
- 1ubuntu 22.04 -- cmake安装_ubuntu22.04离线安装make
- 2Android Studio启动AVD报错:The emulator process for AVD 快速解决方法_unable to launch medium phone api 33 - the emulato
- 3Kafka数据重复和数据丢失的解决方案_kafka相同数据
- 4Ansible-基础模块
- 5Python机器学习项目开发实战:如何从看似混乱的数据中找出规律
- 66大职业类型,你是哪个?霍兰德职业兴趣测试帮你揭晓!
- 7腾讯云被DDos攻击五个解决方案_腾讯云服务器被ddos安全隔离中怎么办
- 8为了找出最好用的安卓模拟器,我发起了一项众测_雷电模拟器 闪退 知乎
- 9如何运行PHP文件 /创建PHP项目【基于VScode、XAMPP】超级详细,亲测有效,这一篇就够了_php项目怎么跑起来
- 10mysql-函数CASE WHEN 语句使用说明
Mask R-CNN论文精读_maskrcnn论文原文
赞
踩
原文:He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
源码:https://github.com/facebookresearch/detectron2
报告:https://www.youtube.com/watch?v=g7z4mkfRjI4&t=241s
我们提出了一个简单、灵活、通用的实例分割框架,称为Mask R-CNN。我们的方法能够有效检测图像中的目标,同时为每个实例生成高质量的分割掩码。Mask R-CNN通过添加一个预测对象掩码的分支,与现有的边框识别分支并行,扩展了之前的Faster R-CNN。Mask R-CNN的训练很简单,只为Faster R-CNN增加了一小部分开销,运行速度为5帧/秒。此外,Mask R-CNN很容易泛化到其他任务,如人体姿态估计。我们展示了Mask R-CNN在COCO挑战赛的实例分割、目标检测和人物关键点检测任务上的最优结果。在不使用花哨技巧的情况下,Mask R-CNN在各项任务上都优于现有的单一模型,包括COCO 2016挑战赛的冠军。我们希望Mask R-CNN能够成为一个坚实的基线,并有助于简化未来实例识别的研究。
★ 论文故事
Fast/Faster R-CNN和Fully Convolutional Network(FCN)框架极大地推动了计算机视觉领域中目标检测和语义分割等方向的发展。这些方法的概念很直观,具有良好的灵活性和鲁棒性,并且能够快速训练和推理。我们这项工作的目标是为实例分割任务开发一个相对可行的框架。
实例分割具有一定的挑战性,因为它需要正确检测图像中的所有对象,同时还要精确分割每个实例。因此,它结合了目标检测和语义分割等计算机视觉任务中的元素。目标检测旨在对单个物体进行分类,并使用边框对每个物体进行定位。语义分割旨在将每个像素归类到一组固定的类别,而不区分对象实例。鉴于此,人们可能会认为需要一套复杂的方法才能获得良好的结果。然而,我们证明了一个令人惊讶的事实:简单、灵活、快速的系统也可以超越现有的最先进的实例分割模型。
我们的方法称为Mask R-CNN,通过在每个RoI(感兴趣区域,Region of Interest)上添加一个预测分割掩码的分支来扩展Faster R-CNN,并与现有的用于分类和边框回归的分支并行。掩码分支是应用于每个RoI的一个小FCN,以像素到像素的方式预测分割掩码,并且只会增加较小的计算开销。Mask R-CNN是基于Faster R-CNN框架而来的,易于实现和训练,有助于广泛、灵活的架构设计。

