
- 1ArkUI:组件化之常用装饰器了解_arkui一共有哪些装修器
- 2java中ArrayList、LinkedList、Vector的区别
- 3解决mac m1环境下centos虚拟机无法连接网络_mac centos链接不上网
- 4微信小程序 通过设置开发者工具编译模式 改变进入后的第一个page界面_微信开发者工具 打开不是pages第一个页面
- 5java程序员面试经验模型分享。(java,c,go,python)一文通_程序开发模拟面试
- 6一文理解UART通信_uart协议的usb接口到底是usb通讯还是uart通讯?
- 7练习:使用springmvc实现H5(server-sent event)_java serversend.do
- 8Python生成文件md5校验值函数_怎么用python md5函数效验
- 9微信小程序实现图片懒加载_微信小程序加载图片
- 10大疆无人机飞行感知技术中各传感器作用_无人机常用的传感器有哪些
【深度学习:Foundation Models】基础模型完整指南_foundation model有哪些
赞
踩

基础模型是经过人工智能训练的大规模模型,可利用海量数据和计算资源生成从文本到图像的任何内容。最流行的基础模型包括 GANs、LLMs、VAEs 和 Multimodal,为 ChatGPT、DALLE-2、Segment Anything 和 BERT 等著名工具提供支持。
基础模型是在大量无标记数据基础上进行无监督训练的大规模人工智能模型。
其结果是,这些模型具有令人难以置信的通用性,可用于众多任务和用例,如图像分类、物体检测、自然语言处理、语音转文本软件,以及在我们日常生活和工作中发挥作用的众多人工智能工具。
人工智能(AI)模型和该领域的进步正以前所未有的速度加速发展。就在不久前,德国艺术摄影师鲍里斯-埃尔达格森(Boris Eldagsen)的作品 "PSEUDOMNESIA:The Electricia "获得了 2023 年索尼世界摄影大赛创意类奖项。
在一份新闻稿中,该奖项的赞助商索尼公司将其描述为 “两代不同女性的黑白肖像,让人联想起 20 世纪 40 年代家庭肖像的视觉语言”。
获奖后不久,Eldagsen 拒绝接受奖项,承认图片是人工智能生成的。
基础模型并不新鲜。但它们对生成式人工智能软件和算法的贡献正开始对世界产生巨大影响。这张图片是否预示着未来的发展,以及基础模型和生成式人工智能的巨大潜在影响?

获奖的人工智能生成图像:未来的征兆和基础模型的力量?
在本文中,我们将深入探讨基础模型,包括以下内容:
- 什么是基金会模式?
- 基础模型背后的 5 项人工智能原理
- 不同类型的基础模型(例如,广义网络模型、本地语言模型、VAE模型、多模态模型和计算机视觉模型等)
- 基础模型的用例、演变和衡量标准;
- 以及如何在计算机视觉中使用基础模型。
让我们继续深入 . .
什么是基础模型?
