
- 1clickhouse Kafka表引擎使用_clickhouse kafka kafka_max_block_size
- 2数模论文写作方法3|问题重述_数学建模问题重述
- 3微信小程序开发-新闻简讯demo_移动端新闻录入开发
- 4jmeter最大请求数_Gatling(和JMeter)努力维持每秒请求数(RPS)?
- 5J2EE程序员需掌握的技术_掌握j2ee技术
- 6浅析mysql中索引B+树_mysql索引树
- 7SpringBoot集成Mysql_springboot 整合mysql 依赖
- 8nlp方向权威期刊,IF仅2.5,EI、SCI、SSCI、AHCI同时收录_nlp一般投什么期刊
- 9npm安装yarn和pnpm_npm下载pnpm
- 10License server激活_mosek license server 激活
论文高质量中文翻译:Scalable Diffusion Models with Transformers 可扩展的Transformer扩散模型
赞
踩
Scalable Diffusion Models with Transformers 可扩展的Transformer扩散模型
垓篇论文是Openai Sora 背后的重要技术基础之一,值得一读。
论文作者: William Peebles, Saining Xie
论文链接: https://arxiv.org/abs/2212.09748
代码地址: https://github.com/facebookresearch/DiT

图1. 具有Transformer骨干的扩散模型实现了最先进的图像质量。 我们展示了两个在ImageNet上训练的类条件DiT-XL/2模型在512×512和256×256分辨率下的部分样本。
摘要
我们探索了一种基于Transformer架构的新型扩散模型。我们训练了基于图像的潜在扩散模型,将常用的U-Net骨干替换为在潜在补丁上操作的Transformer。我们通过Gflops衡量的前向传递复杂性的角度分析了我们的扩散Transformer(DiTs)的可扩展性。我们发现,具有更高Gflops的DiTs(通过增加Transformer的深度/宽度或增加输入令牌的数量)始终具有较低的FID。除了具有良好的可扩展性特性外,我们最大的DiT-XL/2模型在类条件ImageNet 512×512和256×256基准测试中优于所有先前的扩散模型。
引言
机器学习正在经历由Transformer驱动的复兴。在过去的五年中,神经网络在自然语言处理[8, 42]、视觉[10]和其他领域中的应用基本上都被Transformer所取代[60]。然而,许多图像级生成模型仍然没有采用这一趋势,尽管Transformer在自回归模型[3,6,43,47]中得到了广泛应用,但在其他生成建模框架中的应用较少。例如,扩散模型一直处于图像级生成模型的最新进展的前沿[9,46],然而,它们都采用了卷积U-Net作为骨干的默认选择。

图2. 使用扩散Transformer(DiTs)生成ImageNet图像。 气泡面积表示扩散模型的Flops。*左:*我们的DiT模型在400K训练迭代中的FID-50K(越低越好)。随着模型Flops的增加,FID逐渐改善。*右:*我们的最佳模型DiT-XL/2具有高效的计算性能,并优于所有先前基于U-Net的扩散模型,如ADM和LDM。
Ho等人的开创性工作[19]首次引入了U-Net骨干用于扩散模型。U-Net最初在像素级自回归模型和条件GAN中取得了成功[23],它是从Pixel-CNN++[52, 58]继承而来的,经过了一些改动。该模型是卷积的,主要由ResNet[15]块组成。与标准U-Net[49]不同,额外的空间自注意块(在变压器中是必不可少的组成部分)被插入到较低的分辨率中。Dhariwal和Nichol[9]对U-Net的几个架构选择进行了剥离,例如使用自适应归一化层[40]注入条件信息和卷积层的通道数。然而,Ho等人的U-Net的高级设计基本上保持不变。
