
热门标签
热门文章
- 12024年第十四届MathorCup数学应用挑战赛D题思路分享(妈妈杯)_mathorcup d题
- 2Python 直接读写硬盘扇区数据_python读写磁盘扇区数据
- 3小程序如何访问本地后端服务_微信小程序连接后台服务器
- 4CTFHUB-WEB-信息泄露+密码口令【02】 dirsearch 、Githack使用_githack与dirsearch
- 5静态路由实验(eNSP)
- 6《用Python进行自然语言处理》第 5 章 分类和标注词汇_python人称代词
- 7建设数字工厂:华为云数字工厂平台接入第三方网关设备数据_华为云数字工厂行业平台
- 8基于springboot,用micropython开发esp32cam,整合mqtt,websocket,内网穿透技术,实现远程监控的demo_esp32内网穿透
- 9时序模型——如何用Python进行时序模型预测的baseline预测(简单规则)_python 时序预测
- 10jieba的词性标注_jieba词性标注
当前位置: article > 正文
Hive 解决数据倾斜方法_hive reduce端数据倾斜
作者:菜鸟追梦旅行 | 2024-05-17 09:26:11
赞
踩
hive reduce端数据倾斜
数据倾斜问题, 通常是指参与计算的数据分布不均, 即某个 key 或者某些 key 的数据量远超其他 key, 导致在 shuffle 阶段, 大量相同 key 的数据被发往同一个 Reduce, 进而导致该 Reduce 所需的时间远超其他 Reduce, 成为整个任务的瓶颈 。
Hive 中的数据倾斜常出现在分组聚合和 join 操作的场景中,下面分别介绍在上述两种 场景下的优化思路。
1) 分组聚合导致的数据倾斜
Hive 中的分组聚合是由一个 MapReduce Job 完成的。Map 端负责读取数据, 并按照分组字段分区, 通过 Shuffle, 将数据发往 Reduce 端, 各组数据在 Reduce 端完成最终 的聚合运算。若 group by 分组字段的值分布不均,就可能导致大量相同的 key 进入同一 Reduce, 从而导致数据倾斜。
由分组聚合导致的数据倾斜问题, 有如下解决思路:
- (1) 判断倾斜的值是否为 null
若倾斜的值为null, 可考虑最终结果是否需要这部分数据,若不需要,只要提前将null 过滤掉,就能解决问题 。若需要保留这部分数据,考虑以下思路。 - (2) Map-Side 聚合
开启 Map-Side 聚合后,数据会先在 Map 端完成部分聚合工作。这样一来即便原始数据是倾斜的, 经过 Map 端的初步聚合后,发往 Reduce 的数据也就不再倾斜了 。 最佳状态下,Map 端聚合能完全屏蔽数据倾斜问题。
相关参数如下:
set hive.map.aggr=true;
set hive.map.aggr.hash.min.reduction=0.5;
set hive.groupby.mapaggr.checkinterval=0.5;
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
- 1
- 2
- 3
- 4
- (3) Skew-GroupBy 优化
Skew-GroupBy 是 Hive 提供的一个专门用来解决分组聚合导致的数据倾斜问题的方案。 其原理是启动两个 MR 任务, 第一个 MR 按照随机数分区, 将数据分散发送到 Reduce, 并 完成部分聚合, 第二个 MR 按照分组字段分区, 完成最终聚合。
相关参数如下:
