
- 1数据结构进阶篇 之 【堆的应用】(堆排序,TOP-K问题)详细讲解
- 2SOC芯片学习--GPIO简介_soc gpio
- 3乐玩插件和大漠插件哪个好_教您用好Home Assistant各种插件系列之媒体播放器插件DLNA_DMR...
- 4回归预测 | Matlab实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机的多输入单输出回归预测_卷积神经网络结合支持向量机
- 5软件测试行业到底有没有前景和出路?_测试的出路
- 6红胖子创业第三年总结:保守稳定客户,技术业务认可,口碑业务增长,国内创业真相,减少外协占比,投入研发产品,寻求资本渠道,享受快乐自由
- 7Mac电脑tomcat安装部署_mac安装tomcat
- 8Hexo + Github Pages 搭建个人博客详细教程_hexo+githubpage
- 9向量空间模型 2022-1-17_人工智能 向量空间模型
- 10基于深度学习的安全帽检测系统(YOLOv5清新界面版,Python代码)_不佩戴安全帽死亡数据
【论文笔记】Gemini: A Family of Highly Capable Multimodal Models——细看Gemini_gimini
赞
踩
Gemini
【一句话总结,对标GPT4,模型还是transformer的docoder部分,提出三个不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手机上。】
谷歌提出了一个新系列多模态模型——Gemini家族模型,包括Ultra,Pro,Nano(1.5B Nano-1,3.25BNano-2)三种尺寸(模型由大到小)。在图像、音频、视频和文本理解方面都表现出现,Gemini Ultra在32个benchmarks实现了30个sota。在MMLU中甚至达到了人类专家的性能。
