
- 1Doris(原Palo)简介_doris介绍
- 2未来软件测试的5个主要趋势以及软件测试进阶路线_软件测试未来规划
- 3C++入门笔记之std::vector容器详解
- 4[学习笔记]SQL server完全备份指南_sql server 备份
- 5windows11IDEA连接虚拟机的Hadoop(主要解决9000端口无法访问问题,winutil、jdk等的下载默认完成)_idea虚拟机连不到hadoop那个端口上
- 6【零基础系列】了解学习 uni-app_uniapp指h5吗
- 7如何在Firefox中使用Reader View
- 8Redis在虚拟机上安装_虚拟机安装redis
- 9django+nginx+uwsgi 与chatgpt进行对话并流式传输_django实现chatgpt的流式输出
- 10【自监督论文阅读笔记】Learning Transferable Visual Models From Natural Language Supervision_论文精读 learning transferable visual models from natu
[WACV2023] Medical Image Segmentation via Cascaded Attention Decoding
赞
踩
Medical Image Segmentation via Cascaded Attention Decoding
摘要
- Transformer在医学图像分割中表现出了巨大的前景,因为它们能够通过自注意力捕获长期依赖关系。然而,它们缺乏学习像素之间的局部(上下文)关系的能力。以前的工作试图通过在Transformer的编码器或解码器模块中嵌入卷积层来克服这一问题,因此有时会出现特征不一致的情况。
- 为了解决这个问题,本文提出了一种新的基于注意力的解码器,即级联注意解码器(CASCADE),它利用了分层Vision Transformer的多尺度特性。CASCADE由(i)一个带有跳跃连接的注意门和(ii)一个卷积注意模块组成,该模块通过抑制背景信息来增强远程和局部上下文。本文使用了多阶段特征和损失聚合框架,因为它们收敛速度更快,性能更好。
- 我们的实验表明,具有CASCADE的Transformer显著优于最先进的基于CNN和基于Transformer的方法,在DICE和mIoU评分上分别获得高达5.07%和6.16%的改进。CASCADE开启了设计更好的基于注意力的解码器的新方法。
1 引言
医学图像分割是各种疾病治疗前诊断、治疗计划和治疗后评估的关键步骤之一。医学图像分割可以被描述为一个密集的预测问题,它执行按像素分类并创建病变或器官的分割图。卷积神经网络(Convolutional neural networks, CNNs)已广泛应用于医学图像分割任务。具体而言,UNet在医学图像分割中表现出色,因为它使用跳过连接生成了聚合多阶段特征的高分辨率分割图。由于UNet的复杂编码器-解码器架构,UNet的一些变体,如UNet++, UNet 3+ , DC-UNet在医学图像分割中表现出了令人印象深刻的性能。尽管基于CNN的方法具有令人满意的性能,但由于卷积运算的空间上下文,使得它们在学习像素之间的长期依赖关系方面存在局限性。为了克服这一限制,一些作品[23,6,10]在其架构中加入了注意力模块,以增强特征图,从而更好地对医学图像进行像素级分类。尽管这些基于注意力的方法获得了更好的性能(由于捕获了显著的特征),但它们仍然存在捕获不充分的长期依赖关系的问题。
