
- 1鸿蒙开发过程中(DevEco Studio)使用远程真机连接端口异常的解决办法_hdc: hdc_server_port must be set to a positive num
- 2IOS面试题编程机制 31-35
- 3AI作画的业界天花板被我找到了,AIGC模型揭秘 | 昆仑万维_singularity openapl
- 4分享63个微信小程序源代码总有一个是你想要的_微信小程序开源源代码
- 5Java LinkedList类和Vector类_mybug鞋
- 6HarmonyOS中利用overflow属性实现横向滚动失效的解决方法_横向滚动条失效
- 7vue+element实现树状表格的增删改查;使用el-table树形数据与懒加载实现树状表格增删改查_vue3树形表格添加数据
- 8遇见这些APP,我觉得世界都变得温柔了_devcheck csdn
- 9Python圣诞树_python圣诞树代码源码
- 10【DBeaver】建立连接报驱动问题can‘t load driver class ‘org.postgresql.Driver_dbeaver连接pg数据库缺少驱动
聊聊几种分布式全局唯一ID生成方案_分布式唯一id生成策略
赞
踩
缘起
在分布式微服务系统架构下,有非常多的情况我们需要生成一个全局唯一的 ID 来做标识,比如:
- 需要分库分表的情况下,分库或分表会导致表本事的自增键不具备唯一性。
- 较长的业务链路涉及到多个微服务之间的调用,需要一个唯一 ID 来标识比如订单 ID、消息 ID、优惠券 ID、分布式事务全局事务 ID。
对于全局唯一 ID 来说,通常具备以下特点:
- 全局唯一性:ID 不会重复,这个是全局唯一 ID 最基本的特性
- 趋势递增:考虑到类似 MySQL 数据存储是基于 B+ 树的聚簇索引,非趋势递增会导致写入性能受到影响。
- 单调递增:保证上一个 ID 的大小一定小于下一个 ID,对于某些有排序需求的场景有一定的必要性,比如 IM 消息触达到端,或者就是单纯的有需要基于 ID 进行排序的需求。
- 信息安全:如果 ID 可以被简单的枚举出来,那么有潜在的数据安全问题。并且如果是订单号的场景,通过订单号的简单相减就预估出当天的订单量的话,会导致商业数据泄漏。
可以发现 1 是我们必须去保证的,2 尽可能保证,3 和 4 一定程度上是互斥的,无法通过一个方案来实现。并且在这个基础上,全局唯一 ID 的生成需要做到高性能(TP999 的响应耗时要尽可能小)以及高稳定性(可用性 5 个 9)。
常见方案
通常来说全局唯一 ID 的生成方案也分几类:
- 单机自行生成,不依赖其他服务,来保证全局唯一性。
- 应用集群,应用服务的业务场景内保证全局唯一 ID。
- 独立服务提供通用的生产全局唯一 ID 的能力。
下面来具体介绍业界常见的一些方案:
UUID
UUID 是通用唯一识别码(Universally Unique Identifier)的缩写,开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成 UUID。
UUID 一共有 5 个版本:
- 版本1 - 基于时间的 UUID:主要依赖当前的时间戳及机器 mac 地址,因此可以保证全球唯一性。
- 版本2 - 分布式安全的 UUID:将版本1的时间戳前四位换为 POSIX 的 UID 或 GID,很少使用。
- 版本3 - 基于名字空间的 UUID(MD5 版):基于指定的名字空间/名字生成 MD5 散列值得到,标准不推荐。
- 版本4 - 基于随机数的 UUID:基于伪随机数,生成 16byte 随机值填充 UUID。重复机率与随机数产生器的质量有关。