Bard具体使用体验待更新…
1. 引言
Gemini的目标:建立一个模型,该模型不仅具有跨模态的强大通用能力,而且在每个领域都具有尖端的理解和推理性能。
Gemini 1.0 包括三个版本:Ultra 适用于高度复杂的任务,Pro 适用于高性能和大规模部署的场景,Nano 适用于设备上的应用。
Gemini Ultra,在文本推理上实现10/12,图片理解9/9,视频理解6/6,语音识别和翻译5/5。

AlphaCode 团队基于Gemini构建出AlphaCode2,在 Codeforces 竞技编程平台的参赛者中名列前 15%,与名列前 50%的前代产品相比有了很大提高。
此外,还发布了Gemini Nana【针对边缘计算设备的,这个蛮有意思的,想体验一下。】
在下面的章节中,首先概述了模型架构、训练基础设施和训练数据集。然后,介绍了 Gemini 模型系列的详细评估,其中包括文本、代码、图像、音频和视频方面经过充分研究的基准和人类偏好评估–其中包括英语性能和多语言能力。讨论了作者负责任的部署方法2,包括影响评估、制定模型政策、评估以及在部署决策前减轻危害的过程。最后,讨论了 Gemini 的广泛影响、局限性及其潜在应用–为人工智能研究与创新的新时代铺平道路。
2. 模型架构
模型同样使用的Transformer的Decoder部分,对模型架构和的模型优化进行了改进。最大支持32K上下文。

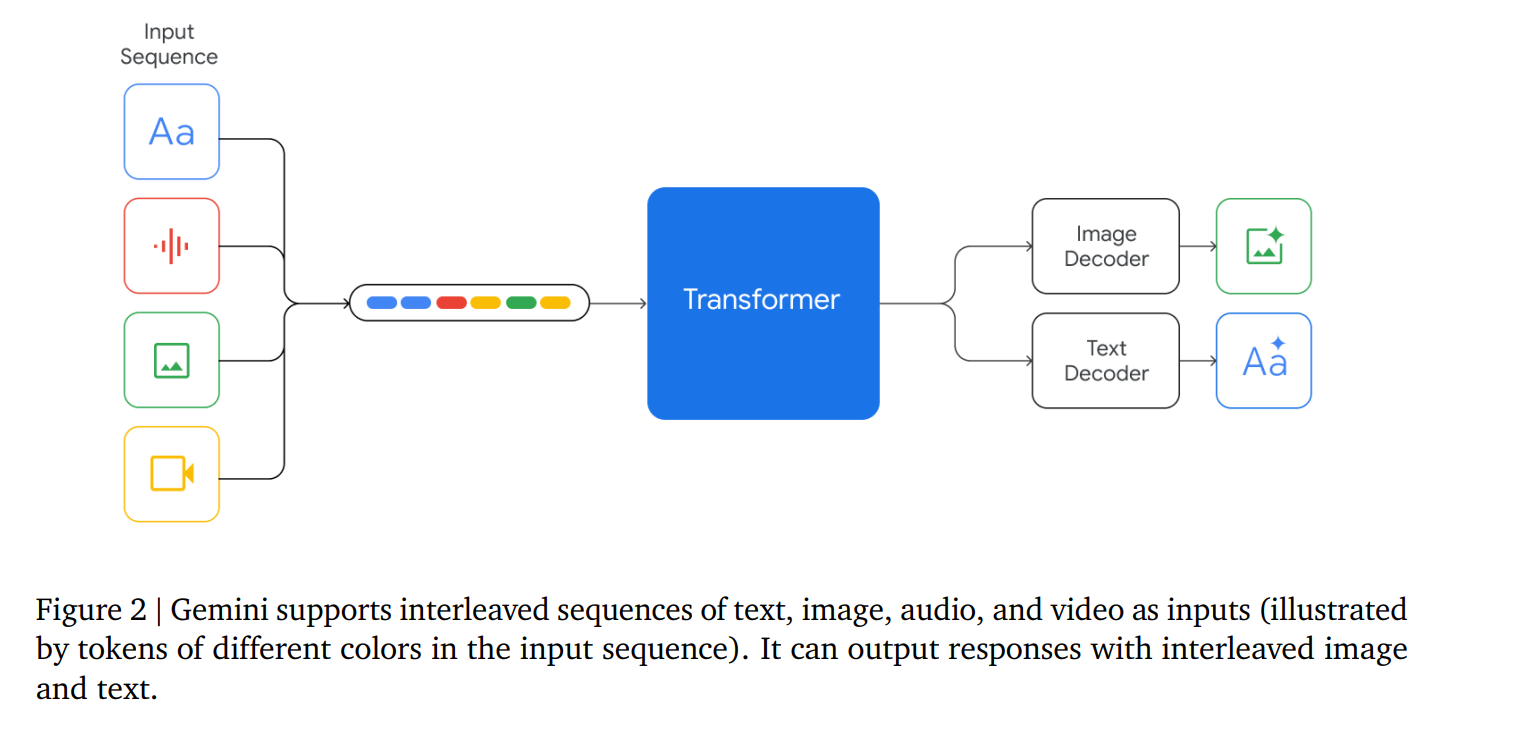