Vision Transformer的最新进展克服了上述在捕获远程依赖关系方面的限制,特别是在医学图像分割方面。Transformer依赖于一个基于注意力的网络架构;它们首先被引入自然语言处理(NLP)中的序列对序列预测。Transformer使用自我注意来学习所有输入token之间的相关性,使它们能够捕获长期依赖关系。继Transformer在NLP中的成功之后,Vision Transformer将图像分割成不重叠的patch,这些patch通过位置嵌入输入Transformer模块。最近,为了降低计算成本,引入了具有基于窗口注意力的Swin Transformer和具有空间约简注意力的金字塔Vision Transformer(PVT)等分层Vision Transformer。这些分层Vision Transformer是有效的医学图像分割任务。然而,Transformer中使用的自注意限制了它们学习像素之间的局部(上下文)关系的能力。
最近,SegFormer , UFormer和PVTv2试图通过在Transformer中嵌入卷积层来克服这一限制。虽然这些架构可以部分学习像素之间的局部(上下文)关系,但它们(i)由于将卷积层直接嵌入前馈网络的全连接层之间,具有有限的识别能力,以及ii)不能正确聚合分层编码器生成的多阶段特征。考虑到这些问题,我们提出了一种利用Vision Transformer的层次表示新型的级联注意力解码器(CASCADE)。CASCADE分别使用门注意力(AGs)和卷积注意模块(CAMs)融合(使用跳过连接)和细化特征。由于使用分层Transformer作为骨干网,并使用基于注意力的卷积模块聚合多阶段特征,CASCADE捕获像素之间的全局和局部(上下文)关系。我们的贡献总结如下:
• 新颖的网络架构: 针对二维医学图像分割问题,提出了一种新的分层级联注意解码器(CASCADE),该解码器利用Vision Transformer的多阶段特征表示,同时学习多尺度、多分辨率的空间表示。我们使用一种新的卷积注意力模块来构建我们的解码器,该模块抑制了不必要的信息。此外,我们将跳跃连接与注意门控融合结合起来,这也抑制了不相关的区域并突出了显著特征。据我们所知,我们是第一个提出这种类型的解码器用于医学图像分割。
• 多阶段损失优化与特征聚合:我们从分层解码器的不同阶段聚合和优化多个损失。我们的实证分析表明,多级损耗可以更快地收敛模型的精度和提高解码器的性能。我们还制作了包含多分辨率特征的最终分割图,这使我们对显著特征更有信心。
•多功能和改进的性能:我们的经验表明,CASCADE可以与任何分层视觉编码器(例如,PVT , TransUNet)一起使用,同时显著提高了2D医学图像分割的性能。当与多个基线进行比较时,CASCADE在ACDC、Synapse多器官和Polyp分割基准上产生了新的最先进的(SOTA)结果。
2 相关工作
我们将相关工作分为三个部分,即Vision Transformer、注意力机制和医学图像分割;下面将描述这些。
2.1 Vision Transformer
