
- 1matlab曲线拟合_matlab拟合曲线并得到方程
- 2基于深度学习大模型实现离线翻译模型私有化部署使用,通过docker打包开源翻译模型,可到内网或者无网络环境下运行使用,可以使用一千多个翻译模型语言模型进行翻译_离线翻译大模型
- 3图像情感识别
- 4华为OD机试 - 模拟数据序列化传输(Java & JS & Python & C & C++)_python实现模拟一套简化的序列化传输方式,请实现下面的数据编码与解码过程 编码前
- 5五子棋简单AI算法(C#版)_五子棋ai
- 6大数据学习第十二天(hadoop概念)
- 7【项目实战】常见的HTTP状态码(401 - Unauthorized)_401 unauthorized
- 8人工智能:神经细胞模型到神经网络模型_mp模型中的mp什么意思
- 9CAD2018下载AutoCAD2018下载安装教程附软件下载
- 10python怎么在数据集中加入新_Python学习笔记 - day11 - Python操作数据库
面试题:数据库和缓存如何保证一致性?_数据库和缓存的数据一致性怎么保证
赞
踩
1.造成缓存和数据库的数据不一致的现象原因:
并发问题
- 1
2.如何保障缓存和数据库的一致性?
方案1:同步删除
核心流程:
1.先更新数据库数据
2.然后删除缓存数据
存在的问题:
1)删除缓存失败存在脏数据
2)难以收拢所有更新数据库入口
方案2:延迟双删
核心流程:
1.删除缓存数据
2.更新数据库数据
3.等待一小段时间
4.再次删除缓存数据
- 1
- 2
- 3
- 4
- 5
- 6
- 7
存在的问题:
1)延迟时间难以确认
到底是延迟一秒或者是几秒,这个其实很难确认,你总不能延迟几分钟吧,因为你如果延迟几分钟,那这几分钟可能就存在脏数据了,所以这个时间很难确定。
2)无法绝对保障数据的一致性
并发情况下
小结:由于延迟时间难以确认,同时无法绝对保障数据的一致性,该方案一般不会使用。
方案3:异步监听binlog删除 + 重试
核心流程:
1.更新数据库
2.监听binlog删除缓存
3.缓存删除失败则通过MQ不断重试,直至删除成功
- 1
- 2
- 3
- 4
- 5
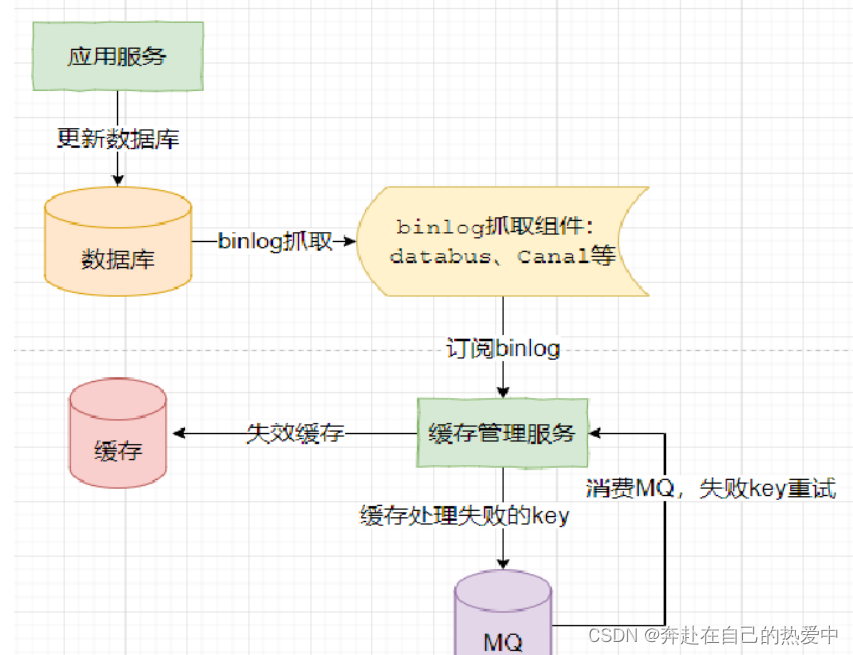
存在的问题:
1)脏数据时间窗口“较大”
这个脏数据时间窗口较大,是相对同步删除来说。在你收到binlog之前,他中间要经过:binlog从主库同步到从库、binlog从库到binlog监听组件、binlog从监听组件发送到MQ、消费MQ消息,这些操作每个都是有一定的耗时的,可能是几十毫秒甚至几百毫秒,所以说它其实整体是有一个脏数据的时间窗口。
而同步删除是在更新完数据库后马上删除,时间窗口大概也就是1毫秒左右,所以说binlog的方式相对于同步删除,可能存在的脏数据窗口会稍微大一点。
2)极端场景下存在长期脏数据问题
binlog抓取组件宕机导致脏数据。该方案强依赖于监听binlog的组件,如果监听binlog组件出现宕机,则会导致大量脏数据。
