
- 1Andriod+Fidder抓包配置(手把手教)_android sdk manager arm 64 怎么连接 fiddler
- 2NineData正式将SQL开发正式升级为数据库DevOps
- 3第五讲:LORA模型训练-探秘数据集整理,挑战核心闪电战
- 4js遇到需要正则匹配来修改img标签+清除行内样式
- 5vue + websocket_vue+websocket
- 6 canvas(一)从零开始
- 7【JDK1.8HashMap也会死循环?记一次线上问题排查经历】_hashmap 1.8死循环
- 8六种复杂控制系统简述:串级、分程、比值、前馈、选择性和三冲量控制_六种复杂控制系统的应用场景
- 9求绝对值函数fabs和abs_cuda abs
- 10Flink 基础核心概念介绍_flink一个job可以有几个task
隐私计算 — 联邦学习 — Overview_fate 聚合策略fedyogi
赞
踩
目录
前言
本文摘自以下文献,为个人学习笔记摘抄:
- 《联邦学习研究综述》 —— 周传鑫, 孙奕, 汪德刚, 葛桦玮
- 《联邦学习算法综述》 —— 王健宗1, 孔令炜1, 黄章成1, 陈霖捷1, 刘懿1, 何安珣1, 肖京2,
- 《联邦学习安全与隐私保护研究综述》 —— 周俊,方国英,吴楠
- 《边缘计算下的联邦学习应用研究》 —— 翟孟冬,陈宇,林榕健,李军
- 《联邦学习的安全性和隐私综述》
联邦学习
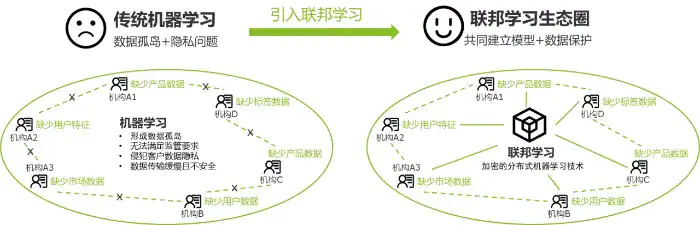
机器学习技术的发展过程中面临两大挑战:
- 隐私数据安全保障
- 打破数据孤岛
为了解决 “数据保护” 与 “数据孤岛” 这两大难题,Google 公司于 2016 年提出了联邦学习(Federated Learning)。
联邦学习包含两个过程,即:
-
模型训练:在模型训练过程中,模型相关信息以加密的方式在各参与方之间进行传输交换,合作训练好的模型,再发送给各参与方,更新各参与方本地模型,直至全局模型性能最优为止。
-
模型推理:模型推理时,训练好的模型可以运用新的数据实例进行推理预测,例如在医疗行业应用,联邦医疗图像系统可能会接受一名患者,该患者的诊断数据来自不同医院,各方协作进行病情预测,并将预测结果反馈给用户。
联邦学习与分布式机器学习的区别
尽管联邦学习和分布式机器学习有部分相似的地方,但是在应用领域、系统设计、优化算法方面,联邦学习有自己的特征。
-
在数据量庞大、所需计算资源较高时,分布式机器学习(如参数服务器)有明显的优势,它将独立同分布(independently identically distribution,IID)的数据或模型参数存储在各个分布式节点上,中心服务器调动数据和计算资源,联合训练模型。
-
因客户端的地理、时间等分布差异,联邦学习的数据集来自各个终端用户,这些用户产生的数据特征往往呈非独立同分布(Non-IID)。Non-IID 指的是在概率统计理论中,各数据集中的随机变量不服从同一分布,即对于不同的客户端 i 和 j,它们的数据集概率分布 Pi ≠ Pj。而传统的分布式框架算法只有在处理独立同分布(IID)数据时表现良好,而在处理 Non-IID 数据时会造成训练过程难以收敛、通信轮数过多等问题。
联邦学习技术具有以下几个特点:
- 参与联邦学习的原始数据都保留在本地客户端,与中心服务器交互的只是模型更新信息。
- 联邦学习的参与方联合训练出的模型 w 将被各方共享。
- 联邦学习最终的模型精度与集中式机器学习相似。
- 联邦学习参与方的训练数据质量越高,全局模型精度越高。
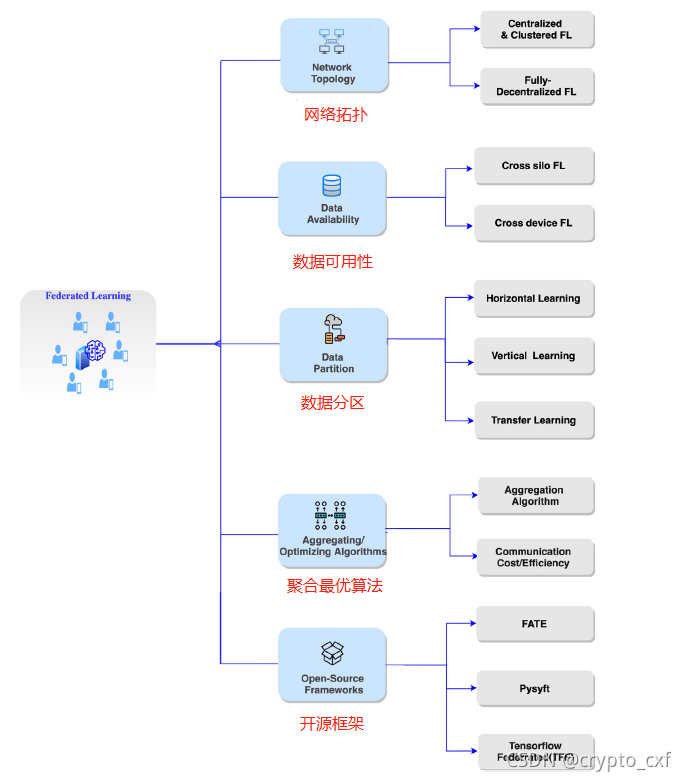
联邦学习的网络拓扑类型
