
- 1Spark笔记10之SparkSQL_请分析spark sql出现的原因
- 2oracle等值连接与innerjoin,inner join(等值联接)、left join(左联接)、right join(右联接)用法及区别...
- 3Vue 常用指令 v-for 标签循环展示数据_v-for item unused
- 4【Redis】三种持久化机制?RDB、AOF、混合?这下弄明白了_持久化的机制有哪些机制呢?
- 5tensorflow2.2实现ResNeXt_使用tensorflow来实现分类神经网络resnext,resnext模型设计和原理需要自己查
- 6浅谈web前端常用的三大主流框架_前端三大框架会几个
- 7prompt工程
- 8LSTM文本情感分类在Deeplearning4j+spark环境中的scala实践_deeplearning4j 情感分类
- 9【AI数字人-论文】Geneface论文
- 10Linux | firewall命令 对外开放端口、查看端口、防火墙开启、防火墙关闭_firewall开放所有端口
C++ 使用哈希表封装模拟实现unordered_map unordered_set_c++ unordered_set使用什么数据结构
赞
踩
一、unordered_map unordered_set 和 map set的区别
1. map set底层采取的红黑树的结构,unordered_xxx 底层数据结构是哈希表。unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
2. Java中对应的容器名为 HashMap HashSet TreeMap TreeSet,命名方面比C++好了很多。主要是早期C++并没有实现哈希结构的容器(C++11之前),也就是unordered系列,在C++11中新增了unordered_map,unordered_set,unordered_multimap,unordered_multiset,故因为历史命名问题,取了这样的名字。
3. 它们的使用大体上几乎一致。显著的差别是:
a、map和set为双向迭代器,unordered_xxx和是单向迭代器。
b、map和set存储为有序存储(红黑树结构,中序遍历有序),unordered_xxx为无序存储(哈希表的结构致使)
4. 性能差异:采取哈希表的unordered系列容器在大量数据的增删查改效率更优,尤其是查(搜索)
二、实现代码
HashTable.h
- //
- // Created by yangzilong on 2022/11/15.
- //
- #pragma once
- #include <utility>
- #include <vector>
- #include <iostream>
- using namespace std;
-
- // 开散列(链地址法)解决哈希表中的哈希冲突
-
- // 哈希表中的结点并不知道自己存储的数据类型,unordered_map为pair,unordered_set为key
- template <class T>
- struct HashNode
- {
- HashNode<T>(const T& data)
- :_data(data)
- { }
- T _data;
- HashNode* _next = nullptr;
- };
-
- // 哈希表的前置声明,因为迭代器中要用到
- template <class , class , class , class , class >
- class HashTable;
-
- // 哈希表迭代器,因为数据成员中有哈希表指针,所以这些模板参数都需要
- template <class K, class T, class KeyOfT, class Hash, class Equal>
- struct __HashTable_Iterator
- {
- typedef HashNode<T> Node;
- typedef HashTable<K, T, KeyOfT, Hash, Equal> HT;
- typedef __HashTable_Iterator<K, T, KeyOfT, Hash, Equal> Self;
-
- __HashTable_Iterator(Node* node, HT* ptr)
- : _node(node), _tablePtr(ptr)
- { }
-
- bool operator==(const Self& it) const {
- return _node == it._node;
- }
-
- bool operator!=(const Self& it) const {
- return _node != it._node;
- }
-