通过这项工作,我们旨在揭示扩散模型中架构选择的重要性,并为未来的生成建模研究提供经验基准。我们展示了U-Net的归纳偏差对扩散模型的性能并不关键,它们可以很容易地被标准设计(如变压器)替代。因此,扩散模型有望从最近的架构统一趋势中受益,例如从其他领域继承最佳实践和训练方法,同时保留可扩展性、鲁棒性和效率等有利特性。标准化的架构还将为跨领域研究开辟新的可能性。
在本文中,我们专注于一种基于变压器的新型扩散模型。我们将其称为Diffusion Transformers,简称DiTs。DiTs遵循Vision Transformers(ViTs)[10]的最佳实践,已经证明在视觉识别方面比传统的卷积网络(如ResNet[15])更具扩展性。
具体而言,我们研究了变压器与网络复杂性和样本质量之间的缩放行为。我们通过在潜在扩散模型(LDMs)[48]框架下构建和基准测试DiT设计空间来展示,扩散模型可以成功地用变压器替换U-Net骨干。我们进一步展示了DiTs作为扩散模型的可扩展架构:网络复杂性(以Gflops衡量)与样本质量(以FID衡量)之间存在着很强的相关性。通过简单地扩大DiT并训练具有高容量骨干(118.6 Gflops)的LDM,我们能够在类条件256×256 ImageNet生成基准测试中实现2.27 FID的最新成果。
相关工作
变压器。 变压器[60]已经取代了语言、视觉[10]、强化学习[5, 25]和元学习[39]等领域的特定领域架构。它们在增加模型大小、训练计算量和数据方面展现出了显著的扩展性,如语言领域[26]、通用自回归模型[17]和ViTs[63]。除了语言之外,变压器还被训练用于自回归预测像素[6, 7, 38]。它们还被用于离散码本的训练[59],既作为自回归模型[11, 47],也作为掩码生成模型[4, 14];前者在20B参数的情况下展现出了出色的扩展行为[62]。最后,变压器已经在DDPM中探索了合成非空间数据的能力;例如,在DALL E 2中生成CLIP图像嵌入[41, 46]。在本文中,我们研究了将变压器用作图像扩散模型骨干时的扩展性能。
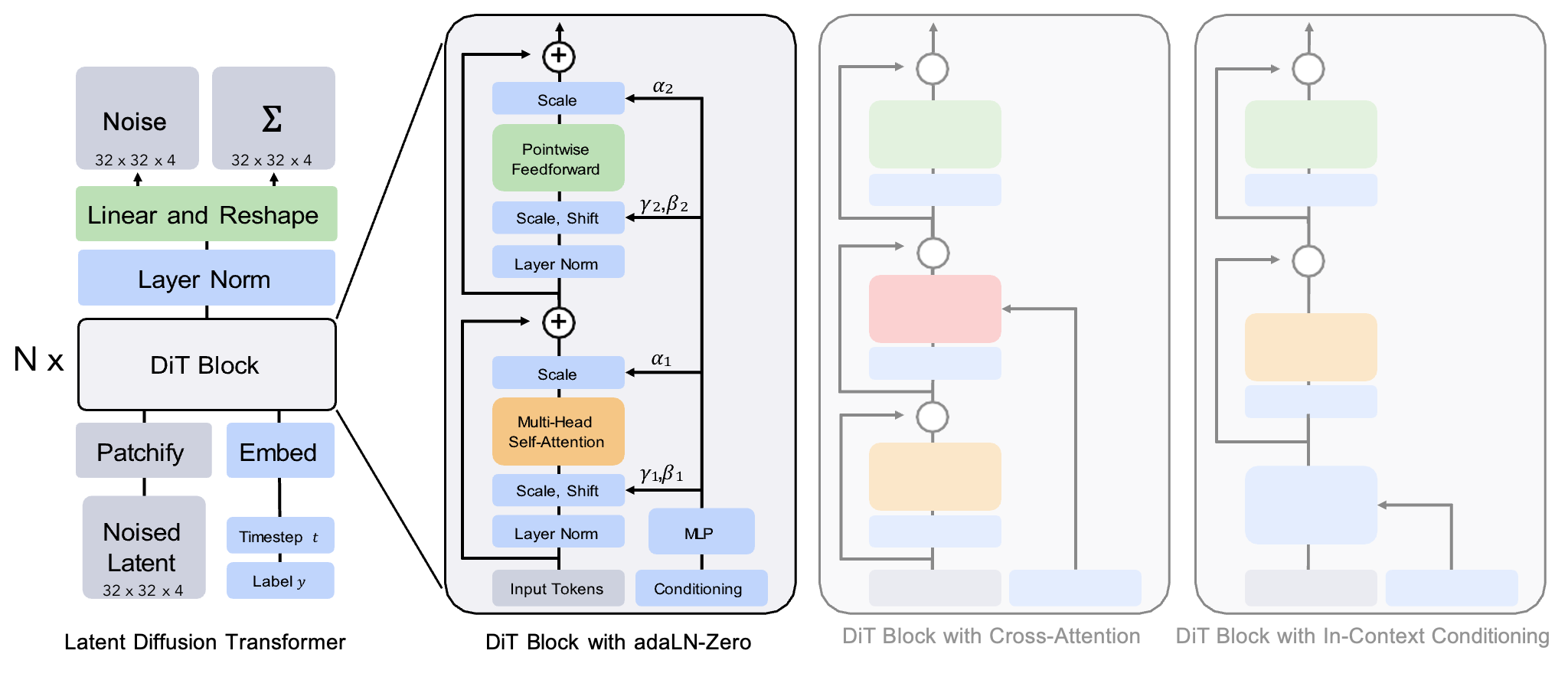
图3. 扩散Transformer(DiT)架构。 *左:*我们训练条件潜在DiT模型。输入潜在被分解成补丁,并由多个DiT块处理。*右:*我们的DiT块的细节。我们尝试了标准变压器块的变体,通过自适应层归一化、交叉注意力和额外的输入令牌来实现条件。
去噪扩散概率模型(DDPMs)。 扩散[19, 54]和基于分数的生成模型[22, 56]在图像生成模型中取得了特别成功[35,46,48,50],在许多情况下超过了以前的最先进的生成对抗网络(GANs)[12]。过去两年中,DDPM的改进主要是由改进的采样技术推动的[19, 27, 55],尤其是无分类器引导[21]、将扩散模型重新定义为预测噪声而不是像素[19]以及使用级联DDPM流水线,其中低分辨率的基础扩散模型与上采样器并行训练[9, 20]。对于上述所有的扩散模型,卷积U-Net[49]都是骨干架构的默认选择。同时进行的工作[24]引入了一种基于注意力的高效架构用于DDPM;我们探索纯变压器。
架构复杂性。 在图像生成领域评估架构复杂性时,常见的做法是使用参数数量。一般来说,参数数量可能不是图像模型复杂性的良好代理,因为它们没有考虑到像素分辨率等对性能的重要影响[44, 45]。相反,本文中的大部分模型复杂性分析是通过理论Gflops的视角进行的。这使我们与架构设计文献保持一致,其中Gflops被广泛用于衡量复杂性。在实践中,黄金复杂性度量仍然存在争议,因为它通常取决于特定的应用场景。Nichol和Dhariwal改进扩散模型的开创性工作[9, 36]与我们最相关-在那里,他们分析了U-Net架构类的可扩展性和Gflop属性。在本文中,我们专注于变压器类。
扩散变压器
预备知识
扩散公式。 在介绍我们的架构之前,我们简要回顾一些理解扩散模型(DDPMs)[19, 54]所需的基本概念。高斯扩散模型假设一个前向噪声过程,逐渐将噪声应用于真实数据中。
**重参数化技巧。**通过重参数化技巧,我们可以采样
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
t