Dosovitskiy等首先引入了Vision Transformer(ViT),它由于捕获像素之间的长期依赖关系而获得了出色的性能。虽然早期的Vision Transformer在计算上是昂贵的,但最近的工作试图从几个方面进一步增强ViT。Touvron等引入了DeiT,它试图使用数据高效的训练策略来最小化ViT的计算成本。Liu等使用滑动窗口注意机制开发了Swin Transformer。在SegFormer中,Xie等引入了Mix-FFN模块,用于编码更好的位置信息和有效的自注意机制,以降低计算成本。SegFormer也是一个分级Transformer,其中图像补丁被合并以保持补丁之间的局部连续性。Wang等提出了一种金字塔Vision Transformer(PVT),其中使用空间约简注意机制降低了计算成本。在PVTv2中,Wang等通过引入线性复杂度注意层、重叠补丁嵌入和卷积前馈网络来提高PVT的性能。
尽管Vision Transformer显示出了良好的前景,但在小数据集上训练时,它们的性能是有限的。这种限制使得Transformer很难训练应用,如具有少量数据的医学图像分割。我们试图通过在大型数据集(如ImageNet)中使用预训练的Transformer主干来克服这一限制;事实上,之前的研究[8,30]已经发现,在其他非医疗大型数据集上预训练的Transformer权重可以提高医学图像分割任务的性能。
2.2 注意力机制
Oktay等为U型架构引入了一种低成本的门注意力模块,以融合跳跃式连接的特性;这有助于模型专注于图像中的相关信息。Chen等提出了一种反向注意力模块来探索缺失的细节信息,从而获得高分辨率和准确的输出。Hu等引入了一种利用全局平均池特征的挤压-激励块来计算通道注意力;这就确定了学习的重要特征图,然后增强它们。尽管通道注意力可以识别关注哪个特征图,但它缺乏识别关注哪里的能力。Chen等为补充通道注意块,提出了空间注意块,以更好地集中在特征图上。Woo等引入了一种卷积块注意力模块(CBAM),利用通道注意力和空间注意力来捕获特征图中关注的位置和特征。他们的实验表明,通道注意力和空间注意力会产生最好的结果。
由于CBAM的附加优势和可忽略的开销,我们在我们的CAM中加入了通道注意和空间注意。CAM与CBAM在块本身的设计和块的使用方式上有所不同。首先,我们的CAM由通道注意力、空间注意力和卷积块组成,而CBAM仅由通道注意力和空间注意力组成。其次,CBAM被放置在编码器和解码器的每个卷积块中,而CAM模块只出现在解码器中。
2.3 医学图像分割
医学图像分割是对给定医学图像(如CT、MRI、内镜、OCT等)中器官或病变的像素进行分类的密集预测任务。UNet及其变体因其更好的性能和复杂的架构而广泛应用于医学图像分割任务。UNet是一种编码器-解码器架构,其中编码器的特征与解码器的上采样特征使用跳过连接聚合,以产生高分辨率的分割映射。Zhou等引入了UNet++,其中编码器-解码器子网络使用嵌套和密集的跳过连接连接。Huang等提出了使用全尺寸跳过连接的UNet 3+,包括解码器块之间的内部连接。Lou等人引入了双通道UNet (DC−UNet)架构,该架构利用了跳跃连接中的多分辨率卷积块和残差路径。随着计算机视觉技术的发展,医学图像分割普遍采用ResNet架构作为主干。金字塔池化和扩张卷积也用于病变和器官分割。
目前,基于Transformer的方法在医学图像分割中也取得了很大的成功。Chen等提出了TransUNet,它使用混合CNN-Transformer编码器来捕获远程依赖关系,并使用级联CNN上采样器作为解码器来捕获像素之间的局部上下文关系。相比之下,我们提出了一种新的基于注意力的级联解码器,在编码器上使用时显示出显著的性能提升。Li等通过结合Transformer和全卷积DenseNet引入TFCNs,传播语义特征,过滤非语义特征。Cao等提出了Swin- Unet,它是基于Swin Transformer的纯Transformer架构。Swin-Unet在编码器和解码器中都使用了Transformer,这并没有导致性能的提高。