- T& operator*() const {
- return _node->_data;
- }
-
- T* operator->() const {
- return &_node->_data;
- }
-
- // unordered_map unordered_set为单向迭代器
- Self& operator++() {
- // 前置++
- if(_node->_next)
- _node = _node->_next;
- else {
- KeyOfT kot;
- Hash hash;
- size_t hashAddress = hash(kot(_node->_data)) % _tablePtr->_table.size();
- ++hashAddress;
- _node = nullptr;
- while(hashAddress < _tablePtr->_table.size() && (_node = _tablePtr->_table[hashAddress]) == nullptr)
- ++hashAddress;
- // while(hashAddress < _tablePtr->_table.size() && _tablePtr->_table[hashAddress] == nullptr)
- // ++hashAddress;
- // if(hashAddress == _tablePtr->_table.size()) //
- // _node = nullptr;
- // else
- // _node = _tablePtr->_table[hashAddress];
- }
- return *this;
- }
- Self operator++(int) {
- Self ret = *this;
- ++*this;
- return ret;
- }
- // 每个迭代器中的数据成员
- Node* _node;
- HashTable<K, T, KeyOfT, Hash, Equal>* _tablePtr; // 存储对应哈希表的指针
- };
-
- // 第一个参数为关键字,用于Find。第二个参数为开散列哈希表中每个结点存储的数据类型
- template <class K, class T, class KeyOfT, class Hash, class Equal>
- class HashTable
- {
- // 迭代器中要用到哈希表的私有数据成员,即那个哈希表(vector)的长度。
- template <typename A, class B, class C, class D, class E>
- friend struct __HashTable_Iterator;
-
- typedef HashNode<T> Node;
- public:
- typedef __HashTable_Iterator<K, T, KeyOfT, Hash, Equal> iterator;
-
- iterator begin() {
- for(size_t i = 0; i < _table.size(); ++i) {
- if(_table[i])
- return iterator(_table[i], this);
- }
- return end();
- }
-
- iterator end() {
- return iterator(nullptr, this);
- }
-
- ~HashTable() {
- for(auto& ptr : _table) {
- Node* cur = ptr;
- while(cur) {
- Node* next = cur->_next;
- delete cur;
- cur = next;
- }
- ptr = nullptr;
- }
- }
-
- pair<iterator, bool> Insert(const T& data) {
- KeyOfT kot;
- iterator it = Find(kot(data));
- if(it != end())
- return make_pair(it, false);
- Hash convert;
-
- // 负载因子到1就扩容
- if(_table.size() == 0 || 10 * _size / _table.size() >= 10) {
- // 开散列法哈希表扩容
- vector<Node*> newTable;
- size_t newSize = _table.size() == 0 ? 10 : _table.size()*2;
- newTable.resize(newSize);
- for(size_t i = 0; i < _table.size(); ++i) {