Gemini的输入可以是文字与各种音频和视觉的组合(如自然图像、图表、截图、PDF 和视频),输出是为文本和图像。The visual encoding of Gemini models is inspired by our own foundational work on Flamingo (Alayrac et al., 2022), CoCa (Yu et al., 2022a), and PaLI (Chen et al., 2022), with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens (Ramesh et al., 2021; Yu et al., 2022b).【视觉编码是来源于下面这些工作的。】
视频理解是通过将视频编码为大型上下文窗口中的帧序列来实现的。视频帧或图像可与文本或音频自然交错,作为模型输入的一部分。
Gemini 可以直接从通用语音模型(USM)(Zhang 等人,2023 年)特征中获取 16kHz 的音频信号。这使得该模型能够捕捉到音频被简单地映射到文本输入时通常会丢失的细微差别(例如,请参阅网站上的音频理解演示)
3. 训练基础设施
用的是Google自己的TPU资源。【图片来自Gemini的blog,每一次看都感觉很震撼……大力出奇迹】

4. 训练数据集
预训练数据集使用了来自网络文档、书籍和代码的数据,还包括图像、音频和视频数据
tokenizer使用的是SentencePiece tokenizer。并且发现,在整个训练语料库的大量样本上训练标记化器可以提高推断词汇量,从而提高模型性能。例如,发现 Gemini 模型可以有效地标记非拉丁文【比如汉语】脚本,这反过来又有利于提高模型质量以及训练和推理速度。用于训练最大模型的token数量是按照霍夫曼等人(2022)的方法确定的。对于较小的模型,则使用更多的token进行训练,以提高给定推理预算下的性能,这与 Touvron 等人(2023a)所提倡的方法类似。