x_{t}=\sqrt{\bar{\alpha}_{t}} x_{0}+\sqrt{1-\bar{\alpha}_{t}} \epsilon_{t}
xt=αˉt
x0+1−αˉt
ϵt,其中
ϵ
t
∼
N
(
0
,
I
)
\epsilon_{t} \sim \mathcal{N}(0, \mathbf{I})
ϵt∼N(0,I)。
扩散模型的训练是为了学习反向过程,以逆转正向过程的破坏:
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
μ
θ
(
x
t
)
,
Σ
θ
(
x
t
)
)
p_{\theta}\left(x_{t-1} \mid x_{t}\right)=\mathcal{N}\left(\mu_{\theta}\left(x_{t}\right), \Sigma_{\theta}\left(x_{t}\right)\right)
pθ(xt−1∣xt)=N(μθ(xt),Σθ(xt)),
其中神经网络用于预测
p
θ
p_{\theta}
pθ 的统计信息。反向过程模型是通过变分下界 [30] 来训练
x
0
x_{0}
x0 的对数似然的,这可以简化为
L
(
θ
)
=
−
p
(
x
0
∣
x
1
)
+
∑
t
D
K
L
(
q
∗
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
t
−
1
∣
x
t
)
)
\mathcal{L}(\theta)=-p\left(x_{0} \mid x_{1}\right)+\sum_{t} \mathcal{D}_{K L}\left(q^{*}\left(x_{t-1} \mid x_{t}, x_{0}\right)|| p_{\theta}\left(x_{t-1} \mid x_{t}\right)\right)
L(θ)=−p(x0∣x1)+∑tDKL(q∗(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)),
其中排除了一个与训练无关的额外项。由于
q
∗
q^{*}
q∗ 和
p
θ
p_{\theta}
pθ 都是高斯分布,可以通过计算两个分布的均值和协方差来评估
D
K
L
\mathcal{D}_{K L}
DKL。通过将
μ
θ
\mu_{\theta}
μθ 重新参数化为噪声预测网络
ϵ
θ
\epsilon_{\theta}
ϵθ,可以使用预测噪声
ϵ
θ
(
x
t
)
\epsilon_{\theta}\left(x_{t}\right)
ϵθ(xt) 和真实采样的高斯噪声
ϵ
t
\epsilon_{t}
ϵt 之间的简单均方误差来训练模型:
L
simple
(
θ
)
=
∥
ϵ
θ
(
x
t
)
−
ϵ
t
∥
2
2
\mathcal{L}_{\text {simple }}(\theta)=\left\|\epsilon_{\theta}\left(x_{t}\right)-\epsilon_{t}\right\|_{2}^{2}
Lsimple (θ)=∥ϵθ(xt)−ϵt∥22。但是,为了训练具有学习的逆过程协方差
Σ
θ
\Sigma_{\theta}
Σθ 的扩散模型,需要优化完整的
D
K
L
\mathcal{D}_{K L}
DKL 项。我们遵循 Nichol 和 Dhariwal 的方法 [36]:用
L
simple
\mathcal{L}_{\text {simple }}
Lsimple 训练
ϵ
θ
\epsilon_{\theta}
ϵθ,用完整的
L
\mathcal{L}
L 训练
Σ
θ
\Sigma_{\theta}
Σθ。一旦训练完成
p
θ
p_{\theta}
pθ,可以通过初始化
x
t
max
∼
N
(
0
,
I
)
x_{t_{\max }} \sim \mathcal{N}(0, \mathbf{I})
xtmax∼N(0,I) 并通过重参数化技巧采样
x
t
−
1
∼
p
θ
(
x
t
−
1
∣
x
t
)
x_{t-1} \sim p_{\theta}\left(x_{t-1} \mid x_{t}\right)
