
- 1Java数据结构————List_java实体类 list
- 2【学习】在软件测试中,如何构建精准测试体系
- 3计算机系统软件最核心软件是,华为鸿蒙操作系统HarmonyOS全景研究与解构
- 4【愚公系列】2024年03月 《AI智能化办公:ChatGPT使用方法与技巧从入门到精通》 003-ChatGPT是什么(关于AIGC、OpenAl和 ChatGPT)
- 5对OpenHarmony中LiteOS的内核分析——超时原理和应用_liteos_m 休眠
- 6OpenHarmony 关闭息屏方式总结_openharmony 设置不息屏
- 7一步步下载并安装VMwaer Workstation player,个人免费虚拟机_vmware workstation player下载
- 8【海思AI芯片Hi3559A】学习笔记(2):编译osdrv、单独编译uboot和kernel_海思3559a编译内核 生成分区表
- 9计算机毕业设计PHP基于微信小程序的商城设计(源码+程序+uni+lw+部署)_微信小程序商超 php+mysql 毕业论文
- 10在VMware虚拟机主机模式下与主机互相ping通的方法_vmware和主机怎样才能ping通
【基础算法 】文本相似度计算_文本相似度匹配算法
赞
踩
在自然语言处理中,文本相似度是一种老生常谈而又应用广泛的基础算法模块,可用于地址标准化中计算与标准地址库中最相似的地址,也可用于问答系统中计算与用户输入问题最相近的问题及其答案,还可用于搜索中计算与输入相近的结果,扩大搜索召回,等等。
基于此,现将几种常见的文本相似度计算方法做一个简单总结,以便后续查阅,本文所有源码均已上传到github。
1.字符串相似度
字符串相似度指的是比较两个文本相同字符个数,从而得出其相似度。
python为我们提供了一个difflib包用于计算两个文本序列的匹配程度,我们可以将其视为两个文本字符串的相似度,其代码实现很简单,如果需要得到两个文本之间相同部分或不同部分,可参考Github:https://github.com/tianyunzqs/pynotes/tree/master/text_diff
import difflib
difflib.SequenceMatcher(None, string1, string2).ratio()
- 1
- 2
2.simhash相似度
simhash最早是由google在文章《detecting near-duplicates for web crawling》中提出的一种用于网页去重的算法。simhash是一种局部敏感hash,计算速度快,对海量网页文本可实现快速处理。
以下内容主要来源于:https://www.cnblogs.com/xlturing/p/6136690.html,介绍通俗易懂,故摘抄过来。
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相似,当然我们降维生成了hash签名也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hash却不行。
我们可以来做个测试,两个相差只有一个字符的文本串,
“你妈妈喊你回家吃饭哦,回家罗回家罗”
“你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
0001000001100110100111011011110
1010010001111111110010110011101通过上面的例子我们可以很清晰的发现simhash的局部敏感性,相似文本只有部分01变化,而hash值很明显,即使变化很小一部分,也会相差很大。
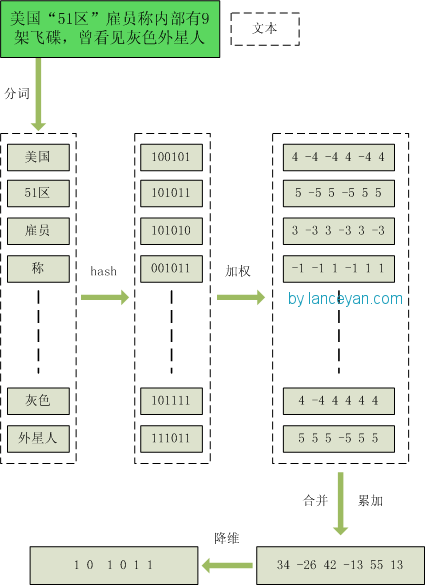
基本流程
- 分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4±5 -4+5 4±5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图为:
simhash的主要思想是将高维的特征向量(文本可转换为高维向量表示)映射成低维的特征向量,通过计算两个向量的汉明距离(Hamming Distance)来确定文本的相似度。
其中,汉明距离,表示在两个等长字符串中对应位置不同字符的个数。如,1011100 与 1001000 之间的汉明距离是 2。而字符串的编辑距离则是汉明距离的扩展。
根据以上simhash算法的流程描述,利用tfidf值表示词语的权重,实现simhash计算文本相似度代码如下
# -*- coding: utf-8 -*- # @Time : 2019/6/25 15:58 # @Author : tianyunzqs # @Description : import codecs import numpy as np import jieba.posseg as pseg def load_stopwords(path): return set([line.strip() for line in open(path, "r", encoding="utf-8").readlines() if line.strip()]) stopwords = load_stopwords(path='stopwords.txt') def string_hash(source): if not source: return 0 x = ord(source[0]) << 7 m = 1000003 mask = 2 ** 128 - 1 for c in source: x = ((x * m) ^ ord(c)) & mask x ^= len(source) if x == -1: x = -2 x = bin(x).replace('0b', '').zfill(64)[-64:] return str(x) def load_idf(path): words_idf = dict() with codecs.open(path, 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: parts = line.strip().split('\t') if len(parts) != 2: continue if parts[0] not