
- 1大语言模型与词向量表示
- 2万字长文简单明了的介绍xxl-job以及quartz_quartz和xxl-job
- 3git新手指南——git相关命令_git丢弃工作区修改
- 4LINUX——账号和权限管理_linux 设置账号权限
- 5Redis基本安装与使用_redis-cli 需要安装嘛
- 6Transformer中Multi-head Attention的作用_transformer多头注意力机制的作用
- 7Flutter学习指南:交互、手势和动画(2),看完全都会了_flutter各种手势
- 8千川-付费投流课,千川从0-1.精准分析,重构逻辑实战训练(32节课)
- 9【介绍下如何使用CocoaPods】
- 10涨知识啦!如何使用3dMax和Vray渲染三维室内平面图效果图?
目标检测 3—— 人脸检测_人脸检测 two stage method
赞
踩
笔记来源:DeepLearning-500-questions
上次学习了目标检测的基本概念 Two Stage和 One Stage 算法:
1.目标检测Two Stage
4 人脸检测
在目标检测领域可以划分为了人脸检测与通用目标检测,往往人脸这方面会有专门的算法(包括人脸检测、人脸识别、人脸其他属性的识别等等),并且和通用目标检测(识别)会有一定的差别,着主要来源于人脸的特殊性(有时候目标比较小、人脸之间特征不明显、遮挡问题等),下面将从人脸检测和通用目标检测两个方面来讲解目标检测。
4.1 目前主要有人脸检测方法分类?
目前人脸检测方法主要包含两个区域:传统人脸检测算法和基于深度学习的人脸检测算法。传统人脸检测算法主要可以分为4类:
(1)基于知识的人脸检测方法;
(2)基于模型的人脸检测方法;
(3)基于特征的人脸检测方法;
(4)基于外观的人脸检测方法。
由于本书着重关注深度学习,下面会着重介绍基于深度学习的人脸检测方法。
2006年Hinton首次提出深度学习(Deep Learning)的概念,它是通过组合低层的特征形成更高层的抽象特征。随后研究者将深度学习应用在人脸检测领域,主要集中在基于卷积神经网络(CNN)的人脸检测研究,如基于级联卷积神经网络的人脸检测(cascade cnn)、 基于多任务卷积神经网络的人脸检测(MTCNN)、Facebox等,很大程度上提高了人脸检测的鲁棒性。当然通用目标检测算法像Faster-rcnn、yolo、ssd等也有用在人脸检测领域,也可以实现比较不错的结果,但是和专门人脸检测算法比还是有差别。下面部分主要介绍基于深度学习的的人脸检测算法,基于深度学习的通用目标检测算法将在第二大节介绍。
4.2 如何检测图片中不同大小的人脸?
传统人脸检测算法中针对不同大小人脸主要有两个策略:
(1)缩放图片的大小(图像金字塔如图4.1所示);
(2)缩放滑动窗的大小(如图4.2所示)。

图 4.1 图像金字塔

图 4.2 缩放滑动窗口
基于深度学习的人脸检测算法中针对不同大小人脸主要也有两个策略,但和传统人脸检测算法有点区别,主要包括:
(1)缩放图片大小。(不过也可以通过缩放滑动窗的方式,基于深度学习的滑动窗人脸检测方式效率会很慢存在多次重复卷积,所以要采用全卷积神经网络(FCN),用FCN将不能用滑动窗的方法。)
(2)通过anchor box的方法(如图8.3所示,不要和图8.2混淆,这里是通过特征图预测原图的anchor box区域,具体在facebox中有描述)。