最近的研究将不同的注意力机制与CNN和基于Transformer的架构结合起来用于医学图像分割。Fan等采用反向注意力进行息肉分割。Zhang等人利用挤压和激励注意力用于分割视网膜图像中的血管。董等人在其解码器中采用了CBAM注意块;他们只使用来自PVTv2第一层的低级特征的CBAM块,这限制了细化所有多阶段特征的能力。相比之下,我们将AG与跳过连接融合在一起,并在我们的所有解码器块中使用CAM模块。
3 方法
我们首先介绍了Transformer主干和我们提出的CASCADE解码器。然后,我们描述了两种不同的基于Transformer的架构(TransCASCADE和PVT-CASCADE),结合了我们提出的解码器。
3.1 Transformer骨干
为了保证医学图像分割有足够的泛化和多尺度特征处理能力,我们使用了金字塔Transformer和混合CNN-Transformer(而不是只有CNN)作为编码器。具体来说,我们采用了PVTv2和TransUNet编码器设计。PVTv2采用卷积运算代替传统Transformer的patch嵌入模块,实现了对空间信息的一致性捕获。TransUNet利用CNN之上的Transformer来捕获特征之间的全局和空间关系。我们提出的解码器灵活,易于与其他分层骨干网采用。
3.2 级联注意力解码器(CASCADE)
现有的基于Transformer的模型在像素之间具有有限的(局部)上下文信息处理能力。因此,基于Transformer的模型在定位更具鉴别性的局部特征时面临困难。为了解决这个问题,我们提出了一种新的基于注意的级联多阶段特征聚合解码器,CASCADE,用于金字塔特征。
如图1(b)所示,CASCADE由UpConv块组成,用于对特征进行上采样,AG用于级联特征融合,CAM用于对特征映射进行鲁棒增强。我们有四个凸轮块用于编码器骨干的金字塔特征的四个阶段,三个AG用于三个跳过连接。为了聚合多尺度特征,我们首先将前一个解码器块的上采样特征与使用AG的跳过连接的特征结合起来。然后,我们将融合的特征与前一层的上采样特征连接起来。然后,我们使用CAM模块对拼接的特征进行像素分组,并利用信道和空间注意抑制背景信息。最后,我们将每个CAM层的输出发送到预测头,并聚合四个不同的预测以生成最终的分割图。
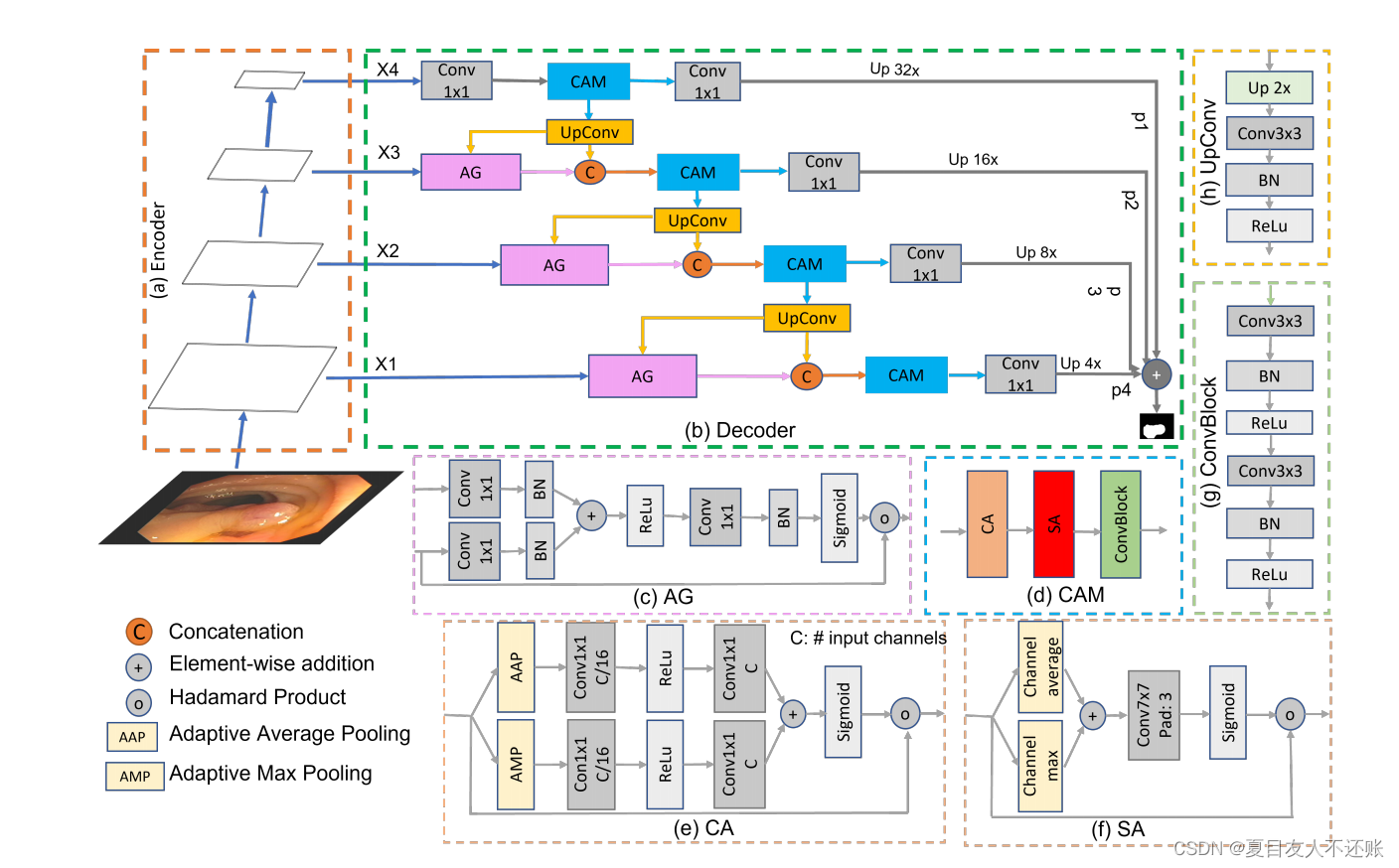
图1。PVT-CASCADE网络架构。(a) PVTv2-b2编码器的四级主干,(b) CASCADE解码器,©门注意(AG), (d)卷积注意模块(CAM), (e)通道注意(CA), (f)空间注意(SA), (g) ConvBlock, (h) UpConv。X1, X2, X3, X4是分层编码器骨干的四个阶段的输出特征。P1、p2、p3和p4是我们的解码器的四个阶段的输出特征映射。
3.2.1 门注意力(AG)
采用基于图像空间信息的栅格注意技术,使用AGs逐步抑制不相关背景区域的特征。更具体地说,用于聚合每个跳过连接的门控信号融合了增加查询信号空间分辨率的多级特征。与Attention UNet一样,我们使用加性注意来获得门控系数,因为它比乘性注意性能更好。加性门注意力AG(·)如式1、式2所示:
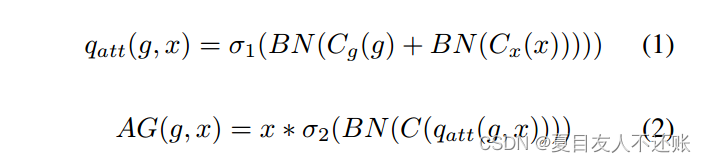
其中,σ1(·)和σ2(·)分别对应ReLU和Sigmoid激活函数。Cg(·)、Cx(·)、C(·)表示通道级1×1卷积运算。BN(·)为批量归一化操作。G和x分别为上采样和跳过连接特征。