基础模型 "一词是斯坦福以人为中心的人工智能研究所(HAI)的基础模型研究中心(CRFM)于 2021 年创造的。CRFM 诞生于斯坦福的 HAI 中心,汇集了斯坦福 10 个院系的 175 名研究人员。
这远非唯一一家对基础模型进行研究的学术机构,但由于这一概念起源于此,因此值得注意的是最初对基础模型的描述方式。
CRFM 将基础模型描述为 “任何在广泛数据上训练出来的模型(一般使用大规模自监督),可以适应(例如微调)广泛的下游任务”。欲了解更多信息,他们的论文《On the Opportunities and Risks of Foundation Models》值得一读。
CRFM 主任、斯坦福大学计算机科学副教授珀西-朗(Percy Lang)说:"当我们听到 GPT-3 或 BERT 时,我们会被它们生成文本、代码和图像的能力所吸引,但更根本、更隐蔽的是,这些模型正在从根本上改变人工智能系统的构建方式。
换句话说,GPT-3(现为 V4)、BERT 和其他许多模型都是基础模型的实例和类型。

让我们来探讨基础模型背后的五个核心人工智能原理、使用案例、基于人工智能的模型类型,以及如何将基础模型用于计算机视觉使用案例。
基础模型背后的 5 项人工智能原理
以下是使基础模型成为可能的五项核心人工智能原则。
根据大量数据进行预训练
无论是经过微调的基础模型,还是开放或封闭的基础模型,通常都是在大量数据的基础上预先训练过的。
以 GPT-3 为例,它是在 500,000 百万字的基础上训练而成的,相当于人类 10 辈子不停地阅读!它包含 1750 亿个参数,比 GPT-3 多 100 倍,比其他同类 LLM 多 10 倍。
要使如此庞大的模型发挥作用,需要大量的数据和参数。实际上,开发基础模型需要非常充足的资金和资源。
一旦公开,任何人都可以将其用于无数商业或开源方案和项目。然而,这些模型的开发需要巨大的计算处理能力、数据和资源。
自我监督学习
在大多数情况下,基础模型根据自我监督学习原则运行。即使有数百万或数十亿的参数,提供的数据和输入也没有标签。模型需要学习数据中的模式,并据此生成响应/输出。
过度拟合
在预训练和参数开发阶段,过拟合是创建基础模型的重要组成部分。同样,Encord 在开发计算机视觉微模型时也使用了过度拟合技术。
微调和快速工程(适应性强)
基础模型的适应性非常强。这成为可能的原因之一是对它们进行微调和促进工程的工作。不仅在开发和训练阶段,而且当模型上线时,提示都可以实现大规模迁移学习。
这些模型根据用户的提示和输入不断改进和学习,使未来发展的可能性更加令人兴奋。
有关更多信息,请查看我们关于 【深度学习:SegGPT】在上下文中分割所有内容 [解释]
。
广义的
基础模型本质上是广义的。由于他们中的大多数人没有接受过任何特定的培训,因此数据输入和参数必须尽可能通用才能使其有效。
然而,基础模型的性质意味着它们可以根据需要应用并适应更具体的用例。从很多方面来说,它们对数十个行业和部门来说更加有用。
考虑到这一点,让我们考虑基础模型的各种用例。 。 。
基础模型的用例
基础模型有数百个用例,包括图像生成、自然语言处理 (NLP)、文本转语音、生成式 AI 应用程序等。
OpenAI 的 ChatGPT(包括最新迭代版本 4)、DALL-E 2 和 BERT(Google 开发的基于 NLP 的掩码语言模型)是最受广泛关注的基础模型示例中的两个。