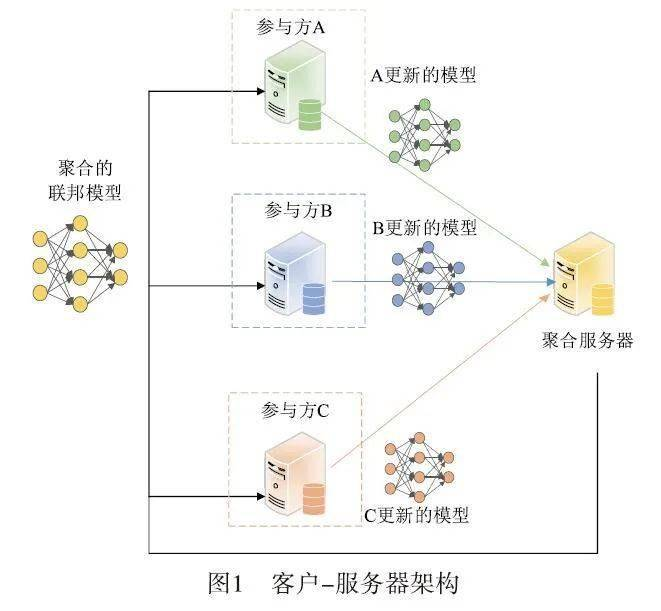
客户端-服务器拓扑
依赖于一个中央服务器来作为一个中央权威机构,监视和管理持续学习过程。客户端(如平板电脑、手机、物联网设备)在中心服务器(如服务提供商)的协调下共同训练模型,其中:
- 客户端:负责训练本地数据得到本地模型(local model)。
- 中心服务器:负责加权聚合本地模型,得到全局模型(global model)。
经过多轮迭代后最终得到一个趋近于集中式机器学习结果的模型 w,有效地降低了传统机器学习源数据聚合带来的许多隐私风险。
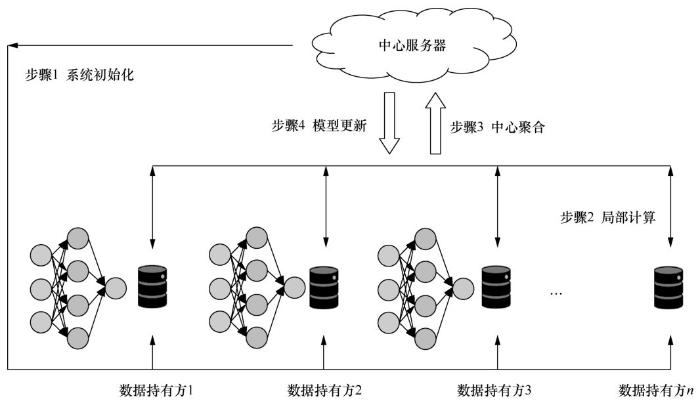
联邦学习的一次迭代过程如下。
Step 1. 系统初始化
1)中心节点与所有局部节点协商确认联合建模设想。
2)中心节点向所有局部节点发布初始预设模型。
3)中心节点向所有局部节点发布初始参数。
Step 2. 本地计算
1)若使用传统聚合算法,那么在局部节点本地训练一次,并将所得梯度脱敏后上传到中心节点。
2)若使用 FedAvg 聚合算法,那么在局部节点本地训练多次,并将所得权重模型上传到中心节点。
Step 3. 中心聚合
在收到来自多个局部节点的计算结果后,中心节点对这些计算值进行聚合操作,在聚合的过程中需要同时考虑效率、安全、隐私等多方面的问题。
1)有时因为系统的异构性,中心节点可能不会等待所有局部节点的上传,而是选择一个合适的局部节点子集作为收集目标。
2)有时为了安全地对参数进行聚合,使用一定的加密技术对参数进行加密。
Step 4. 模型更新
1)中心节点根据聚合后的结果对全局模型进行一次更新,并将更新后的模型返回给参与建模的局部节点。局部节点更新本地模型,并开启下一步局部计算,同时评估更新后的模型性能,当性能足够好时,训练终止,联合建模结束。
2)建立好的全局模型将会被保留在中心节点,以进行后续的预测或分类工作。
上述过程是一个典型的基于客户端服务器架构的联邦学习过程。但并不是每个联邦学习任务都一定要严格按照这样的流程进行操作,有时可能会针对不同场景对流程做出改动,例如,适当地减少通信频率来保证学习效率,或者在聚合后增加一个逻辑判断,判断接收到的本地计算结果的质量,以提升联邦学习系统的鲁棒性。
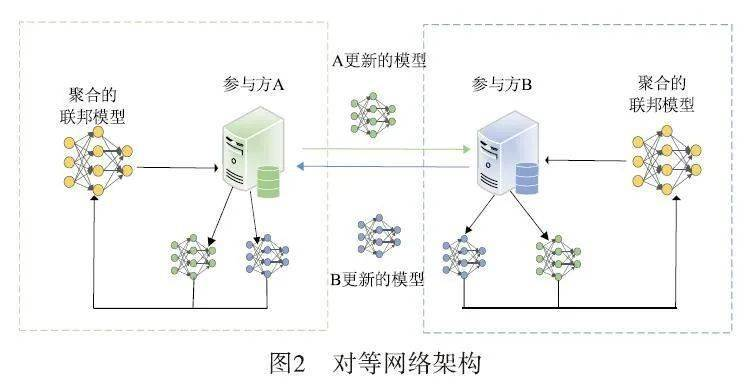
对等网络拓扑
对等网络拓扑,采用去中心化的方式,集中式的权威被建立信任和可靠性的算法所取代,例如:一种基于拜占庭概念的自适应平均算法,该算法假设联邦学习中超过 2/3 的系统是诚实的。
通过这种方法,一组来自不同领域、具有共同目标的客户可以协作、共享数据和建立 ML 模型,并利用高精度的优势,而无需依赖第三方集中服务器。
·
联邦学习的数据分区类型
联邦学习的应用场景不同,客户端之间持有的数据集特征各不相同。假设 Dm 代表客户端 m 持有的数据,I 表示样本 ID,Y 表示数据集的标签信息,X 表示数据集的特征信息,因此,一个完整的训练数据集 D 应由 (I,Y,X) 构成。根据参与训练客户端的数据集特征信息 X 的不同,联邦学习被分为:
- 横向联邦学习
- 纵向联邦学习
- 联邦迁移学习

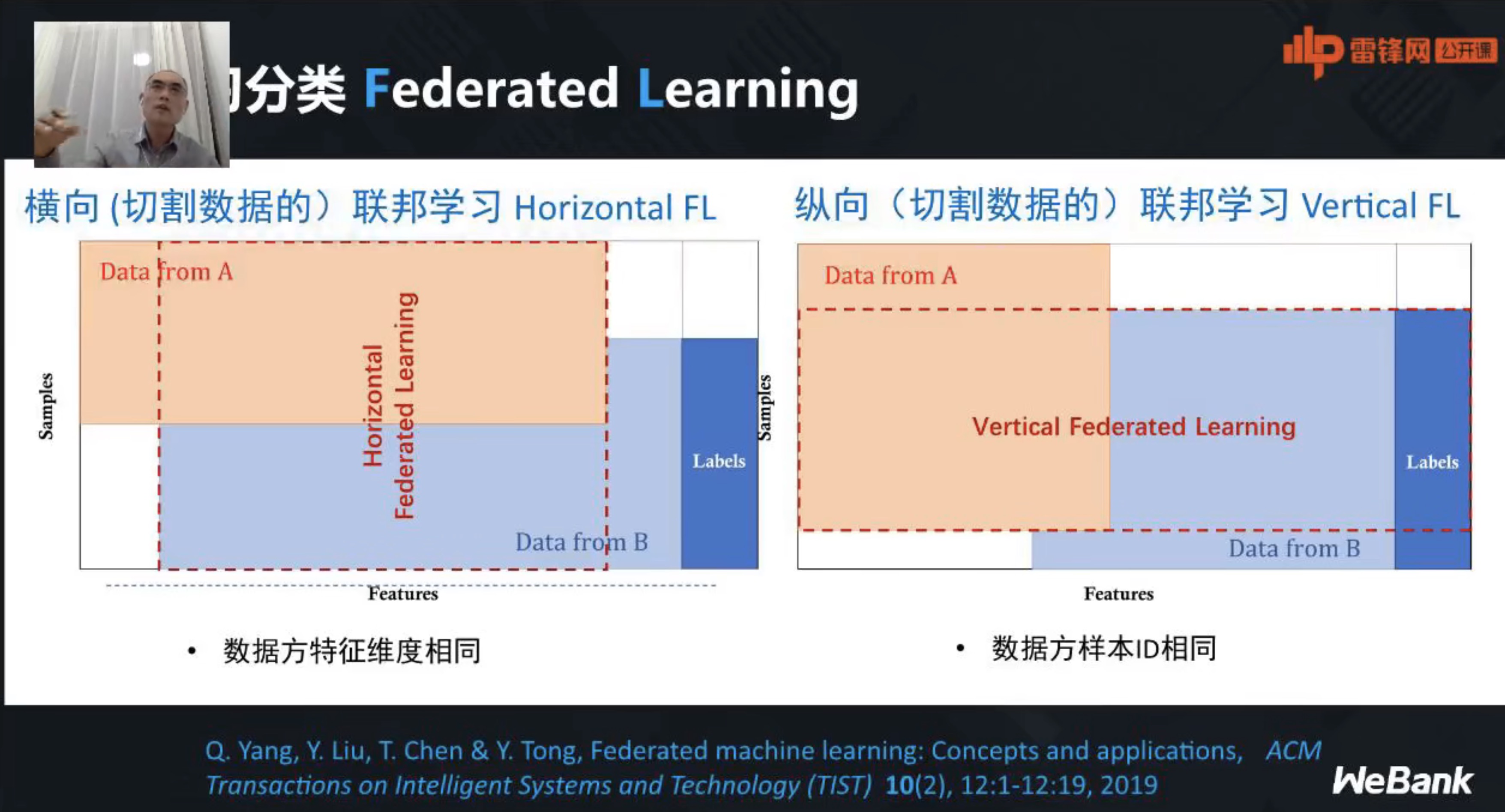
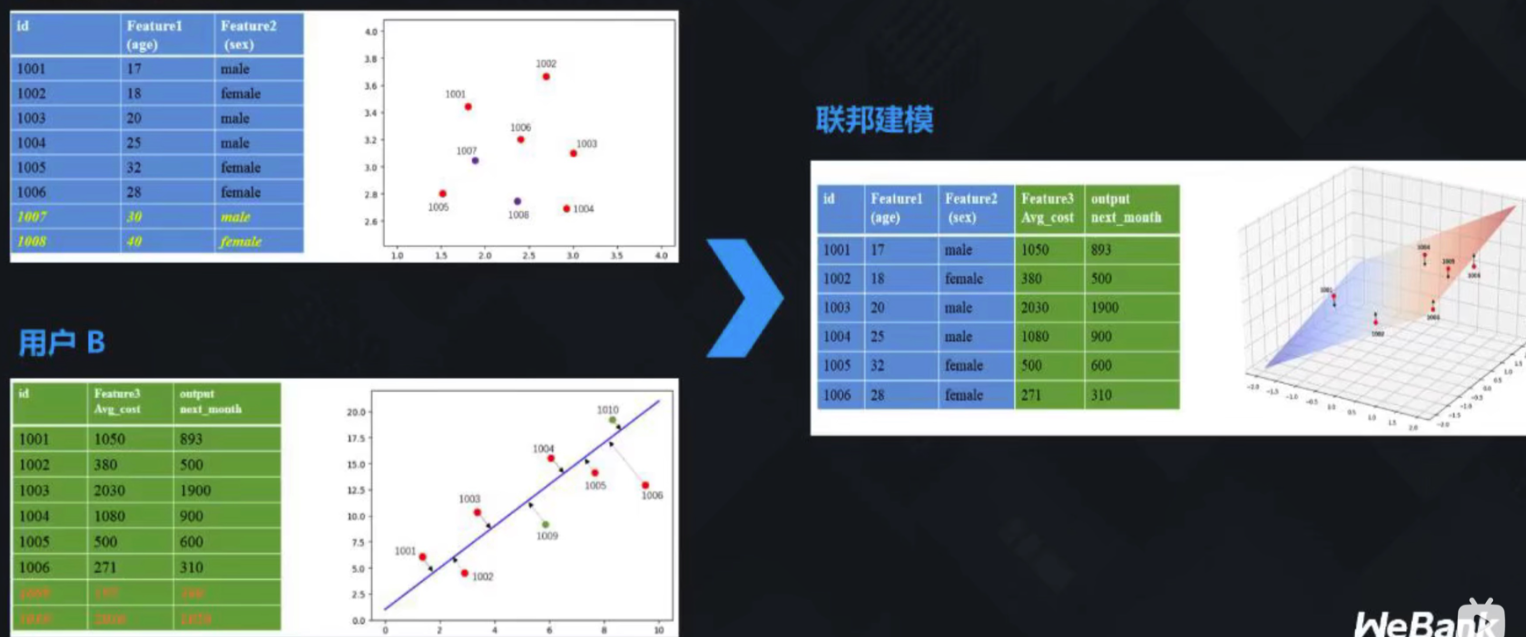
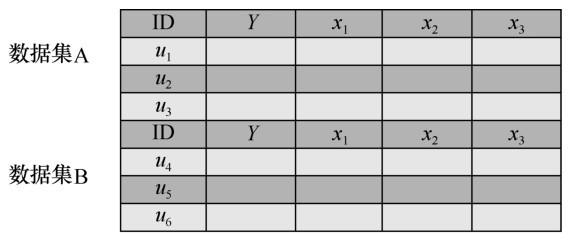
横向联邦学习
横向联邦学习指的是在不同数据集之间数据特征重叠较多而用户重叠较少的情况下,按照用户维度对数据集进行切分,并取出双方数据特征相同而用户不完全相同的那部分数据进行训练。
在这里插入图片描述
