
- 1idea类存在找不到解决办法_idea找不到已存在的工具类
- 2AI示范代码_ai代码
- 3Docker概念|容器|镜像|命令详细(创建,删除,修改,添加)_docker创建容器
- 4Java学习总结之坦克大战项目(完结版)
- 5苹果个人开发者自动发包(超级签)教程(1)-UDID获取_描述文件自动注册uuid到服务器
- 6Mac os镜像下载地址记录
- 7MacOS下使用如何开启并使用MySQL_mac 启动mysql
- 8[STM32] Keil 创建 HAL 库的工程模板
- 9如何让pycharm的shell环境代码编写同python文件中一样丝滑_pycharm美化shell脚本
- 10SAP BASIS ADM100 中文版 Unit 8(1)_sap 假脱机清单 abap清单
深度学习与围棋,零开始一步步实现自己的“AlphaGo”
赞
踩
AlphaGo引领了近年来机器学习领域的几次标志性突破,并被爆出一系列令人难忘的大新闻,包括与樊麾、李世石、柯洁等围棋大师的对决。这一系列比赛为围棋带来了深远的影响,改变了围棋在全世界范围内的格局,而且也让更多人了解并喜欢上了人工智能这个领域,这些都令我们感到自豪。
但读者可能会问,为什么要关注游戏呢?答案是,儿童通过游戏来了解真实世界,与之类似,机器学习研究者也通过游戏来训练人工智能软件。沿着这个脉络,DeepMind公司的整体策略也是用游戏来模拟真实世界。而AlphaGo项目正是这个策略的一部分。这能帮助我们更好地研究人工智能,训练学习代理,以期望将来的某一天,我们能构建真正的通用学习系统,可以解决真实世界中最复杂的问题。
诺贝尔经济学奖获得者Daniel Kahnemann在他关于人类认知的《思考,快与慢》一书中描述了两种思维方式,而AlphaGo的工作方式正是类似于这两种思维方式。在AlphaGo中,慢的思考模式是通过一种名为蒙特卡洛树搜索(Monte Carlo Tree Search)的算法来实现的。对于某个棋盘布局,这个算法可以通过扩展一个游戏树来规划下一步动作。游戏树代表了未来所有可能的落子动作与回应动作。但由于围棋大约有10170(即1后面有170个0)种可能的棋盘布局,因此要搜索全部的可能动作序列,其实是不可能实现的。为了解决这个问题,需要缩减搜索空间,我们给蒙特卡洛树搜索配套了一个深度学习组件——训练两个神经网络,其中一个用来预测对弈双方的获胜概率,另一个用来预测最有希望获胜的落子动作。
AlphaGo的更新版AlphaZero,依照强化学习的原理,完全靠自我对弈来进行学习。这样就不再需要任何人工训练数据了。它从零开始学习下围棋(以及国际象棋、将棋等),在与自己对弈的学习过程中,它常常能独立发现(之后再抛弃)人类棋手几百年来积累下来的策略,也独立地创造了许多属于它自己的独特策略。
刚刚上架的《深度学习与围棋》就是让你从零开始一步步实现自己的“AlphaGo”的一本书。

《深度学习与围棋》的两位作者Max Pumperla和Kevin Ferguson将引领读者踏上从AlphaGo到它的后期扩展的美好旅程。读完本书之后,读者不仅能够了解如何实现AlphaGo风格的围棋引擎,还能对现代人工智能算法最重要的几个组成部分——蒙特卡洛树搜索、深度学习和强化学习,有深入的理解与实践。作者精心地组织了这几个人工智能话题,并选取围棋作为实践案例,使之既富有趣味,又浅显易懂。除此之外,读者还能学会围棋(这个人类有史以来发明的最美丽、最具挑战性的棋类游戏之一)的基础知识。
另外,本书从一开始就构建了一个可以运行的、简单的围棋机器人,并随着本书内容对它进行逐步的强化:从完全随机地选择动作,逐渐进化成一个复杂的、有自我学习能力的围棋AI。作者对基础概念做了精彩的阐述,再加上可执行的Python代码,带着读者一步一步地前进。必要时,他们也会深入阐述数据格式、部署和云计算等细节话题,使读者可以把围棋机器人真正地运行起来,并享受弈棋的乐趣。
适合读者群
