
- 1鸿蒙开发套件申请,鸿蒙开发快速入门之:Hi3861 开发板(2)环境搭建
- 2公司小程序,公众号申请支付流程_小程序账号申请公众号
- 3第15.12节PyQt(Python+Qt)入门学习:可视化设计界面组件布局详解_pyqt 布局
- 4Web逆向、软件逆向、安卓逆向、APP逆向,关于网络安全这些你必须懂_软件逆向安全工程
- 5搭建本地大模型和知识库,最简单的方法_ollama本地知识库
- 6一文搞懂全链路监控:方案概述与比较 | 干货
- 7Qt6入门教程 5:添加资源和应用程序图标_pyqt6 resource compiler在哪里
- 8Android开发学习---repositories配置_android repositories
- 9跨端开发框架:一次编码,多端运行的终极解决方案
- 10Linux Mii management/mdio子系统分析之六 fixed-mii_bus分析(mac2mac分析)_mac-mac 模式下的 fixed-link
自然语言处理NLP(9)——句法分析c:局部句法分析、依存关系分析_请利用转移算法实现句子“我看见你很开心”的短语结构树
赞
踩
在上一部分中,我们介绍了基于规则法、概率统计法、神经网络法的完全句法分析方法(自然语言处理NLP(8)——句法分析b:完全句法分析)。
在这一部分中,我们将介绍句法分析中的另外两种类型:局部句法分析、依存关系分析。
【一】局部句法分析
相比于完全句法分析要求对整个句子构建句法分析树,局部句法分析(浅层句法分析、语块分析)仅要求识别句子中某些结构相对简单的独立成分,如非递归的名词短语、动词短语等。这些识别出来的结构通常被称作语块(chunk),语块和短语这两个概念可以换用。
例如:
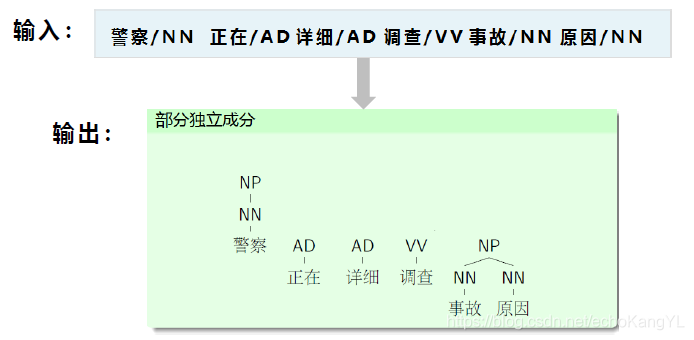
由此可见,在局部句法分析中,可以将组块的分析转化成序列标注问题解决,在这里就不进行赘述。
对序列标注问题不太了解的朋友们可以参考博客:自然语言处理NLP(4)——序列标注a:隐马尔科夫模型(HMM)
【二】依存文法
与完全句法分析以及局部句法分析不同,依存句法分析的主要任务是分析出词与词之间的依存关系,例如:
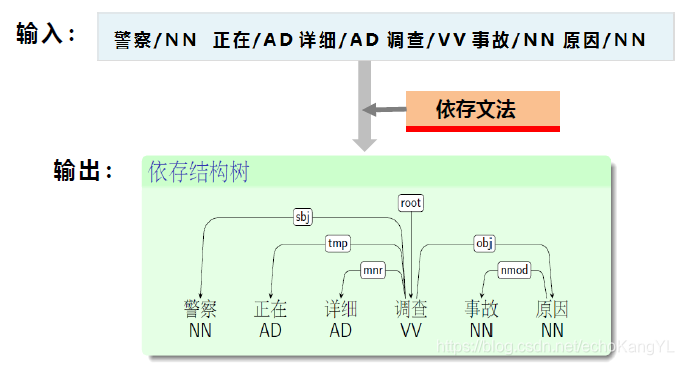
现代依存语法理论认为句法关系和词义体现在词之间的依存关系中。而且,参加组成一个结构的成分(词)之间是不平等(有方向)的,一些成分从属于另一些成分,每个成分只能从属于至多一个成分。