in words_idf: words_idf[parts[0]] = float(parts[1]) return words_idf words_idf = load_idf(path=r'idf.txt') def compute_tfidf(text): words_freq = dict() words = pseg.lcut(text) for w in words: if w.word in stopwords: continue if w.word not in words_freq: words_freq[w.word] = 1 else: words_freq[w.word] += 1 text_total_words = sum(list(words_freq.values())) words_tfidf = dict() for word, freq in words_freq.items(): if word not in words_idf: continue else: tfidf = words_idf[word] * (freq / text_total_words) words_tfidf[word] = tfidf return words_tfidf def get_keywords(text, topk): words_tfidf = compute_tfidf(text) words_tfidf_sorted = sorted(words_tfidf.items(), key=lambda x: x[1], reverse=True) return [item[0] for item in words_tfidf_sorted[:topk]] def hamming_distance(simhash1, simhash2): ham = [s1 == s2 for (s1, s2) in zip(simhash1, simhash2)] return ham.count(False) def text_simhash(text): total_sum = np.array([0 for _ in range(64)]) keywords = get_keywords(text, topk=2) for keyword in keywords: v = int(words_idf[keyword]) hash_code = string_hash(keyword) decode_vec = [v if hc == '1' else -v for hc in hash_code] total_sum += np.array(decode_vec) simhash_code = [1 if t > 0 else 0 for t in total_sum] return simhash_code def simhash_similarity(text1, text2): simhash_code1 = text_simhash(text1) simhash_code2 = text_simhash(text2) print(simhash_code1, simhash_code2) return hamming_distance(simhash_code1, simhash_code2) if __name__ == '__main__': print(simhash_similarity('在历史上有著许多数学发现', '在历史上有著许多科学发现'))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
而simhash算法已有对应python包——simhash,安装即可实现simhash相似度计算
pip install simhash
- 1
利用simhash包,计算文本相似度示例代码
# -*- coding: utf-8 -*- # @Time : 2019/6/25 15:58 # @Author : tianyunzqs # @Description : from simhash import Simhash def simhash_similarity(text1, text2): """ :param text1: 文本1 :param text2: 文本2 :return: 返回两篇文章的相似度 """ aa_simhash = Simhash(text1) bb_simhash = Simhash(text2) max_hashbit = max(len(bin(aa_simhash.value)), (len(bin(bb_simhash.value)))) # 汉明距离 distince = aa_simhash.distance(bb_simhash) similar = 1 - distince / max_hashbit return similar if __name__ == '__main__': print(simhash_similarity('在历史上有著许多数学发现', '在历史上有著许多科学发现'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.word2vec相似度
word2vec是对词语进行向量化的一种无监督算法,具体介绍与tensorflow实现可参考:【基础算法】word2vec词向量
word2vec相似度是指利用word2vec算法将文本向量化,进而利用余弦距离计算两个向量的余弦相似度作为两字符串的相似度。
def sentence_similarity_word2vec(self, sentence1, sentence2):
sentence1 = sentence1.strip()
sentence2 = sentence2.strip()
if sentence1 == sentence2:
return 1.0
vec1 = self.get_sentence_vector(sentence1)
vec2 = self.get_sentence_vector(sentence2)
return self.cosine_similarity(vec1, vec2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