拆库拆表流程中可能存在并发脏数据
最终方案:缓存三重删除 + 数据一致性校验 + 更新流程禁用缓存 + 强制读Redis主节点
整体方案如下:
1.更新数据库同步删除缓存
2.监听数据库的binlog异步删除缓存:带重试,保障一定会最终删除成功
3.缓存数据带过期时间,过期后自动删除,越近更新的数据过期时间越短
主要用于进一步防止并发下的脏数据问题
解决一些由于未知情况,导致需要更换缓存结构的问题
- 1
- 2
- 3
4.监听数据库的binlog延迟N秒后进行数据一致性校验
解决一些极端场景下的脏数据问题
- 1
5.存在数据库更新的链路禁用对应缓存
防止并发下短期内的脏数据影响到更新流程
6.强制读Redis主节点
7.查询异步数据一致性校验、灰度放量
整体流程图
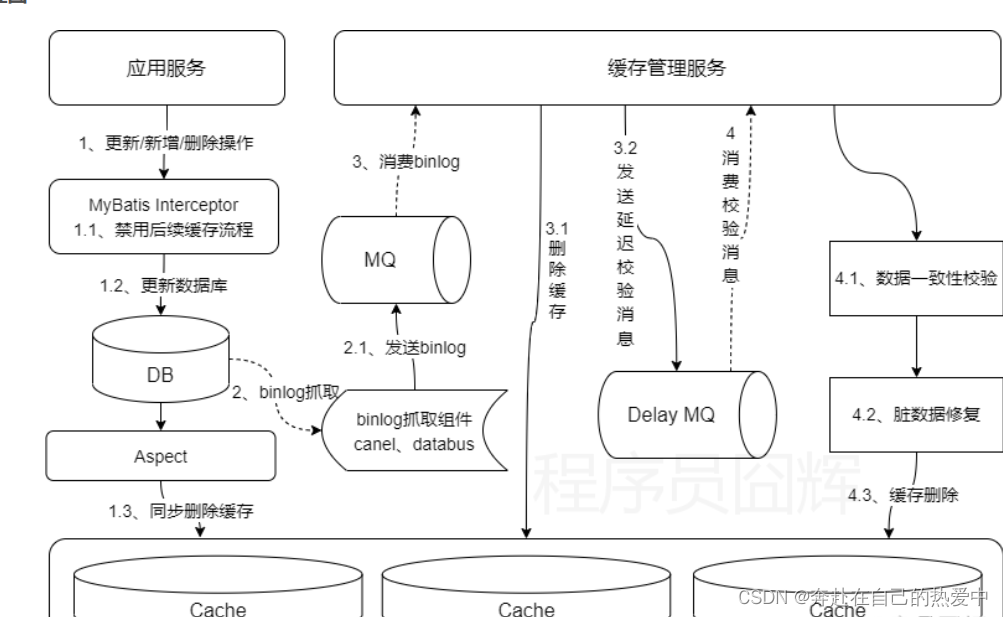
细说各个方案点的设计初衷。
1)更新数据库后同步删除缓存
这个同步删除缓存其实是为了解决我们上面说的那个异步binlog删除不一致时间窗口比较大的问题。更新完数据之后,我们马上进行一次同步删除,不一致的时间窗口非常小。
2)监听数据库的binlog异步删除缓存
该步骤是整个方案的核心,也就是方案3,因为binlog理论上是绝对不会丢的,他不像同步删除存在无法收敛入口的问题。因此,我们会保障该步骤一定能删除成功,如果出现失败,则通过MQ不断重试。
通过前面两个方案点,我们其实已经保障了绝大多数场景下数据是正确的。
3)缓存数据带过期时间,过期后自动删除,越近更新的数据过期时间越短
该策略的设计初衷是因为我们前面讲的那些并发问题其实都是在存在并发更新跟一些并发查询的场景下出现的,因此最近刚刚更新过的数据,他出现不一致的概率相对于那种很久没更新过的数据来说会大很多。
例如最近一个小时内更新的数据,我可能给他设计的过期时间很短,当然这个过期时间很多是相对于其他数据而言,绝对时间还是比较长的,例如我们使用的是一个小时。
这边是因为我们整体的请求量和数据量太大,如果使用的过期时间太短,会导致写缓存流量特别大,导致缓存集群压力很大。
因此,如果使用该策略,建议过期时间一开始可以设置大一点,然后逐渐往下调,同时观察缓存集群的压力情况。
该方案可以进一步保证我们数据的一个最终一致性。
同时带过期时间可以解决另一个问题,如果你在缓存上线后发现缓存数据结构设计不合理,你想把该缓存替换掉。如果该缓存有过期时间,你不需要处理存量数据,让他到期自动删除就行了。如果该缓存没有过期时间,则你需要将存量数据进行删除,不然可能会占用大量空间。
4)监听数据库的binlog延迟N秒后进行数据一致性校验
这个操作也是非常关键,方案3存在的问题就可以通过这个操作来解决掉。就如上面提过的,脏数据都是在更新操作之后的很短时间内触发的。
因此,我们对每一个更新操作,都在延迟一段时间后去校验其缓存数据是否正确,如果不正确,则进行修复,这样就保障了绝大多数并发导致的脏数据问题。
至于延迟多久,我个人建议是延迟几分钟,不能延迟太短,否则起不到兜底的效果。
