
- 1Git撤销已经push到远程分支的commit_git撤销已经push到远端的commit
- 22024华为OD机试(Python)真题【A卷+B卷+C卷+D卷】目录_华为od机试好过吗
- 3【Linux】vim的基本使用_linux vim操作
- 451单片机定时器实现钟表(LCD1602显示)_普中51单片机用定时器做时钟
- 5CommunityToolkit.Mvvm笔记1---Instruction
- 6大数据的重要性与应用_大数据管理与应用的必要性有哪些
- 7船舶推进系统故障诊断(Python代码,多通道信息融合)_船舶设备故障识别
- 8地图比例尺与空间分辨率之间的关系_遥感影像分辨率与地图比例尺的关系及应用浅析...
- 9flink任务cpu和内存资源的计算_flink查看任务内存使用情况
- 10ubuntu: acpi bios error (bug) could not resolve symbol解决_ubuntu acpi bios error
ddddocr可以识别文字验证码,手把手教你用python来实现自动化程序识别验证文字。【建议收藏】
赞
踩
python代码如下:
# coding:utf-8
import datetime
import math
import os
import random
import re
import sys
import time
from io import BytesIO
import ddddocr
from PIL import Image, ImageDraw
from selenium.webdriver import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from api import get_tiiktok_anti2
import execjs
import requests
from colorama import Fore, init
import api
import cooke_path_8
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
# 获取当前文件的目录
cur_path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(cur_path)
cookie_path = cooke_path_8.get_cooke_path_8()
current_path = cooke_path_8.get_current_path()
get_chromedriver_path = cooke_path_8.get_chromedriver_path()
import logging
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
'''
nid =1
ss1= "https://mobile.pinduoduo.com/goods.html?goods_id={0}&force_use_web_bundle=1".format(str(nid))
ss2= "https://mobile.pinduoduo.com/goods.html?goods_id={}&force_use_web_bundle=1".format(str(nid))
print(ss1)
print(ss2)
sys.exit(1)
'''
class UpData:
def __init__(self, page_max, which):
#m3 = execjs.compile(open(r"route.js", encoding='utf-8').read())
#verifyFp = m3.call('mergeFp', '')
#print(verifyFp)
#exit(1)
#dXNlcg==
#anNzd3h2Mmc==
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--disable-blink-features=AutomationControlled") # 禁用启用Blink运行时的功能
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"]) # 去除浏览器检测框
#chrome_options.add_argument('--user-data-dir=' + cookie_path)
#chrome_options.add_argument('--proxy-server=http://127.0.0.1:8999')
self.driver = webdriver.Chrome(chrome_options=chrome_options,
executable_path=get_chromedriver_path)
'''
with open(f'{cur_path}' + '/stealth.min.js', encoding='utf-8') as f:
js = f.read()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
'''
self.page_max = page_max + 1
self.page_no = 1
self.page_size = 200
self.detail_sleep_time = 1
self.debug = 0
self.begin_date = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime('%Y/%m/%d')
self.end_date = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime('%Y/%m/%d')
self.headers = {
'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
}
self.getVerificationCode()
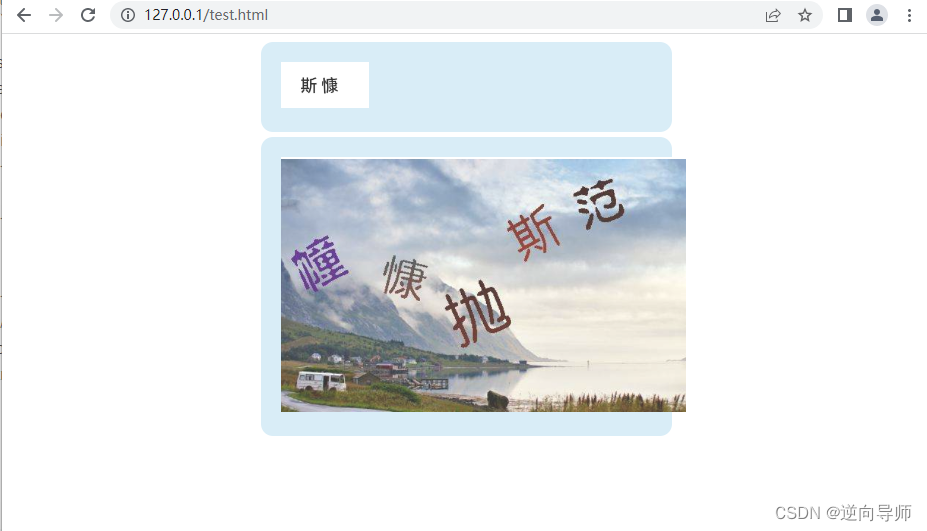
def getVerificationCode(self):
base_url = f"https://www.kgcaptcha.com/demo/content?t=4&cindex=2#code_lang"
base_url = f"http://127.0.0.1/test.html"
self.driver.get(base_url)
time.sleep(5)
