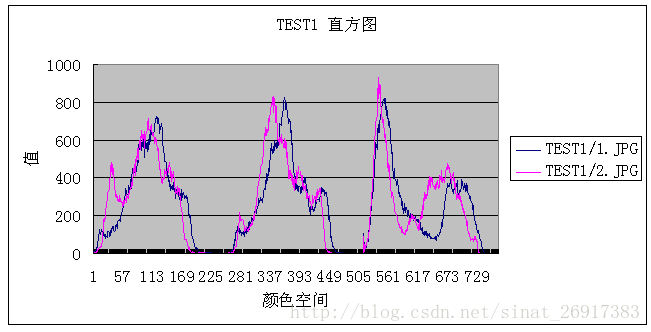
是的,我们可以明显的发现,两张图片的直方图是近似重合的。所以利用直方图判断两张图片的是否相似的方法就是,计算其直方图的重合程度即可。
计算方法如下:
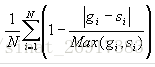
其中gi和si是分别指两条曲线的第i个点。
最后计算得出的结果就是就是其相似程度。
不过,这种方法有一个明显的弱点,就是他是按照颜色的全局分布来看的,无法描述颜色的局部分布和色彩所处的位置。
也就是假如一张图片以蓝色为主,内容是一片蓝天,而另外一张图片也是蓝色为主,但是内容却是妹子穿了蓝色裙子,那么这个算法也很可能认为这两张图片的相似的。
缓解这个弱点有一个方法就是利用Image的crop方法把图片等分,然后再分别计算其相似度,最后综合考虑。
def hist_similar(lh, rh):
assert len(lh) == len(rh)
return sum(1 - (0 if l == r else float(abs(l - r))/max(l, r)) for l, r in zip(lh, rh))/len(lh)
- 1
- 2
- 3
- 1
- 2
- 3
.
四、方向四:哈希化
参考:用 Python 进行图片重复检测
这几种算法是识别相似图像的基础,显然,有时两图中的人相似比整体的颜色相似更重要,所以我们有时需要进行人脸识别,然后在脸部区进行局部哈希,或者进行其他的预处理再进行哈希。
计算得到汉明距离,请看下面三种哈希算法可以用来表征图像指纹,然后利用汉明距离来计算相似性.非常适合大规模去重。大概流程是先对图片进行特定的 hash,再进行相似度检索。用于去重的 hash 算法通常有:
.
1、平均哈希法(aHash)
此算法是基于比较灰度图每个像素与平均值来实现的
一般步骤
1.缩放图片,可利用Image对象的resize(size)改变,一般大小为8*8,64个像素值。
2.转化为灰度图转灰度图的算法。
- 1.浮点算法:Gray=Rx0.3+Gx0.59+Bx0.11
- 2.整数方法:Gray=(Rx30+Gx59+Bx11)/100
- 3.移位方法:Gray =(Rx76+Gx151+Bx28)>>8;
- 4.平均值法:Gray=(R+G+B)/3;
- 5.仅取绿色:Gray=G;
在python中,可用Image的对象的方法convert(‘L’)直接转换为灰度图
3.计算平均值:计算进行灰度处理后图片的所有像素点的平均值。
4.比较像素灰度值:遍历灰度图片每一个像素,如果大于平均值记录为1,否则为0.
5.得到信息指纹:组合64个bit位,顺序随意保持一致性。
最后比对两张图片的指纹,获得汉明距离即可。
.
2、感知哈希算法(pHash)
平均哈希算法过于严格,不够精确,更适合搜索缩略图,为了获得更精确的结果可以选择感知哈希算法,它采用的是DCT(离散余弦变换)来降低频率的方法
一般步骤:
- 缩小图片:32 * 32是一个较好的大小,这样方便DCT计算
- 转化为灰度图:把缩放后的图片转化为256阶的灰度图。(具体算法见平均哈希算法步骤)
- 计算DCT:DCT把图片分离成分率的集合
- 缩小DCT:DCT计算后的矩阵是32 * 32,保留左上角的8 * 8,这些代表的图片的最低频率
- 计算平均值:计算缩小DCT后的所有像素点的平均值。
- 进一步减小DCT:大于平均值记录为1,反之记录为0.