xt−1∼pθ(xt−1∣xt) 来生成新的图像。
**无分类器指导。**条件扩散模型将额外的信息作为输入,例如类别标签
c
c
c。在这种情况下,反向过程变为
p
θ
(
x
t
−
1
∣
x
t
,
c
)
p_{\theta}\left(x_{t-1} \mid x_{t}, c\right)
pθ(xt−1∣xt,c),其中
ϵ
θ
\epsilon_{\theta}
ϵθ 和
Σ
θ
\Sigma_{\theta}
Σθ 是基于
c
c
c 的。在这种设置下,可以使用无分类器指导来鼓励采样过程找到使得
log
p
(
c
∣
x
)
\log p(c \mid x)
logp(c∣x) 很高的
x
x
x [21]。根据贝叶斯定理,
log
p
(
c
∣
x
)
∝
log
p
(
x
∣
c
)
−
log
p
(
x
)
\log p(c \mid x) \propto \log p(x \mid c)-\log p(x)
logp(c∣x)∝logp(x∣c)−logp(x),因此
∇
x
log
p
(
c
∣
x
)
∝
∇
x
log
p
(
x
∣
c
)
−
∇
x
log
p
(
x
)
\nabla_{x} \log p(c \mid x) \propto \nabla_{x} \log p(x \mid c)-\nabla_{x} \log p(x)
∇xlogp(c∣x)∝∇xlogp(x∣c)−∇xlogp(x)。通过将扩散模型的输出解释为得分函数,可以通过以下方式引导 DDPM 采样过程以获得具有高
p
(
x
∣
c
)
p(x \mid c)
p(x∣c) 的
x
x
x:
ϵ
^
θ
(
x
t
,
c
)
=
ϵ
θ
(
x
t
,
∅
)
+
s
\hat{\epsilon}_{\theta}\left(x_{t}, c\right)=\epsilon_{\theta}\left(x_{t}, \emptyset\right)+s
ϵ^θ(xt,c)=ϵθ(xt,∅)+s。
∇
x
log
p
(
x
∣
c
)
∝
ϵ
θ
(
x
t
,
∅
)
+
s
⋅
(
ϵ
θ
(
x
t
,
c
)
−
ϵ
θ
(
x
t
,
∅
)
)
\nabla_{x} \log p(x \mid c) \propto \epsilon_{\theta}\left(x_{t}, \emptyset\right)+s \cdot\left(\epsilon_{\theta}\left(x_{t}, c\right)-\epsilon_{\theta}\left(x_{t}, \emptyset\right)\right)
∇xlogp(x∣c)∝ϵθ(xt,∅)+s⋅(ϵθ(xt,c)−ϵθ(xt,∅)),
其中
s
>
1
s>1
s>1 表示指导的规模(注意
s
=
1
s=1
s=1 时恢复标准采样)。使用
c
=
∅
c=\emptyset
c=∅ 评估扩散模型是通过在训练过程中随机丢弃
c
c
c 并用学习到的“空”嵌入
∅
\emptyset
∅ 替换它来完成的。无分类器指导被广泛认为比通用采样技术 [21,35,46] 产生更好的样本,并且对于我们的 DiT 模型也是如此。
**潜在扩散模型。**在高分辨率像素空间直接训练扩散模型可能计算上是困难的。潜在扩散模型(LDM)[48]通过两阶段方法解决了这个问题:(1)学习一个自编码器,将图像压缩成较小的空间表示,其中包括一个学习到的编码器 E;(2)训练一个表示 z = E(x) 的扩散模型,而不是图像 x 的扩散模型(E 是固定的)。然后,可以通过从扩散模型中采样表示 z,然后使用学习到的解码器 x = D(z) 将其解码为图像。
如图 2 所示,LDM 在使用的 Gflops 仅为 ADM 等像素空间扩散模型的一小部分的情况下实现了良好的性能。由于我们关注计算效率,这使得它们成为架构探索的一个有吸引力的起点。在本文中,我们将 DiT 应用于潜在空间,尽管它们也可以应用于像素空间而无需修改。这使得我们的图像生成流程成为一种混合方法;我们使用现成的卷积 VAE 和基于 Transformer 的 DDPM。
