
- 1Transformer 理解Tokenizer_transformer tokenizer
- 2Python学习笔记(五):数据类型之 String_python rstring
- 3人工智能和python之间有什么联系?为何用python?
- 4ChatGPT:如何运用强大的自然语言处理技术撰写高质量论文
- 5Python自然语言处理 NLTK 库用法入门教程【经典】_python nltk combine函数的用法
- 6a-upload——实现上传功能——基础积累_a-upload 上传
- 7基于T5的模型微调以及对应的数据介绍_t5模型微调
- 8MySql概述及其性能说明_大量使用mysql,性能能否支撑后续发展,文档如何解释
- 9pytorch初学笔记(六):DataLoader的使用_pytorch dataloader
- 10剪辑师和小白都能用的AI解说神器,一键把短剧变解说视频-手把手教程-2024_ai解说短剧自动剪辑
深度学习500问——Chapter06: 循环神经网络(RNN)(1)
赞
踩
文章目录
6.1 为什么需要RNN
时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的神经网络,在训练数据足够、算法模型优越的情况下,给定特定的x,就能得到期望y。其一般处理单个的输入,前一个输入和后一个输入完全无关,但实际应用中,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如:
当我们在理解一句话意思时,孤立的理解这句话的每个词不足以理解整体意思,我们通常需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就由此诞生了。
6.2 图解RNN基本结构
6.2.1 基本的单层网络结构