我们使用启发式规则和基于模型的分类器对所有数据集进行质量过滤。我们还进行了安全过滤,以去除有害内容。我们从训练语料库中过滤评估集。最终的数据混合物和权重是通过对较小模型的消减确定的。我们进行阶段性训练,以便在训练过程中改变混合物的组成–在训练接近尾声时增加领域相关数据的权重。我们发现,数据质量对高性能模型至关重要,并认为在寻找预训练的最佳数据集分布方面仍存在许多有趣的问题。
5. Evalution
Gemini 模型是原生的多模态模型,因为它们是跨文本、图像、音频和视频进行联合训练的。一个悬而未决的问题是,这种联合训练是否能产生一个在每个领域都有强大能力的模型–即使与狭隘地针对单一领域的模型和方法相比也是如此。我们发现情况确实如此:在广泛的文本、图像、音频和视频基准测试中,Gemini 树立了新的技术典范。
5.1. Text
5.1.1. Academic Benchmarks
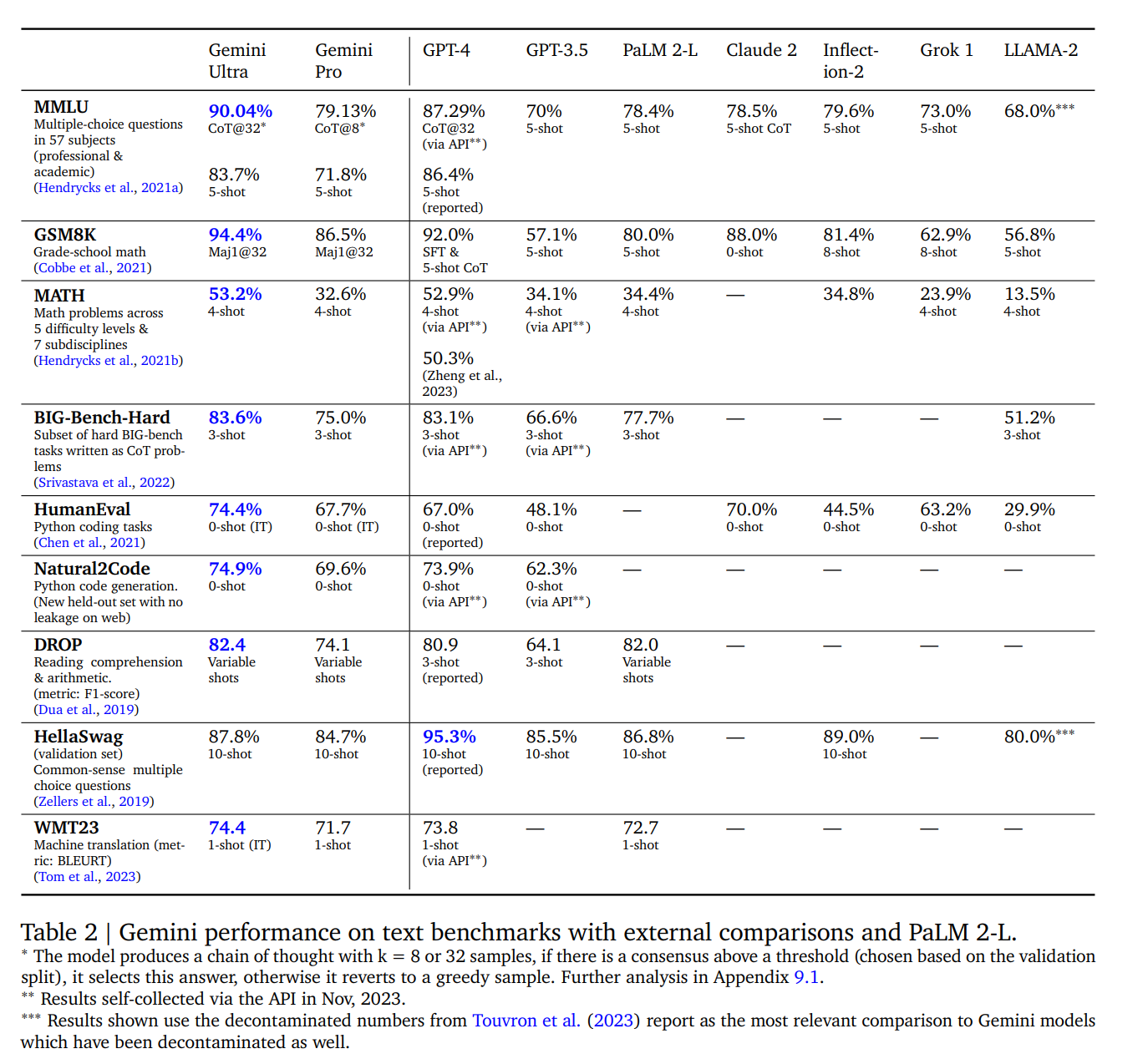
在一系列基于文本的学术基准测试中,我们将 Gemini Pro 和 Ultra 与一套外部 LLM 和我们之前的最佳模型 PaLM 2 进行了比较,测试内容包括推理、阅读理解、STEM 和编码。我们在表 2 中报告了这些结果。总的来说,我们发现 Gemini Pro 的性能优于 GPT-3.5 等推理优化模型,并可与现有的几种能力最强的模型相媲美,而 Gemini Ultra 则优于目前所有的模型。
我们发现,当 Gemini Ultra 与考虑到模型不确定性的思维链提示方法(Wei 等人,2022 年)结合使用时,其准确率最高。该模型会产生一个包含 k 个样本(例如 8 个或 32 个)的思维链。如果存在高于预设阈值的共识(根据验证分割选择),它就会选择这个答案,否则就会返回到基于最大似然选择的贪婪样本,而不进行思维链。【这个CoT@32….挺有意思】
