
- 1Codeforces Round 943 (Div. 3)(A,B,C,D,E,F,G1,G2)
- 2面试题整理_{"code":1,"message":"service codec unmarshal: unma
- 3supervisor启动进程时报错“gave up: monitor entered FATAL state, too many start retries too quickly”
- 4区块链 Hyperledger sawtooth支持哪些共识算法_sawtooth区块链
- 5数据结构之排序专题 —— 快速排序原理以及改进方法(添加随机,三路快排)_数据结构 快速排序 实验思考
- 6chatgpt赋能python:Python中[:3]的用法介绍_python [:3]
- 7如何更换git远程仓库地址_git修改远程仓库地址
- 8AI作画算法原理
- 901 蓝桥杯单片机设计与开发_标准模板
- 10【Matlab股票价格预测】基于LSTM长短期记忆网络的多变量股票价格预测(附MATLAB代码)_基于lstm的股票价格预测
机器学习周报第40周
赞
踩
摘要
本周,我深入研读了RT-DETR(实时目标检测变换器)论文,并专注于学习了其backbone(主干网络)、AIFI(自适应特征交互)以及CCFM(跨尺度特征融合模块)方面的代码实现。RT-DETR作为一种基于Transformer的目标检测模型,通过其独特的设计,在保持实时性的同时,显著提升了目标检测的精度。
在backbone方面,RT-DETR采用了高效的主干网络,能够快速提取图像中的特征信息。通过学习和理解backbone的代码实现,我深入了解了特征提取的过程以及如何通过卷积层、池化层等结构来逐步提取图像中的多尺度特征。
AIFI模块是RT-DETR中的一个重要创新点,它通过自适应地调整不同特征层之间的交互方式,来增强模型对多尺度目标的检测能力。在学习AIFI的代码实现时,我深入理解了其工作原理和参数调整方法,这有助于我更好地掌握如何在实际应用中优化模型的性能。
CCFM模块是RT-DETR中另一个关键组件,它通过跨尺度特征融合的方式,将不同尺度的特征信息进行有效整合,从而提高了模型对尺度变化的鲁棒性。学习CCFM的代码实现,让我更加深入地理解了如何通过融合操作来增强模型的性能,并为未来的模型设计提供了有价值的参考。
通过本周的学习,我不仅加深了对RT-DETR模型的理解,还掌握了其关键组件的代码实现方法。这些知识和经验将对我未来的研究和工作产生积极的影响。未来,我将继续探索RT-DETR的应用和优化方法,并尝试将其应用于更多的实际场景中
Abstract
This week, I delved into the RT-DETR (Real-Time Detection Transformer) paper and focused on learning the code implementations of its backbone, AIFI (Adaptive Feature Interaction), and CCFM (Cross-scale Feature Fusion Module). RT-DETR, as a Transformer-based object detection model, significantly improves the accuracy of object detection while maintaining real-time performance through its unique design.
In terms of the backbone, RT-DETR employs an efficient main network that can quickly extract feature information from images. By studying and understanding the code implementation of the backbone, I gained a deeper understanding of the feature extraction process and how convolutional layers, pooling layers, and other structures are used to gradually extract multi-scale features from images.
The AIFI module is an important innovation in RT-DETR, which enhances the model’s ability to detect multi-scale objects by adaptively adjusting the interaction between different feature layers. While learning the code implementation of AIFI, I gained a profound understanding of its working principle and parameter adjustment methods, which will help me better optimize the model’s performance in practical applications.
The CCFM module, another crucial component of RT-DETR, integrates feature information from different scales effectively through cross-scale feature fusion, improving the model’s robustness to scale variations. Learning the code implementation of CCFM allowed me to gain a deeper understanding of how fusion operations can enhance model performance, providing valuable references for future model design.
Through this week’s study, I have not only deepened my understanding of the RT-DETR model but also mastered the code implementation methods of its key components. These knowledge and experiences will positively impact my future research and work. In the future, I will continue to explore the applications and optimization methods of RT-DETR and attempt to apply it to more practical scenarios.