3.2.2 卷积注意力模块(CAM)
我们使用卷积注意力模块来细化特征图。CAM由通道注意力(CA(·))、空间注意力(SA(·))和卷积块(ConvBlock)组成,如式3所示:
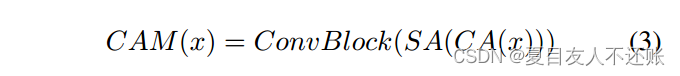
其中x是输入张量,CAM(·)表示卷积注意力模块
通道注意力(CA):
通道注意力确定哪些特征映射需要关注(然后完善它们)。通道注意力CA(·)由式4定义:
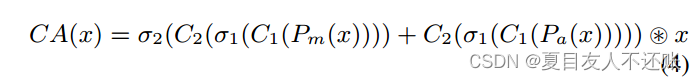
其中σ(·)是Sigmoid激活函数。Cm(·)和Ca(·)分别表示沿通道维度计算得到的最大值和平均值。C(·)是一个7 × 7的卷积层,填充3以增强空间上下文信息(如[8])。
ConvBlock: ConvBlock用于进一步增强使用CA和SA操作生成的特性。ConvBlock由两个3 × 3卷积层组成,每个卷积层后面都有一个批处理归一层和一个ReLU激活层。ConvBlock(·)表示为式6:
表示批量归一化,C(·)为3 × 3卷积层。
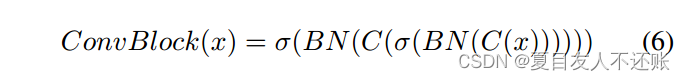
3.2.3 UpConv
UpConv逐步对当前层的特征进行上采样,以匹配下一个跳过连接的维度。每个UpConv层由规模因子为2的上采样UP(·)、3 × 3卷积Conv(·)、批量归一化BN(·)和ReLU激活层组成。U pConv(·)可表示为式7:
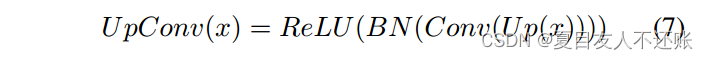
3.3 多级损失和特征聚合
我们使用四个预测头的层次编码器的四个阶段。我们使用加法聚合计算最终的预测图,如式8所示:
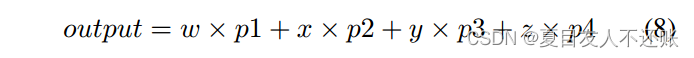
其中p1、p2、p3和p4是四个预测头的特征映射,w、x、y和z是单个预测头的权重。在我们的实验中,我们将所有w、x、y和z设置为1.0。通过对二进制分割采用Sigmoid激活,对多类分割采用Softmax激活,得到最终的预测输出。
但是,我们分别计算每个预测头的损失,然后使用公式9将其聚合:
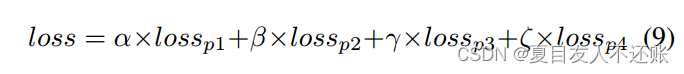
其中,loss sp1, loss sp2, losp3和losp4是四个不同预测头的损失,α, β, γ和ζ是单个预测头损失的权重。在我们的实验中,我们将所有α、β、γ和ζ设为1.0。
3.4 总体架构
我们利用两种不同的分层骨干网编码器网络,如PVTv2和TransUNet进行实验。在TransUNet的情况下,我们只使用他们的混合CNN -Transformer骨干编码器网络。通过使用PVTv2-b2(标准)编码器,我们创建了PVT-CASCADE架构。为了采用PVTv2-b2,我们首先从四层中提取特征(X1, X2, X3, X4),并将它们(即上采样路径中的X4和跳跃连接中的X3, X2, X1)输入到我们的CASCADE解码器中,如图1(a-b)所示。然后我们的CASCADE解码器对它们进行处理,并为编码器网络的四个阶段生成四个预测特征映射。然后,利用公式8对预测特征图进行聚合,得到最终的预测特征图。最后,我们将Sigmoid激活用于二进制分割,将Softmax用于多类分割任务。此外,我们采用TransUNet的骨干编码器网络,介绍了TransCASCADE架构。我们在TransCASCADE体系结构中遵循类似的步骤。这两种架构在Synapse多器官分割、ACDC和几个息肉分割基准上实现了SOTA性能。细节在实验部分给出。