5.1.2. Trends in Capabilities
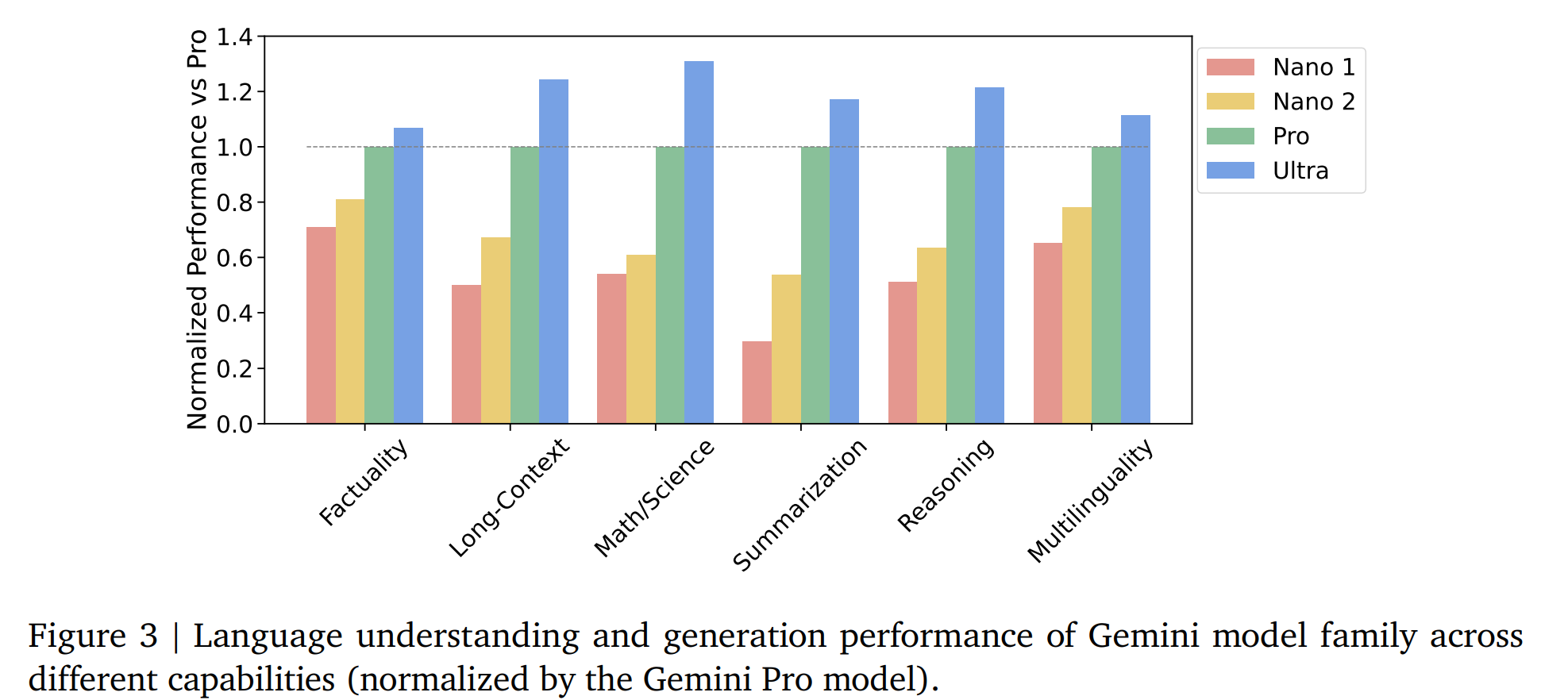
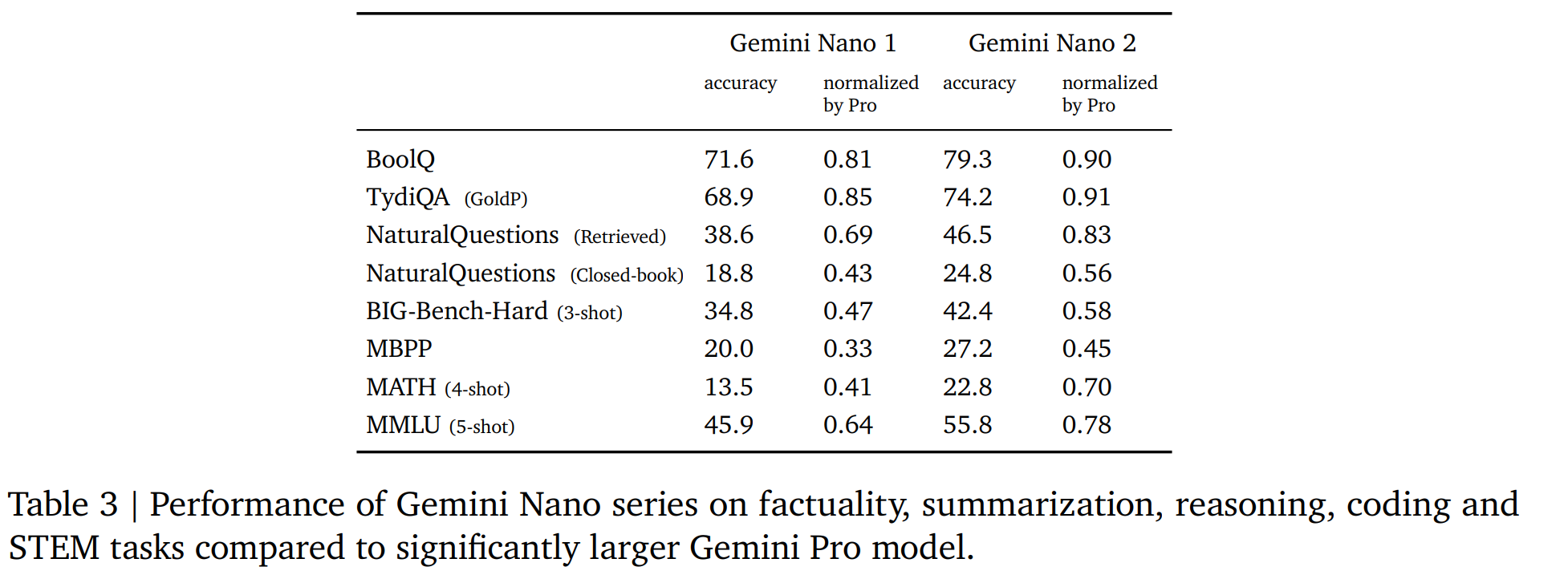
5.1.3. Nano
【个人感觉Nano是最友好的,Nano-1:1.8B的参数,Nano-2:3.25B的参数】
5.1.4. Multilinguality
多语言翻译
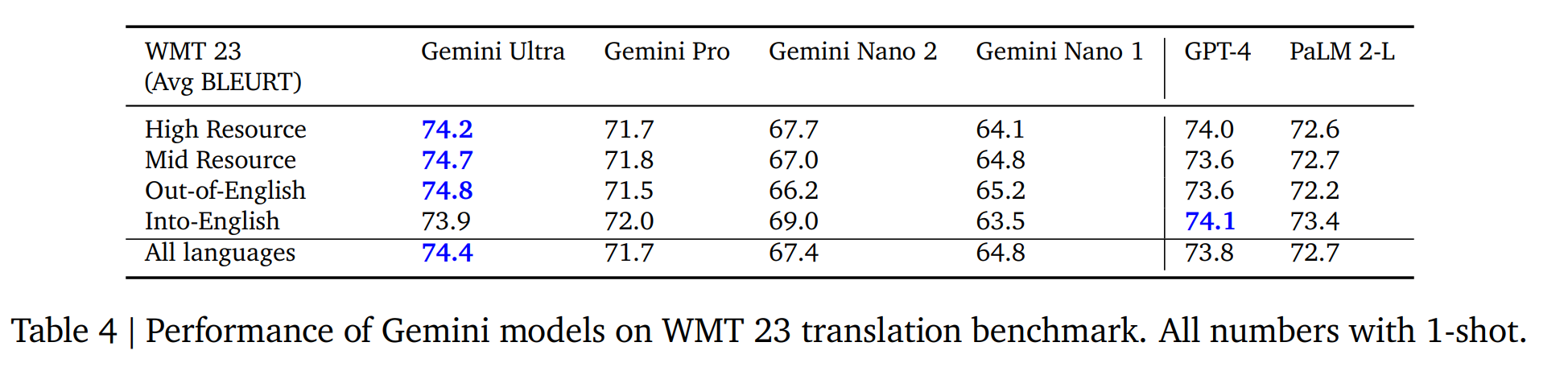
多语言数学与总结

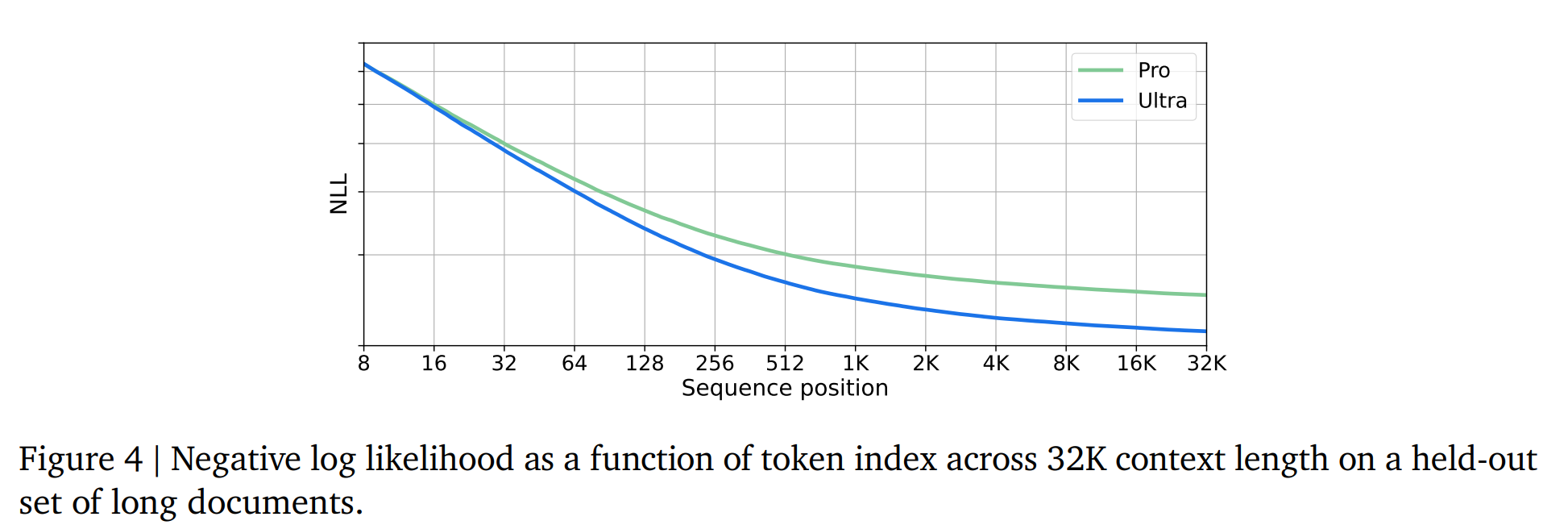
5.1.5. Long Context
Gemini是在32768个token的情况下进行训练的【seq_len = 32768】
5.1.6. Human Preference Evaluations

5.1.7. Complex Reasoning Systems
5.2. Multimodal
双子座模型天生就是多模态的。如图 5 和图 12 所示,这些模型具有独特的能力,能将其跨模态能力(如从表格、图表或图形中提取信息和空间布局)与语言模型的强大推理能力(如其在数学和编码方面的一流性能)无缝结合起来。这些模型在辨别输入中的细粒度细节、聚合跨时空的上下文以及将这些能力应用于与时间相关的视频帧和/或音频输入序列方面也表现出色。下文将对模型在不同模式(图像、视频和音频)下的表现进行更详细的评估,并举例说明模型在图像生成方面的能力以及在不同模式下整合信息的能力。
5.2.1. Image Understanding
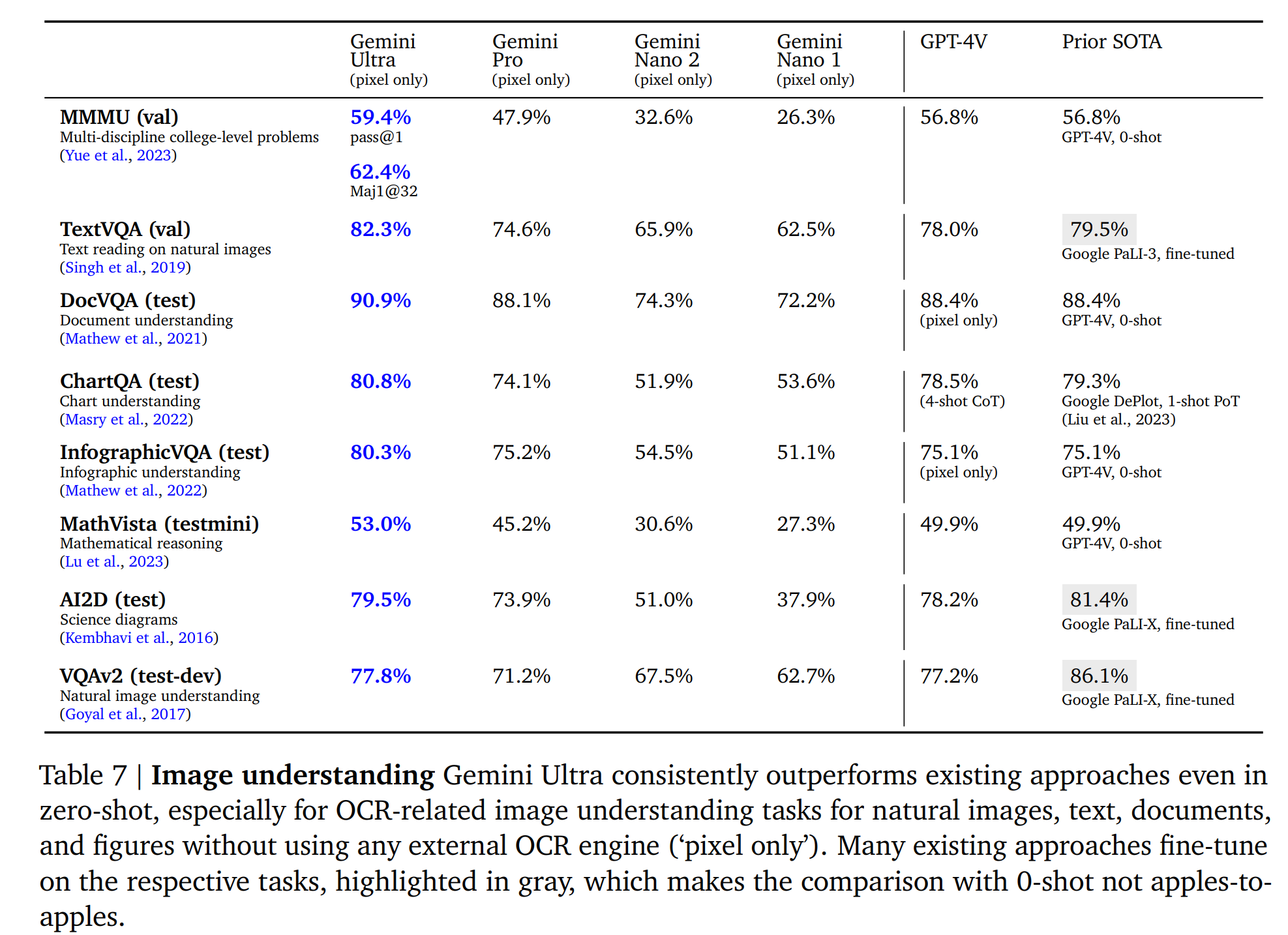
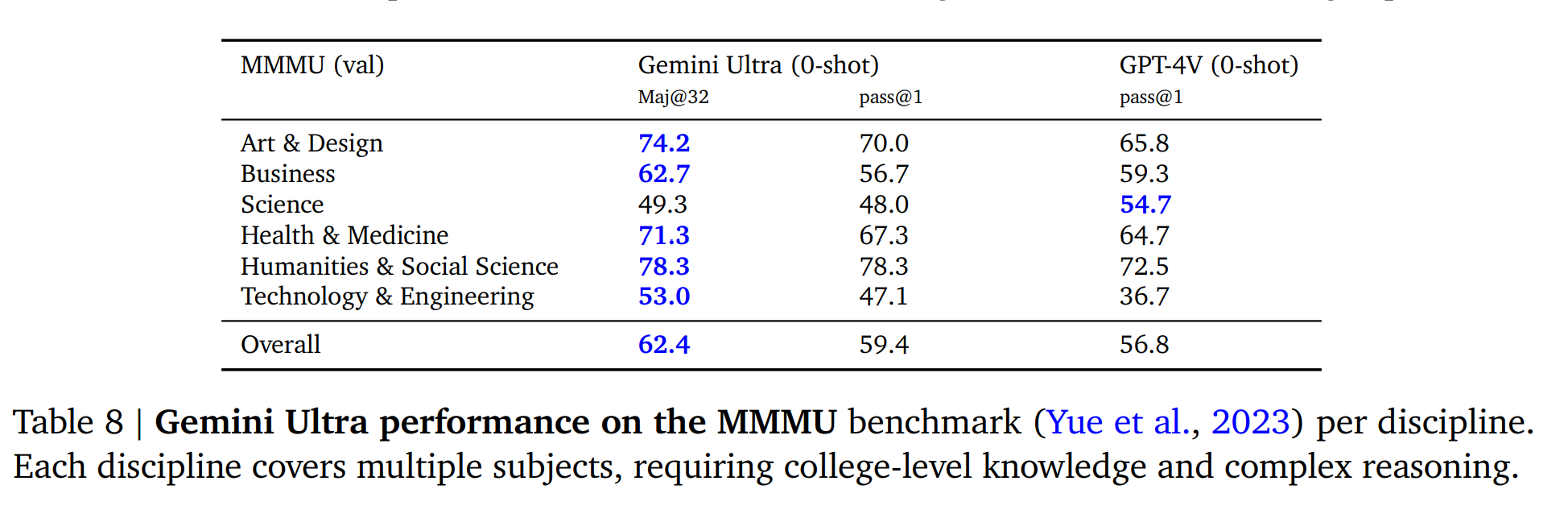