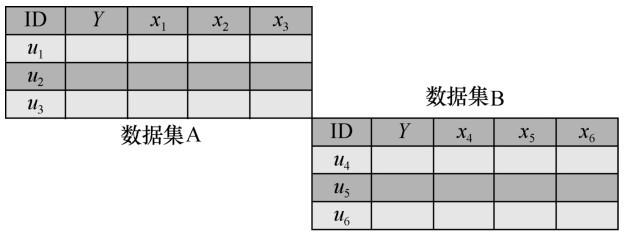
纵向联邦学习
纵向联邦学习指的是在不同数据集之间用户重叠较多而数据特征重叠较少的情况下,按照数据特征维度对数据集进行切分,并取出双方针对相同用户而数据特征不完全相同的那部分数据进行训练。

联邦迁移学习(Federated Transfer Learning)
联邦迁移学习指的是在多个数据集的用户与数据特征重叠都较少的情况下,不对数据进行切分,而是利用迁移学习来克服数据或标签不足的情况。
联邦学习的数据可用性类型
Cross-silo FL(跨筒仓式联邦学习)
在这种情况下的客户端通常范围从 2-100 个设备的小数目,通常有索引,几乎总是在训练轮中可用。训练数据可分为横向联邦学习和纵向联邦学习。
计算和通信瓶颈是主要问题。与 Cross-device FL 相比,Cross-silo FL 更加灵活,可用在组织或组织组的场景中使用它们的机密数据来训练 ML 模型。在纵向和迁移学习中,首选加密技术来限制来自每个客户端的信息推断。
Cross-device FL(跨设备联邦学习)
具有来自全局模型的相似领域的大量客户端的联邦学习的方法被称为跨设备联邦学习。
由于客户端数量庞大,很难跟踪和维护交易历史日志。大多数客户使用不可靠的网络连接,在这些网络中,选择/参与训练是随机发生的。
联邦学习的挑战与研究进展
联邦学习最核心的问题包括:
- 通信效率短板明显
- 隐私安全仍有缺陷
- 异构性
- 等
通信效率短板明显
在联邦学习网络中**,服务器与远程客户端之间往往需要进行不断的通信来交互模型更新信息,动辄万计的客户端很容易对通信网络造成巨大的带宽负担**。
通常,全局模型训练时间分为数据处理时间和通信传输时间两部分,而随着计算机设备算力的提升,数据处理时间不断降低,联邦学习的通信传输效率变成限制其训练速度的主要因素。
对于一些复杂的深度学习模型,比如卷积神经网络,每一个模型可能都包含几百万个参数,如果频繁地进行通信,会造成较大的通信开销并成为模型训练的瓶颈。
在互联网环境中,大量本地模型的更新、上传会导致中心服务器通信开销过大,无法满足正常的应用要求,同时相邻的模型更新中可能包含许多重复更新或者与全局模型不相关的更新。
综上,联邦学习的通信效率优化具有重要的研究意义。通常改进方案有两个目标:
- 减少每轮通信传输的数据大小;
- 减少模型训练的总轮数。
目前,改进通信效率方案主要是通过优化联邦学习框架算法、压缩模型更新和采用分层分级的训练架构。这些方案一定限度上提升了联邦学习模型训练速度、减小了数据通信量,对联邦学习技术的完善具有重大意义,但现阶段仍然存在许多难以解决的问题。例如:
- 优化算法在处理 Non-IID 数据时相对于处理 IID 数据的时间开销成倍增长;
- 压缩算法虽然能够显著降低通信数据大小,但同时会严重影响模型精度,在通信效率和模型精度之间的平衡成为挑战;
- 分层分级的训练架构也不适合于所有的联邦学习场景,有时这种物理结构并不存在。
通信效率优化
目前的研究中针对通信效率的改进主要有以下 3 种方法。
-
算法优化:开发适合处理 Non-IID 和非平衡分布数据的模型训练算法,减少用于传输的模型数据大小,加快模型训练的收敛速度。
-
压缩:压缩能够有效降低通信数据大小,但对数据的压缩会导致部分信息的丢失,此类方法需要在模型精度和通信效率之间寻找最佳的平衡。
-
分散训练:将联邦学习框架分层分级,降低中心服务器的通信负担。
在大多数情况下,这几种方法是相辅相成的,通过特定的方法把这几种方案结合是研究的热点方向[28-29]。表1给出现有通信效率算法的性能比较。
聚合算法