-- 启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
- 1
- 2
2) Join 导致的数据倾斜
若 Join 操作使用的是 Common Join 算法,就会通过一个 MapReduce Job 完成计算 。Map 端负责读取 Join 操作所需表的数据,并按照关联字段进行分区,通过 Shuffle,将其发送到 Reduce 端,相同 key 的数据在 Reduce 端完成最终的 Join 操作。如果关联字段的值分布不均, 就可能导致大量相同的 key 进入同一 Reduce, 从而导致数据倾斜问题。
由 Join 导致的数据倾斜问题, 有如下解决思路:
- (1) Map Join
使用 Map Join 算法,Join 操作仅在 Map 端就能完成,没有 Shuffle 操作,没有 Reduce 阶段,自然不会产生 Reduce 端的数据倾斜 。该方案适用于大表 Join 小表时发生数据倾斜的场景。
相关参数如下:
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask=true;
set hive.auto.convert.join.noconditionaltask.size=10000000;
- 1
- 2
- 3
- (2)Skew Join
若参与 Join 的两表均为大表,Map Join 就难以应对了 。此时可考虑 Skew Join, 其核心原理是Skew Join为倾斜的大 key 单独启动一个 Map Join 任务进行计算,其余 key进行正常的 Common Join 。 原理图如下:
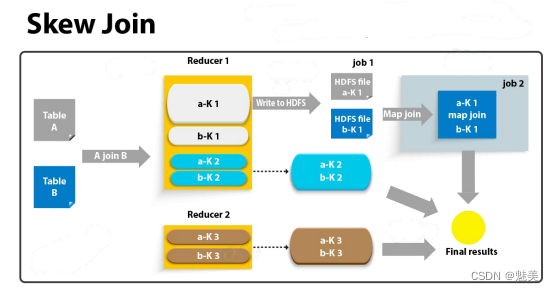
相关参数如下:
--启用skew join 优化
set hive.optimize.skewjoin=true;
--触发skew join 的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
- 1
- 2
- 3
- 4
- 3) 调整 SQL 语句
若参与 Join 的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对 SQL 语句进行相应的调整。
假设原始 SQL 语句如下:A,B 两表均为大表,且其中一张表的数据是倾斜的。
hive (default)>
select
*
from A
join B
on A.id=B.id;
- 1
- 2
- 3
- 4
- 5
- 6
其 Join 过程如下:
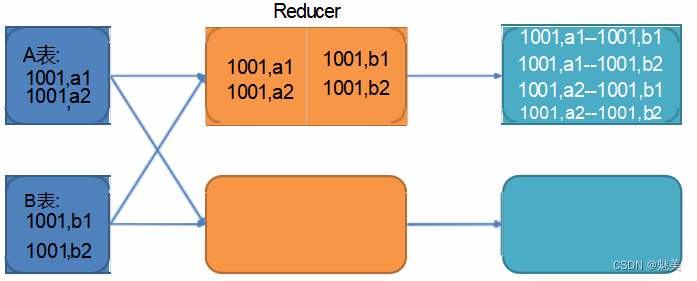
图中 1001 为倾斜的大 key,可以看到,其被发往了同一个 Reduce 进行处理。
调整之后的 SQL 语句执行计划如下图所示:
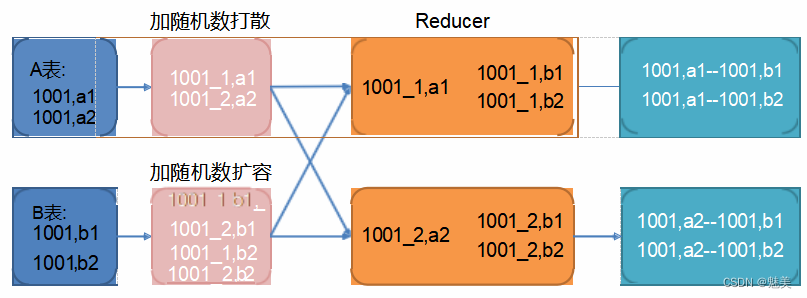
调整 SQL 语句如下:
hive (default)>
select
*
from (
select --打散操作
concat (id, '_ ',cast(rand()*2 as int)) id,
value
from A
)ta
join (
select --扩容操作
concat (id, '_ ',1) id,
value
from B
union all
select
concat (id, '_ ',2) id,
value
from B
)tb
on ta.id=tb.id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/582940
推荐阅读
相关标签