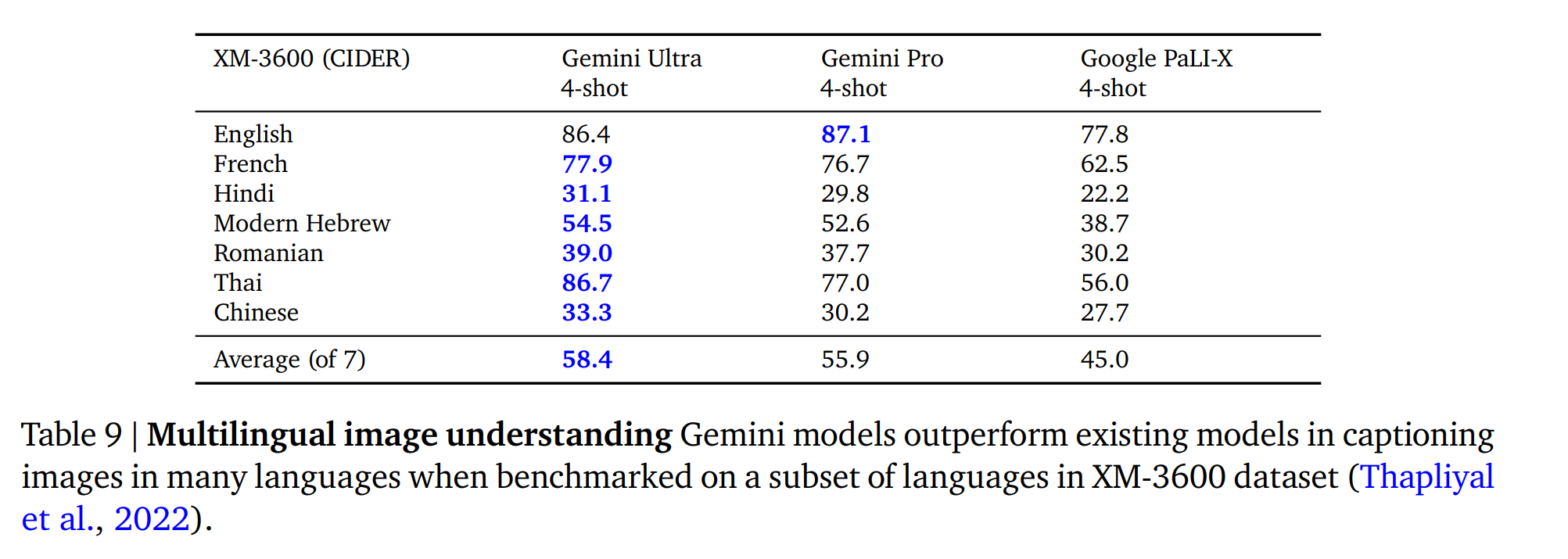
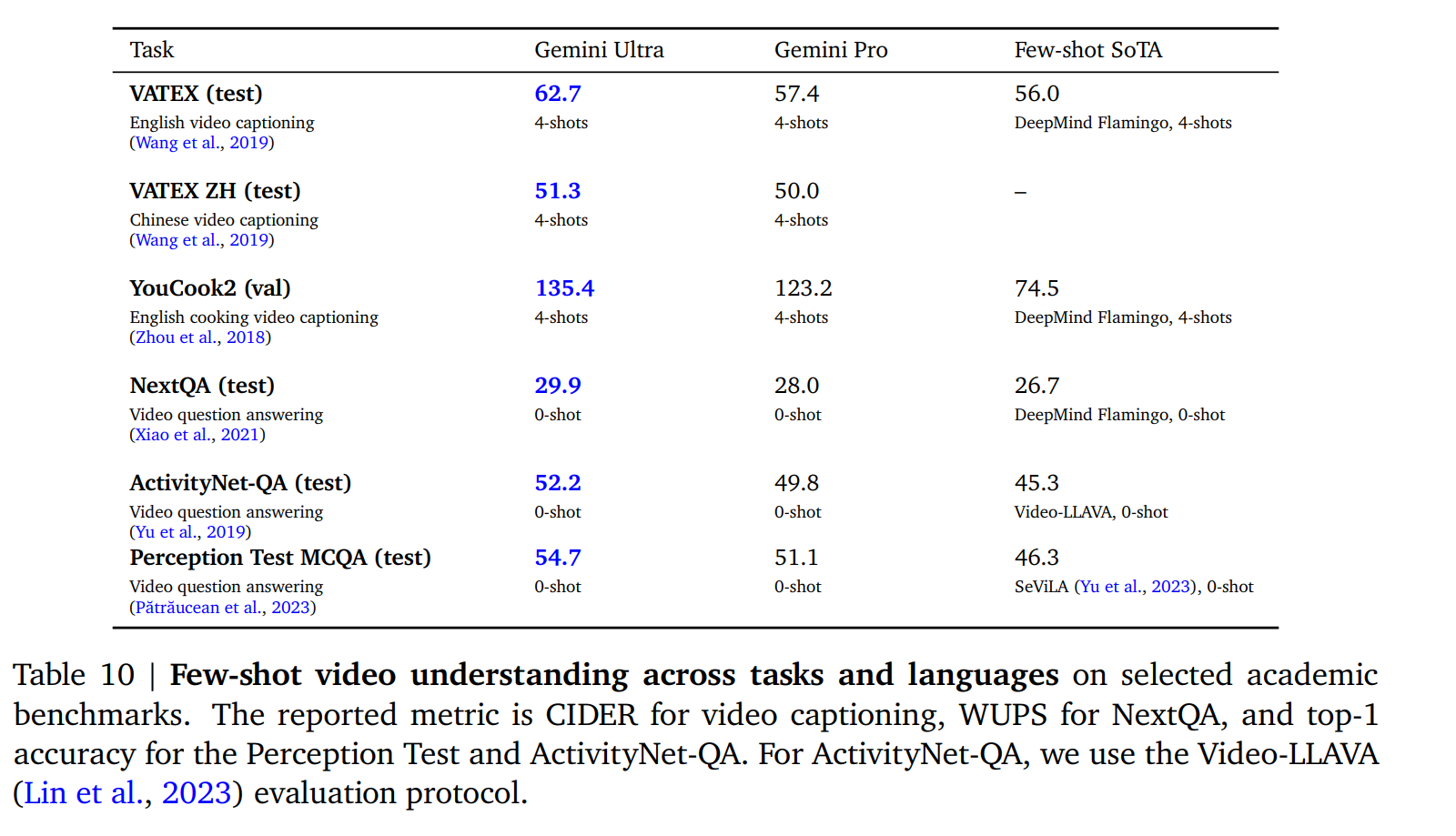
5.2.2. Video Understanding
从每个视频片段中抽取 16 个间隔相等的帧,并将其输入 Gemini 模型
5.2.3. Image Generation

5.2.4. Audio Understanding
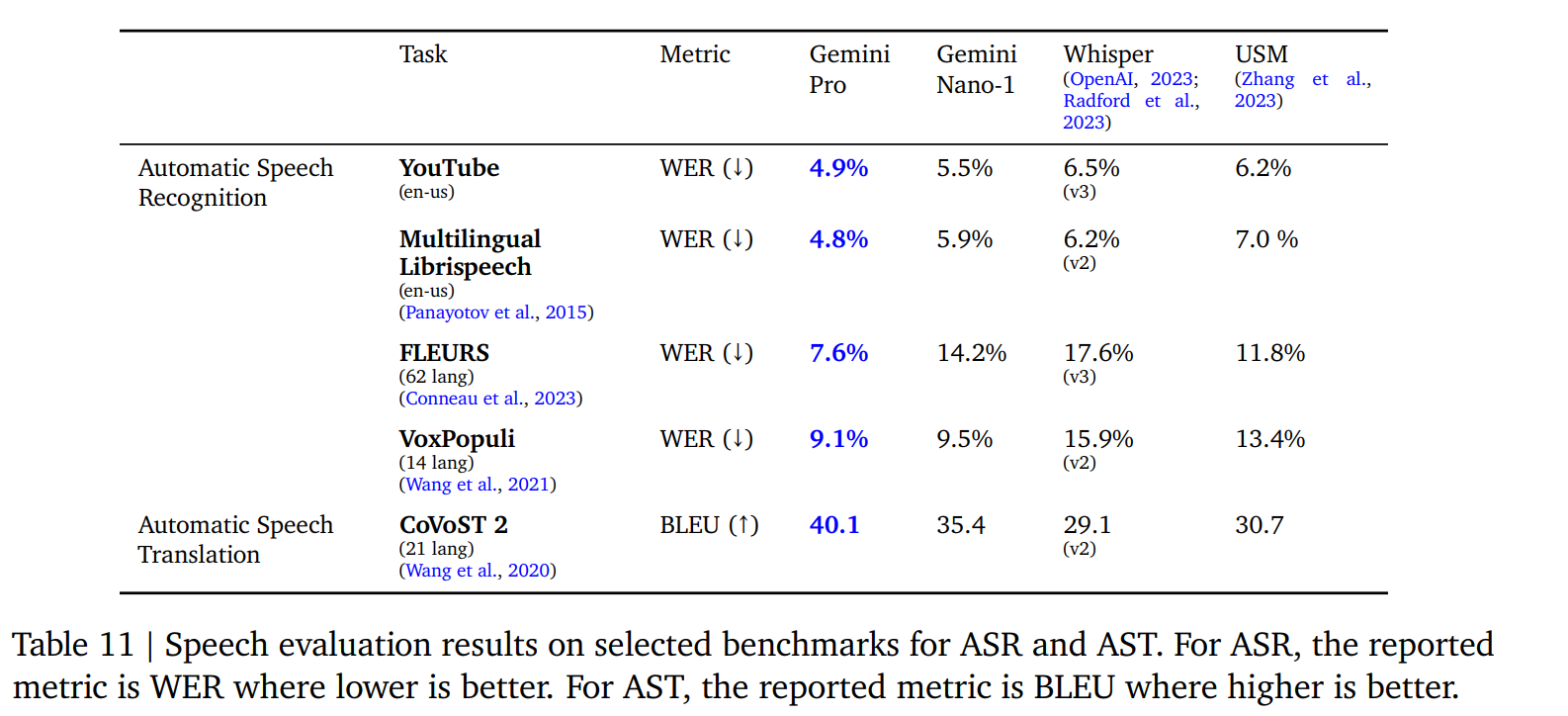

5.2.5. Modality Combination

6. Responsible Deployment
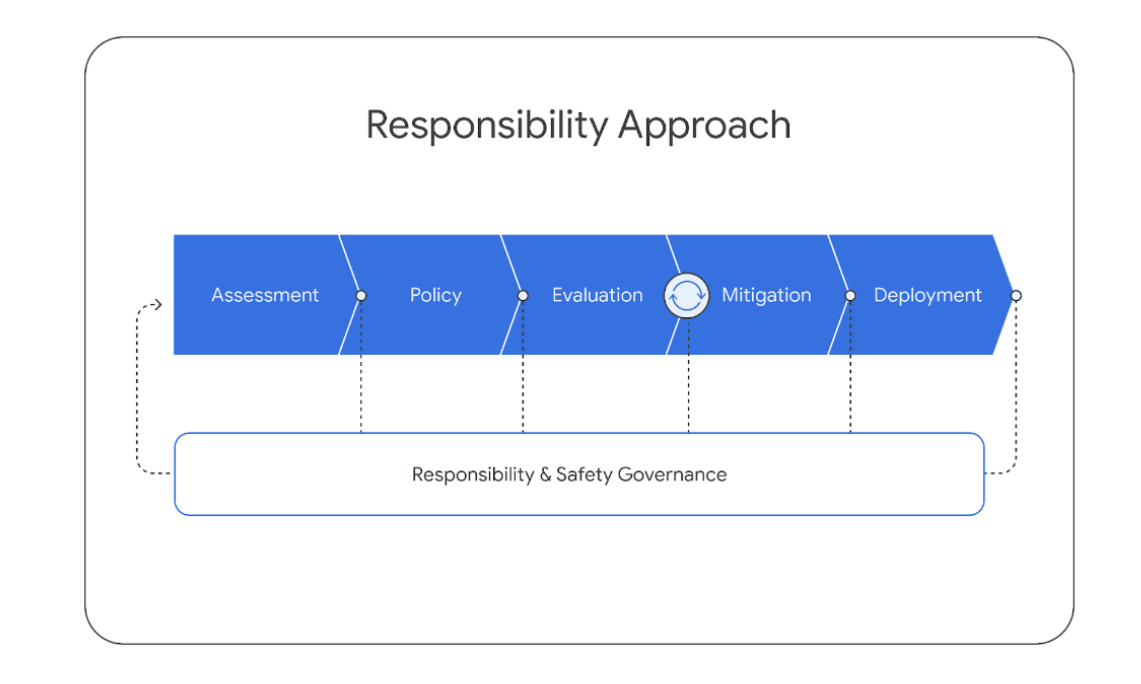
6.1. Impact Assessment
6.2. Model Policy
6.3. Evaluations
6.4. Mitigations
6.4.1. Data
6.4.2. Instruction Tuning
指令调整包括监督微调(SFT)和使用奖励模型通过人类反馈进行强化学习(RLHF)。我们在文本和多模式设置中应用指令调整。指令调整配方经过精心设计,以平衡帮助性的增加和与安全性和幻觉相关的模型危害的减少(Bai 等人,2022a)。 “质量”数据的管理对于 SFT、奖励模型训练和 RLHF 至关重要。使用较小的模型消除数据混合比率,以平衡有用性(例如遵循指令、创造力)和模型危害减少的指标,并且这些结果可以很好地推广到较大的模型。我们还观察到,数据质量比数量更重要(Touvron et al., 2023b; Zhou et al., 2023),特别是对于较大的模型。同样,对于奖励模型训练,我们发现平衡数据集与模型更喜欢说“我无能为力”的示例(出于安全原因)和模型输出有用响应的示例至关重要。