而且,哪个两个词之间有依存关系是根据句法规则和词义来定义的。例如:主语、宾语从属于谓语等。
对于这样的依存关系,我们以“北京是中国的首都”为例,可以得到依存关系树:
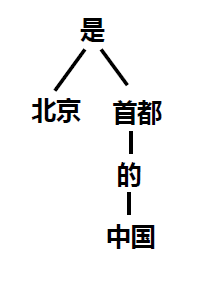
很明显,在一句话中,动词是句子的中心,它支配其他成分,而不受其他成分支配。在上例中,动词“是” 是句子的中心,其他成分依存于它。
我们可以用有向图和依存树的形式表示依存语法,上例“北京是中国的首都”就是用依存树的方式表示的。有向图表示方法举例如下:
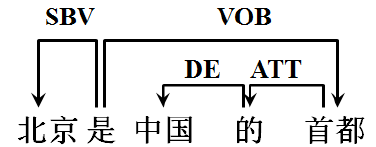
图中,SBV、VOB、DE、ATT表示词与词之间不同的依存关系。
对于依存文法理论的其他内容,例如:依存关系的细化、依存语法的公理、句法的投射性与非投射性以及中文依存树语料库等等,就不再一一进行赘述,有兴趣的朋友们可以自行查阅相关内容~
【三】依存句法分析方法
目前,依存句法分析主要是在大规模训练语料的基础上用机器学习的方法(数据驱动方法)得到依存句法分析器。
数据驱动的依存句法分析方法主要有两种主流方法:
1.基于图(graph-based) 的依存句法分析方法
将依存句法分析问题看成从完全有向图中寻找最大生成树的问题。
2.基于转移(transition-based) 的依存句法分析方法
将依存树的构成过程建模为一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。
基于图的依存句法分析
基于图的生成式分析方法基本思路如下:
1.生成所有节点的完全有向图
2.用各种概率统计法(如最大似然估计)计算各边的概率
3.取权值最大的边加入有向图中
4.使用Prim最大生成树算法,计算出最大生成树,格式化输出
很明显,问题可以转化为传统最小生成树问题(将边概率取负对数即可)。
可以看出,上述过程中最重要的部分是依存边概率的计算。
举个例子:分析句子“我吃米饭”的依存关系
值得注意的是,进行句法分析的输入是进行过词法分析的句子,如下:
[ 我 / rr,吃 / v,米饭 / nf ]
第一步:生成完全有向图
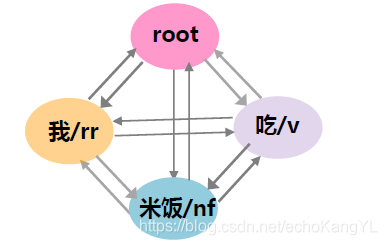
值得注意的是,依存句法树中有虚根的存在,因此,为完全有向图加入一个虚节点,这样图中一共有(