扩散 Transformer 设计空间
我们引入了扩散 Transformer(DiT),这是一种新的扩散模型架构。我们的目标是尽可能忠实于标准 Transformer 架构,以保留其可扩展性。由于我们的重点是训练图像的 DDPM(具体而言是图像的空间表示),DiT 基于 Vision Transformer(ViT)架构,该架构对补丁序列进行操作 [10]。DiT 保留了 ViT 的许多最佳实践。图 3 显示了完整的 DiT 架构概述。在本节中,我们描述了 DiT 的前向传递,以及 DiT 类的设计空间的组成部分。
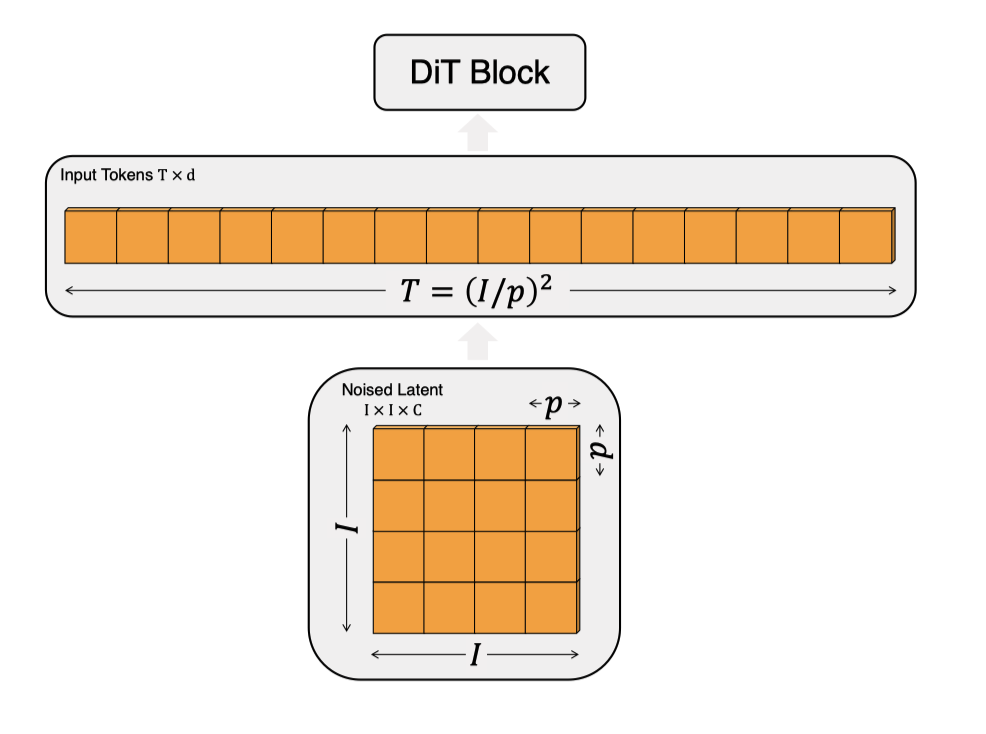
图 4. **DiT 的输入规格。**给定补丁大小 p × p,形状为 I × I × C 的空间表示(来自 VAE 的噪声潜在表示)被“patchify”为长度为 T = (I/p)² 的序列,隐藏维度为 d。较小的补丁大小 p 导致更长的序列长度,因此需要更多的 Gflops。
**Patchify。**DiT 的输入是一个空间表示 z(对于 256 256 3 的图像,z 的形状为 32 32 4)。DiT 的第一层是“patchify”,它通过线性嵌入输入中的每个补丁,将空间输入转换为长度为 T 的令牌序列,每个令牌的维度为 d。在 patchify 之后,我们对所有输入令牌应用标准的 ViT 频率基准位置嵌入(正弦-余弦版本)。由 patchify 创建的令牌数 T 由补丁大小超参数 p 决定。如图 4 所示,将 p 减半将使 T 增加四倍,因此至少会使总的 Transformer Gflops 增加四倍。尽管它对 Gflops 有重大影响,但请注意,改变 p 对下游参数数量没有实质性影响。
我们将 p 设为 2、4、8,加入 DiT 的设计空间。
**DiT 块设计。**在 patchify 之后,输入令牌通过一系列 Transformer 块进行处理。除了噪声图像输入之外,扩散模型有时还会处理其他条件信息,例如噪声时间步长 t、类别标签 c、自然语言等。我们探索了四种变体的 Transformer 块,这些块以不同的方式处理条件输入。这些设计对标准 ViT 块设计进行了小的但重要的修改。所有块的设计如图 3 所示。
- *上下文条件。*我们只需将 t 和 c 的向量嵌入作为输入序列中的两个附加令牌附加在一起,将它们与图像令牌一样对待。这类似于 ViT 中的 cls 令牌,它允许我们使用标准的 ViT 块而无需修改。在最后一个块之后,我们从序列中删除条件令牌。这种方法对模型的新增 Gflops 微不足道。
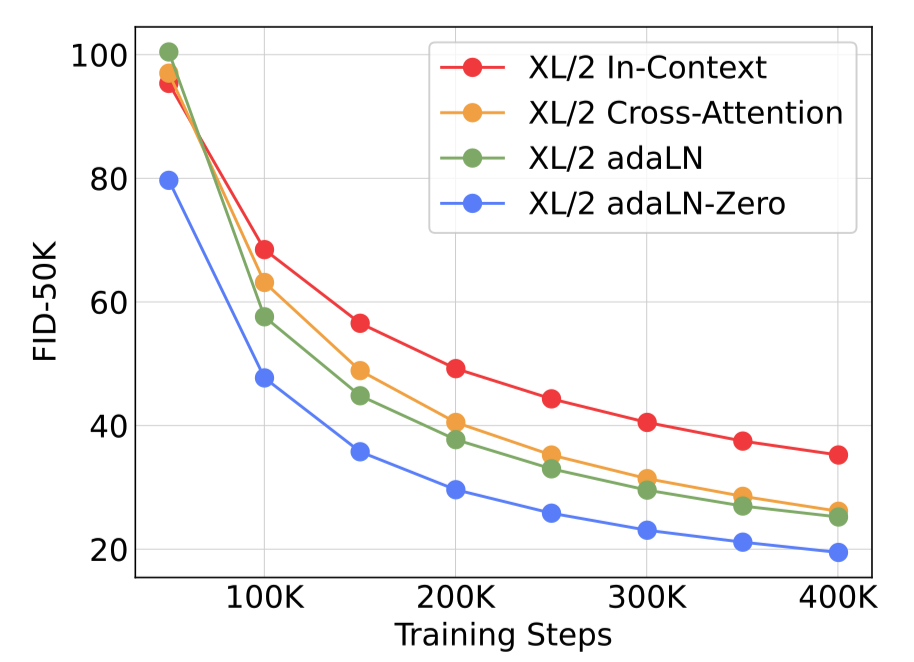
图 5. **比较不同的条件策略。**adaLN-Zero 在训练的所有阶段都优于交叉注意力和上下文条件。
-
*交叉注意力块。*我们将 t 和 c 的嵌入连接成一个长度为二的序列,与图像令牌序列分开。Transformer 块进行修改,以在多头自注意力块之后包括一个额外的多头交叉注意力层,类似于 Vaswani 等人的原始设计 [60],也类似于 LDM 用于类别标签条件的设计。交叉注意力为模型增加了最多的 Gflops,大约增加了 15% 的开销。
-
*自适应层归一化(adaLN)块。*在 GAN [2, 28] 和具有 U-Net 骨干的扩散模型中广泛使用自适应归一化层 [40] 的情况下,我们探索将 Transformer 块中的标准层归一化层替换为自适应层归一化(adaLN)。我们不直接学习维度缩放和偏移参数 γ 和 β,而是从 t 和 c 的嵌入向量之和中回归它们。在我们探索的三种块设计中,adaLN 增加的 Gflops 最少,因此是计算效率最高的。它也是唯一一个将 相同的函数 应用于所有令牌的条件机制。
-
*adaLN-Zero 块。*在 ResNet 的先前工作中发现,将每个残差块初始化为恒等函数是有益的。例如,Goyal 等人发现,在监督学习设置中,将每个块中的最终批归一化尺度因子 γ 初始化为零可以加速大规模训练 [13]。扩散 U-Net 模型使用了类似的初始化策略,在任何残差连接之前,将每个块中的最终卷积层初始化为零。我们探索了 adaLN DiT 块的修改版本,该版本执行相同的操作。除了回归 γ 和 β,我们还回归在 DiT 块内部的任何残差连接之前应用的维度缩放参数 α。
