
- 1Python+Appium+夜神模拟器 全流程从环境搭建到实现自动化(APP自动化)_如何实现appinum控制夜神模拟器
- 2华为应用市场上传APP失败多次因为:您的应用在用户同意隐私政策前申请获取用户的(MAC地址)个人信息。_华为上传app,隐私链接怎么设置不了
- 3【NLP入门教程】十三、Word2Vec保姆教程_word2vec教程
- 4【8个Python数据清洗代码,拿来即用】_python进行文本清洗时的去除噪声的代码
- 5Docker 基础 ( 二十 ) 部署Redis集群,问题记录_could not connect to redis at 127.0.0.1:6380 创建集群
- 6【开题报告】基于SpringBoot的在线乐器购物商城的设计与实现_陈刚. 基于spring boot+thy me leaf+mysql的动态表单功能模块设计与实现
- 7Linux命令行模式安装VMware Tools详解_linux安装vmware tools
- 8【Python Django Web项目】利用 Python+Django+Pycharm+MySQL 搭建一个自己的Web网站项目的步骤(详细图文)上集
- 9WEB渗透之文件包含漏洞_include($demo); 漏洞
- 10了解机器学习(深度学习)的几个特点_机器学习系统的特点
【机器学习】使用Python的自然语言工具包(NLTK)对Reddit新闻标题进行情感分析_新闻标题情感识别
赞
踩
让我们使用Reddit API获取新闻标题并执行情感分析
在我上一篇文章中,使用Python进行K-Means聚类,我们只是抓取了一些预编译数据,但是对于这篇文章,我想更深入地了解一些实时数据。
使用Reddit API,我们可以从各种新闻subreddit获得成千上万的头条新闻,并开始享受Sentiment Analysis的乐趣。
我们将使用NLTK的vader分析器,它可以计算识别文本并将其分为三种情绪:正面,负面或中立。
文章资源
笔记本: GitHub
库:pandas,numpy,nltk,matplotlib,seaborn
目录
入门
首先,一些导入:
- from IPython import display
- import math
- from pprint import pprint
- import pandas as pd
- import numpy as np
- import nltk
- import matplotlib.pyplot as plt
- import seaborn as sns
- sns.set(style='darkgrid', context='talk', palette='Dark2')
一旦使用,这些进口将被清除。现在值得一提的三个是pprint,它让我们“漂亮地打印”JSON和列表,seaborn它们将为matplotlib图形添加样式,以及iPython的display模块,它将让我们控制清除循环内的打印输出。更多关于以下内容。
NLTK
在开始收集数据之前,您需要安装Natural Language Toolkit(NLTK)python包。要了解如何安装NLTK,您可以访问:http :// www 。nltk 。组织/ 安装。HTML。您需要打开Python命令行并运行nltk.download()以获取NLTK的数据库。
通过PRAW的Reddit API
对于本教程,我们将使用名为`praw`的Reddit API包装器来遍历/ r / politics subreddit标题。
要开始使用`praw`,您需要创建一个Reddit应用程序并获取您的客户端ID和客户端密钥。
制作Reddit应用
只需按以下步骤操作:
- 登录到您的帐户
- 导航到https://www.reddit.com/prefs/apps/
- 点击“ 你是开发者吗?创建应用程序...... ” 按钮
- 输入名称(用户名有效)
- 选择“脚本”
- 使用http://localhost:8080 作为重定向URI
- 单击“ 创建应用程序 ”后,您将看到客户端ID和客户端密钥的位置。

客户ID和客户端密钥的位置
现在开始使用praw,我们需要先创建一个Reddit客户端。
只需在以下行中替换您的详细信息(没有插入符号<>):
- import praw
-
- reddit = praw.Reddit(client_id='<your_client_id>',
- client_secret='<your_client_secret>',
- user_agent='<your_user_name>')
让我们为标题定义一个集合,这样我们就不会在多次运行时获得重复:
- for submission in reddit.subreddit('politics').new(limit=None):
- headlines.add(submission.title)
- display.clear_output()
- print(len(headlines))
965
我们正在迭代/ r / politics中的“新”帖子,通过将限制设置为None,我们可以获得最多1000个标题。这次我们只获得了965个头条新闻。
PRAW为我们做了很多工作。它允许我们使用一个非常简单的界面,同时它在后台处理许多任务,如速率限制和组织JSON响应。
不幸的是,如果没有一些更高级的技巧,我们无法超过1000个结果,因为Reddit在那时切断了。我们可以多次运行此循环并继续向我们的集合添加新标题,或者我们可以实现流式版本。还有一种方法可以利用Reddit的时间参数搜索,但让我们暂时转到我们头条新闻的情感分析。
标记我们的数据
NLTK的内置Vader情感分析器将使用正面和负面词汇的词汇将一段文本排名为正面,负面或中性。
我们可以通过首先创建一个情绪强度分析器(SIA)来分类我们的标题来利用这个工具,然后我们将使用该polarity_scores方法来获得情绪。