然而,尽管这些令人兴奋和谈论,还有许多其他用例和基础模型类型。是的,这些基础模型能够执行生成人工智能下游任务,例如创建营销文案和图像,是输出的绝佳演示。
然而,数据科学家还可以为更专业的任务和用例训练基础模型。基础模型可以接受从医疗保健任务到自动驾驶汽车和武器以及分析卫星图像的任何训练。
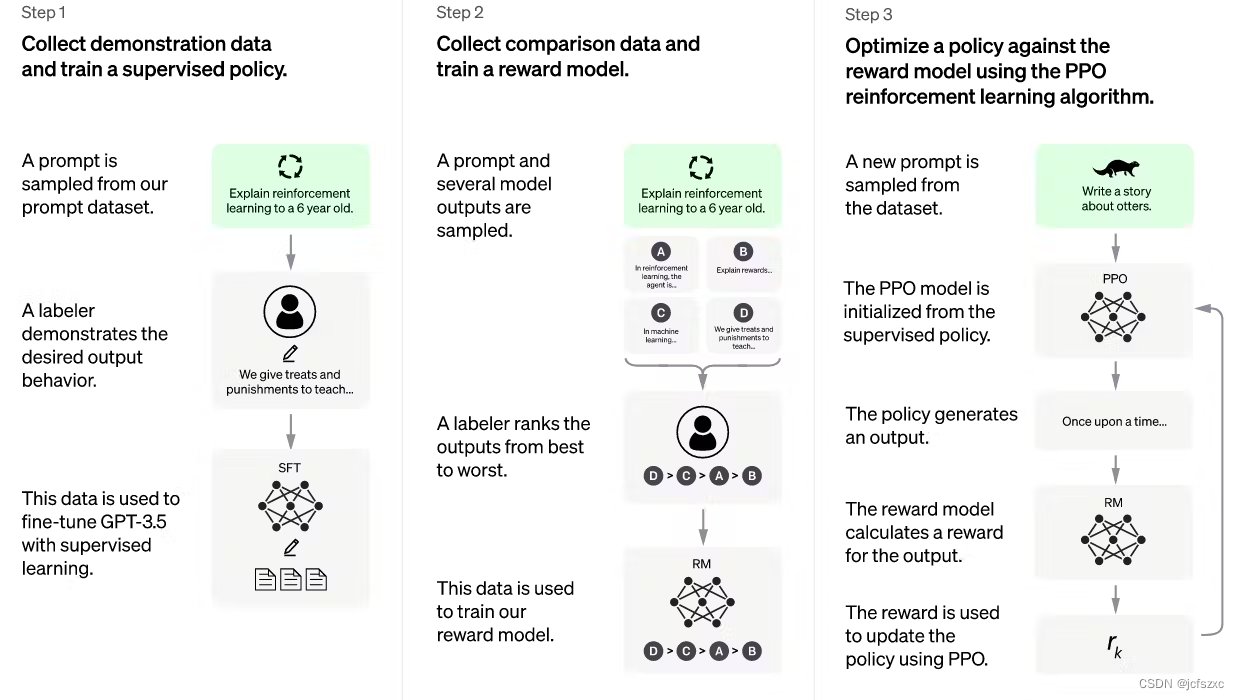
基础模型的类型
有许多不同类型的基础模型,包括生成对抗网络 (GAN)、变分自动编码器 (VAE)、基于 Transformer 的大语言模型 (LLM) 和多模态模型。
当然,还有其他的,例如变分自动编码器(VAE)。但就本文而言,我们将探讨 GAN、多模态、LLM 和计算机视觉基础模型。
计算机视觉基础模型
计算机视觉是许多基于人工智能的模型之一。计算机视觉中使用了数十种不同类型的算法生成模型,基础模型就是其中之一。
计算机视觉基础模型的示例
Florence 就是一个例子,“一种计算机视觉基础模型,旨在学习通用视觉语言表示,适用于各种计算机视觉任务、视觉问答、图像字幕、视频检索等任务。”
Florence 在图像描述和标签方面经过了预先训练,使其成为使用图像文本对比学习方法的计算机视觉任务的理想选择。
多模式基础模型
多模态基础模型结合图像文本对作为输入,并在预训练数据阶段将两种不同的模态关联起来。当尝试实现任务的跨模态学习时,这被证明特别有用,从而使正在训练的多模态模型的数据之间具有很强的语义相关性。
多模式基础模型示例
多模式基础模型的一个例子是微软的 UniLM,“一个统一的预训练语言模型,可以读取文档并自动生成内容。”
微软亚洲研究院于 2019 年开始研究文档 AI(合成、分析、总结和关联文档中大量基于文本的数据)问题。该团队提出的解决方案结合了 CV 和 NLP 模型来创建 LayoutLM 和UniLM,专门用于阅读文档的预训练基础模型。
生成对抗网络(GAN)
生成对抗网络 (GAN) 是一种基础模型,涉及两个神经网络,它们在零和游戏中相互竞争。一个网络的收益就是另一个网络的损失。 GAN 对于半监督、监督和强化学习很有用。并非所有 GAN 都是基础模型;然而,有几个属于这一类。
美国计算机科学家 Ian Goodfellow 和他的同事在 2014 年提出了这个概念。
GAN 的示例
生成对抗网络 (GAN) 有许多用例,包括创建图像和照片、计算机视觉的合成数据创建、视频游戏图像生成,甚至增强天文图像。

基于 Transformer 的大型语言模型 (LLM)
基于 Transformer 的大型语言模型 (LLM) 是最广为人知和使用的基础模型之一。 Transformer 是一种深度学习模型,它权衡每个输入(包括递归输出数据)的重要性。
大型语言模型 (LLM) 是一种语言模型,由具有许多参数的神经网络组成,通常通过自我监督学习方法对数十亿个基于文本的输入进行训练。将 LLM 和 Transformer 相结合,为我们提供了基于 Transformer 的大语言模型 (LLM)。
正如你们中的许多人所知道的那样,有大量的示例和用例,并且可能已经从每天在各种工作场所场景中的部署中受益。

LLMs的例子