我们使用多目标优化以及有用性、真实性和安全性奖励分数的加权总和来训练多头奖励模型。我们进一步阐述了降低有害文本生成风险的方法。我们在各种用例中列举了大约 20 种伤害类型(例如仇恨言论、提供医疗建议、建议危险行为)。我们生成这些类别中潜在危害性查询的数据集,要么由政策专家和机器学习工程师手动生成,要么通过以主题关键字作为种子提示高性能语言模型来生成。考虑到会造成伤害的查询,我们探索 Gemini 模型并通过并排评估来分析模型响应。如上所述,我们平衡了模型输出响应无害与有帮助的目标。根据检测到的风险区域,我们创建额外的监督微调数据来展示理想的响应。
6.4.3. Factuality
6.4.3. Factuality
6.6. Responsible Governance
7. Discussion and Conclusion
【一句话总结:Gimini最牛逼,是谷歌集大成之作】
除了基准测试中最先进的结果之外,我们最兴奋的是 Gemini 模型支持的新用例。 Gemini 模型的新功能可解析复杂图像(例如图表或信息图表),对图像、音频和文本的交错序列进行推理,并在响应时生成交错文本和图像,从而开启了各种新应用。正如报告和附录中的数据所示,Gemini 可以在教育、日常问题解决、多语言交流、信息总结、提取和创造力等领域实现新方法。我们期望这些模型的用户会发现各种有益的新用途,而这些用途在我们自己的调查中只触及了表面。
Gemini 是我们朝着解决智能问题、推进科学发展和造福人类的使命迈出的又一步,我们热切地希望看到 Google 及其他公司的同事如何使用这些模型。我们建立在机器学习、数据、基础设施和负责任的开发方面的许多创新之上,这些都是我们在 Google 十多年来一直追求的领域。我们在本报告中提出的模型为我们更广泛的未来目标提供了坚实的基础,即开发一个大规模、模块化的系统,该系统将在多种模式中具有广泛的泛化能力。