本书适合于那些想要尝试机器学习算法,但相比数学内容来说,更喜欢实践内容的软件开发人员。本书假定读者已经掌握了Python的基础知识。当然,书中的算法也可以用其他现代语言来实现。本书不要求读者有任何围棋基础。如果你喜欢的是国际象棋或其他棋类游戏,也可以将本书介绍的方法与技巧应用到这些棋类游戏中。当然,如果你是围棋爱好者,那么观察自己开发的围棋机器人学会下棋的过程,将会非常开心!两位作者都深有同感。
学习路线图
本书分为3部分,共包括14章和5个附录。
第一部分介绍本书涉及的主要概念。
第1章简明扼要地介绍人工智能的几个分支领域:人工智能、机器学习和深度学习。我们将解释这几个领域之间的关系,以及利用这些领域中的技术所能够解决与无法解决的问题。
第2章介绍围棋的基本规则,并说明我们能够教会计算机哪些知识来学习下棋。
第3章将使用Python来实现围棋棋盘和落子的逻辑,最终可以进行完整的对弈。在本章的最后,我们将编写出最弱的围棋AI。
第二部分介绍创建一个强大的围棋AI所需的技术和理论基础。我们会着重介绍AlphaGo所采用的三大技术支柱:树搜索(第4章)、神经网络(第5章至第8章)、深度学习机器人和强化学习(第9章至第12章)。
第4章概要介绍几种搜索和评估棋局序列的算法。我们将从简单的极小化极大搜索开始介绍,然后介绍更高级的算法,如α-β剪枝算法、蒙特卡洛树搜索等。
第5章是人工神经网络话题的实践性介绍。我们将讲述如何用Python从零开始实现一个神经网络,用来预测手写的数字字符。
第6章解释围棋数据与图像数据的共通特征,并引入卷积神经网络对落子动作进行预测。从本章开始,我们将基于深度学习库Keras来构建我们的模型。
第7章将应用第5章和第6章中学到的实践知识来构建一个由深度神经网络驱动的围棋机器人。我们使用业余高阶棋手的实盘数据进行训练,并分析这种方法的局限性。
第8章讲述如何实现一个围棋软件,让人类棋手能够通过用户界面与围棋机器人进行对弈。读者还将学会如何与其他机器人在本地或远程围棋服务器上进行对弈。
第9章涵盖强化学习的基础知识,并介绍如何在围棋中使用它进行自我对弈。
第10章详细介绍策略梯度的概念。它是改进第7章中落子动作预测的关键方法。
第11章展示如何使用所谓的价值评估方法来评估棋局。这个方法是一种可以与第4章介绍的树搜索相结合的强力工具。
第12章介绍预测给定棋局与下一手落子时预测评估其长期效果的技巧。这将有助于我们更有效地选择下一手落子动作。
第三部分是本书的最终部分,我们将把之前开发的所有部件整合起来,成为一个接近AlphaGo的应用。
第13章的内容无论从技术角度上看还是从数学角度上看,都是本书的巅峰。我们首先将讨论如何在围棋数据上训练神经网络(第5章至第7章),接着继续进行自我对弈(第8章至第11章),最后我们将结合一个更聪明的树搜索方法(第4章),创建超越人类极限的围棋机器人。
第14章是本书的最后一章,描述棋盘游戏AI的最前沿技术。我们深入探讨AlphaGo Zero背后的理论基础:开创性地将树搜索和强化学习相结合。
在附录中,我们还将涵盖下面几个话题。
附录A温习线性代数和微积分的一些基础知识,并展示如何在Python库NumPy中表示常用的线性代数结构。
附录B介绍反向传播算法。这个算法描述了大多数神经网络所采用的学习过程,从第5章开始,我们就一直需要用到它。附录B会详述更多关于这个算法的数学细节。
附录C为想要更深入了解围棋的读者提供一些在线资源。
附录D简要介绍如何在Amazon Web Services(AWS)上运行围棋机器人。
附录E展示如何将机器人连接到流行的围棋服务器上,这样就可以与世界各地的玩家进行对弈,并检验自己的成果了。
图0-1总结了各章对附录的依赖关系。
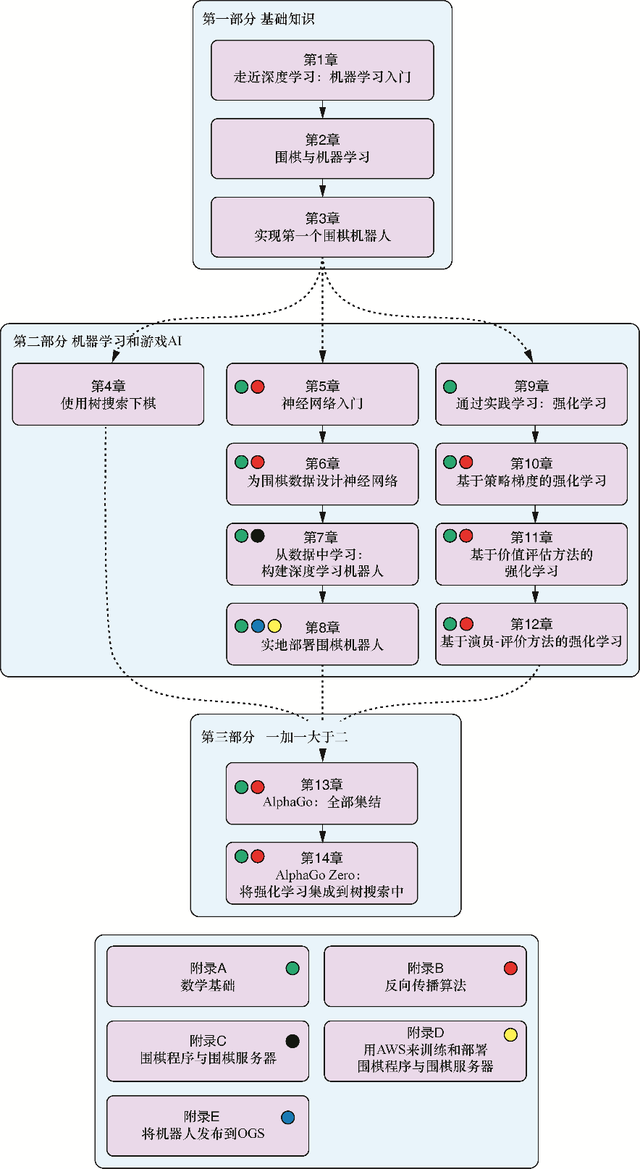
图0-1 各章对附录的依赖关系
详细目录
- 第 一部分 基础知识
- 第 1章 走近深度学习:机器学习入门 3
- 1.1 什么是机器学习 4