4 实验
在本节中,我们首先将我们提出的CASCADE解码器的结果与SOTA方法进行比较,以证明我们提出的方法的优越性。然后,我们进行消融实验,以评估我们的CASCADE解码器的有效性。
4.1. 数据集和评估指标
Synapse多器官数据集:Synapse多器官数据1有30个腹部CT扫描和3779个轴向增强腹部CT图像。每次CT扫描由85-198个512 × 512像素的切片组成,体素空间分辨率为([0:54-0:54]×[0:98-0:98]×[2:55:0])mm3。在TransUNet之后,我们将数据集随机分为18个用于训练的扫描(2212个轴向切片)和12个用于验证的扫描。我们分割8个解剖结构,如主动脉、胆囊(GB)、左肾(KL)、右肾(KR)、肝脏、胰腺(PC)、脾脏(SP)和胃(SM)。
ACDC数据集:ACDC数据2包括100个不同患者的心脏MRI扫描。每次扫描包含三个器官,右心室(RV),左心室(LV)和心肌(Myo)。在TransUNet[3]之后,我们使用70个案例(1930个轴向切片)进行训练,10个用于验证,20个用于测试。
Polyp 数据集:CVC-ClinicDB包含612张图像,从31个结肠镜检查视频中提取。Kvasir包含1000张息肉图像,这些图像是从Kvasir- seg数据集中的息肉类中收集的。按照PraNet中的设置,我们从CVC-ClinicDB和Kvasir数据集中取相同的900张和548张图像作为训练集,剩下的64张和100张图像分别作为测试集。为了评估泛化性能,我们在三个未见数据集上测试模型,即EndoScene , ColonDB和ETIS-LaribDB 。收集了来自不同的医疗中心三个测试集。换句话说,来自这三个来源的数据并不用于训练我们的模型。
评价指标:我们使用DICE、mean intersection over union (mIoU)、95% Hausdorff Distance (95HD)和Average surface Distance (ASD)作为我们在Synapse Multi-organ数据集上的实验的评价指标。按照现有的方法,我们对ACDC数据集只使用DICE分数。在息肉分割实验中,我们使用DICE和mIoU作为评价指标
4.2 实现细节
我们所有的实验都在Pytorch 1.11.0中实现。我们在一个具有48GB内存的NVIDIA RTX A6000 GPU上训练所有模型。我们利用ImageNet上预训练的权重作为骨干网络。我们使用AdamW优化器,学习率和权重衰减为1e-4。
4.3 结果
我们比较了我们的架构(即PVT-CASCADE和TransCASCADE)与SOTA CNN和基于Transformer的Synapse Multi-organ, ACDC和Polyp(即Endoscene , CVC-ClinicDB , Kvasir , ColonDB , ETIS-LaribDB)数据集的分割方法。更多的结果可在补充材料中得到。
4.3.1 在Synapse数据集的实验结果