算法优化是对分布式机器学习框架的改进,使该框架更适用于海量客户端、高频率、低容量、数据特征不均的联邦学习环境,实现通信轮数和模型更新数据的减少。
在分布式计算框架中,客户端每运行一次 SGD 算法训练,机器学习模型就会向中心服务器上传本轮产生的本地模型更新。但是,频繁的通信交互会对参与训练各方造成不必要的通信负担。
McMahan 等针对联邦学习的低带宽环境提出 FedAvg 算法,要求客户端在本地多次执行 SGD 算法,然后与中心服务器交互模型更新,实现用更少的通信轮数训练出相同精度的模型。相比于基准算法 FedSGD,其在训练不同神经网络的通信轮数上减少了 1%~10%,但该算法对于非凸问题没有收敛保证,在非 IID 数据集上难以收敛。
聚合算法的优化在所有 C-S 网络拓扑、横向类型联邦学习中都起到了关键作用。
- FedAvg:引入了基于随机梯度下降(SGD)优化算法的联邦平均算法。
- SMC-Avg:安全聚合基于安全多方计算(SMC)算法的概念,该算法聚合相互不信任的各方的私有值,而不揭示其私有值信息。
- FedProx:一种改进的 FedAvg 算法来处理联邦学习的异构性。
- FedMA:一种在联邦学习环境中构建基于 CNNs 和 LSTM 的 ML 模型更新的共享模型。
- etc…
FedAvg 的思想是增加边缘侧的计算量。边缘侧频繁地对模型进行上传是造成网络通信成本高的主要原因,因此需要减小边缘设备上传模型的次数,考虑到移动设备的处理器越来越强大且训练模型的数据集相对较小,因此可以在移动设备本地对模型进行更多的训练,之后再将训练好的模型上传到联邦学习服务器。由于经过更多计算之后的模型效果更好,因此边缘设备需要迭代的次数也就更少,通过减小上传频率减少了通信成本,这种方法的代价就是边缘侧的移动设备需要进行更多的计算。
自 FedAvg 算法被提出,后续大量研究在此基础上做进一步的拓展,但 FedAvg 算法本身有一定的缺陷:
- 首先,中心服务器端聚合时根据客户端数据量大小来分配相应的权重,这导致拥有大量重复数据的客户端能够轻易影响全局模型;
- 其次,客户端仅执行 SGD 算法和执行固定次数的 SGD 算法一定限度上限制了模型训练的速度。
对此,Li 等提出 FedProx 算法,根据客户端设备可用的系统资源执行可变次数的 SGD 算法,缩短收敛时间的同时将模型更新数据压缩了 1/2~1/3,更加适用于客户端数据质量、计算资源等联邦学习场景。同样是针对联邦学习框架的改进,Liu 等认为传统的 FL 仅利用一阶梯度下降(GD),忽略了对梯度更新的先前迭代,提出了 MFL 方案,在联邦学习的本地模型更新阶段使用动量梯度下降(MGD),实验证明,在一定条件下该方案显著提升了模型训练的收敛速度。Huang 等提出迭代自适应的 LoAdaBoost 算法,通过分析客户端更新的交叉熵损失,调整本地客户端 epoch 次数,相对于传统 FedAvg 算法固定 epoch,准确度与收敛速度均有显著提升。
除了对最初的 FedAvg 算法的各种改进以外,在客户端或者服务器上增加筛选算法也是研究方向之一。Wang 等认为客户端上传的本地模型更新中含有大量的冗余和不相关信息,严重占用通信带宽,因此提出 CMFL 算法,该算法要求客户端筛选本地模型更新与上一轮全局模型的相关度,通过模型梯度正负符号相同的百分比来避免上传达不到阈值要求的本地模型更新,实现通信开销的降低,但该算法建立在客户端按照协议执行的基础上,系统的鲁棒性较弱。Jiang 等提出了 BACombo 算法,利用 gossip 协议和 epsilongreedy 算法检查客户端之间随时间变化的平均带宽,最大限度地利用带宽容量,进而加快收敛速度。
压缩
压缩方案通常分为两种:
- 梯度压缩
- 全局模型压缩