一、文献阅读
论文标题:DETRs Beat YOLOs on Real-time Object Detection
1.1 摘要
YOLO系列已经成为最流行的实时目标检测框架,因为它在速度和准确性之间做出了合理的权衡。然而,我们观察到YOLO的速度和准确性受到NMS的负面影响。最近,端到端基于transformer的检测器(DETR)提供了消除NMS的替代方案。然而,高计算成本限制了它们的实用性,并阻碍了它们充分发挥排除NMS的优势。在本文中,我们提出了实时检测Transformer(RT-DETR),第一个实时端到端对象检测器,以我们所知,解决了上述困境。我们借鉴先进的DETR,分两步构建RT-DETR:首先,我们专注于在提高速度的同时保持准确性,其次是在提高准确性的同时保持速度。具体来说,我们设计了一个高效的混合编码器,通过解耦尺度内交互和跨尺度融合来快速处理多尺度特征,以提高速度。然后,我们提出了不确定性最小的查询选择提供高质量的初始查询的解码器,从而提高准确性。此外,RT-DETR支持灵活的速度调整,通过调整解码器层的数量来适应各种场景,而无需重新训练。我们的RT-DETR-R50 / R101在COCO上实现了53.1% / 54.3%的AP,在T4 GPU上实现了108 / 74 FPS,无论是速度还是精度都超过了之前先进的YOLO。此外,RT-DETR-R50在准确性方面优于DINO-R50 2.2%AP,FPS约为21倍。经过Objects 365的预训练后,RTDETR-R50 / R101分别达到了55.3% / 56.2%的AP。
1.2 论文背景
这篇论文的背景主要聚焦于实时目标检测领域,特别是近年来随着深度学习技术的快速发展,目标检测任务在计算机视觉领域取得了显著的进步。目标检测作为计算机视觉的核心任务之一,旨在从图像或视频中识别出特定类别的目标,并确定其位置。实时目标检测则对算法的速度和准确性提出了更高的要求,以满足实际应用中的实时性需求。
在过去的几年中,虽然基于深度学习的目标检测算法在准确性上取得了显著的提升,如Faster R-CNN、SSD、YOLO等,但在实时性方面仍然存在挑战。这些算法往往需要在准确性和速度之间进行权衡,导致在某些实时性要求较高的场景中表现不佳。其中最著名的是YOLO检测器由于它们在速度和准确性之间的合理权衡。然而,这些检测器通常需要非最大值抑制(NMS)进行后处理,这不仅降低了推理速度,而且还引入了超参数,导致速度和精度不稳定。此外,考虑到不同场景对查全率和准确率的重视程度不同,需要仔细选择合适的NMS阈值,这阻碍了实时检测器的发展。
近年来,基于Transformer的目标检测算法逐渐崭露头角,如DETR(Detection Transformer)等,它们通过引入自注意力机制,实现了端到端的目标检测,并在准确性上取得了不错的表现。然而,由于Transformer的计算复杂度较高,这些算法在实时性方面仍然面临挑战。
因此,本论文的背景是在实时目标检测领域,探索一种既具有高精度又具备实时性的目标检测算法。通过深入研究Transformer结构及其在计算效率上的优化,本论文旨在提出一种新颖的实时目标检测算法,以满足实际应用中对实时性和准确性的双重要求。同时,本论文还将对算法的性能进行详细的评估和比较,以验证其在实时目标检测任务中的有效性和优越性。

1.3 论文模型
1.3.1 模型概述
RT-DETR由一个主干、一个高效的混合编码器和一个带有辅助预测头的Transformer解码器组成。RT-DETR的概述如图4所示。具体来说,我们将来自主干的最后三个阶段{S3,S4,S5}的特征馈送到编码器中。高效的混合编码器通过尺度内特征交互和跨尺度特征融合将多尺度特征变换成图像特征序列。随后,采用不确定性最小查询选择来选择固定数量的编码器特征以用作解码器的初始对象查询。最后,具有辅助预测头的解码器迭代地优化对象查询以生成类别和框。
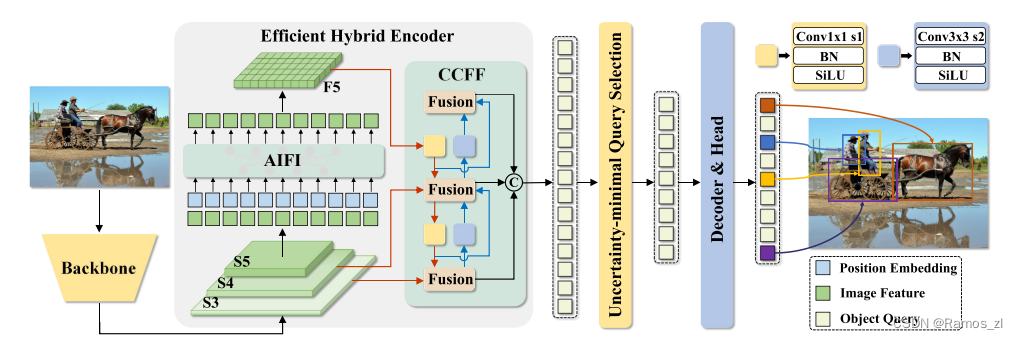
1.3.2 模型细节
主干网络
采用了经典的ResNet和百度自研的HGNet-v2两种,backbone是可以Scaled,应该就是常见的s m l x分大中小几个版本,不过可能由于还要对比众多高精度的DETR系列所以只公布了HGNetv2的L和X两个版本,也分别对标经典的ResNet50和ResNet101,不同于DINO等DETR类检测器使用最后4个stage输出,RT-DETR为了提速只需要最后3个,这样也符合YOLO的风格;
颈部网络