n
n
n+1)个节点(
n
n
n为句子中的词数),句子变成:
[ “核心” / root,我 / rr,吃 / v,米饭 / n ]
以此例为例,每个节点都与另外三个节点构成一条有向边,一共 4 ∗ 3 = 12 4 * 3 = 12 4∗3=12 条。
第二步:计算各边权值
假设 wordA 为词 A,wordB 为词 B,tagA 为 A 的词性,tagB 为 B 的词性。
那么各边权值如下:
W
A
t
o
B
=
−
l
o
g
(
W_{AtoB} = -log(
WAtoB=−log(wordA to wordB 依存关系数 / 总数
)
)
)
W
A
t
o
B
=
−
l
o
g
(
W_{AtoB} = -log(
WAtoB=−log(wordA to tagB 依存关系数 / 总数
)
∗
10
)*10
)∗10
W
A
t
o
B
=
−
l
o
g
(
W_{AtoB} = -log(
WAtoB=−log(tagA to wordB 依存关系数 / 总数
)
∗
10
)*10
)∗10
W
A
t
o
B
=
−
l
o
g
(
W_{AtoB} = -log(
WAtoB=−log(tagA to tagB 依存关系数 / 总数
)
∗
100
)*100
)∗100
对数函数中的内容依然从语料中利用最大似然估计统计获得。
其中,词到词(第一行)的转移概率作为主要因素,其余转移概率主要为平滑操作使用(防止零概率问题)。
此外,为了各种权重的公平起见,对后三行的转移概率进行了加权操作(*10,*100)。
加权值的获取在这里不进行详细描述,有疑问或者感兴趣的朋友可以自行查阅相关资料或私聊本人~
第三步:获取最小生成树
对上图进行最小生成树算法,得到最小生成树:
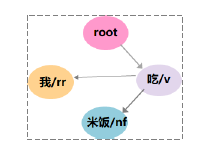
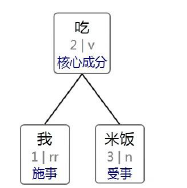
第四步:格式化输出
根据最小生成树,得到依存关系树并输出可视化结果:
该种生成式方法准确率较高,但是算法的复杂度较高,一般为
O
(
n
3
)
O (n^3)
O(n3) 或
O
(
n
5
)
O (n^5)
O(n5),而且不易加入语言特征。
基于转移的依存句法分析
基于转移的决策式(确定性)分析概率方法基本思想如下:
模仿人的认知过程,按照特定方向每次读入一个词。