通常情况下,梯度压缩相比于全局模型压缩对通信效率的影响更大,因为互联网环境中上行链路速度比下载链路速度慢得多,交互通信的时间主要集中在梯度数据上传阶段。
横向联邦学习中往往有大量的本地客户端,很难保证每个客户端都拥有稳定可靠的网络连接,低质量的通信会严重降低通信速度。Konečný 等提出针对本地模型的结构化更新和草图更新算法,客户端被要求在一个低秩或随机掩码后的有限空间中进行模型学习,然后草图更新算法对模型更新进行量化、随机旋转和子采样等压缩操作,该方案被证明在 SGD 迭代方面显著减慢了收敛速度。
在上述基础上,Caldas 等将该方法应用于对全局模型更新的压缩中,同时提出 Federated Dropout 思想优化模型更新,中心服务器随机选择全局模型的更小子集并采用量化、随机旋转和子采样等压缩操作,客户端接收到全局模型后解压缩并进行本地模型训练,从而减少了联邦学习对客户端设备资源的影响,允许培训更高容量的模型,并接触到更多样化的用户。
Reisizadeh 等选择将算法优化与压缩的思路结合起来,其提出的 FedPAQ 算法要求服务器只选择一小部分客户端参与训练,同时客户端减少上传本地模型次数并在上传之前进行量化更新操作减小通信量。
但是,上述算法采取的都是固定阈值的压缩通信,这种方式在客户端之间模型更新差异较大时显得并不合理。对此,Lu 等提出自适应阈值梯度压缩算法,客户端通过判断梯度变化,计算得到适当的阈值用于压缩通信,同时保证模型的性能损失较小。
另外,现有的大部分压缩方法只在呈 IID 分布的客户端数据下表现良好,这些方法并不适合联邦学习场景。对此,Sattler 等提出一种新的稀疏三元压缩(STC)框架,STC 扩展了现有的 top-k 梯度稀疏化压缩技术,通过 Golomb 无损编码压缩联邦框架交互的模型更新,使算法更适用于高频率低容量的联邦学习环境,同时保证了在大量客户端参与下的鲁棒性。
分散训练
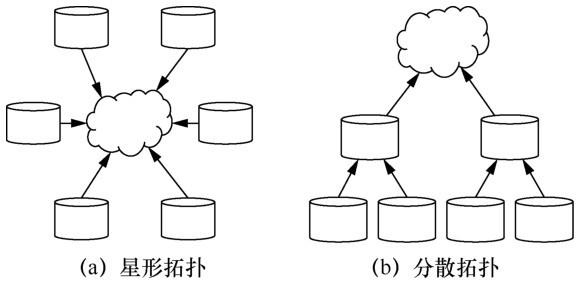
在联邦学习中,通信拓扑通常是星形拓扑,但这往往会造成中心服务器的通信成本太大,分散拓扑(客户端只与它们的邻居通信)可以作为一种替代方案,如图 6 所示。
在低带宽或高时延网络上运行时,分散拓扑被证明比星形拓扑训练速度更快。联邦学习的分散拓扑先设定边缘服务器聚合来自客户端设备的本地更新,然后边缘服务器充当客户端的角色与中心服务器交互。例如,Sharma 等构建了一个多层分布式计算防御框架,通过数据层、边缘层、雾层和云层的协同决策,解决海量数据集中传输的问题。通过这种分层通信的方法可以有效降低中央服务器的通信负担,但它并不适用于所有的场景,因为这种物理层次可能不存在,也不可能预先知道。
隐私安全仍有缺陷
联邦学习通过源数据不出本地而仅交互模型更新(如梯度信息)的方式来保护用户的敏感数据,开创了数据安全的新范式。理想情况下,联邦学习中客户端通过训练源数据上传本地模型,服务器仅负责聚合和分发每轮迭代形成的全局模型。然而,在真实的网络环境中,模型反演攻击、成员推理攻击、模型推理攻击层出不穷,参与训练的客户端动机难以判断,中心服务器的可信程度难以保证,仅通过模型更新来保护用户隐私的方式显然是不够的。
研究表明,梯度信息会泄露用户的隐私数据,攻击者可以通过客户端上传的梯度信息间接推出标签信息和数据集的成员信息。Carlini 等从训练用户语言数据的递归神经网络中提取出了用户的敏感数据,如特定的银行卡号。Fredrikson 等研究了如何从模型信息中窃取数据隐私,并通过药量预测实验实现了对线性回归模型的反演攻击,获得了患者的敏感信息。Hitaj 等用生成对抗网络(GAN)对模型聚合发起攻击,实验结果表明,恶意客户端能够通过产生相似的本地模型更新来窃取用户数据隐私。Gei 等证明了从梯度信息重建输入数据的可行性与深度网络架构无关,并将一批输入图像用余弦相似度和对抗攻击的方法恢复出来。