我们将每个情绪词典附加到结果列表中,我们将其转换为数据帧:
- from nltk.sentiment.vader import SentimentIntensityAnalyzer as SIA
-
- sia = SIA()
- results = []
-
- for line in headlines:
- pol_score = sia.polarity_scores(line)
- pol_score['headline'] = line
- results.append(pol_score)
-
- pprint(results[:3], width=100)
[{'compound': -0.5267,
'headline': 'DOJ watchdog reportedly sends criminal referral for McCabe to federal prosecutor',
'neg': 0.254,
'neu': 0.746,
'pos': 0.0},
{'compound': 0.0,
'headline': 'House Dems add five candidates to ‘Red to Blue’ program',
'neg': 0.0,
'neu': 1.0,
'pos': 0.0},
{'compound': 0.0,
'headline': 'DeveloperTown co-founder launches independent bid for U.S. Senate',
'neg': 0.0,
'neu': 1.0,
'pos': 0.0}]
- df = pd.DataFrame.from_records(results)
- df.head()
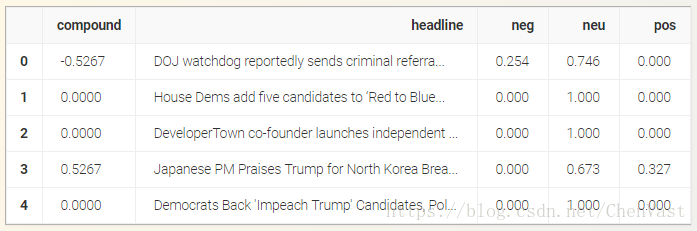
我们的数据帧由来自情绪得分四列:Neu,Neg,Pos和compound。前三个代表我们标题中每个类别的情绪分数百分比,以及compound评分情绪的单个数字。`compound`的范围从-1(极端负)到1(极端正极)。
我们将考虑复合值大于0.2的帖子为正,小于-0.2的帖子为负。选择这些范围需要进行一些测试和实验,这里需要进行权衡。如果您选择更高的值,您可能会得到更紧凑的结果(更少的误报和漏报),但结果的大小将显着减少。
如果compound大于0.2,则创建一个正标签,如果小于-0.2,则标签为-1 compound。其他一切都将是0。
- df['label'] = 0
- df.loc[df['compound'] > 0.2, 'label'] = 1
- df.loc[df['compound'] < -0.2, 'label'] = -1
- df.head()
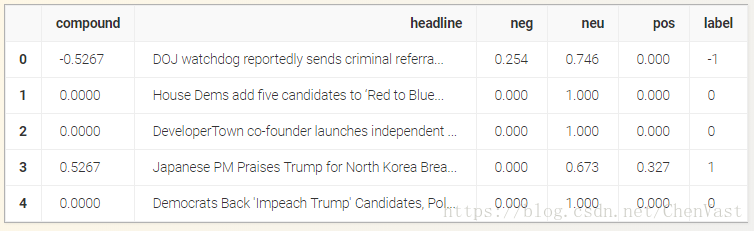
我们拥有需要保存的所有数据,所以让我们这样做:
- df2 = df[['headline', 'label']]
- df2.to_csv('reddit_headlines_labels.csv', mode='a', encoding='utf-8', index=False)
我们现在可以继续附加到此csv,但只要确保如果重新分配标题集,就可以获得重复项。也许添加一个更高级的保存功能,在保存之前读取和删除重复项。
数据集信息和统计
让我们首先在一些积极和消极的头条新闻中占据一席之地:
- print("Positive headlines:\n")
- pprint(list(df[df['label'] == 1].headline)[:5], width=200)
-
- print("\nNegative headlines:\n")
- pprint(list(df[df['label'] == -1].headline)[:5], width=200)
Positive headlines: ['Japanese PM Praises Trump for North Korea Breakthrough', "Bernie Sanders Joins Cory Booker's Marijuana Justice Act to Federally Legalize Weed", 'Trump Administration Seeks to Expand Sales of Armed Drones', 'AP: Trump leaves open possibility of bailing on meeting with Kim, Trump supported by Japan', 'Trump skews reasons behind his 2016 win'] Negative headlines: ['DOJ watchdog reportedly sends criminal referral for McCabe to federal prosecutor', 'Beyer Statement On Syria Strikes', 'Trump confidantes Bossie, Lewandowski urge against firing Mueller', 'Mattis disputes report he wanted Congress to approve Syria strike', 'Criminal charges recommended for fired FBI official Andrew McCabe']
现在让我们检查一下这个数据集中有多少正面和负面:
- print(df.label.value_counts())
-
- print(df.label.value_counts(normalize=True) * 100)
0 433 -1 332 1 200 Name: label, dtype: int64 0 44.870466 -1 34.404145 1 20.725389 Name: label, dtype: float64