在进一步了解RNN之前,先给出最基本的单层网络结构,输入是,经过变换
和激活函数
得到输出
:
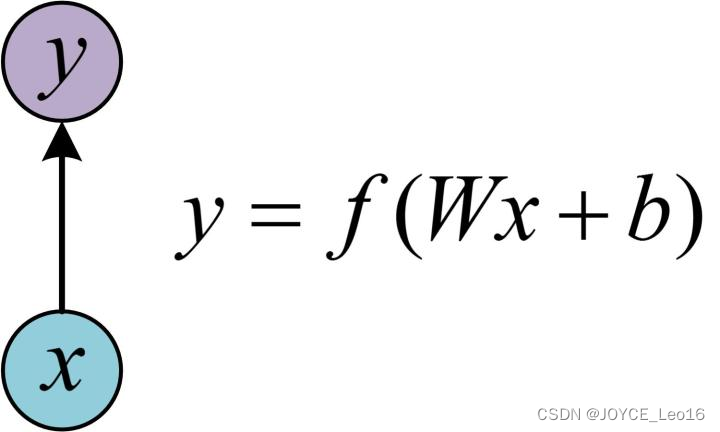
6.2.2 图解经典RNN结构
在实际应用中,我们还会遇到很多序列形的数据。如:
- 自然语言处理问题。
可以看作是第一个单词,
可以看作是第二个单词,依次类推。
- 语音处理。此时,
是每帧的声音。
- 时间序列问题。例如每天的股票价格等等。
其单个序列如下图所示:

前面介绍了诸如此类的序列数据用原始的神经网络难以建模,基于此,RNN引入了隐状态(hidden state),
可对序列数据提取特征,接着再转换为输出。
为了便于理解,先计算:
注:图中的圆圈表示向量,箭头表示对向量做变换。
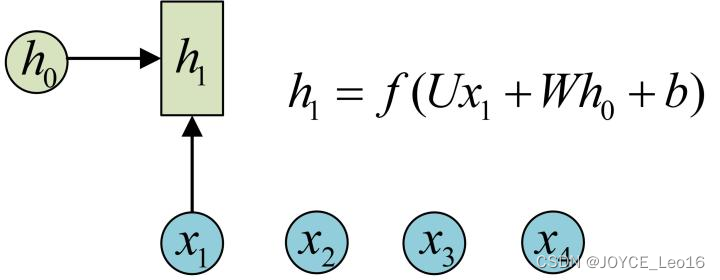
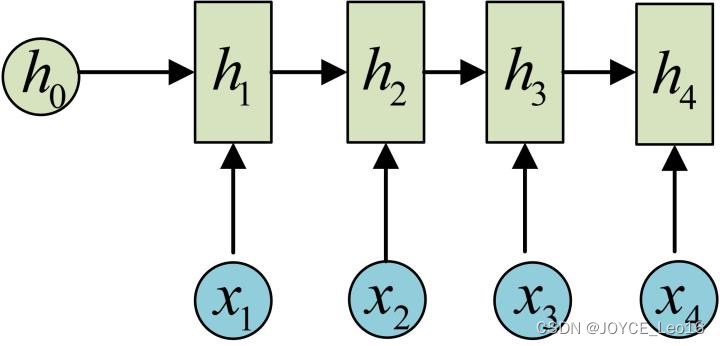
RNN中,每个步骤使用的参数相同,
的计算方式和
类似,其计算结果如下:

计算也相似,可得:
接下来,计算RNN的输出,采用Softmax作为激活函数,根据
,得
:
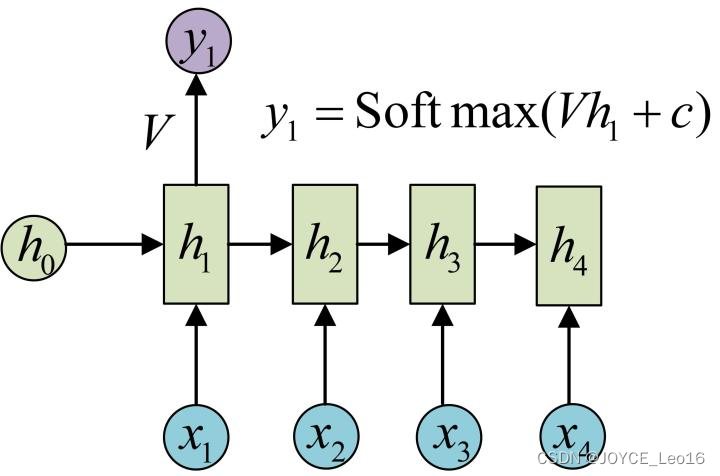
使用和相同的参数
,得到
的输出结构:

以上即为最经典的RNN结构,其输入为,输出为
,当然实际中最大值为
,这里为了便于理解和展示,只计算4个输入和输出。从以上结构可看出,RNN结构的输入和输出等长。
6.2.3 vector-to-sequence结构
有时我们要处理的问题输入是一个单独的值,输出是一个序列。此时,有两种主要建模方式:
方式一:可只在其中的某一个序列进行计算,比如序列第一个进行输入计算,其建模方式如下:

方式二:把输入信息 X 作为每个阶段的输入,其建模方式如下:

6.2.4 sequence-to-vector结构
有时我们要处理的问题输入是一个序列,输出是一个单独的值,此时通常在最后的一个序列上进行输出变换。其建模如下所示:

6.2.5 Encoder-Decoder结构
原始的sequence-to-sequence结构的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往没有相同的长度。
其建模步骤如下:
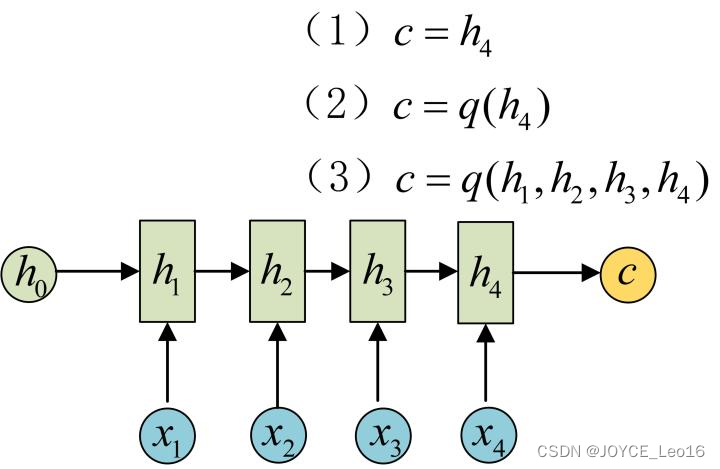
步骤1:将输入数据编码成一个上下文向量,这部分称为Encoder,得到的
有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给
,还可以对最后的隐状态做一个变换得到
,也可以对所有的隐状态做变换。其示意如下所示:
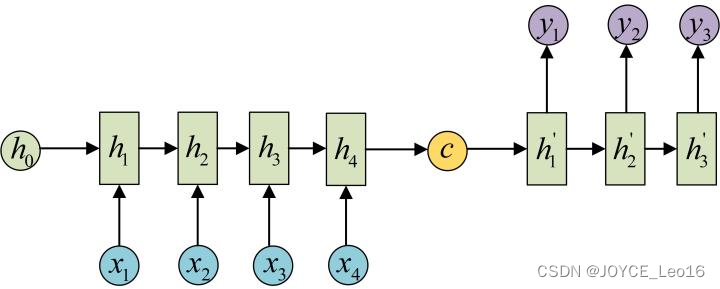
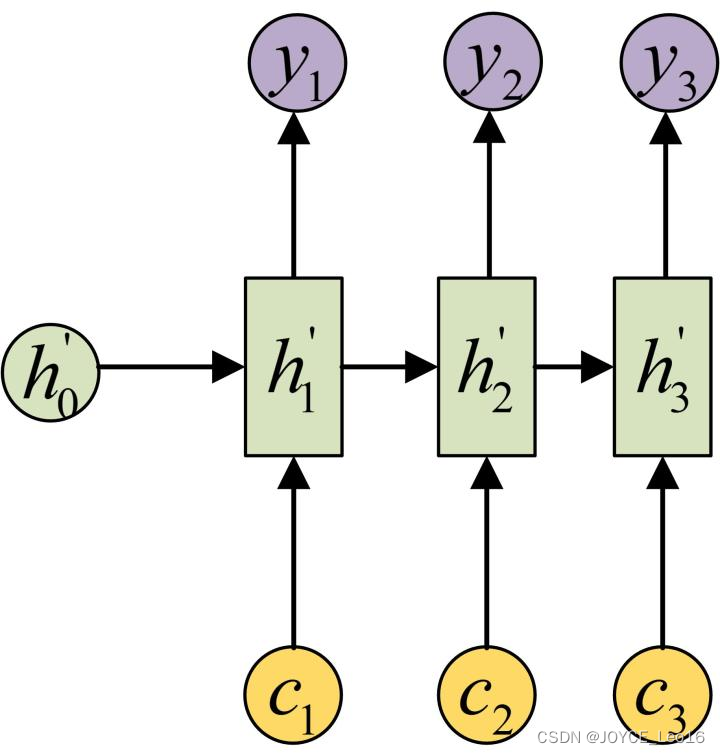
步骤2:用另一个RNN网络(我们将其称为Decoder)对其进行编码。
方法一是将步骤1中的作为初始状态输入到Decoder,示意图如下所示:
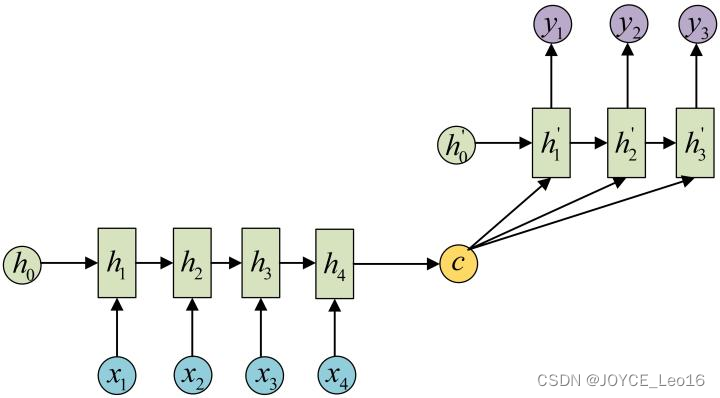
方法二是将作为Decoder的每一步输入,示意图如下所示:
6.2.6 以上三种结构各有怎样的应用场景
| 网络结构 | 结构图示 | 应用场景举例 |
|---|---|---|
| 1 vs N | 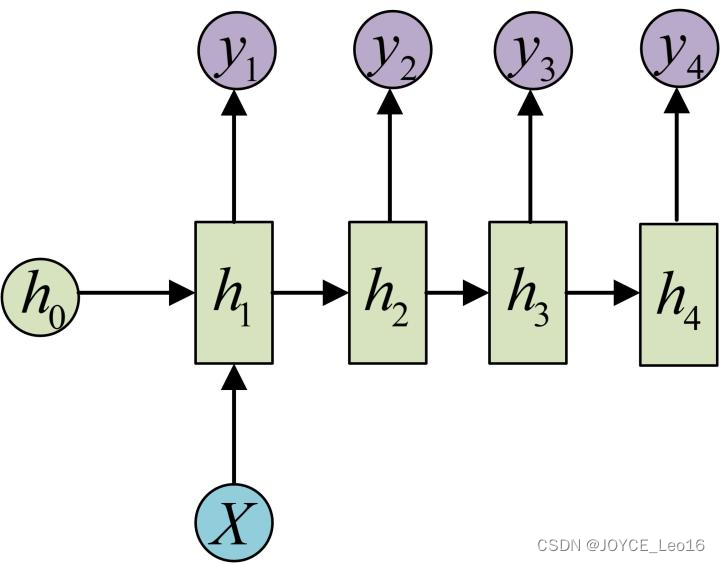 | 1、从图像生成文字,输入为图像的特征,输出为一段句子 2、根据图像生成语音或音乐,输入为图像特征,输出为一段语音或音乐 |
