- 1简易计算器设计_简易计算器的设计
- 2H5跳小程序_h5跳小程序首页
- 3python机器学习课程——决策树全网最详解超详细笔记附代码_决策树python代码
- 4微信canvas画一个进度条刻度扇形_微信小程序 canvas.arc 扇形图
- 5上岸后导师面试失败总结_导师面试被刷
- 6Android_Studio_快捷键_android studio强制类型转换快捷键
- 7中级软件测试笔试题100精讲_(完整版)软件测试笔试题及答案
- 8@Param注解 spring@Param和mybatis中@Param的区别_spring@param()
- 9数据挖掘与数据化运营实战.导读
- 10小程序隐私保护授权处理方式之弹窗组件_getuserprofile:fail api scope is not declared in t
核密度估计KDE_kde示例
赞
踩
一、参数估计与非参数估计
给定一个样本集,怎么得到该样本集的分布密度函数,解决这一问题有两个方法:
1.参数估计方法
根据经验假设数据符合某种特定的分布,然后通过抽样的样本来估计总体对应的参数,比如假设高斯分布,通过样本来估计对应的均值和方差。由于参数估计方法中需要加入主观的先验知识,往往很难拟合出与真实分布的模型。
2.非参数估计
和参数估计不同,非参数估计并不加入任何先验知识,而是根据数据本身的特点、性质来拟合分布,这样能比参数估计方法得出更好的模型。核密度估计就是非参数估计中的一种,全称为Kernel Density Estimation,缩写为KDE。
二、核密度估计
1. 直方图
对于数据分布,最简单的做法就是绘制直方图了,示例如下:
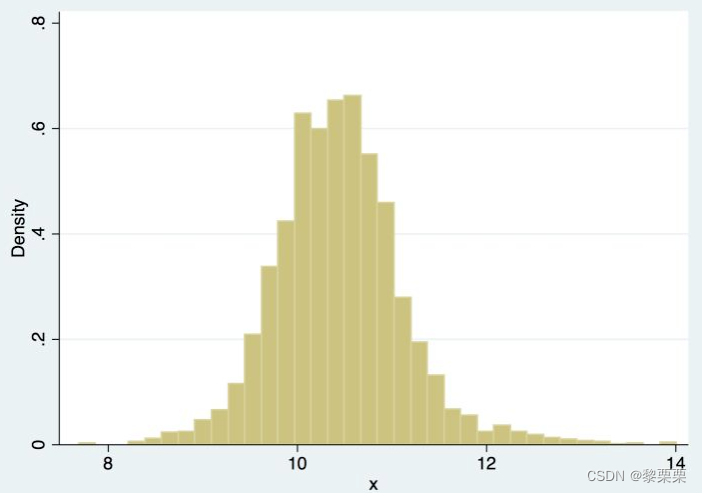
通过直方图上的形态来判断样本分布,但是直方图有着诸多的限制。首先就是直方图非常的离散,不够光滑,仅能反映几个特定区间内的样本分布。其次,该方法对区间大小非常敏感,不同取值会呈现不同的效果,示例如下:

最后直方图的可视化方式也仅仅适用于一维或者二维的数据,对于高维数据,无法适用。
2. 核密度估计 KDE
(1)概述
相比直方图,核密度估计通过离散样本点来的线性加和来构建一个连续的概率密度函数,从而得到一个平滑的样本分布,以一维数据为例,核密度估计的公式如下:
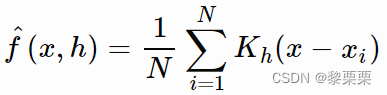
f表示总体的概率密度函数,h是一个超参数,称之为带宽,或者窗口,N表示样本总数,K表示核函数。和SVM中的核函数一样,核函数可以有多种具体形式,以最常用的高斯核函数为例,公式如下:
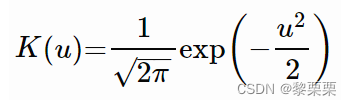
h参数通过影响核函数中自变量的取值来控制每个样本的相对权重,公式如下:
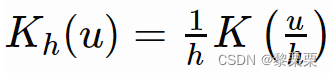
举个例子:
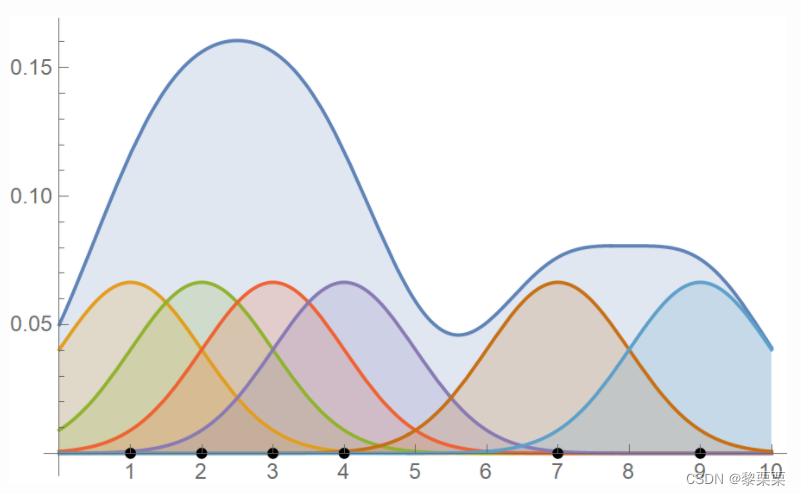
以一个6个样本的一维数据为例,具体取值分别为1,2,3,4,7,9,使用高斯核函数,带宽h设置为1,则KDE对应的概率密度函数如下:
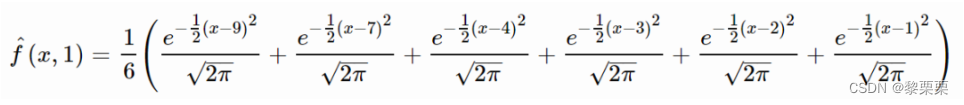
通过图表可以更进一步看到,抽样的6个离散值与总体分布的关系
(2)核函数K与参数h对概率分布的影响
-
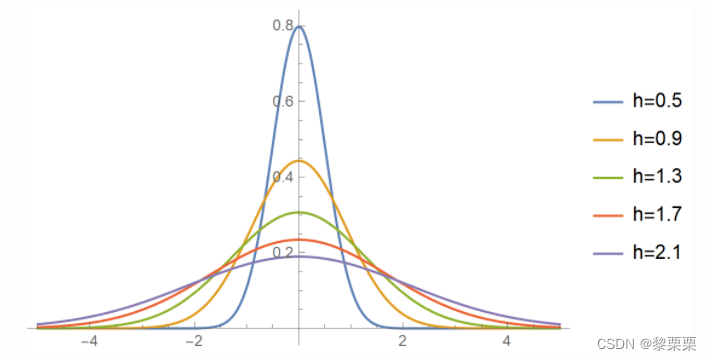
参数h
对于KDE方法而言,h参数的选择对结果的影响较大,以高斯核函数为例,不同的h对应的形状如下
-
核函数K
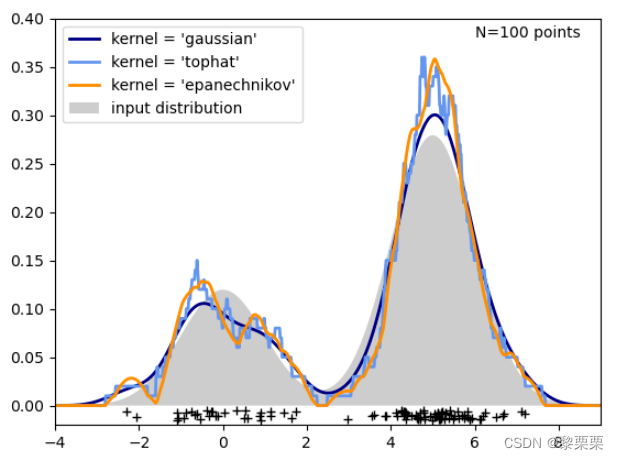
带入到概率密度函数中,不同样本对应的系数值就会不一样,所以说h控制了样本的权重。在sickit-learn中, 提供了多种核函数来进行核密度估计,图示如下
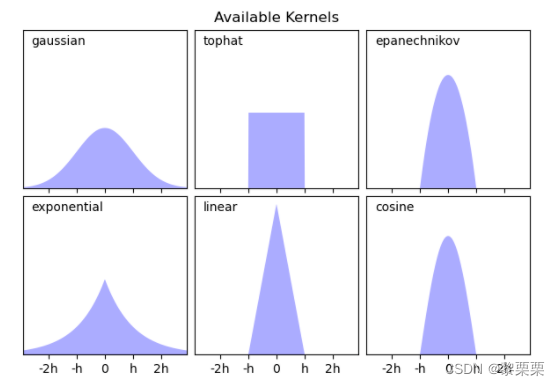
对于不同的核函数而言,虽然会有一定的影响,但是效果没有h参数的影响大,示例如下