一些最受欢迎的LLMs包括 OpenAI 的 ChatGPT(包括最新版本,版本 4)、DALL-E 2 和 BERT(由 Google 创建的LLMs)。
BERT 代表“来自 Transformers 的双向编码器表示”,实际上比基础模型的概念早了几年。
而 OpenAI 的 ChatGPT 中的“Chat”代表“生成式预训练 Transformer”。 Microsft 对 ChatGPT-3 的功能印象深刻,因此对 OpenAI 进行了大量投资,目前正在将其基础模型技术与其搜索引擎 Bing 集成。
谷歌正在取得类似的进展,利用基于人工智能的LLMs通过称为 Bard 的功能来增强其搜索引擎。据我们所知,人工智能即将塑造搜索的未来。
正如您所看到的,LLMs(无论是否基于 Transformer)正在对搜索引擎和人们使用人工智能仅在少量提示下生成文本和图像的能力产生重大影响。
我们始终热衷于学习、理解和使用新工具,尤其是基于人工智能的工具。以下是我们雇用 ChatGPT 作为 ML 工程师一天时发生的事情!
基础模型的评估指标
基础模型的评估方式有很多种,其中大多数分为两类:内在评估(模型针对任务和子任务设置的性能)和外在评估(模型如何针对最终目标进行整体执行)。
不同的基础模型以不同的方式根据性能指标进行衡量;例如,与预测模型相比,生成模型将根据其自身进行评估。
在高层次上,以下是用于评估基础模型的最常见指标:
- 精度: 始终值得测量。这个基础模型的精确度如何?精度和准确度是在数百个算法生成的模型中使用的 KPI。
- F1 分数: 结合了精度和召回率,因为它们是互补的指标,生成单个 KPI 来衡量基础模型的输出。
- 曲线下面积 (AUC): 一种有用的方法,用于评估模型是否可以根据特定基准和阈值分离并捕获积极结果。
- 平均倒数排名 (MRR): 一种评估响应与所提供的查询或提示相比正确与否的方法。
- 平均精度(MAP): 评估检索任务的指标。 MAP 计算接收和生成的每个结果的平均精度。
- 面向召回的 Gisting 评估 (ROUGE): 衡量模型性能的召回,用于评估生成文本的质量和准确性。检查模型是否出现“幻觉”也很有用;得出一个有效猜测的答案,产生不准确的结果。
还有很多其他的。然而,对于研究基础模型或将其与 CV、AI 或深度学习模型结合使用的 ML 工程师来说,这些是一些最有用的评估指标和 KPI。
如何在计算机视觉中使用基础模型
尽管基础模型更广泛地用于基于文本的任务,但它们也可以部署在计算机视觉中。在许多方面,基础模型都直接或间接地为计算机视觉的进步做出了贡献。
更多资源投入人工智能模型开发,这对计算机视觉模型和项目产生了积极的连锁反应。
更直接的是,有专门为计算机视觉创建的基础模型,例如 Florence。另外,正如我们所见,GAN 基础模型对于为计算机视觉项目和应用程序创建合成数据和图像非常有用。
基础模型要点
基础模型在促进各种规模的组织广泛使用和采用人工智能解决方案和软件方面发挥着重要作用。
凭借各个领域的大量用例和应用程序,我们预计基础模型将鼓励采用其他基于人工智能的工具。
生成式人工智能工具等基础模型正在降低企业开始采用人工智能工具的门槛,例如计算机视觉项目的自动注释和标签平台。
得益于人工智能平台,现在所做的很多事情都是不可能的,这展示了组织可以从人工智能工具中获得的投资回报率。

