
- 1MAC 安装 Homebrew(使用国内镜像源)_homebrew 国内镜像
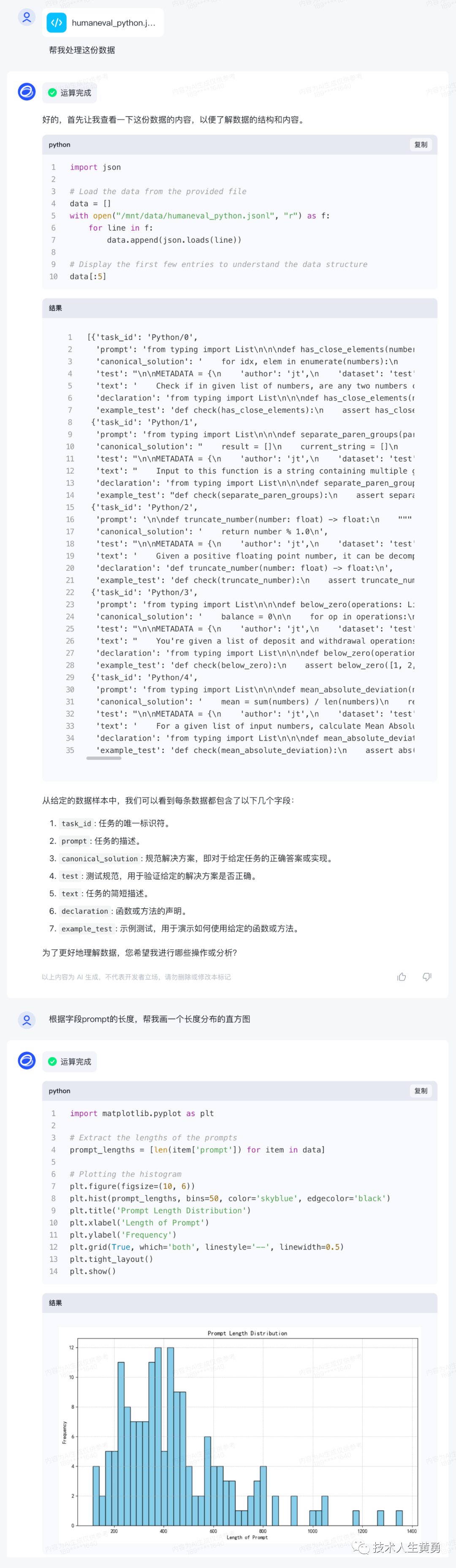
- 2基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的的机械器件识别系统(Python+PySide6界面+训练代码)_机械零件识别检测数据集
- 3android app gps 定位权限,uniapp 打开[ios/安卓]GPS定位权限
- 4【 第十四届蓝桥杯单片机组省赛真题总结】_第十四届蓝桥杯单片机省赛
- 5文件上传漏洞(全网最详细)_文件上传漏洞盲打
- 6MySQL count(*)太慢怎么办_myisam count 慢
- 7Hadoop的调度器总结_作业调度器的作用是将系统中空闲资源
- 8与 Apollo 共创生态:Apollo 7周年大会上感受科技盛宴
- 9学Python真的好找工作吗?工作多年的程序员为你解答_40多岁学python找得到工作吗
- 103位Committer,12场国内外技术实践,2016中国Spark技术峰会议题详解
ChatGLM推出第三代基座大模型在论文阅读、文档摘要和财报分析等方面提升超过50%推理成本降低一半
赞
踩
“ 智谱AI发布了第三代基座大模型ChatGLM3,在模型性能、功能支持、开源序列等方面进行了全面升级。ChatGLM3在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,具有在10B以下的基础模型中最强的性能。同时,ChatGLM3还支持多模态理解、代码增强、联网搜索等新功能,并可支持网络边缘端部署和高效推理。”

01
—
就在今天,智谱AI在 2023 中国计算机大会(CNCC)上,推出了全自研的第三代基座大模型 ChatGLM3 及相关系列产品。
ChatGLM3仍然秉承了开源精神,将模型开源在Github上,地址如下:
https://github.com/THUDM/ChatGLM3
开源的模型参数为最小的型号6B。
相对于之前两个版本,版本3升级的内容:
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
02
—
升级带来的新特性
更好的性能