我们在表1中演示了不同的CNN和基于Transformer的方法的性能。如表1所示,基于Transformer的模型比基于CNN的模型具有更好的性能。我们提出的CASCADE解码器的平均DICE, mIoU和HD95比TransUNet评分分别提高了5.07%、6.16%和9.56分。在所有方法中,TransCASCADE的平均DICE(82.67%)、mIoU(73.48%)、HD95(17.34)、ASD(2.83)得分最佳。此外,TransCASCADE在小器官和大器官分割方面都有显著的性能改进。对于小器官,胆囊改善8.05%,左肾改善7.12%,右肾改善6.03%。对于大器官,胃、胰腺和脾脏分别改善8.52%、6.86%和3.73%。这是因为CASCADE捕获像素之间的长期依赖关系和局部上下文关系。由于使用注意力,CASCADE比其他解码器更好地细化特征映射并产生更强的特征表示。HD95分数较低,说明我们的CASCADE解码器能更好地定位器官边界。
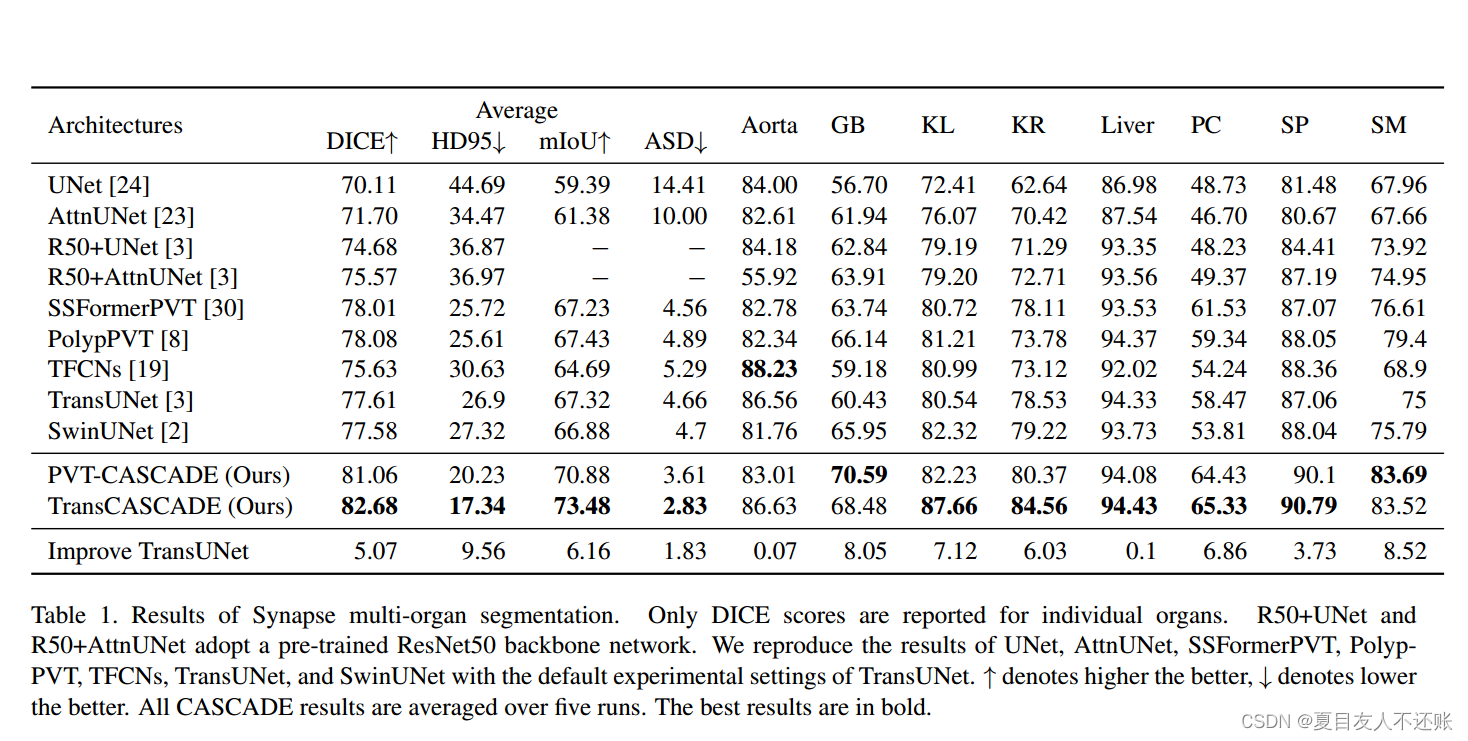
表1。Synapse多器官分割结果。仅报告单个器官的DICE评分。R50+UNet和R50+AttnUNet采用预训练的ResNet50骨干网。我们用缺省的TransUNet实验设置重现了UNet、AttnUNet、SSFormerPVT、PolypPVT、TFCNs、TransUNet和SwinUNet的结果。↑表示越高越好,↓表示越低越好。所有CASCADE结果在五次运行中取平均值。最好的结果用粗体表示。
4.3.2 ACDC数据集实验结果
我们评估了我们的方法在ACDC数据集的MRI图像上的性能。表2展示了我们的PVT-CASCADE和TransCASCADE以及其他SOTA方法的平均DICE分数。我们的TransCASCADE获得了最高的平均DICE分数91.63%,比TransUNet提高了约2%,尽管我们使用相同的编码器。我们的PVT-CASCADE获得了91.46%的DICE分数,这也优于其他所有方法。此外,我们的TransCASCADE在挑战器官RV和Myo分割方面的DICE评分提高了2.5 - 3%。
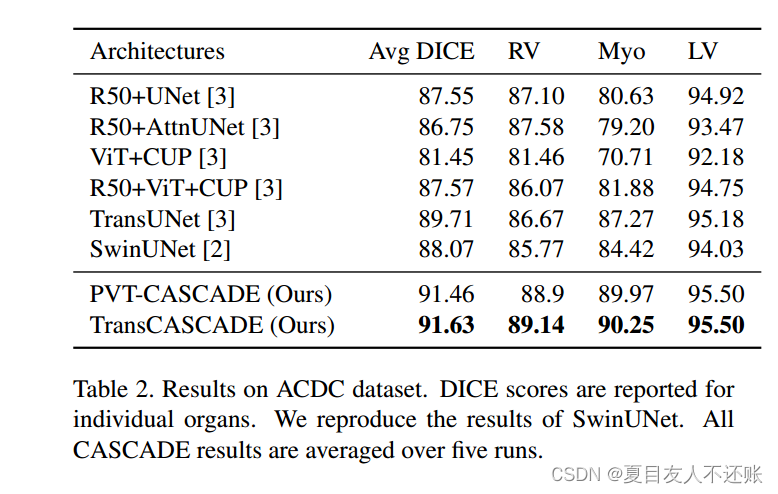
表2。ACDC数据集上的结果。报告单个器官的DICE评分。我们复制了SwinUNet的结果。所有CASCADE结果在五次运行中取平均值。
4.3.3 Polyp数据集的实验结果
我们在五个不同的息肉分割测试集上评估了我们的CASCADE解码器的性能和通用性,其中三个是从不同实验室收集的完全看不见的数据集。表3显示了SOTA方法的DICE和mIoU分数以及我们的CASCADE解码器。从表3中,我们可以看出CASCADE显著优于所有其他方法,使用相同的预训练Transformer骨干,在未见测试集中的DICE和mIoU分数比之前的最佳模型提高了2.04 - 3.2%和2.5 - 3.9%。值得注意的是,CASCADE在未见数据集上的表现大大优于基于CNN的最佳模型UACANet(即ETIS-LaribDB和ColonDB的DICE评分分别提高了16.2%和10%)。因此,我们可以得出结论,由于使用Transformer作为骨干网和我们的基于注意力的CASCADE解码器,PVT-CASCADE继承了Transformer、CNN和注意力的优点,使得它们对于未见数据集具有高度的泛化性。
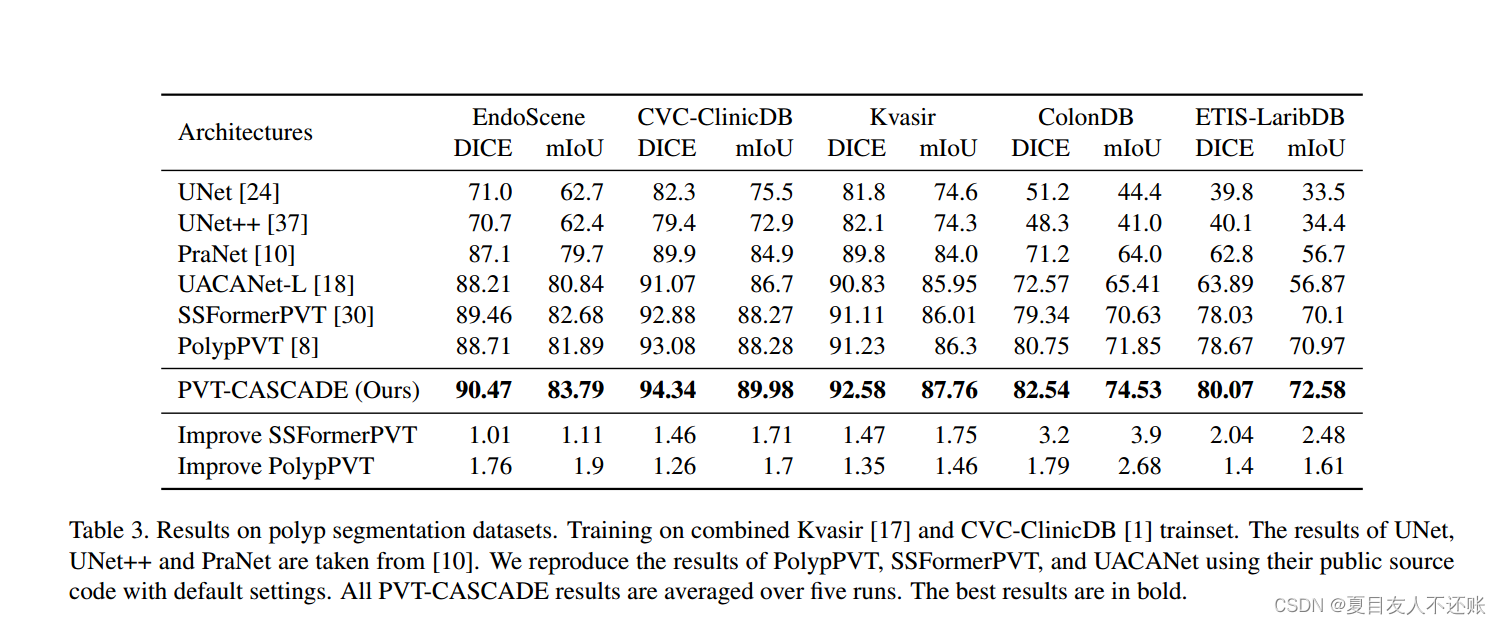
表3。息肉分割数据集的结果。Kvasir和CVC-ClinicDB联合训练。UNet, Unet++和PraNet的结果取自[10]。我们在默认设置下使用PolypPVT、SSFormerPVT和UACANet的公共源代码来重现它们的结果。所有PVT-CASCADE结果均为5次运行的平均值。最好的结果用粗体表示。