每读入一个词,根据当前状态做出决策(比如,判断是否与前一个词发生依存关系)。一旦决策做出,将不再改变。
分析过程可以看作是一步步作用于输入句子之上的分析动作序列。
该种算法用三元组
(
S
,
I
,
A
)
(S,I,A)
(S,I,A) 表示分析状态格局,仿照人类从左
到右的阅读顺序,不断地读入单词,每读入一个单词便根据该单词特征和当前分析状态格局特征确定当前最佳动作,逐个读入单词并一步步“拼装”句法树。
三元组
(
S
,
I
,
A
)
(S,I,A)
(S,I,A) 分别表示栈、队列、依存弧集合:
栈(
S
S
S):用来储存系统已经处理过的句法子树的根节点。初始状态下
S
S
S = [
R
o
o
t
Root
Root ] ;定义从栈顶起的第
i
i
i 个元素为
s
i
s_i
si,栈顶元素为
s
1
s_1
s1。
栈结构如图所示:

图中
s
1
s_1
s1 称为右焦点词,
s
2
s_2
s2 称为左焦点词,后记动作都是围绕着这两个焦点词展开的。
队列(
I
I
I):用来存放未处理结点序列。初始状态下队列就是整个句子
b
b
b = [
w
1
,
w
2
,
.
.
.
,
w
n
w_1,w_2,...,w_n
w1,w2,...,wn]
队列结构如图所示:
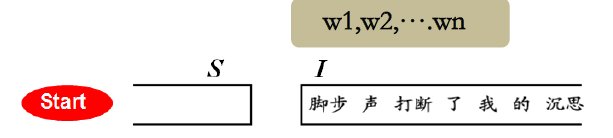
依存弧集合(
A
A
A):一条依存弧有两个信息:动作类型+依存关系名称。
依存关系名称取决于语料库中依存关系的label;
而在Arc-eager 分析法中,动作类型有如下4种:
1.入栈(Shift):

即,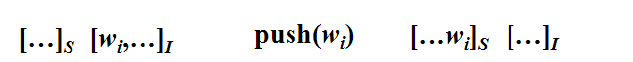
2.依存弧向左指(Left-Arc):

即,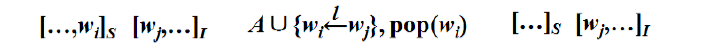
3.依存弧向右指(Right-Arc):

即,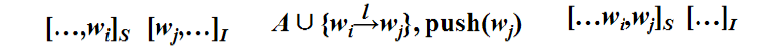
4.出栈(Reduce):

即,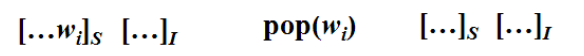
该种方法每读入一个单词便根据该单词特征和当前分析状态格局特征确定当
前最佳动作,逐个“拼装”句法树。
对该过程不太明确的朋友们可以私信我进行交流探讨,在这里就不再赘述啦~
值得注意的是,在传统统计学习方法中,上文提到的两种特征均由人提取出来,例如单词信息、词性信息等等,在这里同样不再进行赘述,有兴趣的朋友们可以自行查阅资料~