- Node* cur = _table[i];
- while(cur) {
- Node* next = cur->_next;
- size_t hashAddress = convert(kot(cur->_data)) % newTable.size();
- cur->_next = newTable[hashAddress];
- newTable[hashAddress] = cur;
- cur = next;
- }
- _table[i] = nullptr;
- // if(_table[i]) {
- // Node* cur = _table[i];
- // Node* next = cur->_next;
- // while(cur) {
- // size_t hashAddress = convert(cur->_kv.first) % newTable.size();
- // cur->_next = newTable[hashAddress];
- // newTable[hashAddress] = cur;
- // cur = next;
- // if(cur)
- // next = cur->_next;
- // }
- // // 也没必要其实
- // _table[i] = nullptr;
- // }
- }
- _table.swap(newTable);
- }
- // 通过哈希函数求哈希地址
- size_t hashAddress = convert(kot(data)) % _table.size();
- Node* ptr = _table[hashAddress];
- Node* newNode = new Node(data);
- // 每个哈希桶中进行头插
- newNode->_next = ptr;
- _table[hashAddress] = newNode;
- ++_size;
- return make_pair(iterator(newNode, this), true);
- }
-
- // 用到了第一个模板参数
- iterator Find(const K& key) {
- Equal equal;
- if(_table.size() == 0) {
- return end();
- }
- KeyOfT kot;
- Hash convert;
- size_t hashAddress = convert(key) % _table.size();
- Node* cur = _table[hashAddress];
- while(cur) {
- if(equal(kot(cur->_data), key)) {
- return iterator(cur, this);
- }
- cur = cur->_next;
- }
- return end();
- }
-
- bool Erase(const K& key) {
- if(_table.size() == 0)
- return false;
- Hash convert;
- Equal equal;
- KeyOfT kot;
- size_t hashAddress = convert(key) % _table.size();
- Node* cur = _table[hashAddress];
- Node* prev = nullptr;
- while(cur) {
- if(equal(kot(cur->_data), key)) {
- if(prev)
- prev->_next = cur->_next;
- else
- _table[hashAddress] = cur->_next;
- delete cur;
- --_size;
- return true;
- }
- prev = cur;
- cur = cur->_next;
- }
- // 不存在该节点
- return false;
- }
-
- // 哈希表的长度
- size_t TableSize() {
- return _table.size();
- }
-
- // 非空哈希桶的个数
- size_t BucketNum() {
- size_t num = 0;
- for(auto&ptr:_table) {
- if(ptr)
- num++;
- }
- return num;
- }
-
- // 哈希表中数据的个数
- size_t Size() {
- return _size;
- }
-
- // 最大的桶的长度
- size_t MaxBucketLength() {
- size_t max = 0;
- for(size_t i = 0; i < _table.size(); ++i) {