第一行给出了标签的原始值计数,而第二行提供了normalize关键字的百分比。
为了好玩,让我们绘制一个条形图:
- fig, ax = plt.subplots(figsize=(8, 8))
-
- counts = df.label.value_counts(normalize=True) * 100
-
- sns.barplot(x=counts.index, y=counts, ax=ax)
-
- ax.set_xticklabels(['Negative', 'Neutral', 'Positive'])
- ax.set_ylabel("Percentage")
-
- plt.show()

大量中性头条新闻主要有两个原因:
- 我们之前做出的假设是复合值在0.2和-0.2之间的标题被认为是中性的。边际越高,中性标题的数量越大。
- 我们使用通用词典来分类政治新闻。更正确的方法是使用政治特定的词典,但为此我们要么需要人工手动标记数据,要么我们需要找到已经制作的自定义词典。
另一个有趣的观察是负面新闻的数量,这可能归因于媒体的行为,例如夸大clickbait的标题。另一种可能性是我们的分析仪产生了许多假阴性。
绝对值得探索改进的地方,但现在让我们继续前进。
标记符和停用词
现在我们收集并标记了数据,让我们来谈谈预处理数据的一些基础知识,以帮助我们更清楚地了解我们的数据集。
首先,我们来谈谈tokenizer。标记化是将文本流分解为称为标记的有意义元素的过程。您可以将段落标记为句子,将句子标记为单词等。
在我们的例子中,我们有标题,可以被认为是句子,所以我们将使用单词标记器:
- from nltk.tokenize import word_tokenize, RegexpTokenizer
-
- example = "This is an example sentence! However, it isn't a very informative one"
-
- print(word_tokenize(example, language='english'))
['This', 'is', 'an', 'example', 'sentence', '!', 'However', ',', 'it', 'is', "n't", 'a', 'very', 'informative', 'one']
如您所见,先前的标记生成器将标点符号视为单词,但您可能希望摆脱标点符号以进一步规范化数据并减小特征大小。如果是这种情况,您需要删除标点符号,或者使用仅查看单词的其他标记器,例如:
- tokenizer = RegexpTokenizer(r'\w+')
- tokenizer.tokenize(example)
['This', 'is', 'an', 'example', 'sentence', 'However', 'it', 'isn', 't', 'a', 'very', 'informative', 'one']
有很多标记器,你可以在这里查看它们:http :// www 。nltk 。org / api / nltk 。令牌化。HTML。可能有一个比其他人更适合这个法案。这TweetTokenizer是一个很好的例子。
在上面的代币中你还会注意到我们有很多单词,比如','是','和','what'等与文本情绪有些无关,而且没有提供任何有价值的信息。这些被称为停用词。
我们可以从NLTK中获取一个简单的停用词列表:
- from nltk.corpus import stopwords
-
- stop_words = stopwords.words('english')
- print(stop_words[:20])
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers']
这是一个简单的英语禁用词列表,其中包含大多数常见的填充词,这些词只会添加到我们的数据大小中,而无需其他信息。更进一步,您很可能会使用更高级的禁用词列表,这对您的用例非常理想,但NLTK是一个良好的开端。
单词分布
让我们首先创建一个函数,该函数将读取标题列表并执行小写,标记化和删除停用词:
- def process_text(headlines):
- tokens = []
- for line in headlines:
- toks = tokenizer.tokenize(line)
- toks = [t.lower() for t in toks if t.lower() not in stop_words]
- tokens.extend(toks)
-
- return tokens
积极的话语
我们可以从数据框中获取所有正面标题标题,将它们交给我们的函数,然后调用NLTK的“FreqDist”函数来获得正面标题中最常见的单词:
- pos_lines = list(df[df.label == 1].headline)
-
- pos_tokens = process_text(pos_lines)
- pos_freq = nltk.FreqDist(pos_tokens)
-
- pos_freq.most_common(20)
[('trump', 80),
('says', 16),
('justice', 13),
('new', 13),
('senate', 12),
('york', 12),
('mueller', 11),
('comey', 11),
('support', 10),
('legal', 10),
('security', 9),
('white', 9),
('giuliani', 9),
('korea', 8),
('party', 8),
('donald', 8),
('cohen', 8),
('state', 8),
('like', 8),
('join', 8)]
现在,让我们看看积极集中一些顶部单词的频率:
有趣的是,最正面的标题词是“特朗普”!