- 1.1.1 机器学习与AI的关系 5
- 1.1.2 机器学习能做什么,不能做什么 6
- 1.2 机器学习示例 7
- 1.2.1 在软件应用中使用机器学习 9
- 1.2.2 监督学习 11
- 1.2.3 无监督学习 12
- 1.2.4 强化学习 12
- 1.3 深度学习 13
- 1.4 阅读本书能学到什么 14
- 1.5 小结 15
- 第 2章 围棋与机器学习 16
- 2.1 为什么选择游戏 16
- 2.2 围棋快速入门 17
- 2.2.1 了解棋盘 17
- 2.2.2 落子与吃子 18
- 2.2.3 终盘与胜负计算 19
- 2.2.4 理解劫争 20
- 2.2.5 让子 20
- 2.3 更多学习资源 20
- 2.4 我们可以教会计算机什么 21
- 2.4.1 如何开局 21
- 2.4.2 搜索游戏状态 21
- 2.4.3 减少需要考虑的动作数量 22
- 2.4.4 评估游戏状态 22
- 2.5 如何评估围棋AI的能力 23
- 2.5.1 传统围棋评级 23
- 2.5.2 对围棋AI进行基准测试 24
- 2.6 小结 24
- 第3章 实现第 一个围棋机器人 25
- 3.1 在Python中表达围棋游戏 25
- 3.1.1 实现围棋棋盘 28
- 3.1.2 在围棋中跟踪相连的棋组:棋链 28
- 3.1.3 在棋盘上落子和提子 30
- 3.2 跟踪游戏状态并检查非法动作 32
- 3.2.1 自吃 33
- 3.2.2 劫争 34
- 3.3 终盘 36
- 3.4 创建自己的第 一个机器人:理论上最弱的围棋AI 37
- 3.5 使用Zobrist哈希加速棋局 41
- 3.6 人机对弈 46
- 3.7 小结 47
- 第二部分 机器学习和游戏AI
- 第4章 使用树搜索下棋 51
- 4.1 游戏分类 52
- 4.2 利用极小化极大搜索预测对手 53
- 4.3 井字棋推演:一个极小化极大算法的示例 56
- 4.4 通过剪枝算法缩减搜索空间 58
- 4.4.1 通过棋局评估减少搜索深度 60
- 4.4.2 利用α-β剪枝缩减搜索宽度 63
- 4.5 使用蒙特卡洛树搜索评估游戏状态 66
- 4.5.1 在Python中实现蒙特卡洛树搜索 69
- 4.5.2 如何选择继续探索的分支 72
- 4.5.3 将蒙特卡洛树搜索应用于围棋 74
- 4.6 小结 76
- 第5章 神经网络入门 77
- 5.1 一个简单的用例:手写数字分类 78
- 5.1.1 MNIST手写数字数据集 78
- 5.1.2 MNIST数据的预处理 79
- 5.2 神经网络基础 85
- 5.2.1 将对率回归描述为简单的神经网络 85
- 5.2.2 具有多个输出维度的神经网络 85
- 5.3 前馈网络 86
- 5.4 我们的预测有多好?损失函数及优化 89
- 5.4.1 什么是损失函数 89
- 5.4.2 均方误差 89
- 5.4.3 在损失函数中找极小值 90
- 5.4.4 使用梯度下降法找极小值 91
- 5.4.5 损失函数的随机梯度下降算法 92
- 5.4.6 通过网络反向传播梯度 93
- 5.5 在Python中逐步训练神经网络 95
- 5.5.1 Python中的神经网络层 96
- 5.5.2 神经网络中的激活层 97
- 5.5.3 在Python中实现稠密层 98
- 5.5.4 Python顺序神经网络 100
- 5.5.5 将网络集成到手写数字分类应用中 102
- 5.6 小结 103
- 第6章 为围棋数据设计神经网络 105
- 6.1 为神经网络编码围棋棋局 107
- 6.2 生成树搜索游戏用作网络训练数据 109
- 6.3 使用Keras深度学习库 112
- 6.3.1 了解Keras的设计原理 112
- 6.3.2 安装Keras深度学习库 113
- 6.3.3 热身运动:在Keras中运行一个熟悉的示例 113