| N vs 1 | 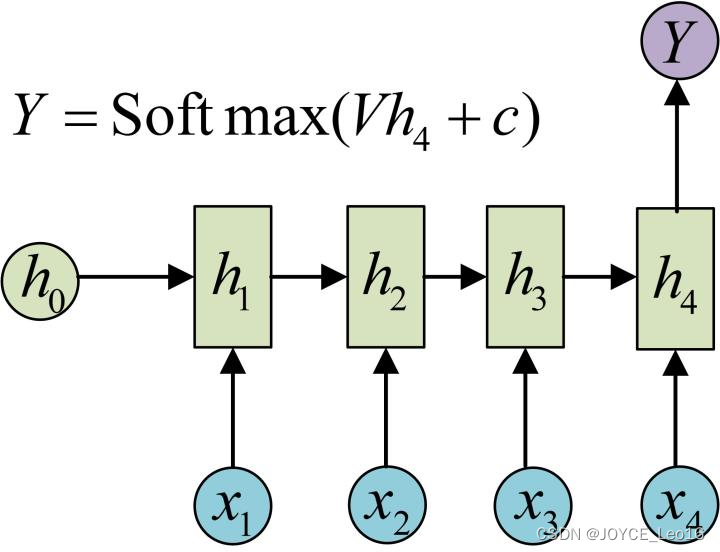 | 1、输出一段文字,判断其所属类别 2、输入一个句子,判断其情感倾向 3、输入一段视频,判断其所属类别 |
| N vs M | 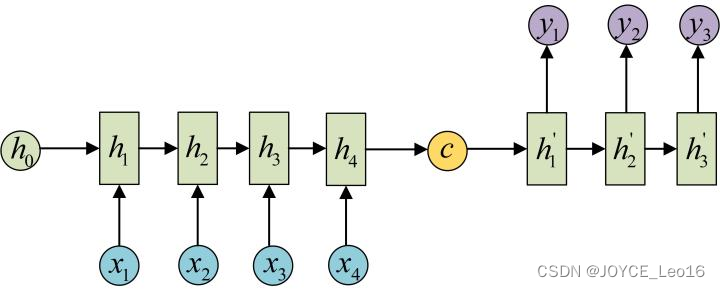 | 1、机器翻译,输入一种语言文本序列,输出另一种语言文本序列 2、文本摘要,输入文本序列,输出这段文本序列摘要 3、阅读理解,输入文章,输出问题答案 4、语音识别,输入语音序列信息,输出文字序列 |
6.2.7 图解RNN中的Attention机制
在上述通用的Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征再解码,因此,
中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个
可能存不下那么多信息,就会造成翻译精度的下降。Attention机制通过在每个时间输入不同的
来解决此问题。
引入了Attention机制的Decoder后,有不同的,每个
会自动选择与当前输出最匹配的上下文信息,其示意图如下所示:
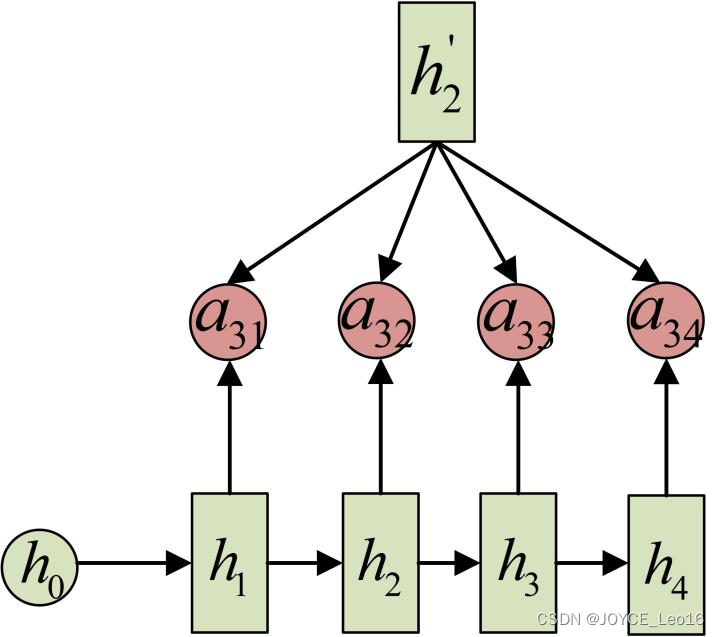
举例:比如输入序列是“我爱中国”,要将此输入翻译成英文:
假如用衡量Encoder中第
阶段的
和解码时第
阶段的相关性,
从模型中学习得到,和Decoder的第
阶段的隐状态、Encoder第
个阶段的隐状态有关,比如
的计算示意如下所示:
最终Decoder中第阶段的输入的上下文信息
来自所有
对
的加权和。
其示意图如下图所示:
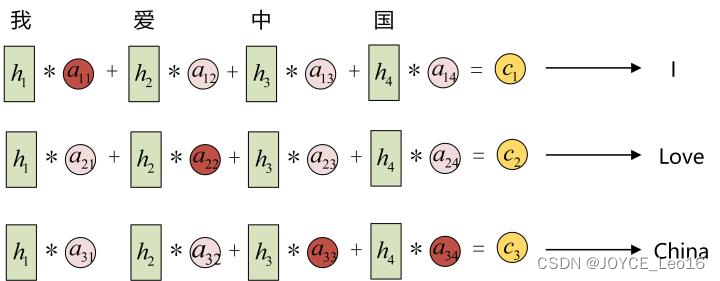
在Encoder中,分别代表“我”,“爱”,“中”,“国”所代表信息。翻译的过程中,