与 ChatGLM 二代模型相比,在44个中英文公开数据集测试中,ChatGLM3在国内同尺寸模型中排名首位。其中,MMLU提升36%、CEval提升33%、GSM8K提升179% 、BBH提升126%。
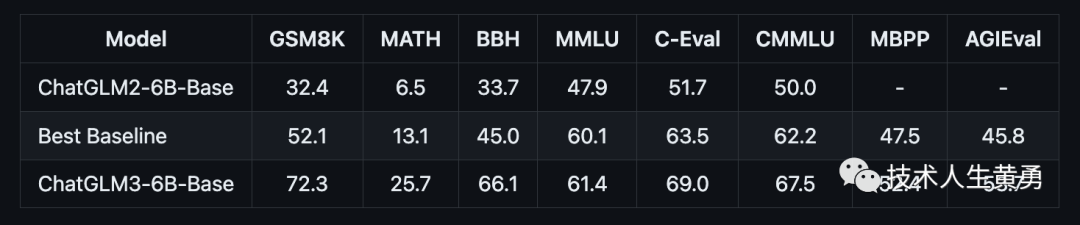
Best Baseline 指的是模型参数在 10B 以下、在对应数据集上表现最好的预训练模型,不包括只针对某一项任务训练而未保持通用能力的模型。
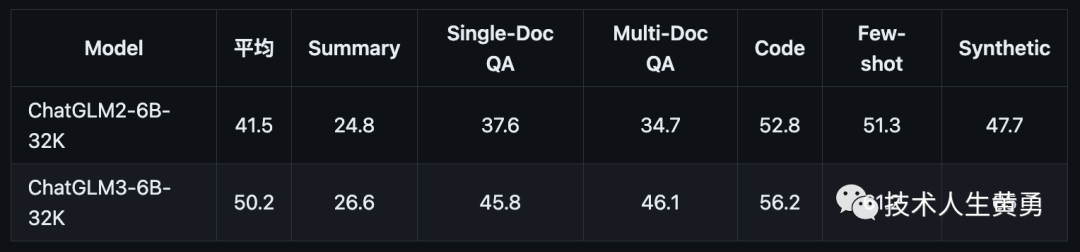
长文本应用场景的人工评估测试结果:
多模态理解
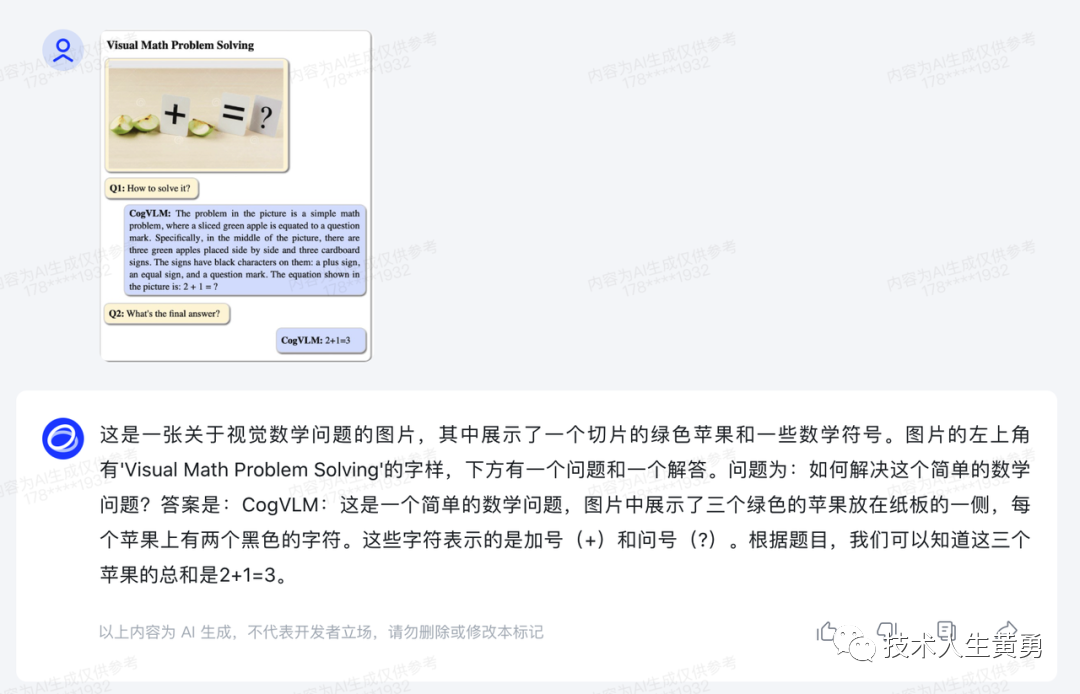
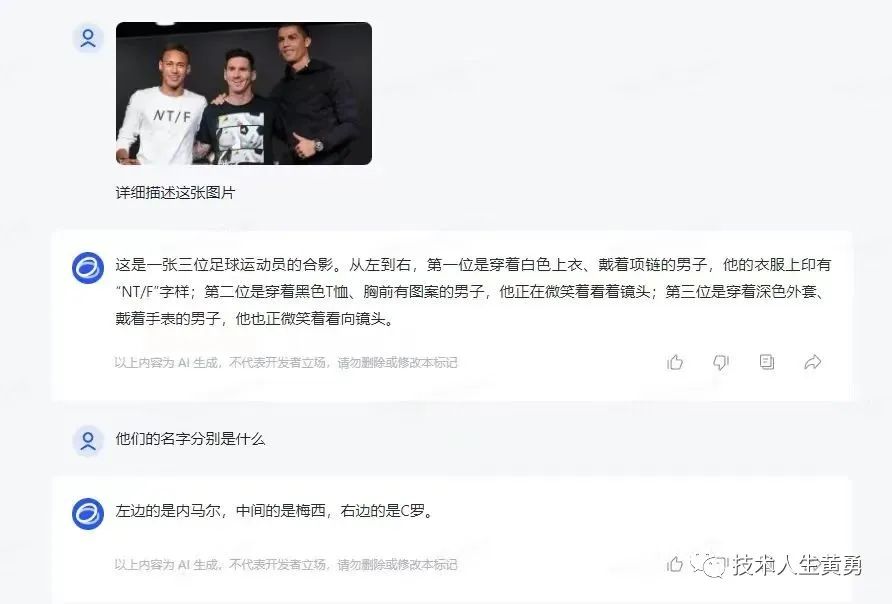
多模态理解即ChatGPT-4V能理解图像的能力。智谱AI的CogVLM,看图识语义,在10余个国际标准图文评测数据集上取得最好成绩。
注:这个,最好成绩,是在图像识别评测上取得,尚不知道实际应用场景能到什么程度。
官方宣传中,CogVLM 可以回答各种类型的视觉问题,并且可以完成复杂的目标检测,并打上标签,完成自动数据标注。
代码增强
Code Interpreter 根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务。
自动分析生成图表
分析SQL语句

联网搜索
WebGLM,接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。

支持网络边缘端(Edge)部署
可手机部署的端测模型 ChatGLM3-1.5B 和 ChatGLM3-3B,支持包括Vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上 CPU 芯片的推理,速度可达20 tokens/s。精度方面 ChatGLM3-1.5B 和 ChatGLM3-3B 在公开 Benchmark 上与 ChatGLM2-6B 模型性能接近。
更高效推理
得益于最新的高效动态推理和显存优化技术,在相同硬件、模型条件下,相较于目前最佳的开源实现,推理速度提升了2-3倍,推理成本降低一倍,每千 tokens 仅0.5分,成本最低。
支持国家信创政策