最终,我们可以通过输入的句子和根据每一步的特征得到的一组操作得到依存关系树:
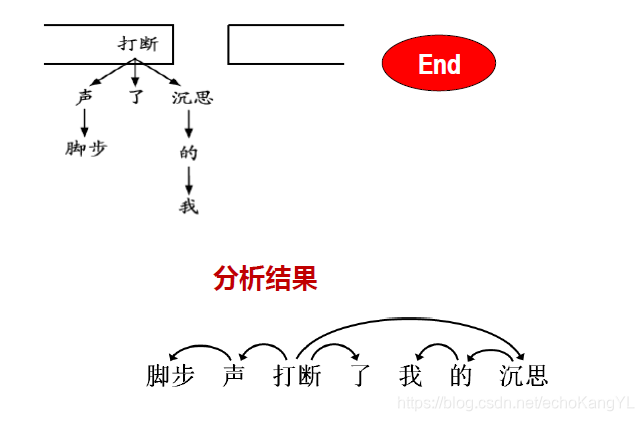
基于神经网络的依存句法分析
一般来说,任何提取特征的工作都可以交给神经网络去做。于是,我们可以利用神经网络实现上述方法:将构成特征的信息项(词、句子、词性等)作为神经网络的输入,由神经网络自动进行特征提取和组合。
【DNN方法】
网络结构如图所示:
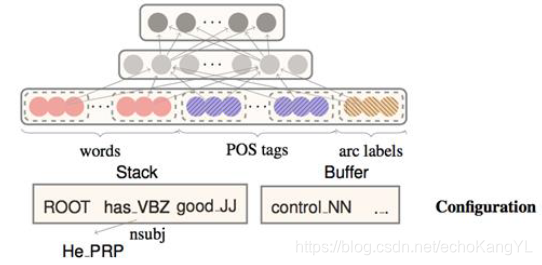
输入是构成特征的信息项,输出是四种动作(Shift、Left-Arc、Right-Arc、Reduce)的概率分布:
即,
图中 X 为输入,Y 为输出。
模型的训练和学习过程与普通的DNN类似,这里就不再进行赘述。
【RNN方法】
前文介绍的DNN方法只使用了格局中部分结点的上下文信息进行依存分析,于是人们想到了用RNN使用全部信息(已生成的部分依存子树、输入队列子串、已有的分析动作序列)进行句法分析:
将分析状态格局的栈、队列和动作分别用三个stack-LSTM(栈式LSTM)表示(分析格局信息为全部上下文信息),分析过程仍是每读入一个单词,根据该单词的当前格局和动作历史信息确定当前最佳动作,最后一步步拼装句法树。
栈式LSTM(stack-LSTM) 结构如下图所示:
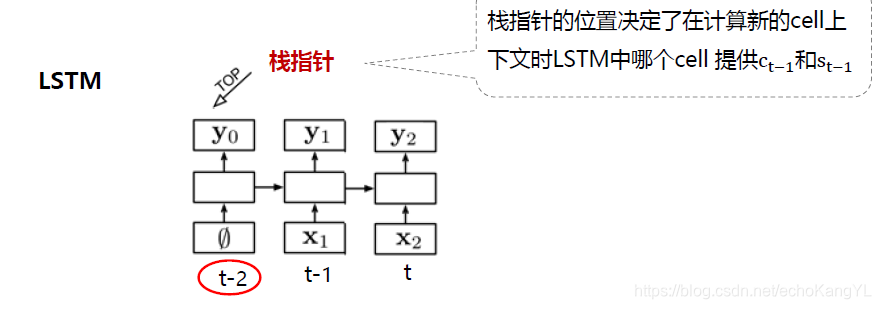
从图中不难看出,该种结构利用栈指针确定当前词,即当前步骤中,三个栈(分析状态格局的栈、队列栈和动作栈)中需要考虑的词。
栈操作对stack-LSTM的影响如下:
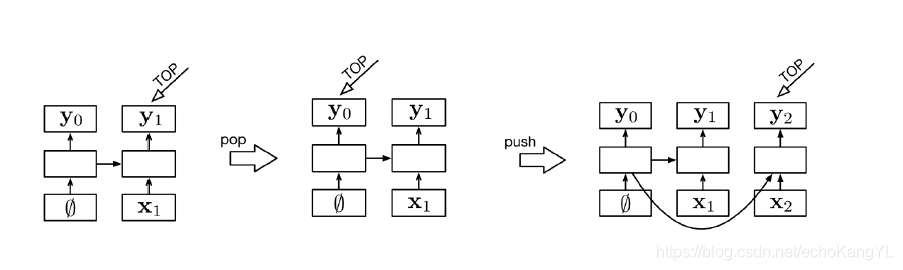
其中,push操作为:输入加到栈顶;pop操作为:栈指针回到先前位置。
于是,利用RNN的依存句法分析方法模型结构如下:
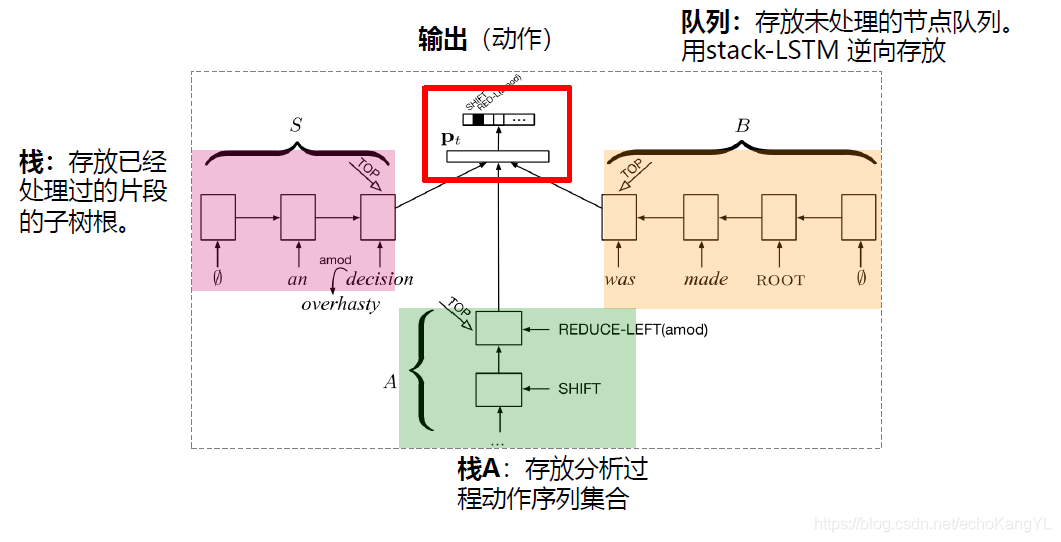
很明显,图中栈 A 只做push操作,加入新动作;而栈 S 的栈顶可以是单个单词,也可以是部分已经建立好的句法树片段。
模型的训练与RNN的训练方式类似,这里不再进行赘述。
最后,我们可以通过读取栈 A 所存储的动作序列集合拼装句法树。
【四】依存句法分析评价方法
依存句法分析评价方法分为三种:
1.无标记依存正确率(unlabeled attachment score, UA):所有词中找到其正确支配词的词所占的百分比,根结点也算在内。
2.带标记依存正确率(labeled attachment score, LA):所有词中找到其正确支配词并且依存关系类型也标注正确的词所占的百分比,根结点也算在内。
3.依存正确率(dependency accuracy, DA):所有非根结点词中找到其正确支配词的词所占的百分比。
看起来有些复杂,没关系我们举个例子:

图中,系统输出与标准答案之间不完全相同的有两个:“外资(3,nmod)”以及“重要(6,sbj)”。
对于无标记依存正确率UA而言,不考虑标记,只考虑支配词。所以“重要(6,sbj)”的支配词正确即算作正确,而“外资(3,nmod)”支配词不正确,所以不算作正确;
而对于带标记依存正确率LA而言,考虑标记同时考虑支配词,所以二者均不算作正确;
依存正确率DA相当于不考虑根节点的UA,只考虑支配词,不考虑标记。
【五】短语结构树与依存结构树
短语机构也成为完全句法结构(自然语言处理NLP(8)——句法分析b:完全句法分析),短语结构和依存结构是目前句法分析中研究最广泛的两类文法体系,依存树偏重关系结构,短语树偏重组成结构,故语义分析中常用依存句法分析。而且,二者可以相互转换。
实现方法如下:
(1) 定义中心词抽取规则,产生中心词表;
(2) 根据中心词表,为句法树中每个节点选择中心子节点;
(3) 将非中心子节点的中心词依存到中心子节点的中心词上,得到相应的依存结构。
第一步中,汉语和英语的中心词抽取规则很多文献都有提到,这里不再进行赘述,有需要的朋友可以自行查阅或者私信我~
实现方法很容易理解,下面我们举个例子:
假设短语结构树如下:
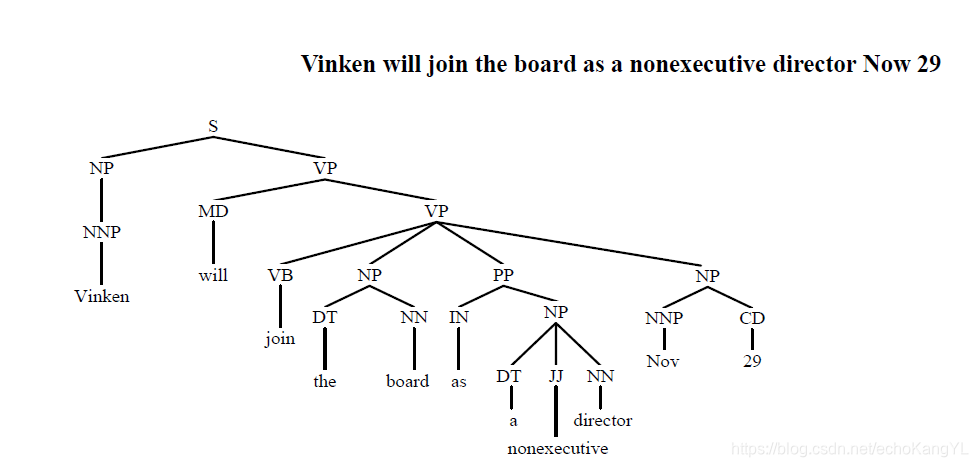
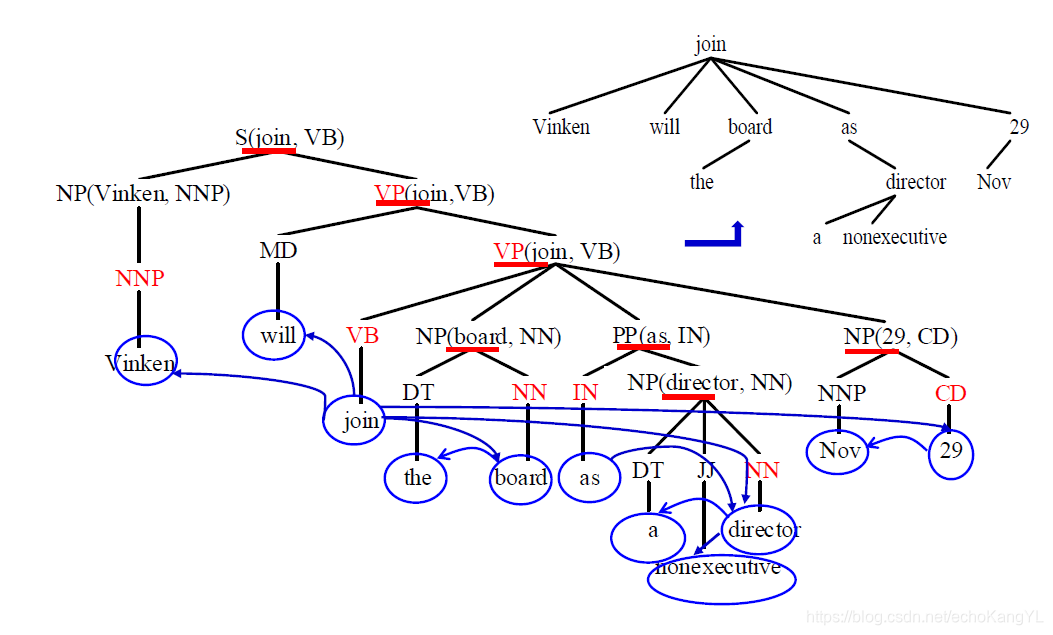
根据中心词表为每个节点选择中心子节点(中心词通过自底向上传递得到),然后将非中心子节点的中心词依存到中心子节点的中心词上。
于是,我们可以得到:
在这一部分中,我们主要介绍了依存关系分析,针对规则法、统计法、神经网络法介绍了实现依存关系的各种方法。
在下一部分的内容中,我们将会介绍NLP领域的另外一个重要问题:语义分析。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!