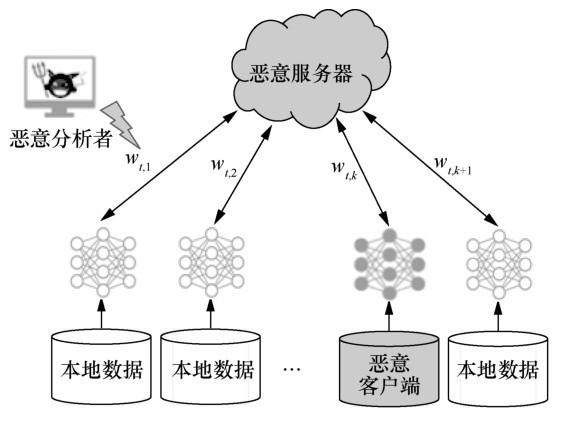
如图 5 所示,联邦学习主要存在 3 种威胁:
- 恶意客户端修改模型更新,破坏全局模型聚合;
- 恶意分析者通过对模型更新信息的分析推测源数据隐私信息;
- 恶意服务器企图获得客户端的源数据。
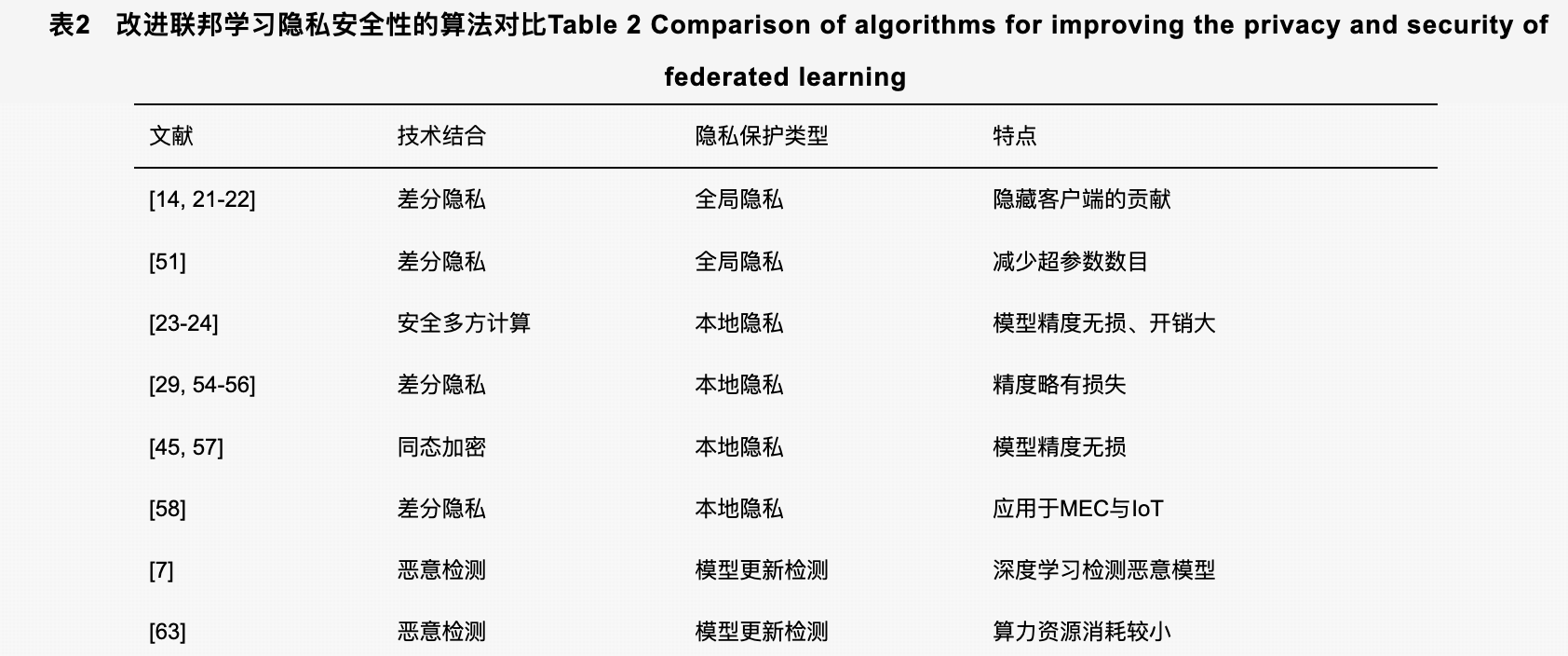
针对以上威胁,增强联邦学习隐私安全性的主流方案与经典机器学习隐私保护技术结合,包括:
- 差分隐私(DP,differential privacy)
- 安全多方计算(MPC,secure multi-party computation)
- 同态加密(HE,homomorphic encryption)
- 等
大量的研究表明,联邦学习与这些隐私保护技术的结合能够提供足够强的安全性,但仍然存在一些问题需要解决。例如:
-
与差分隐私的结合在较少客户端参与的联邦学习中,模型精度受到较大的影响,虽然在大量客户端参与时能够通过模型加权平均抵消噪声误差,但算法中包含的大量超参数仍然限制了进一步的应用;
-
与安全多方计算和同态加密技术的结合能够提供无损全局模型的构建,但同时会造成较大的通信开销,如何平衡通信负担和模型安全是一个相当大的挑战。
隐私安全优化
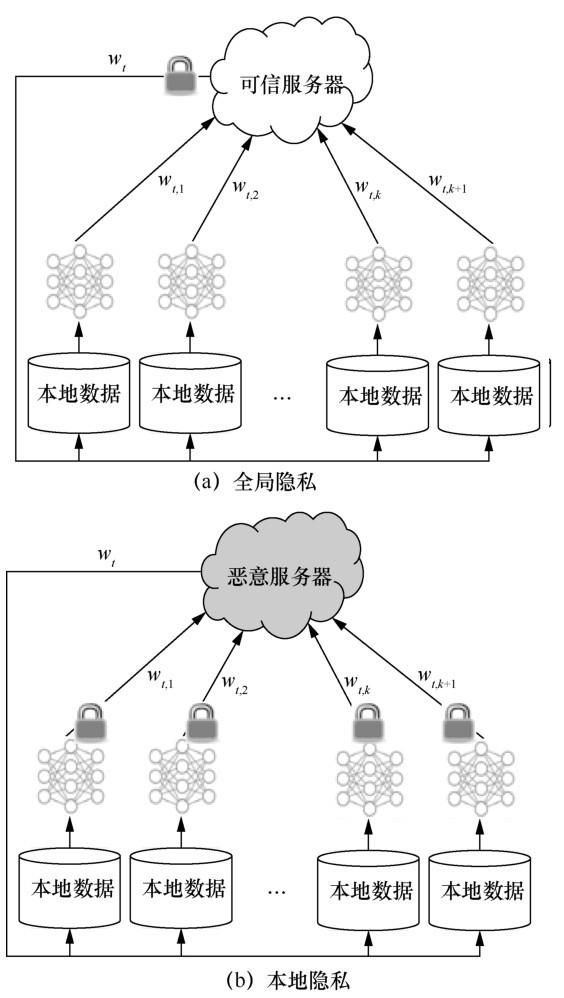
为解决联邦学习中暴露的隐私泄露问题,学术界做了大量研究来增强隐私安全性。根据隐私保护细粒度的不同,联邦学习的隐私安全被分为:
- 全局隐私(global privacy):假定中心服务器是安全可信任的,即每轮通信的模型更新中心服务器可见。
- 本地隐私(local privacy):假定中心服务器同样可能存在恶意行为,因此本地模型更新在上传到中心服务器之前需要进行加密处理。
典型隐私保护技术
现有的方案主要通过结合典型隐私保护技术来提供进一步的隐私增强,如差分隐私、安全多方计算、同态加密等技术,这些技术在之前的研究中已经被广泛应用于传统机器学习的隐私保护。
安全多方计算:假设有 n 个参与方 P1, P2,…,Pn 分别拥有自己的敏感数据 m1,m 2,…,m n,这 n 个参与者在不泄露各自输入数据的前提下共同执行一个协议函数 f(m1,m2,…,mn)。
安全多方计算的研究焦点是在没有可信第三方的条件下,参与训练各方安全计算的一个共同的约束函数。姚期智于 1983 年提出安全多方计算的概念,通过混淆电路、不经意传输、秘密分享等技术实现多方共同运算,并确保各方数据的安全性。

全局隐私
在全局隐私中,假设存在一个受信任的服务器,外部敌手可能是恶意客户端、分析师、使用学习模型的设备或它们的任何组合。恶意客户端可以从中心服务器接收到它们参与轮的所有模型迭代信息,分析师可以在不同的训练轮中使用不同的超参数来研究模型迭代信息。因此,对中间迭代过程和最终模型进行严格的加密保护十分重要。
在联邦学习进程中,恶意客户端能够通过对分布式模型的分析,获得客户端在训练过程中的贡献及数据集信息。Geyer 等提出一种针对客户端的差分隐私保护联邦优化算法,实现了对模型训练期间客户端贡献的隐藏,在有足够多客户端参与的情况下,能够以较小的模型性能成本来达到用户级差分隐私。McMahan 等同样使用差分隐私加密全局模型更新,证明了如果参与联邦学习的客户端数量足够多,对模型更新信息的加密就会以增加计算量为代价而不会降低模型精度。Bhowmick 等利用差分隐私技术,通过限制潜在对手的能力,提供同等隐私保护程度的同时保证了更好的模型性能。