- size_t len = 0;
- Node* ptr = _table[i];
- while(ptr)
- {
- len++;
- ptr = ptr->_next;
- }
- if(len > max)
- max = len;
- // if (len > 0)
- // printf("[%d]号桶长度:%d\n", i, len);
- }
- return max;
- }
- private:
- vector<HashNode<T>*> _table;
- size_t _size = 0;
- };

Unordered_map.h
- //
- // Created by yangzilong on 2022/11/16.
- //
-
- #pragma once
-
- #include "HashTable.h"
- namespace yzl
- {
- template <class K>
- struct MapEqual
- {
- bool operator()(const K& k1, const K& k2) {
- return k1 == k2;
- }
- };
-
- // unordered_map的key需要支持转为整型,相等判断,若关键字类型不支持,可传递仿函数类。
- template<class K, class V, class Hash = hash<K>, class Equal = MapEqual<K>>
- class unordered_map {
- struct MapKeyOfT
- {
- const K& operator()(const pair<K,V>& kv) {
- return kv.first;
- }
- };
- public:
- typedef typename HashTable<K, pair<K,V>, MapKeyOfT, Hash, Equal>::iterator iterator;
-
- iterator begin() {
- return _table.begin();
- }
-
- iterator end() {
- return _table.end();
- }
-
- pair<iterator, bool> insert(const pair<K,V>& kv) {
- return _table.Insert(kv);
- }
-
- V& operator[](const K& key) {
- pair<iterator, bool> ret = _table.Insert(make_pair(key, V()));
- return ret.first->second;
- }
- private:
- HashTable<K, pair<K,V>, MapKeyOfT, Hash, Equal> _table;
- };
- }
unordered_set.h
- //
- // Created by yangzilong on 2022/11/16.
- //
-
- #pragma once
-
- #include "HashTable.h"
- namespace yzl
- {
- template <class K>
- struct hash
- {
- size_t operator()(const K& key) {
- return key;
- }
- };
-
- // 模板特化
- template <>
- struct hash<string>
- {
- size_t operator()(const string& str) {
- size_t sum = 0;
- for(auto&ch:str)
- {
- sum*=131;
- sum+=ch;
- }
- return sum;
- }
- };
-
- template <class K>
- struct SetEqual
- {
- bool operator()(const K& k1, const K& k2) {
- return k1 == k2;
- }
- };
-
- template<class K, class Hash = hash<K>, class Equal = SetEqual<K>>
- class unordered_set {
- struct SetKeyOfT
- {
- const K& operator()(const K& key) {
- return key;
- }
- };
- public:
- typedef typename HashTable<K, K, SetKeyOfT, Hash, Equal>::iterator iterator;
-
- iterator begin() {
- return _table.begin();