- 6.3.4 使用Keras中的前馈神经网络进行动作预测 115
- 6.4 使用卷积网络分析空间 119
- 6.4.1 卷积的直观解释 119
- 6.4.2 用Keras构建卷积神经网络 122
- 6.4.3 用池化层缩减空间 123
- 6.5 预测围棋动作概率 124
- 6.5.1 在最后一层使用softmax激活函数 125
- 6.5.2 分类问题的交叉熵损失函数 126
- 6.6 使用丢弃和线性整流单元构建更深的网络 127
- 6.6.1 通过丢弃神经元对网络进行正则化 128
- 6.6.2 线性整流单元激活函数 129
- 6.7 构建更强大的围棋动作预测网络 130
- 6.8 小结 133
- 第7章 从数据中学习:构建深度学习机器人 134
- 7.1 导入围棋棋谱 135
- 7.1.1 SGF文件格式 136
- 7.1.2 从KGS下载围棋棋谱并复盘 136
- 7.2 为深度学习准备围棋数据 137
- 7.2.1 从SGF棋谱中复盘围棋棋局 138
- 7.2.2 构建围棋数据处理器 139
- 7.2.3 构建可以高效地加载数据的围棋数据生成器 146
- 7.2.4 并行围棋数据处理和生成器 147
- 7.3 基于真实棋局数据训练深度学习模型 148
- 7.4 构建更逼真的围棋数据编码器 152
- 7.5 使用自适应梯度进行高效的训练 155
- 7.5.1 在SGD中采用衰减和动量 155
- 7.5.2 使用Adagrad优化神经网络 156
- 7.5.3 使用Adadelta优化自适应梯度 157
- 7.6 运行自己的实验并评估性能 157
- 7.6.1 测试架构与超参数的指南 158
- 7.6.2 评估训练与测试数据的性能指标 159
- 7.7 小结 160
- 第8章 实地部署围棋机器人 162
- 8.1 用深度神经网络创建动作预测代理 163
- 8.2 为围棋机器人提供Web前端 165
- 8.3 在云端训练与部署围棋机器人 169
- 8.4 与其他机器人对话:围棋文本协议 170
- 8.5 在本地与其他机器人对弈 172
- 8.5.1 机器人应该何时跳过回合或认输 172
- 8.5.2 让机器人与其他围棋程序进行对弈 173
- 8.6 将围棋机器人部署到在线围棋服务器 178
- 8.7 小结 182
- 第9章 通过实践学习:强化学习 183
- 9.1 强化学习周期 184
- 9.2 经验包括哪些内容 185
- 9.3 建立一个有学习能力的代理 188
- 9.3.1 从某个概率分布中进行抽样 189
- 9.3.2 剪裁概率分布 190
- 9.3.3 初始化一个代理实例 191
- 9.3.4 在磁盘上加载并保存代理 191
- 9.3.5 实现动作选择 193
- 9.4 自我对弈:计算机程序进行实践训练的方式 194
- 9.4.1 经验数据的表示 194
- 9.4.2 模拟棋局 197
- 9.5 小结 199
- 第 10章 基于策略梯度的强化学习 200
- 10.1 如何在随机棋局中识别更佳的决策 201
- 10.2 使用梯度下降法修改神经网络的策略 204
- 10.3 使用自我对弈进行训练的几个小技巧 208
- 10.3.1 评估学习的进展 208
- 10.3.2 衡量强度的细微差别 209
- 10.3.3 SGD优化器的微调 210
- 10.4 小结 213
- 第 11章 基于价值评估方法的强化学习 214
- 11.1 使用Q学习进行游戏 214
- 11.2 在Keras中实现Q学习 218
- 11.2.1 在Keras中构建双输入网络 218
- 11.2.2 用Keras实现ε贪婪策略 222
- 11.2.3 训练一个行动-价值函数 225
- 11.3 小结 226
- 第 12章 基于演员-评价方法的强化学习 227