起名为HybridEncoder,其实是相当于DETR中的Encoder,其也类似于经典检测模型模型常用的FPN,论文里分析了Encoder计算量是比较冗余的,作者解耦了基于Transformer的这种全局特征编码,设计了AIFI (尺度内特征交互)和 CCFM(跨尺度特征融合)结合的新的高效混合编码器也就是 Efficient Hybrid Encoder ,此外把encoder_layer层数由6减小到1层,并且由几个通道维度区分L和X两个版本,配合CCFM中RepBlock数量一起调节宽度深度实现Scaled RT-DETR;
Transformer
起名为RTDETRTransformer,基于DINO Transformer中的decoder改动的不多;
Head和Loss
和DINOHead基本一样,从RT-DETR的配置文件其实也可以看出neck+transformer+detr_head其实就是一整个Transformer,拆开写还是有点像YOLO类的风格。而训练加入了IoU-Aware的query selection,这个思路也是针对分类score和iou未必一致而设计的,改进后提供了更高质量(高分类分数和高IoU分数)的decoder特征;
Reader和训练策略
Reader采用的是YOLO风格的简单640尺度,没有DETR类检测器复杂的多尺度resize,其实也就是原先他们PPYOLOE系列的reader,都是非常基础的数据增强,0均值1方差的NormalizeImage大概是为了节省部署时图片前处理的耗时,然后也没有用到别的YOLO惯用的mosaic等trick;训练策略和优化器,采用的是DETR类检测器常用的AdamW,毕竟模型主体还是DETR类的;
1.4 模型精度
RT-DETR和各大YOLO和DETR的精度对比:
(1)对比YOLO系列:
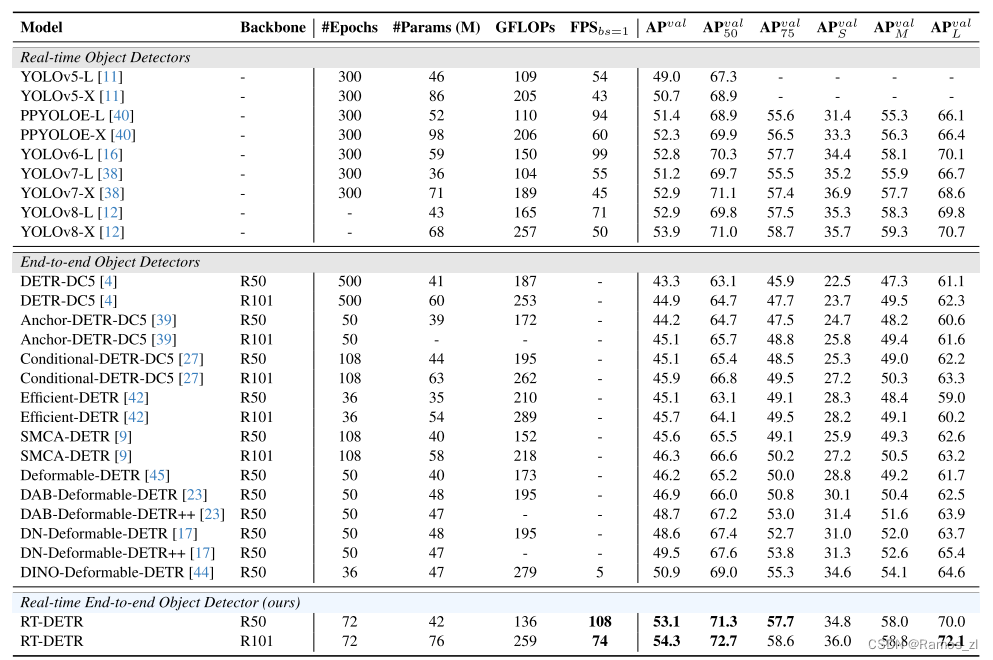
同级别下RT-DETR比所有的YOLO都更高,而且这还只是RT-DETR训练72个epoch的结果,先前精度最高的YOLOv8都是需要训500个epoch的,其他YOLO也基本都需要训300epoch,这个训练时间成本就不在一个级别了,对于训练资源有限的用户或项目是非常友好的。之前各大YOLO模型在COCO数据集上,同级别的L版本都还没有突破53 mAP的,X版本也没有突破54 mAP的,唯一例外的YOLO还是RT-DETR团队他们先前搞的PP-YOLOE+,借助objects365预训练只80epoch X版本就刷到了54.7 mAP,而蒸馏后的L版本更刷到了54.0 mAP。此外RT-DETR的参数量FLOPs上也非常可观,换用HGNetv2后更优。
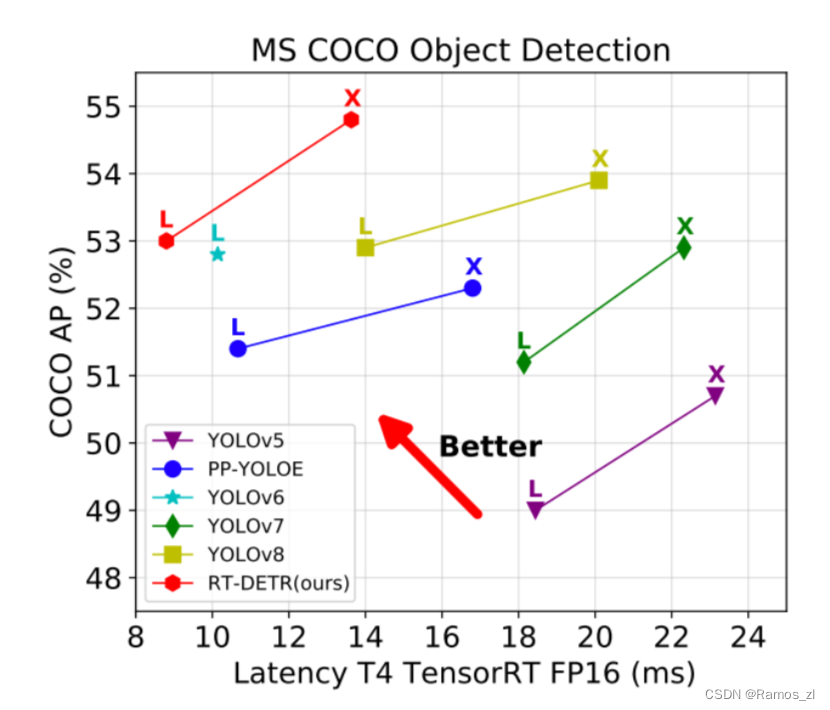
(2)对比DETR系列:
DETR类在COCO上常用的尺度都是800x1333,以往都是以Res50 backbone刷上45 mAP甚至50 mAP为目标,而RT-DETR在采用了YOLO风格的640x640尺度情况下,也不需要熬时长训几百个epoch 就能轻松突破50mAP,精度也远高于所有DETR类模型。此外值得注意的是,RT-DETR只需要300个queries,设置更大比如像DINO的900个肯定还会更高,但是应该会变慢很多意义不大。
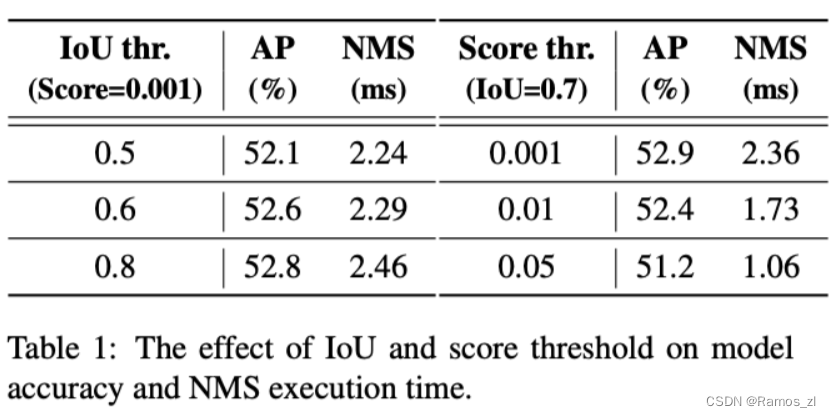
关于NMS的分析:
针对NMS的2个超参数得分阈值和IoU阈值,作者不仅分析了不同得分阈值过滤后的剩余预测框数,也分析了不同NMS超参数下精度和NMS执行时间,结论是NMS其实非常敏感,如果真的实际应用,不仅调参麻烦而且精度速度波动很大。以往YOLO论文中都会比一个纯模型去NMS后的速度FPS之类的,其实也很容易发现各大YOLO的NMS参数不一,而且真实应用的时候都得加上NMS才能出精确的检测框结果,所以端到端的FPS和论文公布的FPS(纯模型)不是一回事,明显会更慢的多,可以说是虚假的实时性。
二、论文代码
2.1 rtdetr.py