GLM 系列模型支持在昇腾、神威超算、海光 DCU 架构上进行大规模预训练和推理,当前已支持10余种国产硬件生态,包括昇腾、神威超算、海光DCU、海飞科、沐曦曦云、算能科技、天数智芯、寒武纪、摩尔线程、百度昆仑芯、灵汐科技、长城超云等。
03
—
ChatGLM的官网已经更新到最新版本,可以识别图片。朋友们可以访问下面地址体验。
https://chatglm.cn/

辅助阅读|知识点
基座大模型(Foundation Models)和长文本对话模型(Long-Context Conversation Models)有以下几点主要区别:
适用场景不同
基座大模型更侧重于通用能力,可以适用于多种下游任务,如图像识别、自然语言处理等,提供基础的特征提取和建模能力。
长文本对话模型专注于对话场景,通过预训练获取语言理解和生成能力,以产生更连贯、相干的长对话。
模型结构不同
基座大模型通常采用Transformer等结构,目标是提取通用的语义特征。
长文本对话模型在Transformer基础上进行了优化,加强了对长程上下文的建模能力,以用于多轮交互对话。
训练数据不同
基座大模型使用大规模通用语料进行预训练。
长文本对话模型需要大量高质量的对话语料进行细致预训练。
应用侧重点不同
基座大模型侧重提供通用语义特征,可迁移到下游任务。
长文本对话模型侧重对话能力,可直接应用于智能对话机器人、客服等对话场景。
总体来说,两者都属于大模型家族,但应用场景、模型设计和训练目标有所不同。长文本对话模型更专注对话领域,是在基座模型基础上进行优化的产物。
参考资料:
https://mp.weixin.qq.com/s/JoTodw9ZWDQ38wYsddINyA
https://github.com/THUDM/ChatGLM3
阅读推荐:
StreamingLLM 框架:利用最新标记让 AI 记住你的话、创作长篇小说,探索无限长度文本
大规模语言模型从理论到实践:模型基础、数据、强化学习、应用、评估
如何做大模型的微调实验,记录一次基于ChatGLM-6B 大模型微调实验过程。
ChatGLM团队发布AI Agent能力评测工具AgentBench:GPT-4一骑绝尘,开源模型表现非常糟糕!
教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + LangChain
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。