但是,上述方案中都存在许多影响通信效率和精度的超参数,用户必须谨慎选择才能达到预期效果。Thakkar 等针对这个缺点提出自适应梯度裁剪策略,对特定层添加不同的噪声,同时对迭代差分隐私机制应用自适应分数剪裁,有效缓解了差分隐私算法中超参数过多的问题。
本地隐私
针对不可信服务器和恶意敌手反演攻击的问题,结合传统的安全多方计算和同态加密等技术,能实现模型信息的无损加解密,但却大大增加了通信成本与计算开销。
- Bonawitz 等提出 Secure Aggregation 模型,结合秘密分享等技术使服务器无法解密单一客户端的梯度信息,仅能执行聚合操作得到全局模型,从而实现对恶意服务器的信息隐藏。
- Mandal 等在此工作基础上做了通信效率的改进,引入它非交互式成对密钥交互计算(NIKE)技术,在离线阶段计算主密钥的同时限定用户最多与 L 个邻居进行掩码操作,从而有效减少了秘密分享的时间开销。
- Dong 等将秘密分享与同态加密应用于通信效率算法(TernGrad),解决了隐私泄露的同时大幅提升了框架的通信和计算开销。
- Hao 等通过改进 BGV 同态加密算法,消除了密钥交换操作并增加了纯文本空间,提供后量子安全性的同时避免了交互密钥导致的通信负担。在纵向联邦学习场景中,各部门进行训练数据对齐时可能造成标签信息和私有数据的泄露。
- Cheng 等通过改进 XGBoost 树模型提出 SecureBoost 算法,其利用 RSA 和哈希函数实现各方数据的共有样本 ID 对齐,同时使用加法同态加密保护各方交互的标签信息和梯度直方图信息,最终实现了与不添加隐私保护的联邦学习相同的模型精度。
- Aono 等对深度神经网络模型进行同态加密的思想为联邦学习提供了新方向。
另一个研究热点是联邦学习与差分隐私的融合,由于差分隐私不增加客户端通信成本,被广泛应用于模型更新的隐私保护。学术界的研究主要致力于在保护隐私信息的前提下,尽可能地减少噪声对模型训练的影响,进而提升模型性能。Liu 等提出一种自适应隐私保护的 APFL 方案,通过分析数据集的特征向量 xi 对输出模型的影响,为不同贡献的特征向量分配不同的隐私预算 ε,同时减少贡献较少的数据集的噪声,实现严格差分隐私的同时高效保证了全局模型精度与性能。Huang 等针对客户端之间的不平衡数据提出 DP-FL 框架,其根据每个用户的数据量设置不同的差分隐私预算 ε,设计具有自适应梯度下降算法的差分隐私专用卷积神经网络,来更新每个用户的训练参数,结果证明相较于传统的 FL 框架,该方案在不平衡数据集中表现较好。Wei 等将差分隐私与 FL 的结合做了深入的分析,证明存在最优的 K 值(1≤K≤总客户端数 N),可以在固定的隐私保护级别上实现最佳的收敛性能。Cao 等则从通信效率和隐私保护的结合出发,结合本地差分隐私,为物联网终端低算力设备提供了资源消耗的隐私保护框架。
但是,上述方案主要致力解决服务器不可信的问题,没有考虑服务器是否正确执行指定聚合操作,恶意服务器很有可能会回传虚假全局模型,蓄意破坏特定客户端对全局模型的使用。针对这类信任问题,Xu 等提出具有隐私保护和模型可验证的联邦学习框架 VerifyNet,通过双掩码协议保证客户端本地梯度的保密性,同时将中心服务器欺骗客户端的困难性转移到解 NP-hard 数学难题上,保证了全局模型的完整性和正确性。
随着联邦学习在移动边缘计算(MEC)和物联网(IoT)中的广泛应用,其存在的安全与隐私问题开始受到关注。Lu 等提出了一种差分隐私异步联邦学习(DPAFL)方案,通过将本地差分隐私引入联邦学习中,在本地模型的 SGD 更新中加入高斯噪声以保护隐私性,同时开发了一个新的异步联邦学习架构,它利用分布式的点对点更新方案,而不是集中式更新,以减轻集中式服务器带来的单点安全威胁,更适用于 MEC 环境。后来,Lu 等将这种方案应用于车载网络物理系统,解决车辆物联网环境下敏感数据泄露的问题。Hu 等在异构物联网环境中使用联邦学习结合差分隐私保障用户隐私,提出一种对用户设备异质性具有鲁棒性的 FL 算法。