- 12.1 优势能够告诉我们哪些决策更加重要 227
- 12.1.1 什么是优势 228
- 12.1.2 在自我对弈过程中计算优势值 230
- 12.2 为演员-评价学习设计神经网络 232
- 12.3 用演员-评价代理下棋 234
- 12.4 用经验数据训练一个演员-评价代理 235
- 12.5 小结 240
- 第三部分 一加一大于二
- 第 13章 AlphaGo:全部集结 243
- 13.1 为AlphaGo训练深度神经网络 245
- 13.1.1 AlphaGo的网络架构 246
- 13.1.2 AlphaGo棋盘编码器 248
- 13.1.3 训练AlphaGo风格的策略网络 250
- 13.2 用策略网络启动自我对弈 252
- 13.3 从自我对弈数据衍生出一个价值网络 254
- 13.4 用策略网络和价值网络做出更好的搜索 254
- 13.4.1 用神经网络改进蒙特卡洛推演 255
- 13.4.2 用合并价值函数进行树搜索 256
- 13.4.3 实现AlphaGo的搜索算法 258
- 13.5 训练自己的AlphaGo可能遇到的实践问题 263
- 13.6 小结 265
- 第 14章 AlphaGo Zero:将强化学习集成到树搜索中 266
- 14.1 为树搜索构建一个神经网络 267
- 14.2 使用神经网络来指导树搜索 268
- 14.2.1 沿搜索树下行 271
- 14.2.2 扩展搜索树 274
- 14.2.3 选择一个动作 276
- 14.3 训练 277
- 14.4 用狄利克雷噪声改进探索 281
- 14.5 处理超深度神经网络的相关最新技术 282
- 14.5.1 批量归一化 282
- 14.5.2 残差网络 283
- 14.6 探索额外资源 284
- 14.7 结语 285
- 14.8 小结 285
- 附录A 数学基础 286
- 附录B 反向传播算法 293
- 附录C 围棋程序与围棋服务器 297
- 附录D 用AWS来训练和部署围棋程序与围棋服务器 300
- 附录E 将机器人发布到OGS 307

作者简介
马克斯•帕佩拉(Max Pumperla)就职于Skymind公司,是一名专职研究深度学习的数据科学家和工程师。他是深度学习平台Aetros的联合创始人。
凯文•费格森(Kevin Ferguson)在分布式系统和数据科学领域拥有18年的工作经验。他是Honor公司的数据科学家,曾就职于谷歌和Meebo等公司。
Max和Kevin是BetaGo的共同创造者。BetaGo是用Python开发的极少数开源围棋机器人之一。
关于阿尔法围棋
阿尔法围棋(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人,由谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。其主要工作原理是“深度学习”。
2016年3月,阿尔法围棋与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册账号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;2017年5月,在中国乌镇围棋峰会上,它与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平,在GoRatings网站公布的世界职业围棋排名中,其等级分曾超过排名人类第一的棋手柯洁。
2017年5月27日,在柯洁与阿尔法围棋的人机大战之后,阿尔法围棋团队宣布阿尔法围棋将不再参加围棋比赛。2017年10月18日,DeepMind团队公布了最强版阿尔法围棋,代号AlphaGo Zero。
2017年7月18日,教育部、国家语委在北京发布《中国语言生活状况报告(2017)》,“阿尔法围棋”入选2016年度中国媒体十大新词。——来自百度