原则上,Mask R-CNN是Faster R-CNN的直观扩展,但正确构建掩码分支对于获得好的结果至关重要。最重要的是,Faster R-CNN的设计没有考虑网络输入和输出之间的像素到像素的对齐。这一点在RoIPool(处理实例的核心操作)如何执行粗空间量化来提取特征上表现得最为明显。为了修正错位,我们提出了一个简单的、没有量化的层,称为RoIAlign,它忠实地保留了精确的空间位置。尽管这看起来是一个很小的变化,但是RoIAlign有很大的影响:它将掩码精度提高了10%-50%,在更严格的localization指标下显示出更大的收益。其次,我们发现有必要将掩码和类别预测解耦:我们为每个类别独立预测一个二进制掩码,类别之间没有竞争,并依靠网络的RoI分类分支来预测类别。相比之下,FCN通常执行逐像素的多分类操作,将分割和分类耦合在一起,我们的实验结果表明这种方法的实例分割效果不佳。
在不使用花哨技巧的情况下,Mask R-CNN在COCO实例分割任务上就超越了之前的所有SOTA单模型,包括COCO 2016比赛的冠军。作为副产品,我们的方法在COCO目标检测任务上也表现出色。在消融实验中,我们评估了多个基本实例,这使我们能够证明Mask R-CNN的鲁棒性,并分析其核心因素的影响。
我们的模型可以在GPU上以每帧约200ms的速度运行,在一台8-GPU的机器上进行COCO训练需要1-2天。我们相信,快速的训练和测试,以及框架的灵活性和准确性,将有利于未来实例分割的研究。
最后,我们通过COCO关键点数据集上的人体姿态估计任务展示了Mask R-CNN框架的通用性。通过将每个关键点视为一个独热二进制掩码,只需对Mask R-CNN稍加修改,即可用于检测特定实例的姿态。Mask R-CNN超越了COCO 2016关键点检测比赛的冠军,并且能够以5帧/秒的速度运行。因此,Mask R-CNN可以被更广泛地视为一个实例识别的灵活框架,并且很容易泛化到其他更复杂的任务上。
★ 模型方法
Mask R-CNN方法很简单:Faster R-CNN对每个候选对象有两个输出,一个是类别标签,另一个是边框偏移量。在此基础上,我们添加了第三个分支,用于输出分割掩码。因此,Mask R-CNN是一个自然且直观的想法。但是掩码输出不同于类别和边框输出,需要提取更精细的对象空间布局。接下来,我们介绍了Mask R-CNN的关键元素,包括像素到像素对齐,这是Fast/Faster R-CNN所缺失的部分。
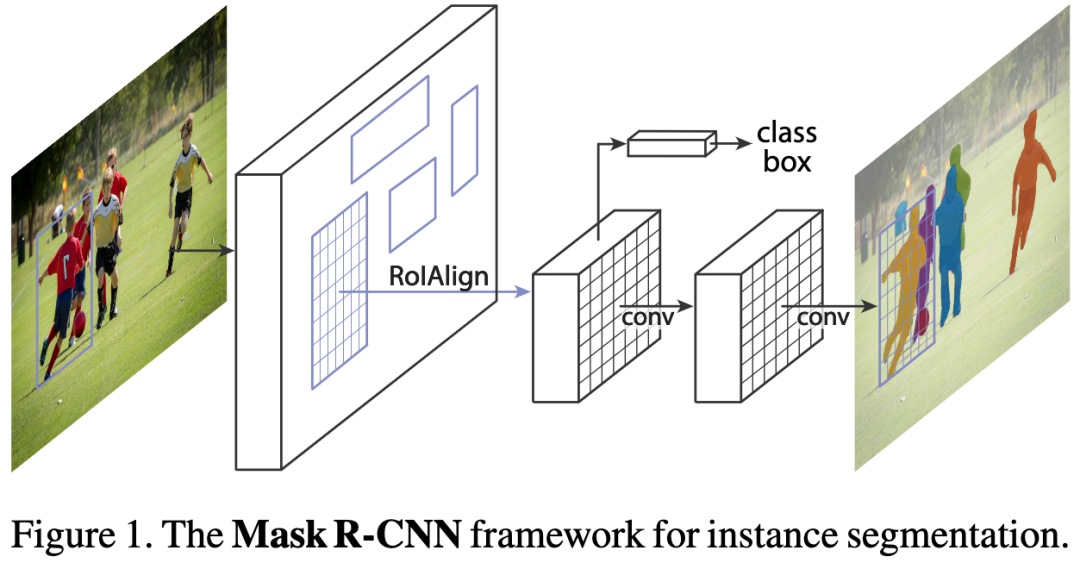
图1:用于实例分割的Mask R-CNN框架。