模型更新检测
对于模型更新的异常检测同样是确保训练过程安全的重要方式,Fang 等通过客户端的本地模型发起中毒攻击使全局模型具有较大的测试错误率,并对 4 种拜占庭鲁棒性联邦学习框架进行了攻击研究,证明了联邦学习对局部模型中毒防御的必要性。
在联邦学习环境中,通常有数以万计的设备参与训练,服务器如果无法及时检测恶意客户端,很容易造成全局模型被污染甚至隐私泄露问题。Li 等提出基于检测的算法,通过一个预先训练的自动编码器神经网络来检测异常的客户行为,并消除其负面影响,给出各客户端信用评分并拒绝恶意客户端的连接。Zhao 等通过在服务器端部署 GAN,通过客户端模型参数生成审计数据集,并利用该数据集检查参与者模型的准确性,确定是否存在中毒攻击。实验证明,该方法相比传统的模型反演方法,生成的审计数据集质量更高。
但是,上述提出的检测算法需要消耗服务器大量的算力审核客户端本地模型,这导致在全诚实客户端参与的联邦学习中,资源遭到极大的浪费。对此,为减少算力消耗,Kang 等通过经典的 RONI 中毒攻击检测算法,比较数据库中有没有相似的本地模型更新效果来判断是否中毒,然后对客户端给出信誉分以供任务发布者选择信誉值高的客户端参与训练,进而排除恶意客户端攻击的可能。Fung 等将这种比较放在本地模型与上一轮全局模型上,通过比较本地模型更新与全局模型更新向量方向的相似性,判断客户端是否存在恶意。Chen 等基于受信任的执行环境,设计了训练完整性协议用于检测不诚实的行为,如篡改本地训练模型和延迟本地训练进程,实验证明该方案具有训练完整性与实用性。
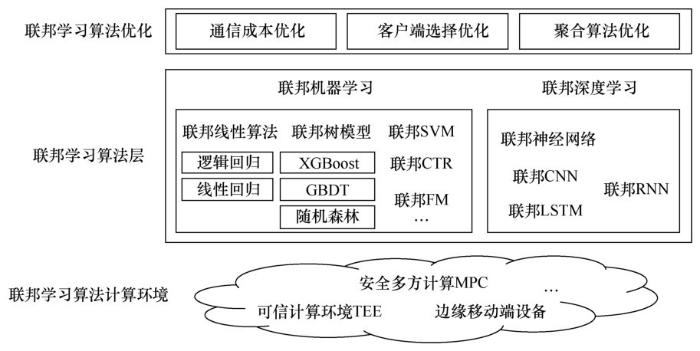
联邦学习算法结构
-
支持非独立同分布数据:这是联邦学习算法的一个很重要的特性。联邦学习算法必须在非独立同分布数据中有良好的表现。在联邦学习的实际使用中,数据持有方的数据质量和分布是不可控的,无法要求数据持有方的数据满足独立同分布,因此联邦学习算法需要支持非独立同分布数据。
-
通信高效:联邦学习算法需要考虑数据持有方的系统异构性,并在不损失准确率或损失很小的情况下提高通信效率,降低通信损耗。
-
快速收敛:在联合建模过程中,首先需要保证模型收敛,同时需要提高收敛速度。
-
安全性和隐私性:数据隐私安全是联邦学习的重要特点,因此安全性和隐私性是对联邦梯度更新的必要要求。安全性和隐私性可以通过加密等方式在聚合过程中进行,也可以反映在单机优化的过程中。
-
支持复杂用户:复杂用户指用户本身数量大,且用户数据存在不均衡性或偏移。这在联邦学习的实际应用中是非常可能的,联邦优化算法需要对这种情况具有很好的兼容效果。
联邦学习的开源框架
- Tensorflow Federated(https://www.tensorflow.org/federated/federated_learning):谷歌的 TensorFlow Federated 在 Gboard 中有一个产品化的版本,它可以让 Android 手机用户在使用手机键盘时预测下一个单词,这是社区中将联邦学习变为现实的最早尝试。
- PySyft(https://blog.openmined.org/tag/pysyft/):是在 PyTorch 框架之上用 Python 编写的,它提供了一个虚拟 Hook,通过 WebSocket 端口连接到客户端。
- FATE(https://fate.fedai.org):来自微众银行开发人员名为 FATE 的软件,每次发布都在即兴创作。