看到其他一些最重要的积极话语与俄罗斯的调查有关,最有可能的情况是“特朗普”+“调查新闻”大多被认为是积极的,但正如我们将在负面词部分看到的那样,很多相同的单词出现所以它不是确定的。
让我们通过绘制频率分布来看更宏观的一面,并尝试检查单词的模式,而不是具体地检查每个单词。
- y_val = [x[1] for x in pos_freq.most_common()]
-
- fig = plt.figure(figsize=(10,5))
- plt.plot(y_val)
-
- plt.xlabel("Words")
- plt.ylabel("Frequency")
- plt.title("Word Frequency Distribution (Positive)")
- plt.show()

上图显示了频率模式,其中y轴是单词的频率,x轴是按频率排序的单词。因此,最常说的一句话,这在我们的例子中是“王牌”,在绘制(1,74)(1,74)。
对于你们中的一些人来说,这个情节可能看起来有点熟悉。那是因为它似乎遵循了幂律分布。因此,为了直观地确认它,我们可以使用对数 - 对数图:
- y_final = []
- for i, k, z, t in zip(y_val[0::4], y_val[1::4], y_val[2::4], y_val[3::4]):
- y_final.append(math.log(i + k + z + t))
-
- x_val = [math.log(i + 1) for i in range(len(y_final))]
-
- fig = plt.figure(figsize=(10,5))
-
- plt.xlabel("Words (Log)")
- plt.ylabel("Frequency (Log)")
- plt.title("Word Frequency Distribution (Positive)")
- plt.plot(x_val, y_final)
- plt.show()

正如所料,一条几乎是直线,尾巴很重(尾巴嘈杂)。这表明我们的数据符合Zipf定律。换句话说,上面的图表显示,在我们的单词分布中,大部分单词出现的次数最多,而大多数单词出现的次数较少。
否定词
现在我们已经检查了积极的话,现在是时候转向消极的话了。让我们获取并处理负面文本数据:
- neg_lines = list(df2[df2.label == -1].headline)
-
- neg_tokens = process_text(neg_lines)
- neg_freq = nltk.FreqDist(neg_tokens)
-
- neg_freq.most_common(20)
[('trump', 125),
('mueller', 25),
('criminal', 21),
('judge', 20),
('mccabe', 19),
('court', 18),
('contempt', 17),
('police', 16),
('comey', 16),
('pittsburgh', 15),
('new', 15),
('kobach', 15),
('syria', 14),
('war', 14),
('senate', 13),
('u', 13),
('cohen', 13),
('case', 13),
('fires', 12),
('says', 12)]
好吧,总统再做一次。他也是最负面的消极词。列表中有一个有趣的补充词是“叙利亚”和“战争”。
这篇文章正在对叙利亚发生的第一次重大罢工时进行更新,所以看起来很明显为什么会被视为负面。
有趣的是,如上所述,我们看到一些相同的词,如'comey'和'mueller',出现在正面集合中。需要进行更多的分析来确定差异,看看我们是否可以更准确地分离,但是现在让我们继续讨论负面词分布的一些图:
- y_val = [x[1] for x in neg_freq.most_common()]
-
- fig = plt.figure(figsize=(10,5))
- plt.plot(y_val)
-
- plt.xlabel("Words")
- plt.ylabel("Frequency")
- plt.title("Word Frequency Distribution (Negative)")
- plt.show()

- y_final = []
- for i, k, z in zip(y_val[0::3], y_val[1::3], y_val[2::3]):
- if i + k + z == 0:
- break
- y_final.append(math.log(i + k + z))
-
- x_val = [math.log(i+1) for i in range(len(y_final))]
-
- fig = plt.figure(figsize=(10,5))
-
- plt.xlabel("Words (Log)")
- plt.ylabel("Frequency (Log)")
- plt.title("Word Frequency Distribution (Negative)")
- plt.plot(x_val, y_final)
- plt.show()

负分布符合Zipf法则。斜坡有点平滑,但重尾绝对存在。这里得出的结论与正分布中显示的前一个完全相同。
结论
正如您所看到的,Reddit API可以非常快速地编译大量新闻数据。绝对值得花时间和精力来增强数据收集步骤,因为它可以很容易地获得数千行政治标题用于进一步分析和预测。
在数据挖掘方面仍然有很多可以设计,并且仍然有很多与检索到的数据有关。在下一个教程中,我们将继续通过数据集进行分析,以构建和训练情感分类器。
原文:
https://www.learndatasci.com/tutorials/sentiment-analysis-reddit-headlines-pythons-nltk/