- 得到信息指纹:组合64个信息位,顺序随意保持一致性。
最后比对两张图片的指纹,获得汉明距离即可。
这等同于”汉明距离”(Hamming distance,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数)。如果不相同的数据位数不超过5,就说明两张图像很相似;如果大于10,就说明这是两张不同的图像。
这里给出别人的DCT的介绍和计算方法(离散余弦变换的方法)
python代码:
def pHash(imgfile):
"""get image pHash value"""
#加载并调整图片为32x32灰度图片
img=cv2.imread(imgfile, 0)
img=cv2.resize(img,(64,64),interpolation=cv2.INTER_CUBIC)
#创建二维列表
h, w = img.shape[:2]
vis0 = np.zeros((h,w), np.float32)
vis0[:h,:w] = img #填充数据
#二维Dct变换
vis1 = cv2.dct(cv2.dct(vis0))
#cv.SaveImage('a.jpg',cv.fromarray(vis0)) #保存图片
vis1.resize(32,32)
#把二维list变成一维list
img_list=flatten(vis1.tolist())
#计算均值
avg = sum(img_list)*1./len(img_list)
avg_list = ['0' if i<avg else '1' for i in img_list]
#得到哈希值
return ''.join(['%x' % int(''.join(avg_list[x:x+4]),2) for x in range(0,32*32,4)])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
.
3、dHash算法
相比pHash,aHash的速度要快的多,相比aHash,pHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。
步骤:
- 缩小图片:收缩到9*8的大小,以便它有72的像素点
- 转化为灰度图:把缩放后的图片转化为256阶的灰度图。(具体算法见平均哈希算法步骤)
- 计算差异值:dHash算法工作在相邻像素之间,这样每行9个像素之间产生了8个不同的差异,一共8行,则产生了64个差异值
- 获得指纹:如果左边的像素比右边的更亮,则记录为1,否则为0.最后比对两张图片的指纹,获得汉明距离即可。
和 aHash、pHash 相比,dHash 更快更精确。dHash 压缩的尺寸不是 8x8 或 16x16,而是 NxN+1,通常是 8x9。计算灰度后进行变换的到 NxN 的矩阵。最后一步还是简化为 hash。
没有完全理解,上面的说明可能有重点遗漏或者错误。项目代码在 GitHub 上,下面是演示截图:

.
五、方向五:深度学习
参考简书:从图片相似度学习图片的表示
最早用来从相似图片数据集上学习图片表示的网络结构是siamese网络。

两幅图通过两个共享权重的CNN得到各自的表示。而各自表示的距离决定了他们是相似还是不相似。
在siamese网络之后,又提出了用triplet loss来学习图片的表示,大概思路如下:
拿到3张图片A, B, C。其中A,B相似,A,C不相似。
学到A, B, C 的表示,使得A,B之间的距离尽量小,而A,C之间的距离尽量大。
相关MXNet代码可以见github:https://github.com/xlvector/learning-dl/tree/master/mxnet/triple-loss
.