class RTDETR(nn.Module): __inject__ = ['backbone', 'encoder', 'decoder', ] def __init__(self, backbone: nn.Module, encoder, decoder, multi_scale=None): super().__init__() self.backbone = backbone self.decoder = decoder self.encoder = encoder self.multi_scale = multi_scale def forward(self, x, targets=None): if self.multi_scale and self.training: sz = np.random.choice(self.multi_scale) x = F.interpolate(x, size=[sz, sz]) x = self.backbone(x) x = self.encoder(x) x = self.decoder(x, targets) return x def deploy(self, ): self.eval() for m in self.modules(): if hasattr(m, 'convert_to_deploy'): m.convert_to_deploy() return self

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.2 backbone模块
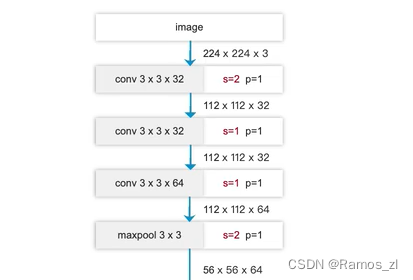
backbone之一是对resnet的改造,命名为presnet,主要修改两点:
第一是把开始阶段的7x7卷积改为三组3x3卷积,通过调整步长使得输出shape与原来的7x7保持一致,这样可以更好地提取特征。

第二是把resnetblock中1x1,步长为2的池化模块替换为步长为2的全局池化,然后1x1调整通道数,这样做的目的是原来的下采样方式会丢失信息,修改后更多地保留信息。
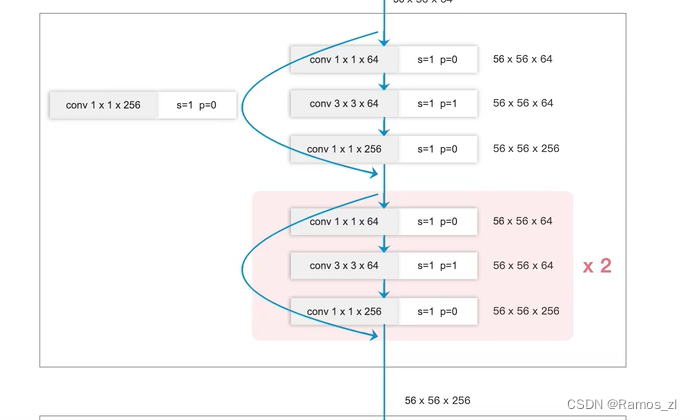

具体代码如下:
class PResNet(nn.Module): def __init__( self, depth, variant='d', num_stages=4, return_idx=[0, 1, 2, 3], act='relu', freeze_at=-1, freeze_norm=True, pretrained=False): super().__init__() block_nums = ResNet_cfg[depth] ch_in = 64 if variant in ['c', 'd']: conv_def = [ [3, ch_in // 2, 3, 2, "conv1_1"], [ch_in // 2, ch_in // 2, 3, 1, "conv1_2"], [ch_in // 2, ch_in, 3, 1, "conv1_3"], ] else: conv_def = [[3, ch_in, 7, 2, "conv1_1"]] self.conv1 = nn.Sequential(OrderedDict([ (_name, ConvNormLayer(c_in, c_out, k, s, act=act)) for c_in, c_out, k, s, _name in conv_def ])) ch_out_list = [64, 128, 256, 512] block = BottleNeck if depth >= 50 else BasicBlock _out_channels = [block.expansion * v for v in ch_out_list] _out_strides = [4, 8, 16, 32] self.res_layers = nn.ModuleList() for i in range(num_stages): stage_num = i + 2 self.res_layers.append( Blocks(block, ch_in, ch_out_list[i], block_nums[i], stage_num, act=act, variant=variant) ) ch_in = _out_channels[i] self.return_idx = return_idx self.out_channels = [_out_channels[_i] for _i in return_idx] self.out_strides = [_out_strides[_i] for _i in return_idx] if freeze_at >= 0: self._freeze_parameters(self.conv1) for i in range(min(freeze_at, num_stages)): self._freeze_parameters(self.res_layers[i]) if