图 4.3 anchor box
4.3 如何设定算法检测最小人脸尺寸?
主要是看滑动窗的最小窗口和anchorbox的最小窗口。
(1)滑动窗的方法
假设通过12×12的滑动窗,不对原图做缩放的话,就可以检测原图中12×12的最小人脸。但是往往通常给定最小人脸a=40、或者a=80,以这么大的输入训练CNN进行人脸检测不太现实,速度会很慢,并且下一次需求最小人脸a=30*30又要去重新训练,通常还会是12×12的输入,为满足最小人脸框a,只需要在检测的时候对原图进行缩放即可:w=w×12/a。
(2)anchorbox的方法
原理类似,这里主要看anchorbox的最小box,通过可以通过缩放输入图片实现最小人脸的设定。
4.4 如何定位人脸的位置?
(1)滑动窗的方式:
滑动窗的方式是基于分类器识别为人脸的框的位置确定最终的人脸,
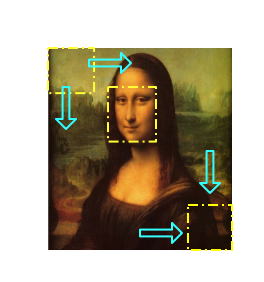
图 4.4 滑动窗
(2)FCN的方式:
FCN的方式通过特征图映射到原图的方式确定最终识别为人脸的位置,特征图映射到原图人脸框是要看特征图相比较于原图有多少次缩放(缩放主要查看卷积的步长和池化层),假设特征图上(2,3)的点,可粗略计算缩放比例为8倍,原图中的点应该是(16,24);如果训练的FCN为12*12的输入,对于原图框位置应该是(16,24,12,12),当然这只是估计位置,具体的再构建网络时要加入回归框的预测,主要是相对于原图框的一个平移与缩放。
(3)通过anchor box的方式:
通过特征图映射到图的窗口,通过特征图映射到原图到多个框的方式确定最终识别为人脸的位置。
4.5 如何通过一个人脸的多个框确定最终人脸框位置?

图 4.5 通过NMS得到最终的人脸位置
NMS改进版本有很多,最原始的NMS就是判断两个框的交集,如果交集大于设定的阈值,将删除其中一个框,那么两个框应该怎么选择删除哪一个呢? 因为模型输出有概率值,一般会优选选择概率小的框删除。
4.6 基于级联卷积神经网络的人脸检测(Cascade CNN)
- cascade cnn的框架结构是什么?

级联结构中有6个CNN,3个CNN用于人脸非人脸二分类,另外3个CNN用于人脸区域的边框校正。给定一幅图像,12-net密集扫描整幅图片,拒绝90%以上的窗口。剩余的窗口输入到12-calibration-net中调整大小和位置,以接近真实目标。接着输入到NMS中,消除高度重叠窗口。下面网络与上面类似。
- cascade cnn人脸校验模块原理是什么?
该网络用于窗口校正,使用三个偏移变量:Xn:水平平移量,Yn:垂直平移量,Sn:宽高比缩放。候选框口(x,y,w,h)中,(x,y)表示左上点坐标,(w,h)表示宽和高。
我们要将窗口的控制坐标调整为:
(
x
−
x
n
w
/
s
n
,
y
−
y
n
h
/
s
n
,
w
/
s
n
,
h
/
s
n
)
(x-{x_nw}/{s_n},y-{y_nh}/{s_n},{w}/{s_n},{h}/{s_n})
(x−xnw/sn,y−ynh/sn,w/sn,h/sn)
这项工作中,我们有
N
=
5
×
3
×
3
=
45
N=5×3×3=45
N=5×3×3=45种模式。偏移向量三个参数包括以下值:
S
n
:
(
0.83
,
0.91
,
1.0
,
1.10
,
1.21
)
Sn:(0.83,0.91,1.0,1.10,1.21)
Sn:(0.83,0.91,1.0,1.10,1.21)
X n : ( − 0.17 , 0 , 0.17 ) Xn:(-0.17,0,0.17) Xn:(−0.17,0,0.17)
Y n : ( − 0.17 , 0 , 0.17 ) Yn:(-0.17,0,0.17) Yn:(−0.17,0,0.17)
同时对偏移向量三个参数进行校正。

3、训练样本应该如何准备?
人脸样本:
非人脸样本:
- 级联的好处
级联的工作原理和好处:
- 最初阶段的网络可以比较简单,判别阈值可以设得宽松一点,这样就可以在保持较高召回率的同时排除掉大量的非人脸窗口;
- 最后阶段网络为了保证足够的性能,因此一般设计的比较复杂,但由于只需要处理前面剩下的窗口,因此可以保证足够的效率;
- 级联的思想可以帮助我们去组合利用性能较差的分类器,同时又可以获得一定的效率保证。
4.7 基于多任务卷积神经网络的人脸检测(MTCNN)