wait = WebDriverWait(self.driver, 10)
image2 = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="verify-bar-code"]')))
target_img_url = image2.get_attribute('src')
target_image_content = requests.get(target_img_url).content
docr = ddddocr.DdddOcr(show_ad=False)
target_words = docr.classification(target_image_content)
image1 = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="captcha-verify-image"]')))
background_img_url = image1.get_attribute('src')
background_image_content = requests.get(background_img_url).content
ddet = ddddocr.DdddOcr(det=True, show_ad=False)
poses = ddet.detection(background_image_content)
img = Image.open(BytesIO(background_image_content))
draw = ImageDraw.Draw(img)
click_identify_result = {}
for row in poses:
# 框字
row = (row[0] - 3, row[1] - 3, row[2] + 3, row[3] + 3)
x1, y1, x2, y2 = row
draw.line(([(x1, y1), (x1, y2), (x2, y2), (x2, y1), (x1, y1)]), width=1, fill='red')
# 裁剪出单个字
corp = img.crop(row)
img_byte = BytesIO()
corp.save(img_byte, 'png')
# 识别出单个字
word = docr.classification(img_byte.getvalue())
click_identify_result[word] = row
img.show()
# 计算文字点击坐标
img_xy = {}
for key, xy in click_identify_result.items():
if key:
img_xy[key] = (int((xy[0] + xy[2]) / 2), int((xy[1] + xy[3]) / 2))
logger.info(img_xy)
# 计算最终点击顺序与坐标
result = {}
for word in target_words:
result[word] = img_xy[word]
logger.info(result)
# 点击坐标
image1_x = image1.location.get('x')
image1_y = image1.location.get('y')
for xy in result.values():
x = xy[0] * (340 / 552)
y = xy[1] * (212 / 344)
ActionChains(self.driver).reset_actions()
ActionChains(self.driver).move_by_offset(image1_x + x, image1_y + y).click().perform()
time.sleep(6000)
if __name__ == '__main__':
updata = UpData(1, 2)
html代码如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>站点创建成功-phpstudy for windows</title>
<meta name="keywords" content="">
<meta name="description" content="">
<meta name="renderer" content="webkit">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="format-detection" content="telephone=no">
<meta HTTP-EQUIV="pragma" CONTENT="no-cache">
<meta HTTP-EQUIV="Cache-Control" CONTENT="no-store, must-revalidate">
<meta HTTP-EQUIV="expires" CONTENT="Wed, 26 Feb 1997 08:21:57 GMT">
<meta HTTP-EQUIV="expires" CONTENT="0">
<style>
body{
font: 16px arial,'Microsoft Yahei','Hiragino Sans GB',sans-serif;
}
h1{
margin: 0;
color:#3a87ad;
font-size: 26px;
}
.content{
width: 45%;
margin: 0 auto;
}
.content >div{
margin-top: 5px;
padding: 20px;
background: #d9edf7;
border-radius: 12px;
}
.content dl{
color: #2d6a88;
line-height: 40px;
}
.content div div {
padding-bottom: 20px;
text-align:center;
}
</style>
</head>
<body>
<div class="content">
<div>
<img id="verify-bar-code" src="http://localhost/1.png">
</div>
<div>
<img id="captcha-verify-image" src="http://localhost/2.png">
</div>
</div>
</body>
</html>
自己做一个测试网站
百分百原创 ,大家一起学习共同进步,喜欢逆向的同学可以关注点点赞,也欢迎私聊。