freeze_norm: self._freeze_norm(self) if pretrained: state = torch.hub.load_state_dict_from_url(donwload_url[depth]) self.load_state_dict(state) print(f'Load PResNet{depth} state_dict') def _freeze_parameters(self, m: nn.Module): for p in m.parameters(): p.requires_grad = False def _freeze_norm(self, m: nn.Module): if isinstance(m, nn.BatchNorm2d): m = FrozenBatchNorm2d(m.num_features) else: for name, child in m.named_children(): _child = self._freeze_norm(child) if _child is not child: setattr(m, name, _child) return m def forward(self, x): conv1 = self.conv1(x) x = F.max_pool2d(conv1, kernel_size=3, stride=2, padding=1) outs = [] for idx, stage in enumerate(self.res_layers): x = stage(x) if idx in self.return_idx: outs.append(x) return outs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
2.3 AIFI
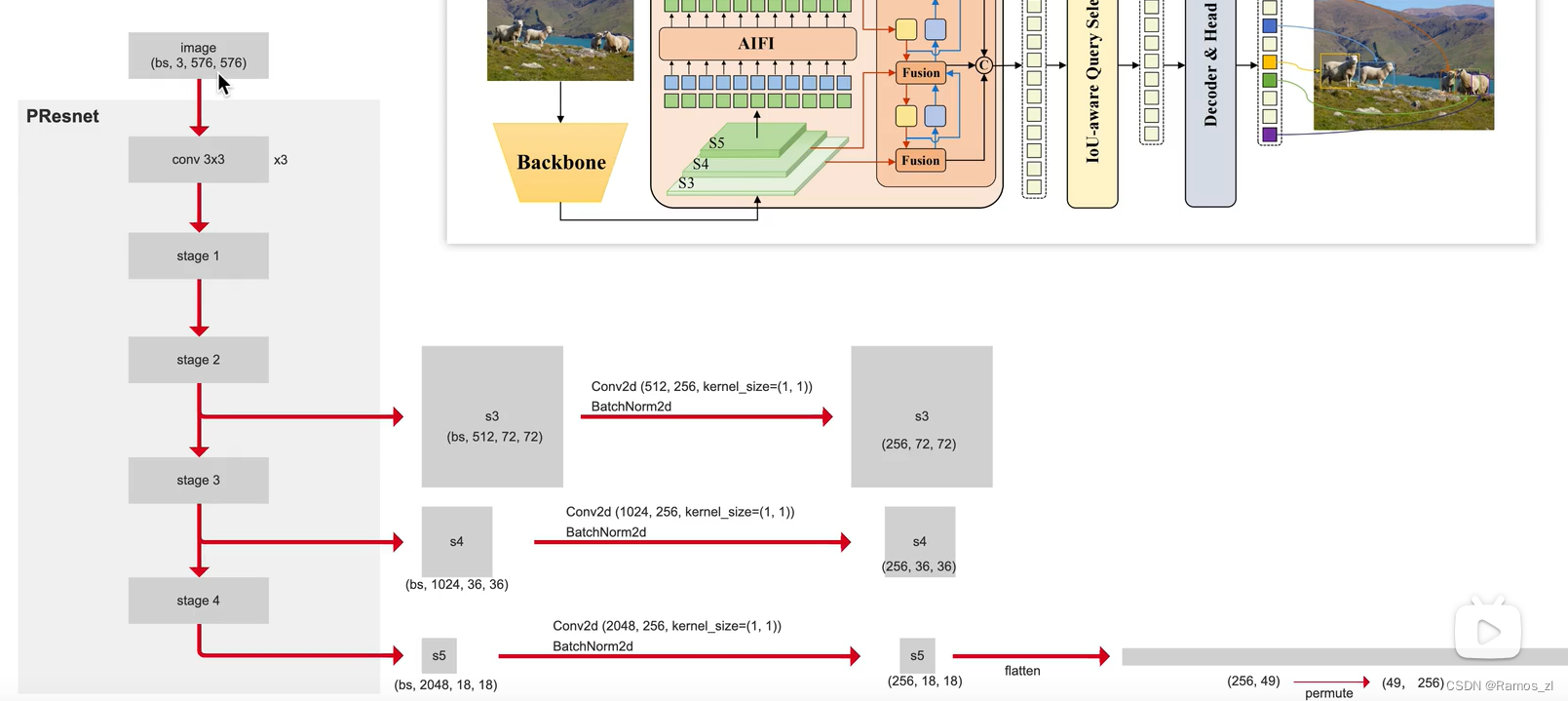
使用backbone输出的s5进行transformer编码
src/zoo/rtdetr/hybrid_encoder.py (class HybridEncoder)
其中self.input_proj是一个包含3个线性结构的ModuleList,作用是将s3,s4,s5的统一输出通道数,为了以后的尺度间融合
self.encoder是transformer的编码器结构,代码中套了好几层,模型结构如下所示。在detr和deformable detr中encode是6层,这里为加快运行速度,只使用了一层encoder。
class HybridEncoder(nn.Module): def __init__(self, in_channels=[512, 1024, 2048], feat_strides=[8, 16, 32], hidden_dim=256, nhead=8, dim_feedforward = 1024, dropout=0.0, enc_act='gelu', use_encoder_idx=[2], num_encoder_layers=1, pe_temperature=10000, expansion=1.0, depth_mult=1.0, act='silu', eval_spatial_size=None): super().__init__() self.in_channels = in_channels self.feat_strides = feat_strides self.hidden_dim = hidden_dim self.use_encoder_idx = use_encoder_idx self.num_encoder_layers = num_encoder_layers self.pe_temperature = pe_temperature self.eval_spatial_size = eval_spatial_size self.out_channels = [hidden_dim for _ in range(len(in_channels))] self.out_strides = feat_strides # channel projection self.input_proj = nn.ModuleList() for in_channel in in_channels: self.input_proj.append( nn.Sequential( nn.Conv2d(in_channel, hidden_dim, kernel_size=1, bias=False), nn.BatchNorm2d(hidden_dim) ) ) # encoder transformer encoder_layer = TransformerEncoderLayer( hidden_dim, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout, activation=enc_act) self.encoder = nn.ModuleList([ TransformerEncoder(copy.deepcopy(encoder_layer), num_encoder_layers) for _ in range(len(use_encoder_idx)) ]) # top-down fpn self.lateral_convs = nn.ModuleList() self.fpn_blocks = nn.ModuleList() for _ in range(len(in_channels) - 1, 0, -1): self.lateral_convs.append(ConvNormLayer(hidden_dim, hidden_dim, 1, 1, act=act)) self.fpn_blocks.append( CSPRepLayer(hidden_dim * 2, hidden_dim, round(3 * depth_mult), act=act, expansion=expansion) ) # bottom-up pan self.downsample_convs = nn.ModuleList() self.pan_blocks = nn.ModuleList() for _ in range(len(in_channels) - 1): self.downsample_convs.append( ConvNormLayer(hidden_dim, hidden_dim, 3, 2, act=act) ) self.pan_blocks.append( CSPRepLayer(hidden_dim * 2, hidden_dim, round(3 * depth_mult), act=act, expansion=expansion) ) self._reset_parameters() def _reset_parameters(self): if self.eval_spatial_size: for idx in self.use_encoder_idx: stride = self.feat_strides[idx] pos_embed = self.build_2d_sincos_position_embedding( self.eval_spatial_size[1] // stride, self.eval_spatial_size[0] // stride, self.hidden_dim, self.pe_temperature) setattr(self, f'pos_embed{idx}', pos_embed) # self.register_buffer(f'pos_embed{idx}', pos_embed) @staticmethod def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.): ''' ''' grid_w = torch.arange(int(w), dtype=torch.float32) grid_h = torch.arange(int(h), dtype=torch.float32) grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij') assert embed_dim % 4 == 0, \ 'Embed dimension must be divisible by 4 for 2D sin-cos position embedding' pos_dim = embed_dim // 4 omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim omega = 1. / (temperature ** omega) out_w = grid_w.flatten()[..., None] @ omega[None] out_h = grid_h.flatten()[..., None] @ omega[None] return torch.concat([out_w.sin(), out_w.cos(), out_h.sin(), out_h.cos()], dim=1)[None, :, :] def forward(self, feats): assert len(feats) == len(self.in_channels) proj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)] # encoder if self.num_encoder_layers > 0: for i, enc_ind in enumerate(self.use_encoder_idx): h, w = proj_feats[enc_ind].shape[2:] # flatten [B, C, H, W] to [B, HxW, C] src_flatten = proj_feats[enc_ind].flatten(2).permute(0, 2, 1) if self.training or self.eval_spatial_size is None: pos_embed = self.build_2d_sincos_position_embedding( w, h, self.hidden_dim, self.pe_temperature).to(src_flatten.device) else: pos_embed = getattr(self, f'pos_embed{enc_ind}', None).to(src_flatten.device) memory = self.encoder[i](src_flatten, pos_embed=pos_embed) proj_feats[enc_ind] = memory.permute(0, 2, 1).reshape(-1, self.hidden_dim, h, w).contiguous() # print([x.is_contiguous() for x in proj_feats ]) # broadcasting and fusion inner_outs = [proj_feats[-1]] for idx in range(len(self.in_channels) - 1, 0, -1): feat_high = inner_outs[0] feat_low = proj_feats[idx - 1] feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_high) inner_outs[0] = feat_high upsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest') inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1)) inner_outs.insert(0, inner_out) outs = [inner_outs[0]] for idx in range(len(self.in_channels) - 1): feat_low = outs[-1] feat_high = inner_outs[idx + 1] downsample_feat = self.downsample_convs[idx](feat_low) out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_high], dim=1)) outs.append(out) return outs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
关于AIFI编码器 memory = self.encoder[i](src_flatten, pos_embed=pos_embed) 的实现部分如下:
在当前模块的TransformerEncoderLayer类中
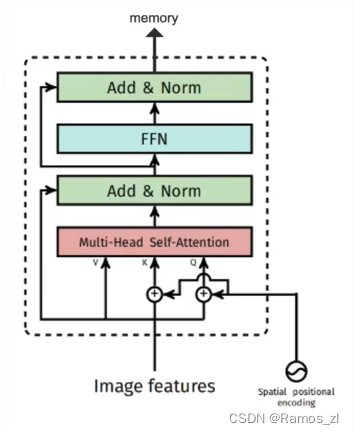