- 版本5 - 基于名字空间的 UUID(SHA1版):将版本 3 的散列算法改为 SHA1。
大家多数情况下使用的是 v4 版本,Node.js 的 uuid 包支持所有版本的 uuid 生成。Java 的 UUID.randomUUID() 是基于 v4 版本,UUID.nameUUIDFromBytes() 是基于 v3 版本。
UUID 的优势:
- 本地生成,不依赖外部服务,生成的性能也还不错。
UUID 的劣势:
- v1 版本存在信息安全问题,直接将 mac 地址暴露出去,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- v3、v5 都是在命名空间 + 名称输入的情况下可以输出统一的 UUID,不适合用于唯一 ID 生成。
- v4 版本如果基于伪随机数,理论上会存在出现重复的概率。
- 通常在数据库中存储为字符串,相比整型会花费更多存储空间。
- 字符串无法保证有序,在 MySQL 基于 B+ 树的聚簇索引结构下,写入性能不佳。
在一些简单场景下,对于性能的要求不严格,并且系统并发不高的情况下,使用 UUID 可能是最简单、最低成本的方案。
数据库自增键
数据库主键自增这个是大家都非常熟悉的功能,在分库分表的场景下,依赖单表主键自增显然没法保证唯一性。但也并不是完全不能利用,比如一个统一的 ID 生成服务,背后建若干张 sequence 表专门用于 ID 的生成,每台机器对应不同的 sequence 表,并且每个 sequence 表设置不同的自增初始值和统一的自增步长,比如 2 台机器的情况下,一台自增初始值为 1,一台自增初始值为 2,自增步长都为 2,就相当于每台机器返回的是一个等差数列,且每台机器返回的等差数列之间不会重复。
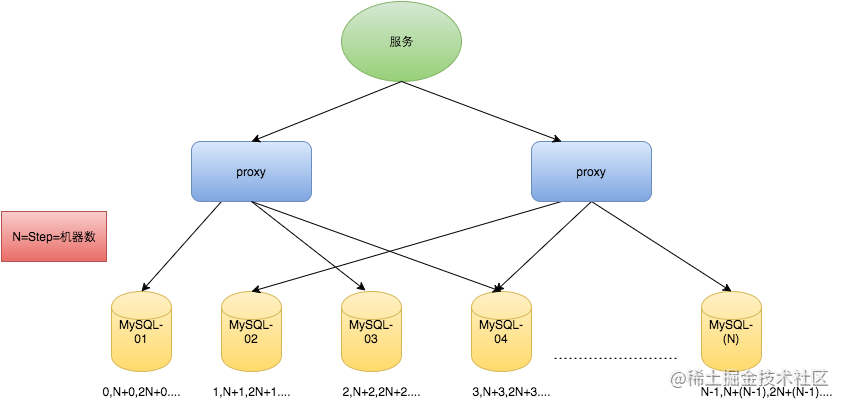
这种方案满足的是趋势递增,但不是绝对的单调递增,同时也有明显的缺陷:
- 扩展性较差,如果服务需要扩容,自增起始值和自增步长都需要整体重新设置。
- 强依赖数据库,数据库挂了整个服务不可用,且数据库的 IO 性能会成为整个服务的瓶颈。
但其实这些缺陷并非无法解决,有一个 “批量发号” 思想的解决方案:
TDDL Sequence
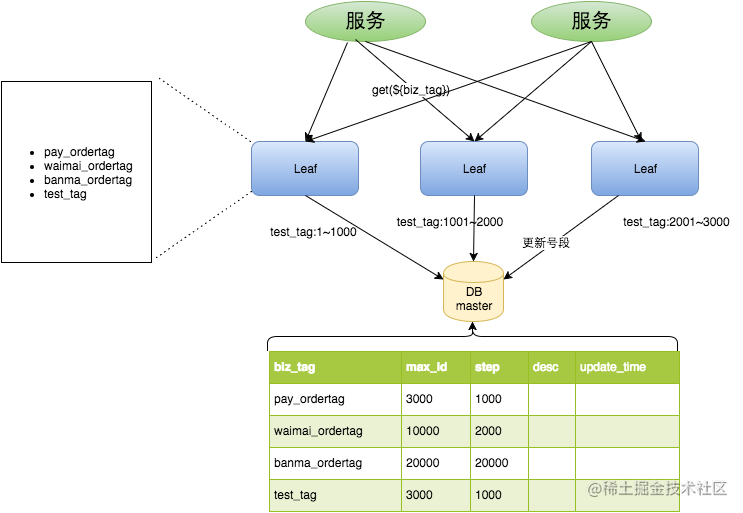
这里通过介绍我司 TDDL Sequence 的方案来解释 “批量发号” 的思想。其实依然是自增初始值结合自增步长的思路,但核心思路是通过应用层来代理 ID 的自增。只是在数据库中记录当前场景的 ID 最大值,通过在应用侧设置了自增步长,每次通过数据库拿到当前场景的 ID 起始值,就在本地得到了一个“号段”,此时更新数据库记录当前最新的 ID 最大值,之后这个 “号段” 维护在内存中,ID 自增通过在内存中自增后直接返回,当这个 “号段” 消耗殆尽后,再重复之前的操作,得到一个新的号段。
举个例子,当前场景下,应用配置的自增步长为 1000,且当前数据库中 ID 最大值为 1000,那么第一次请求数据库,会将当前场景的 ID 最大值更新到 2000,并得到号段 [1000, 2000),在这个区间内的自增 ID 全部通过内存生成,当生成到 2000 的时候,再次请求数据库,将当前场景的 ID 最大值更新为 3000,并在内存中维护号段 [2000, 3000)。
- CREATE TABLE `sequence` (
- `id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
- `name` VARCHAR(64) NOT NULL,
- `value` BIGINT NOT NULL,