我们将MLP初始化为对所有的α输出零向量;这将全面初始化DiT块为恒等函数。与普通的adaLN块一样,adaLN-Zero对模型的Gflops增加可以忽略不计。
我们在DiT设计空间中包括了上下文、交叉注意力、自适应层归一化和adaLN-Zero块。
**模型大小。**我们应用了一系列的N个DiT块,每个块在隐藏维度大小d上操作。遵循ViT的做法,我们使用了一些标准的transformer配置,同时对N、d和注意力头进行了联合缩放。具体来说,我们使用了四个配置:DiT-S、DiT-B、DiT-L和DiT-XL。它们涵盖了从0.3到118.6 Gflops的广泛的模型大小和Flop分配范围,使我们能够评估缩放性能。表1给出了这些配置的详细信息。
我们在DiT设计空间中添加了B、S、L和XL的配置。
**Transformer解码器。**在最后一个DiT块之后,我们需要将图像令牌序列解码为输出噪声预测和输出对角协方差预测。这两个输出的形状与原始的空间输入相同。我们使用标准的线性解码器来完成这个任务;我们将最后的层归一化(如果使用adaLN,则是自适应的)应用于每个令牌,并将其线性解码为一个pp2C的张量,其中C是DiT中空间输入的通道数。最后,我们重新排列解码后的令牌,以恢复其原始的空间布局,从而得到预测的噪声和协方差。
我们探索的完整的DiT设计空间包括补丁大小、transformer块架构和模型大小。
实验设置
我们探索DiT的设计空间,并研究我们的模型类的缩放性能。我们的模型根据其配置和潜在补丁大小p进行命名;例如,DiT-XL/2表示XLarge配置和p=2。
**训练。**我们在ImageNet数据集上训练了256×256和512×512的图像分辨率下的类条件潜在DiT模型,ImageNet是一个高度竞争的生成建模基准。我们将最后的线性层初始化为零,其他方面使用了ViT的标准权重初始化技术。我们使用AdamW进行所有模型的训练。
我们使用恒定的学习率1×10^(-4),没有权重衰减,批量大小为256。我们只使用水平翻转进行数据增强。与ViTs的许多先前工作不同,我们发现学习率预热和正则化对训练DiTs到高性能并不必要。即使没有这些技术,训练在所有模型配置上都非常稳定,我们没有观察到训练transformer时常见的损失峰值。按照生成建模文献中的常规做法,我们在训练过程中使用指数移动平均(EMA)对DiT的权重进行维护,衰减率为0.9999。所有报告的结果都使用EMA模型。我们在所有DiT模型大小和补丁大小上使用相同的训练超参数。我们的训练超参数几乎完全来自ADM。我们没有调整学习率、衰减/预热计划、Adam β₁/β₂或权重衰减。
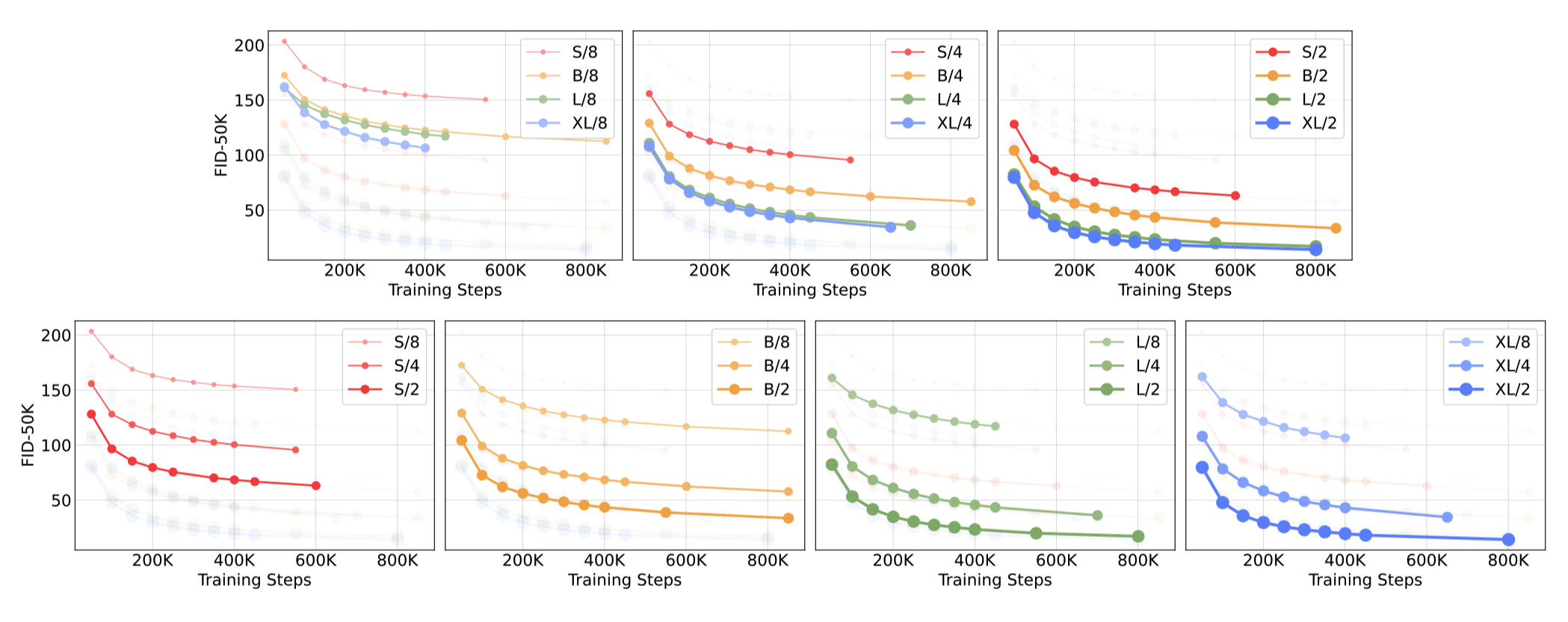
图6. **缩放DiT模型改善了训练的所有阶段的FID。**我们展示了12个DiT模型在训练迭代过程中的FID-50K。*上排:*我们比较了保持补丁大小不变的FID。*下排:*我们比较了保持模型大小不变的FID。缩放transformer骨干网络在所有模型大小和补丁大小上都产生了更好的生成模型。
**扩散。**我们使用了一个现成的预训练变分自编码器(VAE)模型[30],来自稳定扩散[48]。VAE编码器的下采样因子为8,给定形状为256×256×3的RGB图像x,其形状为32×32×4的z=E(x)。
在本节的所有实验中,我们的扩散模型在这个Z空间中运行。从我们的扩散模型中采样一个新的潜在变量后,我们使用VAE解码器将其解码为像素
x
=
D
(
z
)
x=D(z)
x=D(z)。我们保留了ADM中的扩散超参数;具体来说,我们使用了一个
t
max
=
1000
t_{\max}=1000
tmax=1000的线性方差计划,范围从
1
×
1
0
−
4
1×10^{-4}
1×10−4到
2
×
1
0
−
2
2×10^{-2}
2×10−2,ADM的协方差
Σ
θ
\Sigma_{\theta}
Σθ的参数化以及他们的输入时间步长和标签的嵌入方法。