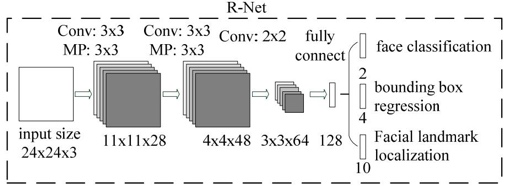

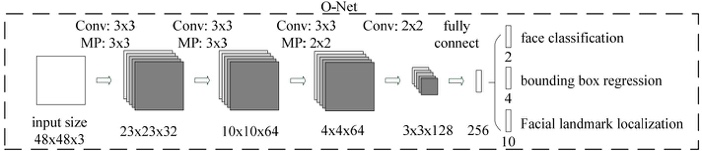
1.MTCNN模型有三个子网络。分别是P-Net,R-Net,O-Net.我想问一下,1.模型中的三个input size是指的是同一张图resize到不同尺度下喂给不同模型,还是同一张图,依次经过三个模型,然后是不同的输入尺寸?(这部分能给我讲一下吗)2.每个模型它都有对应三个结果(face classification;bounding box;facial landmark)这三个在网络上是如何对应的呢?
为了检测不同大小的人脸,开始需要构建图像金字塔,先经过pNet模型,输出人脸类别和边界框(边界框的预测为了对特征图映射到原图的框平移和缩放得到更准确的框),将识别为人脸的框映射到原图框位置可以获取patch,之后每一个patch通过resize的方式输入到rNet,识别为人脸的框并且预测更准确的人脸框,最后rNet识别为人脸的的每一个patch通过resize的方式输入到oNet,跟rNet类似,关键点是为了在训练集有限情况下使模型更鲁棒。
还要注意一点构建图像金字塔的的缩放比例要保留,为了将边界框映射到最开始原图上的
还要注意一点:如何从featureMap映射回原图
4.8 Facebox

(1)Rapidly Digested Convolutional Layers(RDCL)
在网络前期,使用RDCL快速的缩小feature map的大小。 主要设计原则如下:
- Conv1, Pool1, Conv2 和 Pool2 的stride分别是4, 2, 2 和 2。这样整个RDCL的stride就是32,可以很快把feature map的尺寸变小。
- 卷积(或pooling)核太大速度就慢,太小覆盖信息又不足。文章权衡之后,将Conv1, Pool1, Conv2 和 Pool2 的核大小分别设为7x7,3x3,5x5,3x3
- 使用CReLU来保证输出维度不变的情况下,减少卷积核数量。
(2)Multiple Scale Convolutional Layers(MSCL)
在网络后期,使用MSCL更好地检测不同尺度的人脸。 主要设计原则有:
- 类似于SSD,在网络的不同层进行检测;
- 采用Inception模块。由于Inception包含多个不同的卷积分支,因此可以进一步使得感受野多样化。
(3)Anchor densification strategy
为了anchor密度均衡,可以对密度不足的anchor以中心进行偏移加倍,如下图所示:

5 目标检测的技巧汇总
- Data Augmentation
- OHEM
- NMS:Soft NMS/ Polygon NMS/ Inclined NMS/ ConvNMS/ Yes-Net NMS/ Softer NMS
- Multi Scale Training/Testing
- 建立小物体与context的关系
- 参考relation network
- 结合GAN
- 结合attention
6 目标检测的常用数据集
6.1 PASCAL VOC
VOC数据集是目标检测经常用的一个数据集,自2005年起每年举办一次比赛,最开始只有4类,到2007年扩充为20个类,共有两个常用的版本:2007和2012。学术界常用5k的train/val 2007和16k的train/val 2012作为训练集,test 2007作为测试集,用10k的train/val 2007+test 2007和16k的train/val 2012作为训练集,test2012作为测试集,分别汇报结果。
6.2 MS COCO
COCO数据集是微软团队发布的一个可以用来图像recognition+segmentation+captioning 数据集,该数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展。依托这一数据集,每年举办一次比赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中心任务,是继ImageNet Chanllenge以来最有影响力的学术竞赛之一。
相比ImageNet,COCO更加偏好目标与其场景共同出现的图片,即non-iconic images。这样的图片能够反映视觉上的语义,更符合图像理解的任务要求。而相对的iconic images则更适合浅语义的图像分类等任务。
COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通用的划分是使用train和35k的val子集作为训练集(trainval35k),使用剩余的val作为测试集(minival),同时向官方的evaluation server提交结果(test-dev)。除此之外,COCO官方也保留一部分test数据作为比赛的评测集。
6.3 Google Open Image
Open Image是谷歌团队发布的数据集。最新发布的Open Images V4包含190万图像、600个种类,1540万个bounding-box标注,是当前最大的带物体位置标注信息的数据集。这些边界框大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。另外,这些图像是非常多样化的,并且通常包含有多个对象的复杂场景(平均每个图像 8 个)。
6.4 ImageNet
ImageNet是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。ImageNet是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
7 目标检测常用标注工具
7.1 LabelImg
LabelImg 是一款开源的图像标注工具,标签可用于分类和目标检测,它是用 Python 编写的,并使用Qt作为其图形界面,简单好用。注释以 PASCAL VOC 格式保存为 XML 文件,这是 ImageNet 使用的格式。 此外,它还支持 COCO 数据集格式。
7.2 labelme
labelme 是一款开源的图像/视频标注工具,标签可用于目标检测、分割和分类。灵感是来自于 MIT 开源的一款标注工具 LabelMe。labelme 具有的特点是:
- 支持图像的标注的组件有:矩形框,多边形,圆,线,点(rectangle, polygons, circle, lines, points)
- 支持视频标注
- GUI 自定义
- 支持导出 VOC 格式用于 semantic/instance segmentation
- 支出导出 COCO 格式用于 instance segmentation
7.3 Labelbox
Labelbox 是一家为机器学习应用程序创建、管理和维护数据集的服务提供商,其中包含一款部分免费的数据标签工具,包含图像分类和分割,文本,音频和视频注释的接口,其中图像视频标注具有的功能如下:
- 可用于标注的组件有:矩形框,多边形,线,点,画笔,超像素等(bounding box, polygons, lines, points,brush, subpixels)
- 标签可用于分类,分割,目标检测等
- 以 JSON / CSV / WKT / COCO / Pascal VOC 等格式导出数据
- 支持 Tiled Imagery (Maps)
- 支持视频标注 (快要更新)
7.4 RectLabel
RectLabel 是一款在线免费图像标注工具,标签可用于目标检测、分割和分类。具有的功能或特点:
- 可用的组件:矩形框,多边形,三次贝塞尔曲线,直线和点,画笔,超像素
- 可只标记整张图像而不绘制
- 可使用画笔和超像素
- 导出为YOLO,KITTI,COCO JSON和CSV格式
- 以PASCAL VOC XML格式读写
- 使用Core ML模型自动标记图像
- 将视频转换为图像帧
7.5 CVAT
CVAT 是一款开源的基于网络的交互式视频/图像标注工具,是对加州视频标注工具(Video Annotation Tool) 项目的重新设计和实现。OpenCV团队正在使用该工具来标注不同属性的数百万个对象,许多 UI 和 UX 的决策都基于专业数据标注团队的反馈。具有的功能
- 关键帧之间的边界框插值
- 自动标注(使用TensorFlow OD API 和 Intel OpenVINO IR格式的深度学习模型)
7.6 VIA
VGG Image Annotator(VIA)是一款简单独立的手动注释软件,适用于图像,音频和视频。 VIA 在 Web 浏览器中运行,不需要任何安装或设置。 页面可在大多数现代Web浏览器中作为离线应用程序运行。
- 支持标注的区域组件有:矩形,圆形,椭圆形,多边形,点和折线
8.7.6 其他标注工具
liblabel,一个用 MATLAB 写的轻量级 语义/示例(semantic/instance) 标注工具。
ImageTagger:一个开源的图像标注平台。
Anno-Mage:一个利用深度学习模型半自动图像标注工具,预训练模型是基于MS COCO数据集,用 RetinaNet 训练的。
参考文献:
https://github.com/amusi/awesome-object-detection
https://github.com/hoya012/deep_learning_object_detection
https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html
https://www.zhihu.com/question/272322209/answer/482922713
http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
https://blog.csdn.net/hw5226349/article/details/78987385
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[3] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
[5] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[6] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
[7] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[8] Fu C Y, Liu W, Ranga A, et al. Dssd: Deconvolutional single shot detector[J]. arXiv preprint arXiv:1701.06659, 2017.
[9] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[10] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
[11] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[12] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2980-2988.
[13] Liu S, Huang D. Receptive field block net for accurate and fast object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 385-400.
[14] Zhao Q, Sheng T, Wang Y, et al. M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network[J]. arXiv preprint arXiv:1811.04533, 2018.