图3:RoIAlign:虚线网格表示特征映射图,实线边框表示RoI(Region of Interest),点表示每个边框中的4个采样点。RoIAlign通过双线性插值从特征映射图上的相邻网格点计算每个采样点的值。
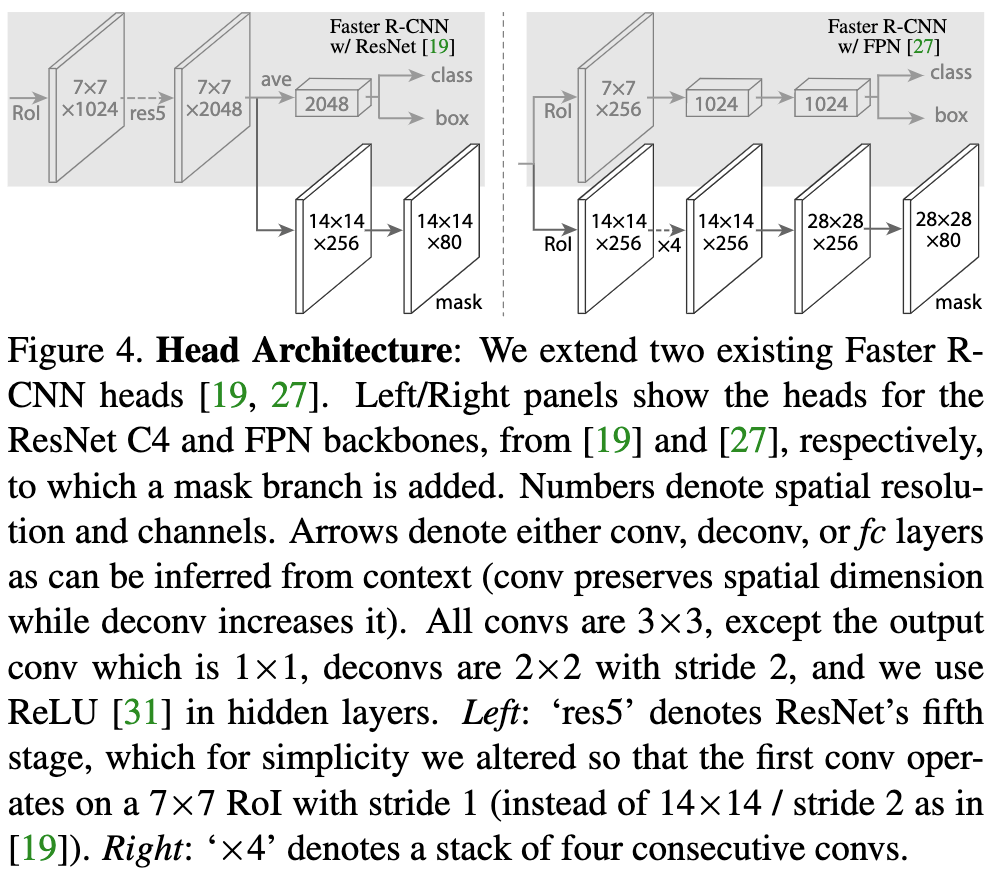
图4:Head架构:我们扩展了两个现有的Faster R-CNN Head。
★ 实验结果

图2:Mask R-CNN在COCO测试集上的实验结果。

图5:Mask R-CNN在COCO测试集上的更多结果。

表1:在COCO test-dev数据集上的实例分割结果。Mask R-CNN不使用花哨技巧就能胜过复杂的FCIS++,后者使用了多尺度训练/测试、水平翻转测试和OHEM等技巧。

图6:Mask R-CNN与FCIS++实验结果的对比。

表2:Mask R-CNN的消融实验结果。
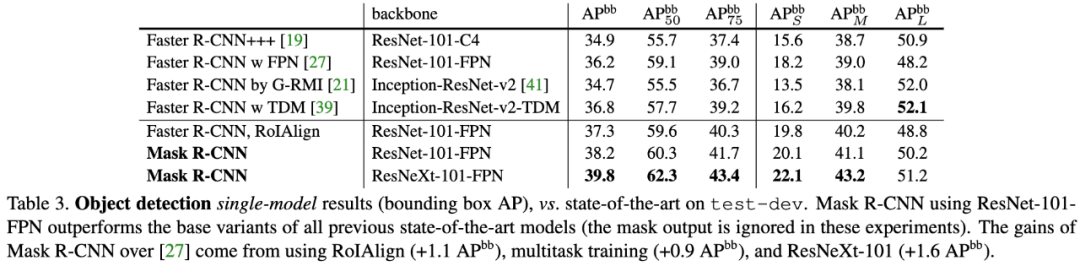
表3:Mask R-CNN与Faster R-CNN目标检测结果的比较。Mask R-CNN性能的提升主要得益于三个方面:RoIAlign、多任务训练和ResNeXt-101。

图7:Mask R-CNN在COCO test数据集上的关键点检测和人物分割结果。

表4:不同模型在COCO test-dev数据集上的关键点检测结果。

表5:在COCO minival数据集上,边界框、掩码和关键点的多任务学习。

表6:用于关键点检测的RoIAlign与RoIPool的对比。
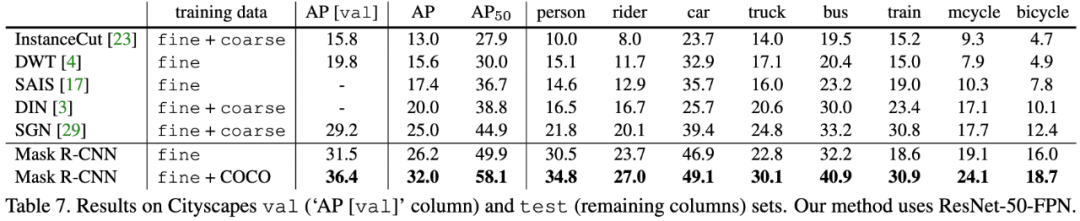
表7:Mask R-CNN在Cityscapes val和test数据集上的实验结果。

图8:Mask R-CNN在Cityscapes test数据集上的分割检测结果(32.0 AP)。

表8:Mask R-CNN在COCO minival数据集上的检测结果。

表9:Mask R-CNN在COCO minival数据集上的关键点检测结果。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号,一起进步^_^↑