**评估指标。**我们使用Fre´chet Inception Distance (FID)作为评估图像生成模型的标准指标。
在与先前的工作进行比较时,我们遵循惯例,并使用250个DDPM采样步骤报告FID-50K。众所周知,FID对实现细节非常敏感;为了确保准确的比较,本文中报告的所有值都是通过导出样本并使用ADM的TensorFlow评估套件获得的。本节中报告的FID数字不使用无分类器的引导,除非另有说明。我们还报告Inception Score、sFID和Precision/Recall作为辅助指标。
**计算。**我们使用JAX实现了所有的模型,并使用TPU-v3 pod进行训练。DiT-XL/2是我们计算最密集的模型,在全局批量大小为256的TPU v3-256 pod上训练速度约为5.7次迭代/秒。
实验
**DiT块设计。**我们训练了四个最高Gflop的DiT-XL/2模型,每个模型使用不同的块设计——上下文(119.4 Gflops)、交叉注意力(137.6 Gflops)、自适应层归一化(adaLN,118.6 Gflops)或adaLN-zero(118.6 Gflops)。我们测量了训练过程中的FID。图5显示了结果。adaLN-Zero块的FID比交叉注意力和上下文条件下的FID更低,同时计算效率最高。在训练迭代400K时,adaLN-Zero模型的FID几乎是上下文模型的一半,这表明条件机制对模型质量有重要影响。初始化也很重要——将每个DiT块初始化为恒等函数的adaLN-Zero明显优于普通的adaLN。在接下来的部分中,所有的模型都将使用adaLN-Zero的DiT块。

图7. **增加transformer前向传递的Gflops可以提高样本质量。**我们在400K训练步骤后从我们的12个DiT模型中进行采样,使用相同的输入潜在噪声和类别标签。通过增加模型中的Gflops(通过增加transformer的深度/宽度或增加输入令牌的数量),在视觉保真度方面取得了显著的改进。

图8. **Transformer的Gflops与FID强相关。**我们绘制了每个DiT模型的Gflops和每个模型在400K训练步骤后的FID-50K。
**缩放模型大小和补丁大小。**我们训练了12个DiT模型,涵盖了模型配置(S、B、L、XL)和补丁大小(8、4、2)。需要注意的是,相对于其他配置,DiT-L和DiT-XL在相对Gflops方面更接近。图2(左)给出了每个模型的Gflops和它们在400K训练迭代时的FID的概览。在所有情况下,我们发现增加模型大小和减小补丁大小可以显著改善扩散模型。
图6(上)展示了在保持补丁大小不变的情况下,FID随着模型大小的增加而变化。在所有四个配置中,通过使transformer更深更宽,在训练的所有阶段都获得了显著的FID改进。类似地,图6(下)展示了在保持模型大小不变的情况下,FID随着补丁大小的减小而变化。我们再次观察到,通过简单地扩展DiT处理的令牌数量,保持参数大致不变,可以在整个训练过程中显著改善FID。
**DiT的Gflops对于改善性能至关重要。**图6的结果表明,参数数量并不能唯一确定DiT模型的质量。在保持模型大小不变的情况下,减小补丁大小,transformer的总参数实际上是不变的(实际上,总参数稍微减少),只有Gflops增加。这些结果表明,扩展模型的Gflops实际上是改善性能的关键因素。为了进一步研究这一点,我们在图8中绘制了400K训练步骤后的FID-50K与模型Gflops之间的关系。结果表明,当模型的总Gflops相似时(例如,DiT-S/2和DiT-B/4),不同的DiT配置获得了类似的FID值。我们发现模型的Gflops与FID-50K之间存在强烈的负相关关系,这表明额外的模型计算是改进DiT模型的关键因素。在附录的图12中,我们发现这种趋势在其他指标(如Inception Score)上也成立。
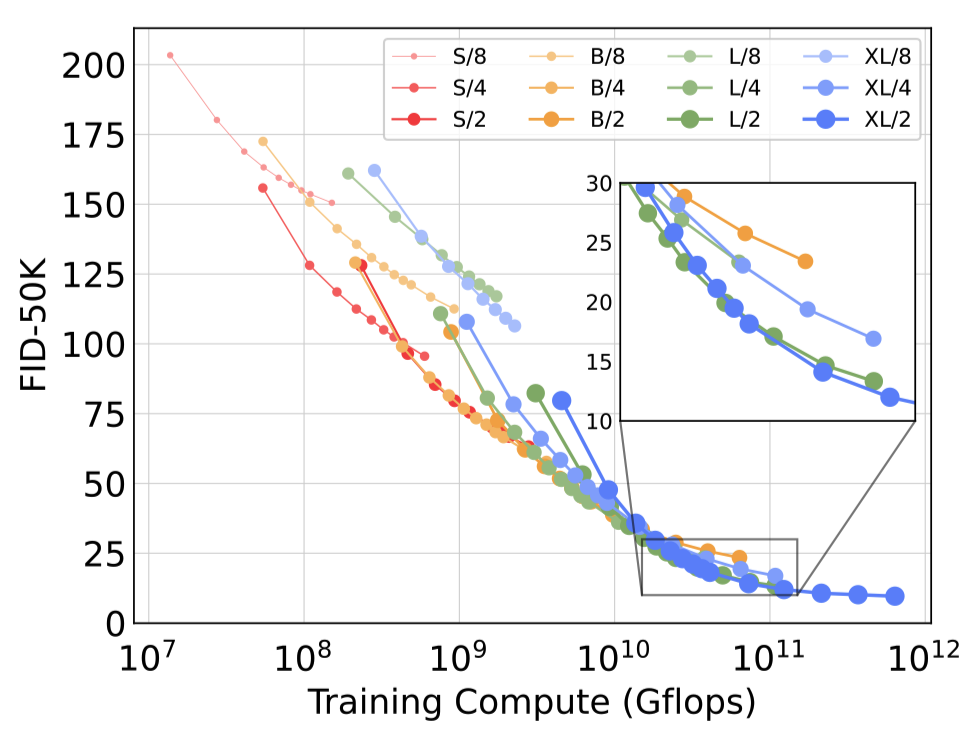
图9. **更大的DiT模型更有效地使用大型计算。**我们将FID作为总训练计算量的函数进行绘制。