word2vec对文本的向量化是将文本分词后,得到各词语的向量化表示,然后对向量的每个维度进行加权相加,形成文本向量,进而可利用余弦距离计算文本的相似度。
def get_sentence_vector(self, sentence):
words = self.text_segment(sentence)
words_vec = [self.get_word_vector(word) for word in words]
return np.mean(words_vec, axis=0)
@staticmethod
def cosine_similarity(vec1, vec2):
tmp1, tmp2 = np.dot(vec1, vec1), np.dot(vec2, vec2)
if tmp1 and tmp2:
return np.dot(vec1, vec2) / (np.sqrt(tmp1) * np.sqrt(tmp2))
return 0.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
完整代码,可参考Github
4.神经网络相似度
利用神经网络进行相似度计算的一种思路是将输入X编码为中间向量V,然后对中间结果进行解码得到输出Y,其中损失函数的计算方式就是尽可能减少X与Y之间的偏差,理想情况就是中间向量V能完全解码还原为原始输入X。网络训练完成后,我们也就得到了输入句子所表示的语义特征向量。
根据上述思路,我们自然可以联想到最基础的自编码器(AutoEncoder, AE),当然还有其他更复杂的自编码器( 如:栈式自编码器(Stacked Autoencoder, SAE)、变分自编码器(Variational auto-encoder, VAE)等)。
AutoEncoder能很好的编码句子中所包含的语义信息,可以在一定程度上解决字符串相似度计算中所缺乏的语义理解问题和word2vec相似度计算中所缺乏的词序问题。本文基于tensorflow实现了基础版本的自编码器,模型代码如下,完整的项目代码可参考Github
class AutoEncoder(object): def __init__(self, embedding_size, num_hidden_layer, hidden_layers): assert num_hidden_layer == len(hidden_layers), 'num_hidden_layer not match hidden_layers' self.embedding_size = embedding_size self.num_hidden_layer = num_hidden_layer self.hidden_layers = hidden_layers self.input_x = tf.placeholder(tf.float32, [None, embedding_size]) new_hidden_layers1 = [embedding_size] + hidden_layers + hidden_layers[::-1][1:] new_hidden_layers2 = hidden_layers + hidden_layers[::-1][1:] + [embedding_size] encoder_weights, encoder_biases, decoder_weights, decoder_biases = [], [], [], [] for i, (hidden1, hidden2) in enumerate(zip(new_hidden_layers1, new_hidden_layers2)): if i < int(len(new_hidden_layers1) / 2.0): encoder_weights.append(tf.Variable(tf.random_normal([hidden1, hidden2]))) encoder_biases.append(tf.Variable(tf.random_normal([hidden2]))) else: decoder_weights.append(tf.Variable(tf.random_normal([hidden1, hidden2]))) decoder_biases.append(tf.Variable(tf.random_normal([hidden2]))) with tf.name_scope('output'): self.encoder_output = self.encoder_or_decode(self.input_x, encoder_weights, encoder_biases) self.decoder_output = self.encoder_or_decode(self.encoder_output, decoder_weights, decoder_biases) with tf.name_scope('loss'): self.loss = tf.reduce_mean(tf.pow(self.input_x - self.decoder_output, 2)) self.global_step = tf.Variable(0, name="global_step", trainable=False) tf.summary.scalar('loss', self.loss) self.merge_summary = tf.summary.merge_all() self.saver = tf.train.Saver() @staticmethod def encoder_or_decode(input_data, encoder_weights, encoder_biases): layer_output = [input_data] for weight, biase in zip(encoder_weights, encoder_biases): layer_output.append(tf.nn.sigmoid(tf.add(tf.matmul(layer_output[-1], weight), biase))) return layer_output[-1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40