基于内容的图像检索技术综述-传统经典方法
来源:基于内容的图像检索技术综述-传统经典方法
早期的图片检索技术都是基于文本的,需要按照图片的名称去搜索对应的图片,而这样有个很明显的缺陷就是:大量的图片需要人为事先去命名,这个工作量太大了。随后渐渐出现了基于内容的图片检索技术,较早出现的有哈希算法LSH(Locality-Sensitive Hashing),随后图搜这一块逐渐丰富,从BOF -> SPM -> ScSPm ->LLC 使传统的图搜技术逐渐成熟。下面我们就来巴拉一下传统图搜技术的前世今生。
- 指数权重VLAD,VLAD(Vector of Aggragate Locally
Descriptor)相对于BOW的差别就是,BOW是把局部特征的个数累加到聚类中心上,而VLAD是把局部特征相对于聚类中心的偏差(有正负)累加到聚类中心上,而且是对最相邻的k个聚类中心都进行累加(k一般设为4左右),这样能很大程度地提高特征量化的准确度,而且还能减少聚类中心的数目以提高量化速度。 - FV(Fisher
Vector)是一种类似于BOW词袋模型的一种编码方式,如提取图像的SIFT特征,通过矢量量化(K-Means聚类),构建视觉词典(码本),FV采用混合高斯模型(GMM)构建码本,但是FV不只是存储视觉词典的在一幅图像中出现的频率,并且FV还统计视觉词典与局部特征的差异。 - SPM,由于BOW模型完全缺失了空间位置信息,会使特征的精度降低很多,而SPM(Spatial Pyramid
Matching)就在BOW的基础上加了一个空间位置信息,也相当于在BOW的基础上加了一个多尺度
延伸一:Flickr十亿级图像相似性搜索(附论文+代码)
来源了一个相似性搜索工具:https://github.com/yahoo/lopq 以及 开发 | 揭开Faiss的面纱 探究Facebook相似性搜索工具的原理
使用Locally Optimized Product Quantization (LOPQ)

Faiss 是一个打破上述限制的算法库。它的优点有:
提供数个相似性搜索方法。这些方法针对不同使用情况,提供了跨度很大的功能取舍。
为内存的使用和速度而优化。
为相关索引方法提供了最前沿的 GPU 执行方案。
精确度在 Deep1B 上进行评估,它是包含十亿张图片的图像库。每一个图像都已经被 CNN 处理过,CNN 中的其中一个 activation map,会被作为图像 描述符(descriptor)。这些矢量可以与欧几里得距离进行比较,来量化这些图像之间的相似度。
Deep1B 包含一个比较小的检索图像库。真实的相似性搜索结果,由处理了这些图像的暴力算法提供。因此,如果我们运行一个搜索算法,我们就可以评估结果中的 1-recall@1。
- 上手 Faiss
Faiss 用 C++ 实现,支持 Python。想要上手的各位,请到 GitHub 获取 Faiss,进行编译,然后把 Faiss 模块导入到 Python。Faiss 与 numpy 能做到完美的整合,包括需借助 numpy 阵列来实现的所有功能 (in float32)。
GitHub 地址:https://github.com/facebookresearch/faiss
详情请访问:https://code.facebook.com/posts/1373769912645926/faiss-a-library-for-efficient-similarity-search/
.
延伸二:深度多模态哈希:Deep Cross-Modal Hashing
paper地址:https://arxiv.org/abs/1602.02255
摘要:
Due to its low storage cost and fast query speed, cross-modal hashing (CMH) has been widely used for similarity search in multimedia retrieval applications. However, almost all existing CMH methods are based on hand-crafted features which might not be optimally compatible with the hash-code learning procedure. As a result, existing CMH methods with handcrafted features may not achieve satisfactory performance. In this paper, we propose a novel cross-modal hashing method, called deep crossmodal hashing (DCMH), by integrating feature learning and hash-code learning into the same framework. DCMH is an end-to-end learning framework with deep neural networks, one for each modality, to perform feature learning from scratch. Experiments on two real datasets with text-image modalities show that DCMH can outperform other baselines to achieve the state-of-the-art performance in cross-modal retrieval applications.
.