**可视化扩展。**我们在图7中可视化了扩展对样本质量的影响。在训练400K步之后,我们使用相同的起始噪声*x_(t)*max,采样噪声和类标签从我们的12个DiT模型中采样一张图像。这样可以让我们直观地解释扩展如何影响DiT的样本质量。事实上,扩展模型大小和令牌数量都会显著提高视觉质量。
最先进的扩散模型
**256 *256 ImageNet。**在我们的扩展分析之后,我们继续训练我们最高的Gflop模型DiT-XL/2,进行了700万步的训练。我们在图1中展示了该模型的样本,并与最先进的条件生成模型进行了比较。我们在表2中报告了结果。当使用无分类器指导时,DiT-XL/2优于所有先前的扩散模型,将先前最佳的FID-50K(3.60,由LDM实现)降低到2.27。图2(右)显示,相对于像LDM-4(103.6 Gflops)这样的潜空间U-Net模型和像ADM(1120 Gflops)或ADM-U(742 Gflops)这样的像素空间U-Net模型,DiT-XL/2(118.6 Gflops)在计算效率上更高。

表2. 在ImageNet 256×**256上进行基准测试的条件图像生成。DiT-XL/2实现了最先进的FID。

表3. 在ImageNet 512×**512上进行基准测试的条件图像生成。请注意,先前的工作[9]使用1000个真实样本来测量512 × 512分辨率的精确度和召回率;为了保持一致,我们也这样做。
我们的方法在所有先前的生成模型中实现了最低的FID,包括先前最先进的StyleGAN-XL[53]。最后,我们还观察到,与LDM-4和LDM-8相比,DiT-XL/2在所有测试的无分类器指导尺度上实现了更高的召回值。即使只训练了235万步(类似于ADM),XL/2的FID仍然优于所有先前的扩散模型,为2.55。
**512512 ImageNet。**我们在ImageNet上训练了一个新的512512分辨率的DiT-XL/2模型,进行了3M次迭代,使用与256256模型相同的超参数。使用2个补丁,这个XL/2模型在将6464*4输入潜空间分块化后总共处理了1024个令牌(524.6 Gflops)。表3显示了与最先进方法的比较。在这个分辨率下,XL/2再次优于所有先前的扩散模型,将先前最佳的FID(3.85,由ADM实现)降低到3.04。即使令牌数量增加,XL/2仍然具有计算效率。例如,ADM使用1983 Gflops,ADM-U使用2813 Gflops;XL/2使用524.6 Gflops。我们在附录中展示了高分辨率XL/2模型的样本。
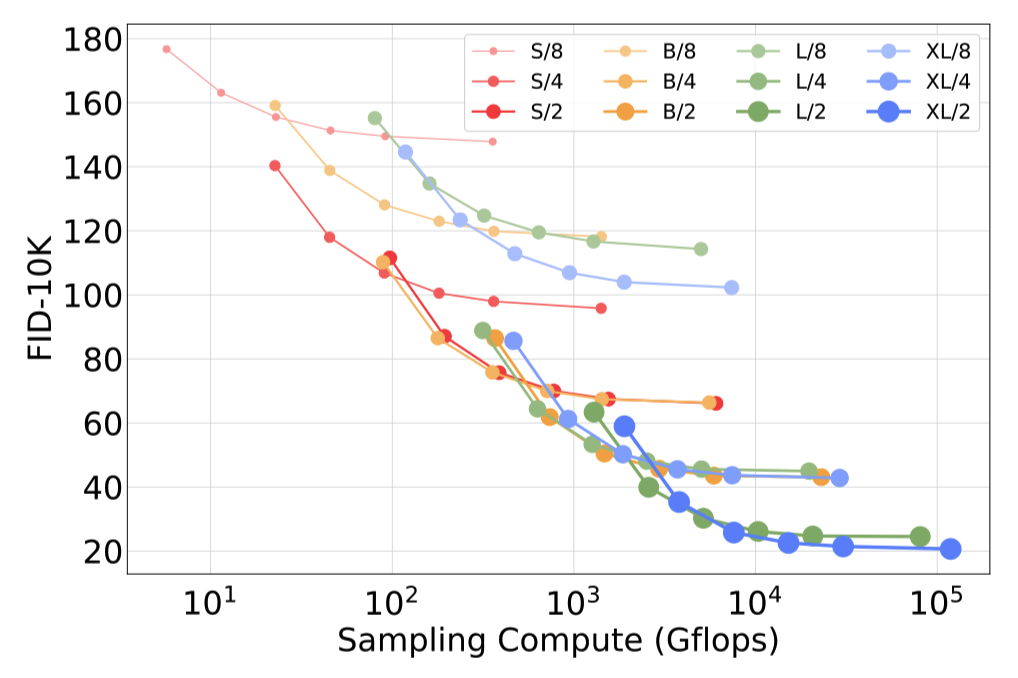
图10. **扩大采样计算量不能弥补模型计算量不足。**对于我们训练400K次迭代的每个DiT模型,我们使用[16, 32, 64, 128, 256, 1000]个采样步骤计算FID-10K。对于每个步骤数,我们绘制了FID以及用于采样每个图像的Gflops。即使小模型使用比大模型更多的测试时间Gflops进行采样,它们也无法弥补性能差距。
模型扩展与采样计算量的比较
扩散模型的独特之处在于在生成图像时可以通过增加采样步骤来使用额外的计算。鉴于模型Gflops对样本质量的影响,本节我们研究了通过使用更多的采样计算量来使用较小的模型计算量是否能够胜过较大的模型。我们在400K训练步骤后为我们的12个DiT模型使用[16, 32, 64, 128, 256, 1000]个采样步骤计算FID。主要结果如图10所示。考虑使用1000个采样步骤的DiT-L/2与使用128个步骤的DiT-XL/2进行比较。在这种情况下,L/2使用80.7 Tflops来采样每个图像;XL/2使用5倍较少的计算量——15.2 Tflops来采样每个图像。尽管如此,XL/2的FID-10K更好(23.7比25.9)。总的来说,扩大采样计算量不能弥补模型计算量不足。
结论
我们引入了扩散变换器(DiTs),这是一种简单的基于Transformer的扩散模型骨干,优于先前的U-Net模型,并继承了Transformer模型类的出色扩展性能。鉴于本文中有希望的扩展结果,未来的工作应继续将DiTs扩展到更大的模型和令牌数量。DiT还可以作为文本到图像模型(如DALL·E 2和稳定扩散)的替代骨干进行探索。