- }
-
- iterator end() {
- return _table.end();
- }
-
- pair<iterator, bool> insert(const K& key) {
- return _table.Insert(key);
- }
-
- private:
- HashTable<K, K, SetKeyOfT, Hash, Equal> _table;
- };
- }
三、解析:
0. 这里和红黑树封装map set的整体结构十分相似。红黑树的数据成员是一个RBTreeNode*(因为是树结构),而这里的哈希表采取开散列法,存储的是vector<HashNode<T>*> _table 和一个size_t _size;
1. Insert,Find成员函数的实现都在哈希表类中。而unordered_map 和 unordered_set只是对哈希表的Insert和Find进行了简单调用封装。这样是因为unordered_map和 unordered_set只是在哈希表中存储的数据类型不同,一个是key value键值对类型,一个是key类型。而这里的实现最关键的也是利用了C++的模板。
2. 明白这里的模板参数的作用与对应关系:
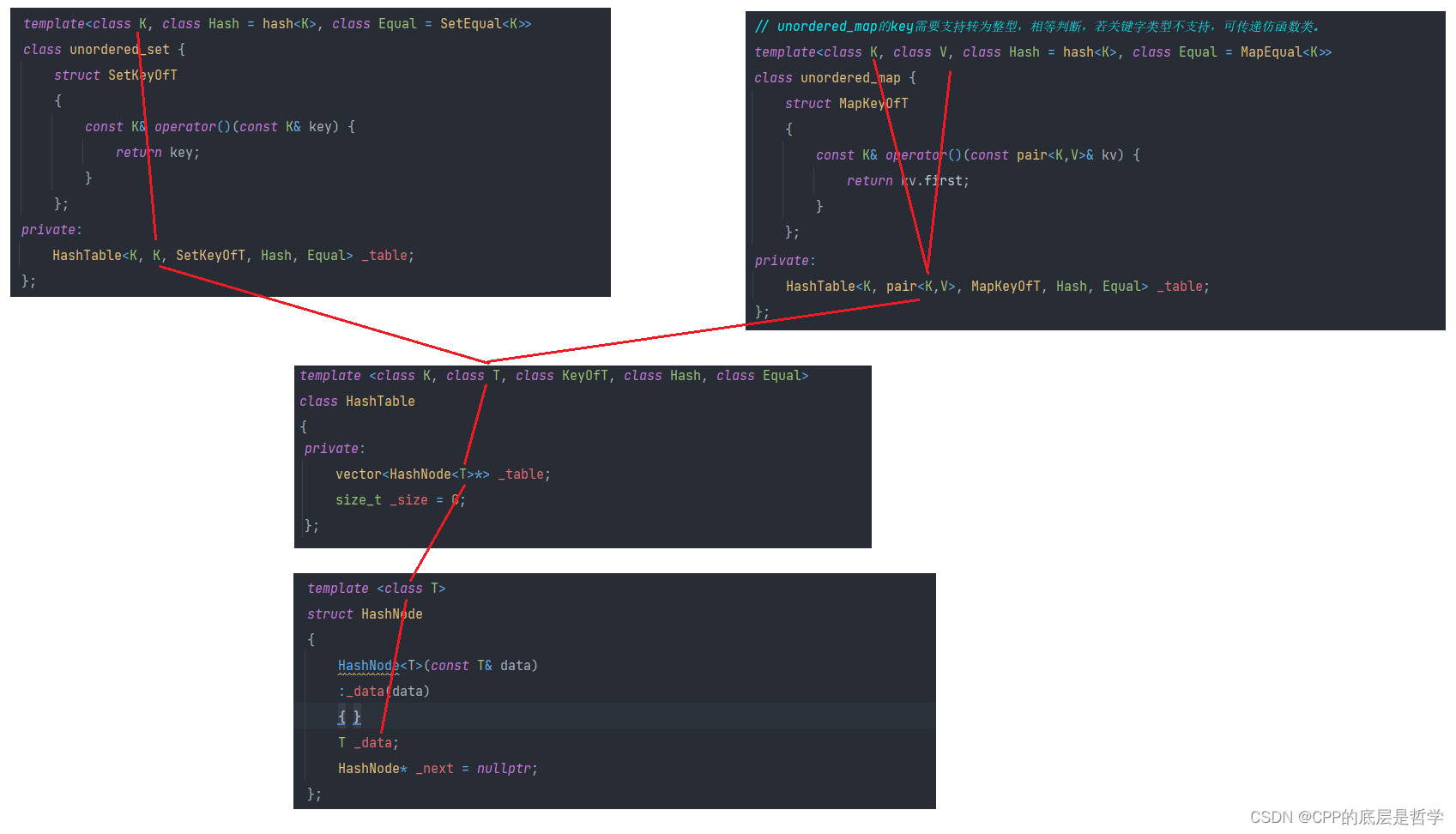
这里和红黑树封装map set很类似。只是因为红黑树和哈希表结构的不同,对关键值的使用和要求不同,新增了一些模板参数实现一些功能。
这里的unordered_map 和 unordered_set 对比STL实现,除了少了最后一个内存池模板参数,其他都一样。
开散列哈希表中结点存储的数据类型只有一个T,u_map为pair u_set为K。这是由HashTable的第二个模板参数传递的。再往上追溯,u_map 和 u_set的数据成员中,只有一个HashTable,对应的传递的第二个模板实参就是pair<K,V>和K.
因为在哈希表的Find实现中,参数为关键值类型,而如果只传递HashTable的第二个T(value_type)类型,无法得知关键值类型,所以在HashTable中有了第一个模板参数。也就是set中,你可以用T代替K,因为它们一样,但是在map中,无法得到关键值类型,而Find和Erase中又要用,所以有了第一个模板参数K。
因为map和set的底层哈希表中T的类型不同,也就是结点中存储的数据类型不同,而有时候又要取出T中的key,这里T是pair或者K,对于unordered_set不需要取,但是对于unordered_map需要取出pair中的key。所以,传递第三个模板参数KeyOfT,是仿函数类型,用于取出T中的key。这里和map set 红黑树那里的功能一样。(这个东西不需要unordered_map unordered_set的使用者传递,所以实现在了容器类内部)
对于Hash模板参数:哈希表的关键在于求出关键值通过哈希函数得到的哈希地址,而上方采用的哈希函数是除留余数法,所以,需要要求关键值为整型(或者可以直接强转为整型)。但是使用哈希表时,key(K)又不可能永远都是整型或者可以转换成整型,故,当传递某些不能直接转为整型的关键值类型时,Hash类模板参数起到了仿函数的作用,用于将关键值转为整型,从而求出哈希地址。
Equal类模板参数:因为在哈希表的查找删除实现中,需要对关键值进行相等比较,所以,对于不支持==运算符的key(K)类型,可以传递Equal模板参数,仿函数类型,用于判断关键值是否相等。
3. 迭代器:
和map set有些类似,begin end等的实现直接实现在了哈希表中,unordered_map unordered_set只是简单封装。
关键在于思考哈希表迭代器的++如何实现:只有一个结点指针是不够的,所以迭代器中多了一个哈希表指针数据成员,所以,哈希表的类模板参数,迭代器这里都需要,并且还需要前置声明。
以往,在list map set的迭代器中,const迭代器和普通迭代器只通过Ptr Ref模板参数来指定operator* 和 operator->的返回类型即可区分,但是这里哈希表的迭代器并没有这样做,所以没有Ptr Ref类模板参数。const迭代器需要单独定义一份(STL中也是这样的)。具体怎么实现自己研究吧。
又因为哈希桶底层为单链表结构,故迭代器没有--操作,为单向迭代器(与map set的区别)
四、unordered_map unordered_set 和 map set对于关键值类型的要求:
map set底层为红黑树,因此,
关键值类型必须支持小于比较。若不支持,需要显式提供比较的仿函数
unordered_map unordered_set的底层为哈希,因此,
关键值类型需要支持转换成整型。若不支持,需要显式提供转换为整型的仿函数
关键值类型需要支持==比较。若不支持,需要显式提供进行等于比较的仿函数