- `gmt_create` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
- `gmt_modified` TIMESTAMP NOT NULL,
- PRIMARY KEY (`id`),
- UNIQUE KEY `uk_unique_name` (`name`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 复制代码
但如果自增是在内存中执行的,是否会存在多台机器申请到同一 “号段” 导致出现重复 ID 呢?这个部分是通过在请求数据库阶段的乐观锁实现的,因为当前机器确定使用这个号段前,会更新数据库当前最大 ID 值,通过乐观锁机制,如果拿老的最大 ID 值更新没有成功,意味着需要再去尝试取下一个 “号段”,直到成功更新数据库记录为止。这个过程的时序如下:
另外也不需要担心因为应用重启导致内存中维护号段丢失的问题,因为启动后一定会申请一个新号段,只是可能会存在一些 ID 的浪费,但这个问题通常可以忽略。
Leaf-segment
美团 Leaf-segment 的思路其实几乎和 TDDL Sequence 非常类似,不再额外说明。不过针对号段消耗殆尽后会同步请求数据库,对性能 TP999 指标有一定影响,故其设计了 “双 Buffer优化” 方案,本质上就是在监控号段已经消耗到比如 20% 的情况下,就会提前通过异步的方式拉取下一个号段,避免号段消耗殆尽后的数据库 IO 对性能 TP999 指标的影响。
滴滴也曾开源了 tinyid,其生成 ID 的思想和上述方案几乎一致,就不再赘述。
类雪花算法
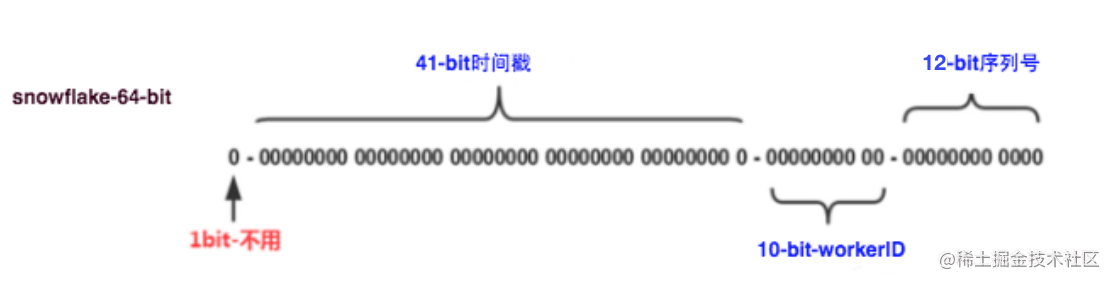
雪花算法是 Twitter 工程师提出的生成全局唯一 ID 的方案,它使用固定的 64 位二进制表示一个 ID,最后可以通过长整型的数据类型存储这个 ID。第一位为保留位,固定为 0,后面 41 位是 时间戳位,表示当前时间戳,那么算一下最多可以表示 (1L<<41)/(1000L*3600*24*365)=69 年的时间,再后面 10 位是 机器标识位,可以分别表示 1024 台机器。最后的 12 位为 序列号位,或者是自增序列位,可以表示 4096 个 ID,理论上 snowflake 方案的 QPS 约为 409.6w/s,这种分配方式可以保证在任何一个 IDC 的任何一台机器在任意毫秒内生成的 ID 都是不同的。
之所以标题叫 “类雪花算法”,原因是位数的分配,实际是可以自己调整的。比如单元化架构,多地分别有不同的机房,或者一个集群的机器数量超过了 1024 台,那么都可以根据实际情况去调整,比如需要单元化架构但一个应用的机器数量不可能超过 1024 台,那么可以将原来的 10 位机器位拿出两位来表示单元,8 位去标识机器。这个通常根据自己业务的实际情况可以灵活调整。
类雪花算法由于依赖本地时间,会有一个知名的时间回拨问题:
时间回拨问题
所谓时间回拨,即当前得到的本地时间小于了之前获取的本地时间,感觉时针被“回拨”了。那么什么情况下可能出现时间回拨问题呢?
- 人工设置
- NTP 网络时间同步
人工设置的情况不多做解释,一般也很少发生。NTP 网络时间同步是一个时间同步协议,C/S 架构,服务器通过从权威设施(原子钟、GPS)获取到当前时间后,同时考虑传输时间差进行时间校准后得到当前的准确时间。首先我们日常家用的时钟,包括机器上的时钟通常是石英材质,石英材质的时钟精度虽然可以满足家用,但实际存在误差,也就意味着通过网络时间同步后的时间可能会出现回拨现象。
这里不得不提到闰秒问题,什么是闰秒?