4.4 消融实验
有效的增强/细化特征:我们在图2中可视化了我们的CASCADE以及级联上采样器(CUP)的特征。我们计算特征图中所有通道的平均值,然后使用OpenCV-Python生成热图。从图2中可以明显看出,CASCADE中使用的注意力机制比CUP更好地帮助识别、增强和分组像素。

图2。级联与级联上采样器(CUP)特性。第一行和第二行分别表示CASCADE和CUP特征。为了公平的比较,我们只在CASCADE解码器中加入了相似的层特性。根据相应的Transformer层数对层进行编号。在这两种情况下,我们使用ImageNet预训练的PVTv2-b2骨干作为编码器。
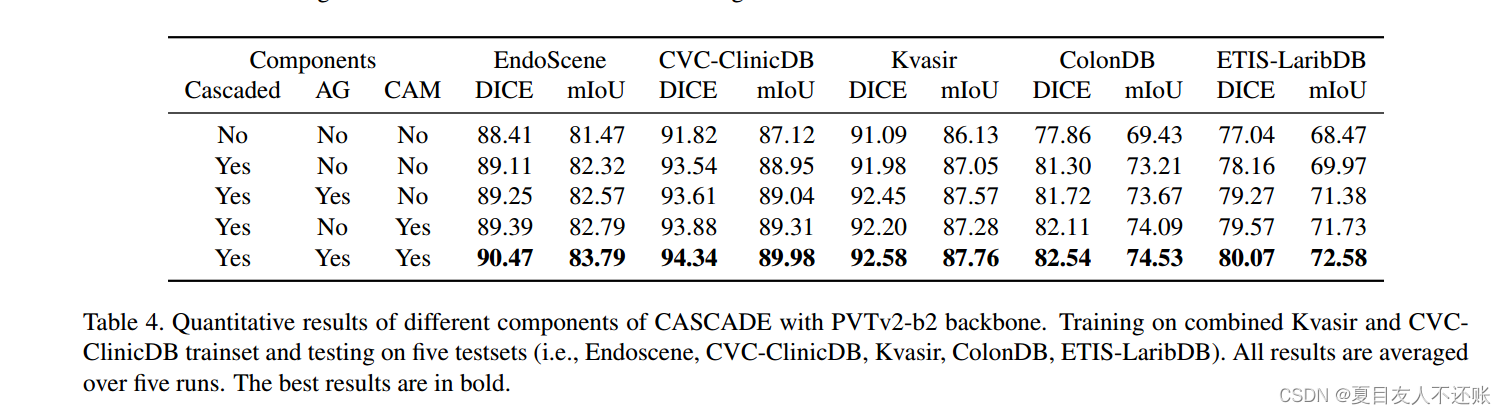
CASCADE不同部分的有效性:我们对Polyp数据集进行了消融研究,以评估我们提出的CASCADE解码器不同组件的有效性。在所有实验中,我们使用在ImageNet上预训练的相同PVTv2b2骨干,并对息肉数据集使用相同的实验设置。我们从CASCADE解码器中去除不同的模块,如AGs和CAM,并比较结果。从表4可以明显看出,解码器的级联结构比非级联解码器提高了性能。AG和CAM模块也有助于提高性能。然而,AG和CAM模块的使用在所有测试数据集中产生了最好的性能。
更快地学习多级损失和输出融合:
我们将我们的CASCADE解码器的四个阶段的损耗和输出相加,得到总体损耗和最终的分割图。图3绘制了每个纪元在五个数据集上的平均DICE分数。该图包含六种不同的损耗和输出聚合设置,如“1-损耗,1-输出”、“1-损耗,4-输出”、“4-损耗(添加),4个输出”、“4-损耗(平均),4个输出”和“1-损耗,1个输出,学习率4e-4”。从图中可以明显看出,“4-loss (add), 4 output”和“4-loss (avg), 4 output”在第一个epoch中获得了74 - 75%的DICE分数,并且这些设置在5个epoch中获得了超过82%的DICE分数。另一方面,其他损失和输出聚合的DICE分数约为35 - 53%,这些设置在5个epoch内达到71%的DICE分数。从图中我们还可以看到,“4-loss (add), 4 output”表现最好,平均DICE得分为84.67%。因此,我们可以得出结论,多阶段损失和输出的聚合利用多尺度特征,有助于产生准确和高分辨率的分割输出。
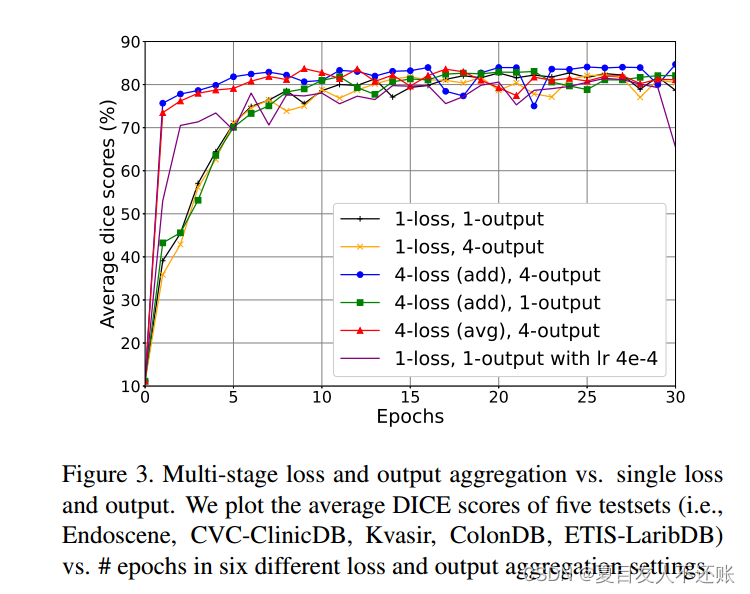
图3。多级损失和输出聚合vs.单级损失和输出。我们绘制了5个测试集(即Endoscene、CVC-ClinicDB、Kvasir、ColonDB、ETIS-LaribDB)与# epochs在6种不同损失和输出聚合设置下的平均DICE分数。
5 结论
本文提出了一种新的基于注意的分层特征聚合解码器,该解码器具有鲁棒的泛化能力和学习能力;这些是医学图像分割的关键。我们相信CASCADE在其他医学图像分割任务中有很大的潜力来提高深度学习的表现。此外,实验证明CASCADE有效地增强了Transformer特征,并融合了像素之间的空间关系(例如,在Synapse多器官分割中,将基线TransUNet提高了5.07% DICE和6.16% mIoU)。实验结果表明,CASCADE由于在解码过程中使用注意力,可以很好地定位器官或病变(如HD95评分提高9.56)。因此,我们的解码器可以进一步用于增强一般计算机视觉和高度一般化的医疗应用的Transformer特性。