5)存在数据库更新的链路禁用对应缓存
在数据库更新的场景里面,我们可能会有一些查询操作。例如我更新完这个数据之后,我马上又查了一下。这个时候其实如果你去走缓存,很有可能是会存在脏数据。因为他更新完之后,马上读取这个间隔是非常短的。你的缓存其实可能还没有删除完,或者存在短期内的不一致,我们还没有修复。
但是这种更新场景他对数据的一致性要求一般是比较高的。因为更新完之后,他要拿这个查询出来的数据去做一些其他操作。例如记录数据变更的操作日志。
我把一个数据从a=1改成a=2,我在更新之前,我先查出来a=1,更新完之后我立马就去查出来a=2,这个时候我就记录一条操作日志,内容是a从1变成2。
这种情况下,如果你在更新完之后的这个查询去走缓存,就有很大的概率查到a=1,这时候你的操作日志就变成a从1变成1,导致操作日志是错的。
所以说这种更新后的查询,我们一般会让他不走缓存,因为他这个时效性就是太快了,缓存流程可能还没处理完成。
这个方案点其实是借鉴了MySQL事务的设计思想,MySQL中,事务对于自己更新过的内容都是实时可见的。因此,我们这边也做了一个类似的设计。
6)强制读Redis主节点
Redis跟MySQL一样,也会有主从副本,也会有主从延迟。当你将数据写入Redis后,马上去查Redis,可能由于查询从副本,导致读取到的是老数据,因此我们可以通过直接强制读主节点来解决这个问题,进一步增加数据的准确性。
Redis 不像 MySQL 有主节点压力过大的问题,Redis 是分布式的,可以将16384个槽分摊到多个分片上,每个分片的主节点部署在不同的机器上,这样强制读主时,流量也会分摊到多个机器上,不会存在MySQL的单节点压力过大问题。
7)查询异步数据一致性校验、灰度放量
这一步是缓存功能使用前的一些保障措施,保障缓存数据是准确的。
对于查询异步数据一致性校验,我们一般在查询完数据库之后,通过线程池异步的再查询一次缓存,然后把这个缓存的数据跟刚才数据库查出来的数据进行比较,然后将结果进行打点统计。
然后查看数据一致性校验的一致率有多少,如果不一致的概率超过了1%,那可能说明我们的流程还是有问题,我们需要分析不一致的例子,找出原因,进行优化。
如果不一致的概率低于0.01%,那说明整个流程可能基本上已经没啥问题了。这边理论上一定会存在一些不一致的数据,因为我们查询数据库和缓存之间还是有一定的时间间隔的,可能是1毫秒这样,在高并发下,可能这个间隔之间数据已经被修改过了,所以你拿到的缓存数据和数据库数据可能其实不是一个版本,这种情况下的不一致是正常的。
对于灰度放量,其实就是保护我们自己的一个措施。因为缓存流程毕竟还没经过线上的验证,我们一下全切到缓存,如果万一有问题,那可能就导致大量问题,从而可能导致线上事故。
如果我们一开始只是使用几个门店来进行灰度,如果有问题,影响其实很小,可能是一个简单的事件,对我们基本没影响。
在有类似比较大的改造时,通过灰度放量的方式来逐渐上线,是一种比较安全的措施,也是比较规范的措施。
- 首先是布局
[详细] 赞
踩