为确定时间,世界上有两种常用的时间计量系统:基于地球自转的世界时(UT)和基于原子振荡周期的国际原子时(TAI)。由于两种测量方法不同,随着时间推移,两个计时系统结果会出现差异,因此有了协调世界时的概念。 协调世界时以国际原子时秒长为基础,在时刻上尽量接近世界时。1972年的国际计量大会决定,当国际原子时与世界时的时刻相差达到0.9秒时,协调世界时就增加或减少 1 秒,以尽量接近世界时,这个修正被称作闰秒。
简单表达,就是地球自转速率本身不是一个稳定的值,为了磨平误差,世界时可能会出现减少 1 秒的情况,而网络时间同步又会去同步世界时,于是便发生了时间回拨问题。
过去已经有几个知名的因为闰秒导致的故障:2012 年实施闰秒时,引发了 Reddit 的大规模故障,以及 Mozilla、LinkedIn、Yelp 和航空预订服务 Amadeus 的相关问题。2017 年,Cloudflare 的一个闰秒故障使这家网络基础设施公司的一部分客户的服务器离线。
总之时间回拨问题无法避免,对于强依赖本地时间的计算,都需要考虑时间回拨问题的处理。
闰秒将在 2035 年被取消,喜大普奔。
Leaf-snowflake
美团的 Leaf-snowflake 是基于雪花算法的 ID 生成方案,通过独立的集群服务对外提供能力,其机器标识位依赖 Zookeeper 生成,机器本地会备份一份结果用于 Zookeeper 的灾备。
首先记录上一次生成 ID 的时间戳,如果本次的时间戳还小于上次的,那么说明发生时间回拨,如果时间偏差较小,则等待这个时间差过去,再进行生成,否则抛出异常拒绝服务,并且将当前机器剔除。
- //发生了回拨,此刻时间小于上次发号时间
- if (timestamp < lastTimestamp) {
- long offset = lastTimestamp - timestamp;
- if (offset <= 5) {
- try {
- //时间偏差大小小于5ms,则等待两倍时间
- wait(offset << 1);//wait
- timestamp = timeGen();
- if (timestamp < lastTimestamp) {
- //还是小于,抛异常并上报
- throwClockBackwardsEx(timestamp);
- }
- } catch (InterruptedException e) {
- throw e;
- }
- } else {
- //throw
- throwClockBackwardsEx(timestamp);
- }
- }
- //分配ID
- 复制代码

Seata UUID
Seata 的 UUID 生成器是基于雪花算法改良的,针对上述的时间回拨问题进行了解决,同时也进一步突破了原来雪花算法的性能瓶颈。
时间回拨问题本质是每次生成 ID 都会依赖本地时间,Seata UUID 生成器改良成了仅在应用启动是记录当前的时间戳,之后的生产就不再依赖,时间戳位的更新改成了依赖序列号位的溢出,每次当序列号位溢出(即已达到 4096)后将时间戳位进位。

这样的改变相当于即解决了时钟回拨问题,也突破了 4096/ms 的生产性能瓶颈,相当于有 53 位参与递增。
那么这样的改变是否有问题?因为在并发较高的情况下,会出现 超前消费,消费速率超过 4096/ms 的情况下,时间戳位的进位速度以及超过了当前时间戳的值,那么这个时候应用重启再拿当前的时间戳作为初始值,是否就会出现大量重复 ID 的情况呢?没错,理论可能,但这个问题实际被 Seata 忽略了,原因是如果真的持续是这样的 QPS,瓶颈不就不再 UUID 生成器了,Seata 服务本身就撑不住。
当然由于每次生成的 ID 对本地时间不再是强依赖了,那么意味着这个 ID 在有限范围内是可被枚举的,不过由于是用在分布式事务的场景下,这个问题可以忽略。
总结
如果场景简单,直接使用 UUID 即可。如果仅是因为数据量比较大,需要分库分表,那么类似 TDDL Sequence 的方案也完全足够。除此之外,需要具体问题具体分析:
- 如果唯一 ID 要落库,且可预见的会无限增长(比如是一个通用服务),需要一个定长 ID 来保证数据库字段长度的确定性,倾向于考虑类雪花算法的方案。
- 如果判断服务需要承载的并发较高,则最好不要考虑 UUID 的方案。
- 如果业务场景强依赖 ID 进行排序的,必须要求 ID 单调递增,则选择类雪花算法的方案。
作者:淇右
原文链接:https://juejin.cn/post/7191431147593662523