延伸三:Facebook AI实验室开源相似性搜索库Faiss
github:https://github.com/facebookresearch/faiss
雷锋网:Facebook AI实验室开源相似性搜索库Faiss:性能高于理论峰值55%,提速8.5倍
在处理图像或视频等复杂数据时会涉及专用数据库系统,而相似性搜索(similarity search)则可以在专用数据库系统中找寻应用。但问题是,这些复杂数据通常用高维特征表示,而且需要特定的索引结构。
Faiss 是用于有效的相似性搜索(similarity search)和稠密矢量聚类(clustering of dense vectors)的库。它包含了可在任何大小向量集合里进行搜索的算法,向量集合的大小甚至可达到RAM容纳不下的地步。另外,它还包含了用于评估和参数调优的支持代码。Faiss 用 C ++编写,有 Python / numpy 的完整包装。其中最有用的一些算法则在 GPU 上实现。
Faiss 包含几种相似性搜索的方法。它假定示例可以被表示为向量,并可以通过整数识别。除此之外,这些向量可以与 L2 位距或点积进行比较。与一个查询向量(query vector)相似的向量是具有最低 L2 位距或最高点积的查询向量。Faiss 还支持余弦相似性(cosine similarity),因为它属于标准化向量上的点积。
大多数方法,例如基于二元向量和紧凑量化代码的方法,仅使用向量的压缩表征,并不需要保留原始向量。这通常会降低搜索的准确性,但这些方法可在单个服务器上的主存储器中扩展到数十亿个向量。
该 GPU 实现可接受来自 CPU 或 GPU 内存的输入。在一个带有 GPU 的服务器上,其 GPU 索引可以被用作其 CPU 索引的插入替换(比如用 GpuIndexFlatL2 替代 IndexFlatL2),而且来自或发往 GPU 内存的副本可以被自动处理。
- 给出一个可在GPU上运行的k-selection算法。它可在快速寄存奇储器中运行,并且其灵活性能使它能与其他内核一起使用。对此我们给出了复杂性分析;
- 在GPU上实现的为精确和近似的k最近邻搜索的近最优算法布局;
- 通过一系列实验表明,在单一或多GPU配置中运行的中到大规模的最近邻搜索任务上,我们的方法大幅度优于先前技术。
.
延伸四:PCA-SIFT描述符
参考: PCA-SIFT:一个更鲜明地局部图像描述符
我们的对局部描述符的算法(称为 PCA-SIFT)接受与标准SIFT描述符相同的输入:子像素位置,尺度,和关键点的主导方向。
我们在给出的尺度上提取一个41×41的斑块,围绕关键点,旋转并对齐它的主导方向至规范方向。PCA-SIFT可以总结如下步骤:
- (1)前置计算一个特征空间来表示局部斑块的梯度图像;
- (2)给出一个斑块,计算图像梯度;
- (3)用特征空间投射梯度图像矢量导出紧凑的特征矢量。这个特征矢量比标准SIFT特征矢量在相当大的程度上更小,并可以用相同的匹配算法。
两种特征矢量之间的欧几里德距离被用于确定两个特征矢量中哪个与不同图像中相同关键点符合。

在第二和第三row表示来计算描述符表示所需的时间。我们观察到来计算表示所需要的时间是相当。该表的下部显示,PCA-SIFT是显著快于匹配阶段,PCA-SIFT(N=20)只需要1/3的时间做2.4 million 点比较.
.
延伸五:深入理解空间搜索算法 ——数百万数据中的瞬时搜索
空间数据有两种基本查询类型:最相邻查询和范围查询。这两种查询都是很多几何问题和GIS问题的基本模块。
K相邻
如果给出几千个数据点,如城市的坐标,我们如何检索出与某特定查询点最相邻的点呢?
我们很自然想到的方法可能是这样:
计算每个点与查询点之间的距离。
按距离大小对所有的点进行排序。
返回前k个点。
当有几百个数据点时我们可以用这种方法,但是当我们面临数百万的数据点时,这种方法就显得太慢且无法应用到实际情景。
空间树是如何工作的
大规模地解决这两种问题时就需要将数据点转换到空间索引中。由于数据转变的频率会远远少于查询的频率,因此将数据转变到空间索引的花销对于之后的快速搜索是非常值得的。
几乎所有的空间数据结构都具有相同的原理,以实现有效的搜索:分支和绑定(https://en.wikipedia.org/wiki/Branch_and_bound)。
- R-tree
- K-d tree
- K相邻查询
延伸六:基于深度学习的视觉实例搜索研究进展
来源:深度学习大讲堂
Multi-Scale Orderless Pooling of Deep Convolutional Activation Features (ECCV 2014)
由于全局的CNN特征缺少几何不变性,限制了对可变场景的分类和匹配。作者将该问题归因于全局的CNN特征包含了太多的空间信息,因此提出了multi-scale orderless pooling (MOP-CNN)——将CNN特征与无序的VLAD编码方法相结合。
MOP-CNN的主要步骤为,首先将CNN网络看作为“局部特征”提取器,然后在多个尺度上提取图像的“局部特征”,并采用VLAD将这些每个尺度的“局部特征”编码为该尺度上的图像特征,最后将所有尺度的图像特征连接在一起构成最终的图像特征。提取特征的框架如下所示:

作者分别在分类和实例搜索两个任务上进行测试,如下图所示,证明了MOP-CNN相比于一般的CNN全局特征有更好的分类和搜索效果。
2015年首届阿里巴巴大规模图像搜索大赛总结
首先简单介绍我们的方法——Multi-level Image Representation for Instance Retrieval,该方法取得了这次比赛的第三名。很多方法都是用最后一个卷积层或全连接层的特征进行检索,而由于高层的特征已经损失了很多细节信息(对于更深的网络,损失更严重),所以实例搜索时不是很精准,如下图所示,即整体轮廓相似,但细节则差距很大。

为了克服该问题,我们将CNN网络中不同层的特征图谱(feature map)进行融合,这不仅利用了高层特征的语义信息,还考虑了低层特征的细节纹理信息,使得实例搜索更精准。如下图所示,我们的实验主要基于GoogLeNet-22网络,对于最后的8层特征图(从Inception 3b到Inception 5b),首先使用最大池化对这些不同尺度的特征图分别进行子采样(转换为相同尺寸的特征图),并使用的卷积对这些采样结果进一步地处理。然后对这些特征图做线性加权(由的卷积完成),最后在此基础上,使用sum pooling得到最终的图像特征。在训练时,我们根据所提供的训练数据,通过优化基于余弦距离的triplet ranking loss来端到端学习这些特征。因此在测试时,可以直接使用特征之间的余弦距离来衡量图像的相似度。

另外,借鉴于训练SVM分类器时使用了难分样本挖掘的思想,我们的方法首先在前向计算时,计算当前训练批次中所有潜在三元组的损失(从当前训练批次中选取两张相同类别的图片和一张不同类别的图片构成潜在三元组),然后找到那些“困难”的三元组(更大的损失),最后在反向计算时,使用这些“困难”的三元组进行误差传播,从而取得更好的训练效果。
延伸七:基于内容的图像检索引擎
来源:图像处理
相似图片搜索
- TinEye
http://www.tineye.com/ - Google
http://images.google.com.hk/ - Baidu (百度识图)
http://stu.baidu.com/ - Bing
http://www.bing.com/images - Sougou (搜狗识图)
http://pic.sogou.com/ - Yahoo
http://images.search.yahoo.com/ - Imense
http://imense.com/similarsearch/ - Macroglossa
http://www.macroglossa.com/disclaimer.html - Immenselab
http://www.immenselab.com/ - Picsearch
http://www.picsearch.com/
商品图像搜索

- Like (被Google收购)
http://www.google.com/shopping - Ebay
http://www.ebay.com/mlt/ - Amazon
http://www.a9.com/whatwedo/visual-search/ - 淘淘搜
http://www.taotaosou.com/ - Shopachu
http://www.shopachu.com - Chic Engine
http://www.chicengine.com/ - Fashionfreax
http://lens.fashionfreax.net/zh/ - Incogna
http://www.incogna.com/
移动图像搜索和识别
- Google Goggles
http://www.google.com/mobile/goggles - Kooaba
http://www.kooaba.com/en/apps - SnapTell (被Amazon收购)
SnapTell for iPhone - Pixlinq
http://www.pixlinq.com/home - Digimarc Discover
http://www.digimarc.com/discover - Picitup
http://www2.picitup.com/ - Recognize
https://www.recognize.im/ - LTU Mobile
http://www.ltutech.com/solutions/mobile-visual-search/ - Fashionfreax
http://lens.fashionfreax.net/zh/ - 百度识别(Mobile)
百度搜索APP - 腾讯微信
封面搜索 - ARART
http://arart.info/
More CBIR search engines: http://en.wikipedia.org/wiki/List_of_CBIR_engines
CBIR experimental systems: http://www.icvpr.com/cbir-systems/