8. 人员
9. Appendix
9.1. Chain-of-Thought Comparisons on MMLU benchmark
9.2. Capabilities and Benchmarking Tasks
9.3. Qualitative Examples
9.3.1. Chart understanding and reasoning over data
9.3.2. Multimodal question answering
9.3.3. Interleaved image and text generation
9.3.4. Image understanding and reasoning
9.3.5. Geometrical reasoning
9.3.6. Information seeking about objects
9.3.7. Multimodal reasoning based on visual cues
9.3.8. Multimodal humor understanding
9.4. Commonsense reasoning in a multilingual setting
9.4.1. Reasoning and code generation
9.4.2. Mathematics: Calculus
9.5. Multi-step reasoning and mathematics
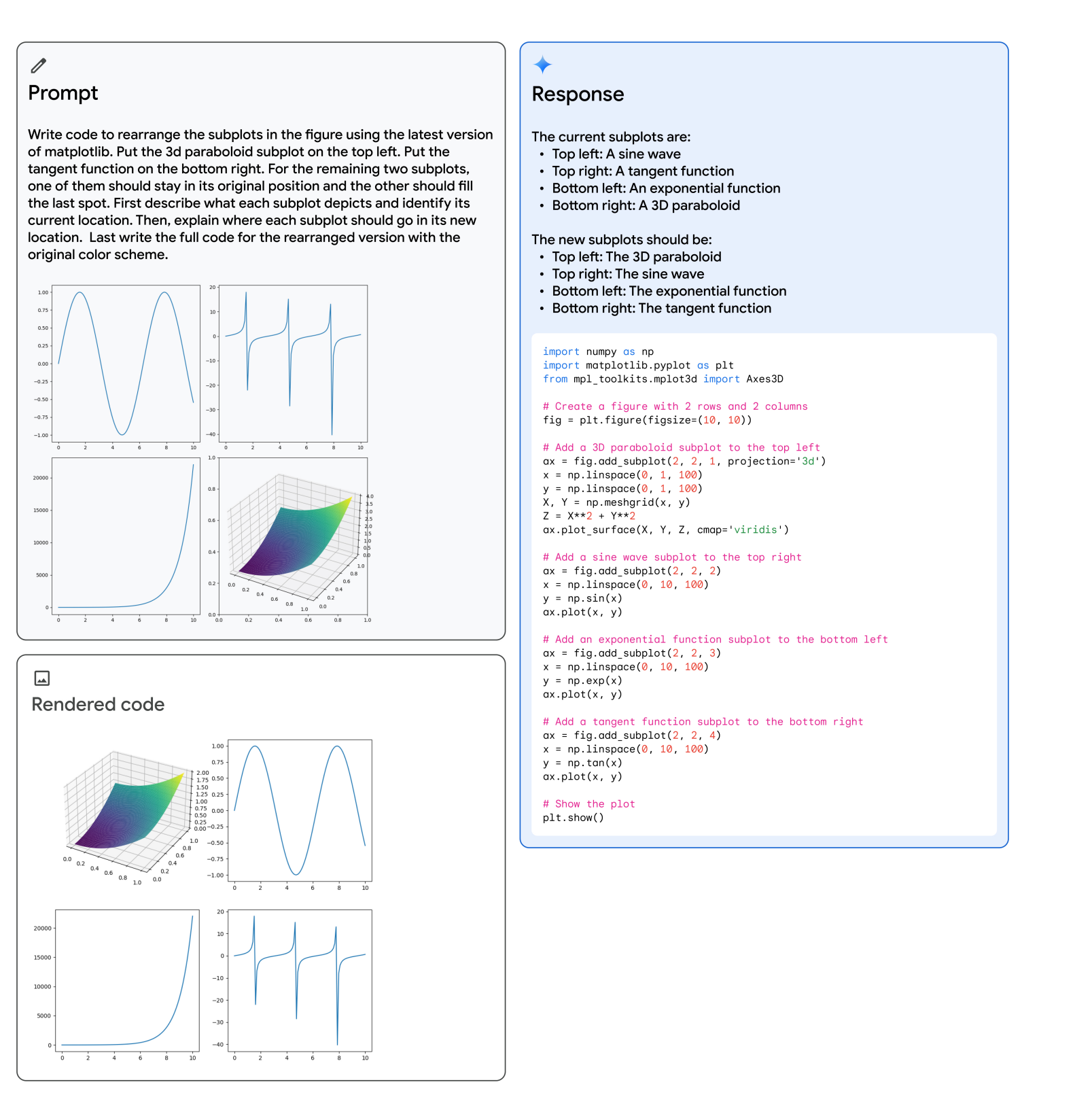
9.5.1. Complex image understanding, code generation, and instruction following
9.5.2. Video understanding and reasoning