会选择和“我”最相关的上下午信息,如上图所示,会优先选择
,以此类推,
会优先选择相关性较大的
,
会优先选择相关性较大的
,这就是Aattention机制。
6.3 RNNs典型特点
1、RNN主要用于处理序列数据。对于传统的神经网络模型,从输入层到隐含层再到输出层,层与层之间一般为全连接,每层之间神经元是无连接的。但是传统神经网络无法处理数据间的前后关联问题。例如,为了预测句子的下一个单词,一般需要该词之前的语义信息。这是因为一个句子中前后单词是存在语义联系的。
2、RNNs中当前单元的输出与之前步骤输出也有关,因此称之为循环神经网络。具体的表现形式为当前单元会对之前步骤信息进行存储并应用与当前输出的计算中。隐藏层之间的节点连接起来,隐藏层当前输出由当前时刻输入向量和之前时刻隐藏层状态共同决定。
3、标准的RNNs结构图中,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。
4、在标准的RNN结构中。隐藏层的神经元之间也是带有权值的,且权值共享。
5、理论上,RNNs能够对任何长度序列数据进行处理。但是在实践中,为了降低复杂度往往假设当前状态只与之前某几个时刻状态相关,下图便是一个典型的RNNs:

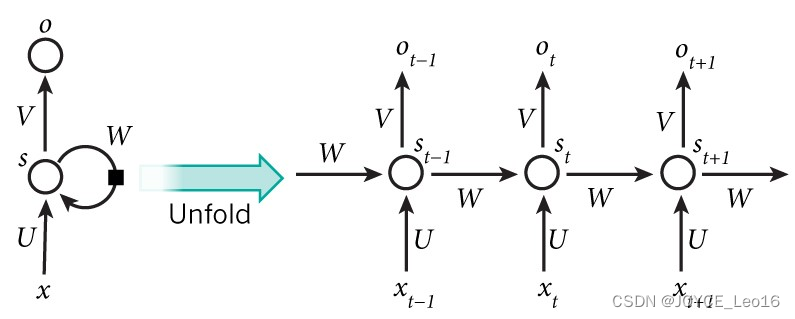
- 输入单元(Input units):输入集
,
- 输出单元(Output units):输出集
,
- 隐藏单元(Hidden units):输出集
。
图中信息传递特点:
- 一条单向流动的信息流是从输入单元到隐藏单元。
- 一条单向流动的信息流从隐藏单元到输出单元。
- 在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”。
- 当前单元(cell)输出是由当前时刻输入和上一时刻隐藏层状态共同决定。