class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False): super().__init__() self.normalize_before = normalize_before self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout, batch_first=True) self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.activation = get_activation(activation) @staticmethod def with_pos_embed(tensor, pos_embed): return tensor if pos_embed is None else tensor + pos_embed def forward(self, src, src_mask=None, pos_embed=None) -> torch.Tensor: residual = src if self.normalize_before: src = self.norm1(src) q = k = self.with_pos_embed(src, pos_embed) src, _ = self.self_attn(q, k, value=src, attn_mask=src_mask) src = residual + self.dropout1(src) if not self.normalize_before: src = self.norm1(src) residual = src if self.normalize_before: src = self.norm2(src) src = self.linear2(self.dropout(self.activation(self.linear1(src)))) src = residual + self.dropout2(src) if not self.normalize_before: src = self.norm2(src) return src
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
2.4 CCFM
CCFM的示意图如下图所示:
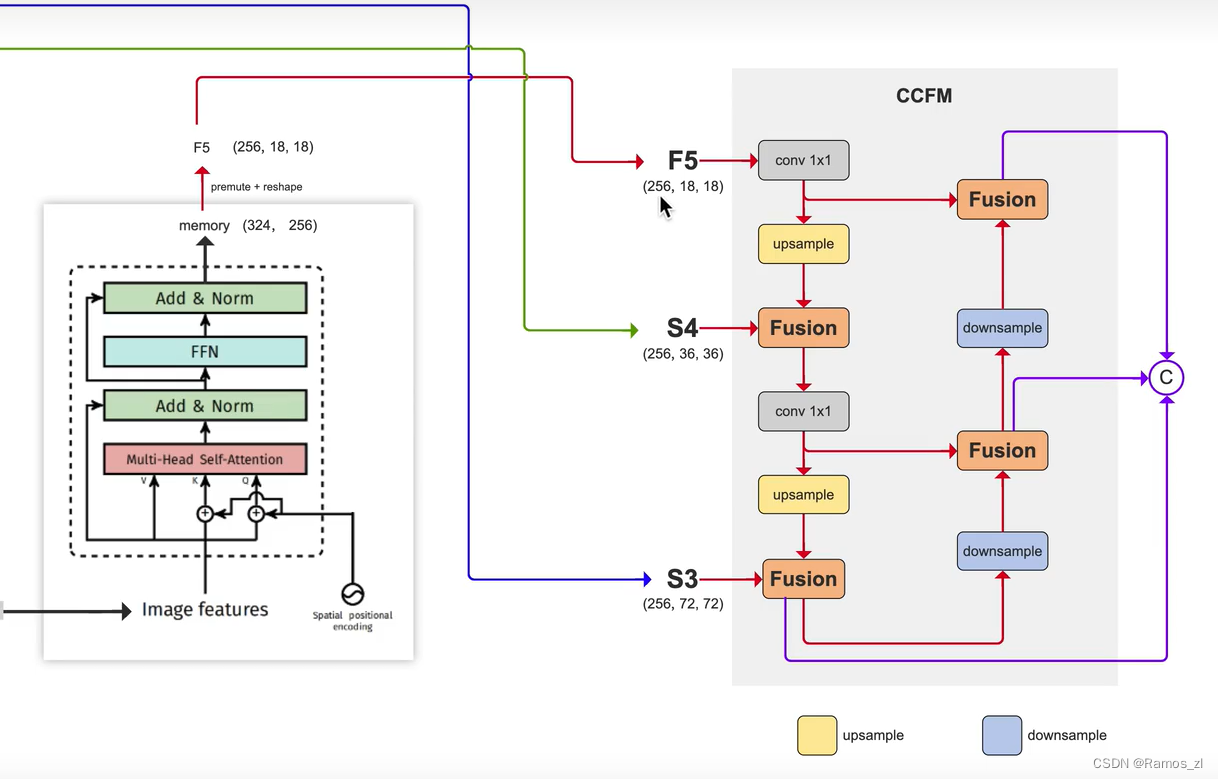
CCFM是一个轻量级跨尺度特征融合模块。该模块的主要原理是将不同尺度的特征通过融合操作整合起来,以增强模型对于尺度变化的适应性和对小尺度对象的检测能力。
代码如下:
inner_outs = [proj_feats[-1]] for idx in range(len(self.in_channels) - 1, 0, -1): feat_high = inner_outs[0] feat_low = proj_feats[idx - 1] feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_high) inner_outs[0] = feat_high upsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest') inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1)) inner_outs.insert(0, inner_out) outs = [inner_outs[0]] for idx in range(len(self.in_channels) - 1): feat_low = outs[-1] feat_high = inner_outs[idx + 1] downsample_feat = self.downsample_convs[idx](feat_low) out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_high], dim=1)) outs.append(out) return outs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结
通过本周的学习,我不仅掌握了RT-DETR的基本原理和实现方法,还对其在实际应用中的潜力和挑战有了更全面的了解。我相信这些知识和经验将对我未来的研究和工作产生积极的影响。我将继续探索RT-DETR的更多应用场景和优化方法,尝试将其应用于更广泛的领域,并不断优化和完善其性能。同时,我也将关注其他相关领域的最新进展,以期在目标检测领域取得更多的突破。下周我将继续学习RT-DETR后续的模块。

